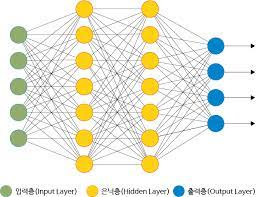
신경망
퍼셉트론으로 복잡한 함수를 표현할 수 있지만, 가중치를 설정하는 작업은 여전히 사람이 수동적으로 해야 한다.
신경망은 가중치 매개변수의 적절한 값을 데이터로부터 자동으로 학습하는 능력이 있기 때문에 이를 해결할 수 있다.
신경망의 구조
가장 왼쪽 줄을 입력층(Input Layer)
중간 줄을 은닉층(Hidden Layer)
가장 오른쪽 줄을 출력층(Output Layer)
은닉층(Hidden Layer)은 입력층이나 출력층과 달리 사람 눈에는 보이지 않는다.
편향을 명시한 퍼셉트론
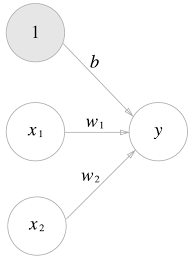 (편향의 입력 신호는 항상 1이기 때문에 해당 뉴런을 회색으로 칠해 다른 뉴런과 구별.)
(편향의 입력 신호는 항상 1이기 때문에 해당 뉴런을 회색으로 칠해 다른 뉴런과 구별.)
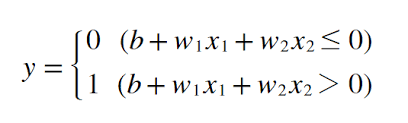
는 편향을 나타내는 매개변수로, 뉴런이 얼마나 쉽게 활성화되느냐를 제어.
는 각 신호의 가중치를 나타내는 매개변수로, 각 신호의 영향력을 제어.
활성화 함수의 개념(Activation Function)

처럼 입력 신호의 총합을 출력 신호로 변환하는 함수를 활성화 함수(Activation Function)라 한다.
이름이 말해주듯 활성화 함수는 입력 신호의 총합이 활성화를 일으키는지를 정하는 역할을 한다.
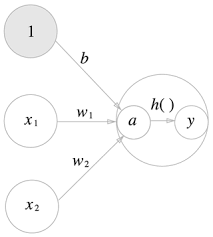
가중치가 달린 입력 신호와 편향의 총합()을 라 할 때,
위와 같이 라는 Activation Function에 를 넣어 를 출력하는 흐름.
활성화 함수

활성화 함수는 임계값을 경계로 출력이 바뀌는데, 이런 함수를 계단 함수(Step Function)라 한다.
그래서 퍼셉트론에서는 활성화 함수로 계단 함수를 이용한다. 라고 할 수 있다.
신경망에서 사용하는 활성화 함수
Step Function(계단 함수)
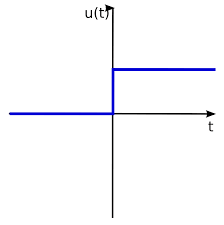
입력값의 합이 임계값을 넘으면 0을, 넘지 못하면 1을 출력.
신경망의 활성함수에서 Step Function은 거의 사용하지 않는다.
그 이유는 ?
- 불연속(Discontinuous)이다. 그래프를 보면 알 수 있듯 임계값 지점에서 불연속점을 갖게 되는데 이 점에서 미분이 불가능하기 때문에 학습이 필요한 신경망에 사용할 수 없게 된다.
- 미분값이 0이 된다. 추후 역전파 과정에서 미분값을 통해 학습을 하게 되는데 이 값이 0이 되어버리면 제대로 된 학습이 되지 않는다.
이런 문제점을 해결하기 위해서 등장한 것이 시그모이드 함수(Sigmoid)
Step Function 구현
Sigmoid Function(시그모이드 함수)
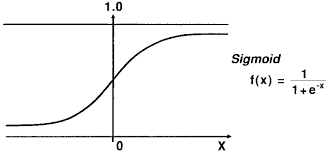
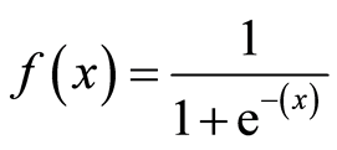
신경망에서 자주 이용하는 활성화 함수인 시그모이드 함수(Sigmoid Function)이다.
Sigmoid Function은 부드러운 곡서이며 입력에 따라 출력이 연속적으로 변화한다.
한편, 계단 함수는 0을 경계로 출력이 이산적으로 바뀌게 된다.
Sigmoid Function 구현
Step Func VS Sigmoid Func (차이점)
Sigmoid Function은 입력에 따라 출력이연속적으로변화한다.
Step Function은 0을 경계로 출력이이산적으로변화한다.
Step Func VS Sigmoid Func (공통점)
- 입력이 아무리 작거나 커도 출력은 0과 1 사이라는 것이 공통된다.
비선형 함수이다.
신경망에서는 활성화 함수로 비선형 함수를 사용해야 한다. 선형 함수를 이용하면 신경망의 층을 깊게 하는 의미가 없어지기 때문이다.
비선형 함수
선형 함수 : 함수에 변수를 입력했을 때, 출력이 입력의 상수배만큼 변하는 함수
에서 는 상수이다. 그래서 선형 함수는 곧은 1개의 직선이 된다.
비선형 함수 : 선형이 아닌 함수. 직선 1개로는 그릴 수 없는 함수.
활성화 함수는 반드시 비선형 함수로

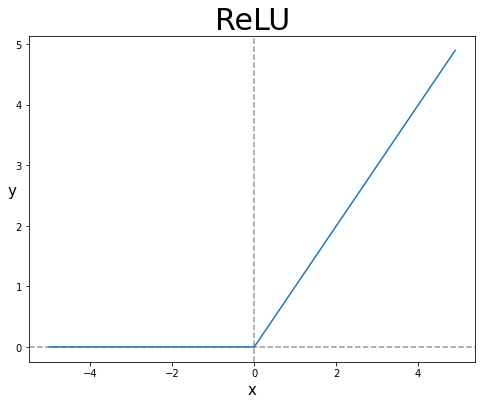
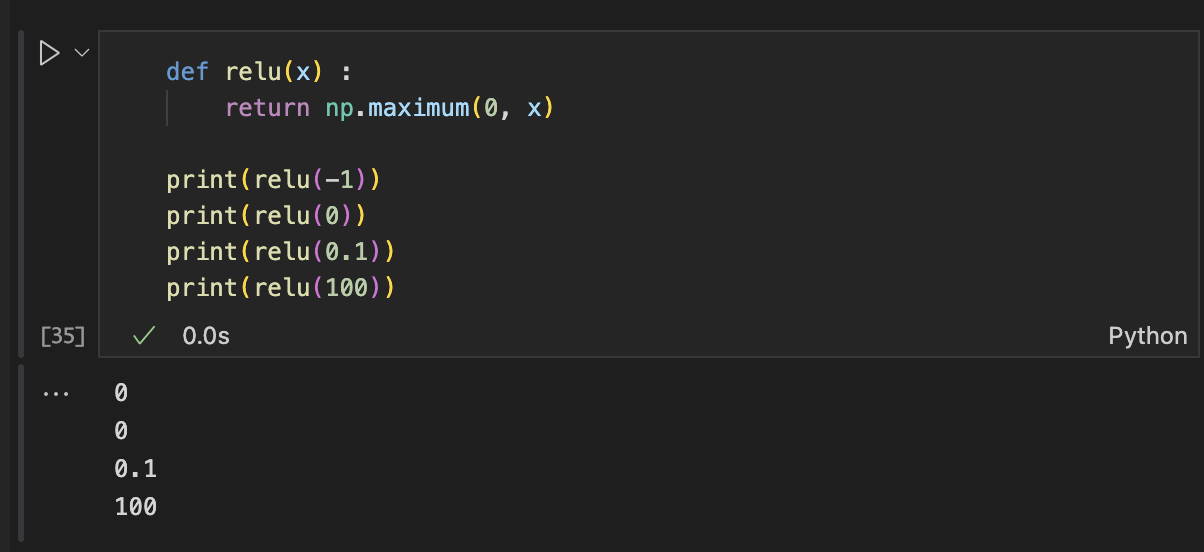
ReLU(Recified Linear Unit, 렐루 함수)
Sigmoid Function은 오래전부터 이용했으나, 최근에는 ReLu(Rectified Linear Unit, 렐루) Function을 주로 사용한다.
ReLU는 입력이 0을 넘으면 그 입력을 그대로 출력하고, 0 이하이면 0을 출력하는 함수이다.
- Rectified : 정류된. (교류에서 -흐름을 차단하는 회로. x가 0 이하일 때를 차단하여 아무 값도 출력하지 않는다.)
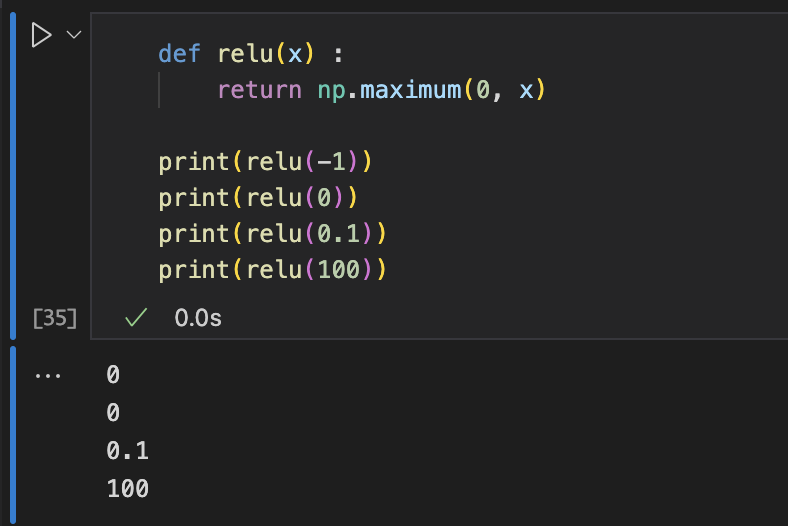
ReLU Function 구현
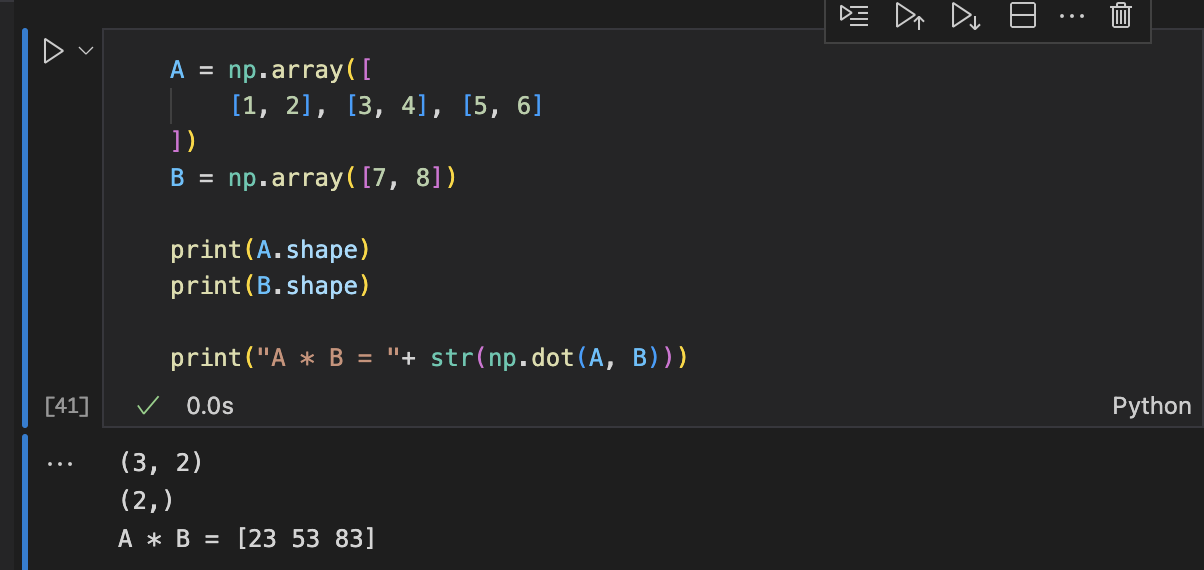
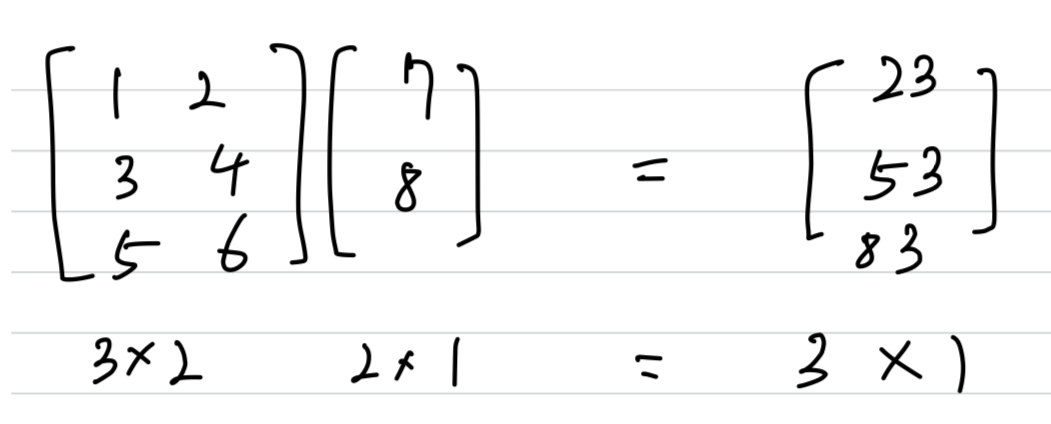
다차원 배열의 계산(Numpy)
두 행렬의 곱 : np.dot(A, B)
신경망에서의 표기법
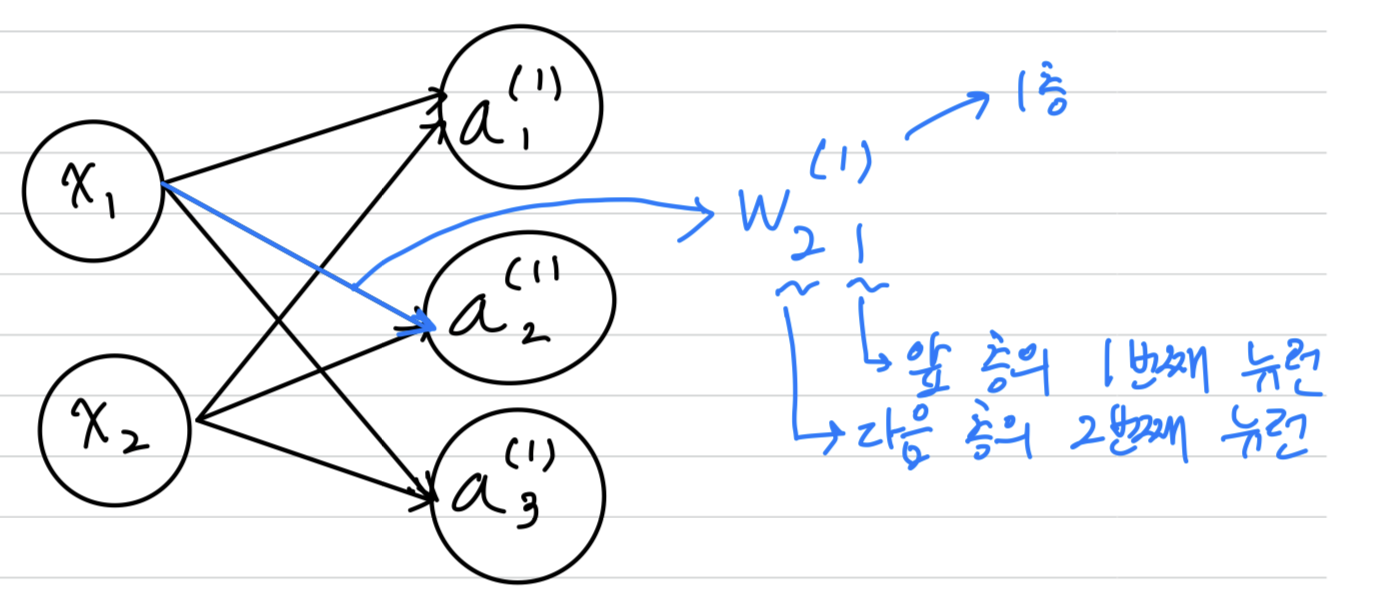
가중치 오른쪽 아래의 인덱스 번호는 '다음 층 번호, 이전 층 번호' 순으로 적는다
각 층의 신호 전달 구현하기
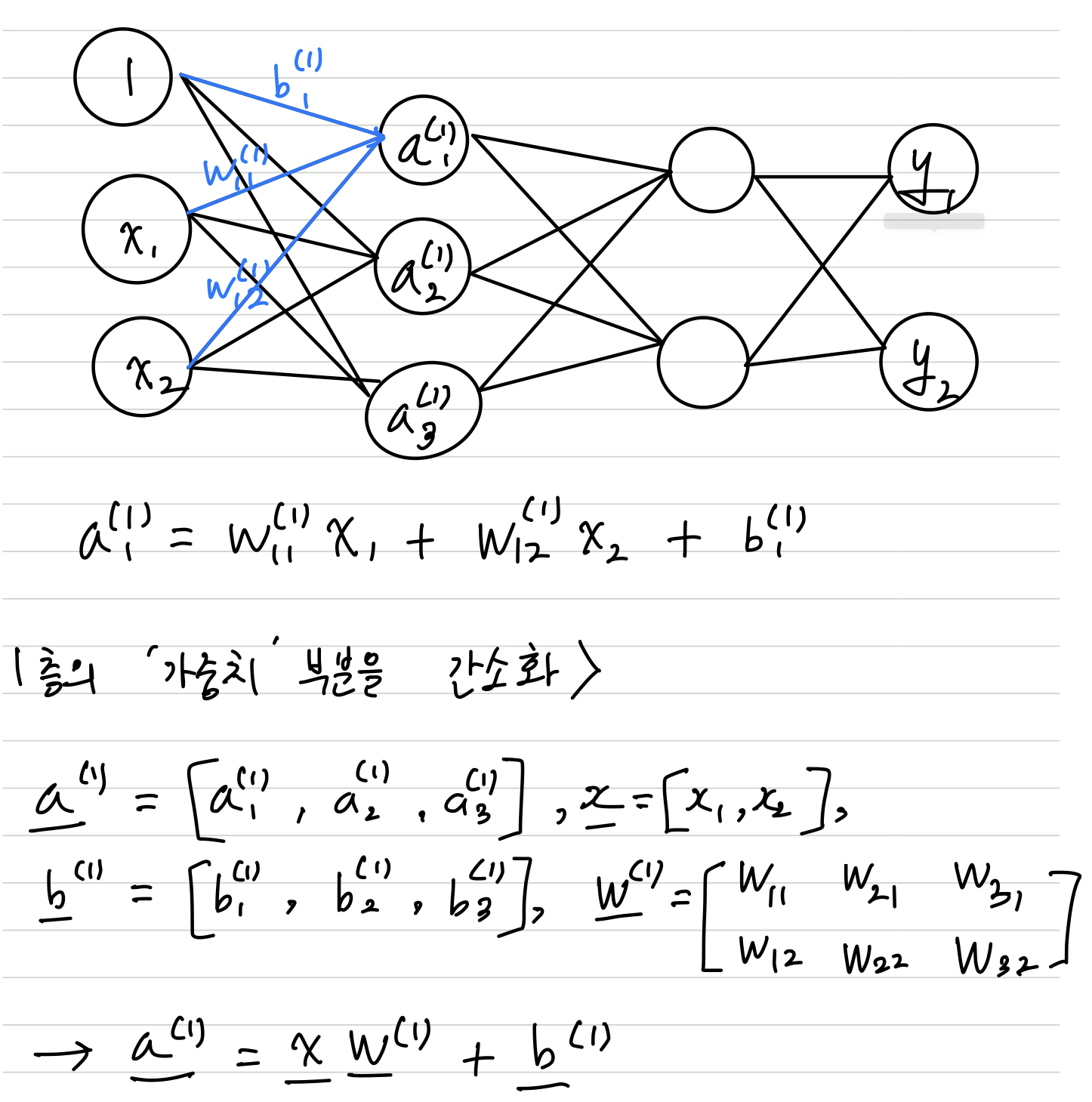
이와 같이 층마다 변수들을 Vector와 Matrix 형태로 변환하여 간소화가 가능하다.
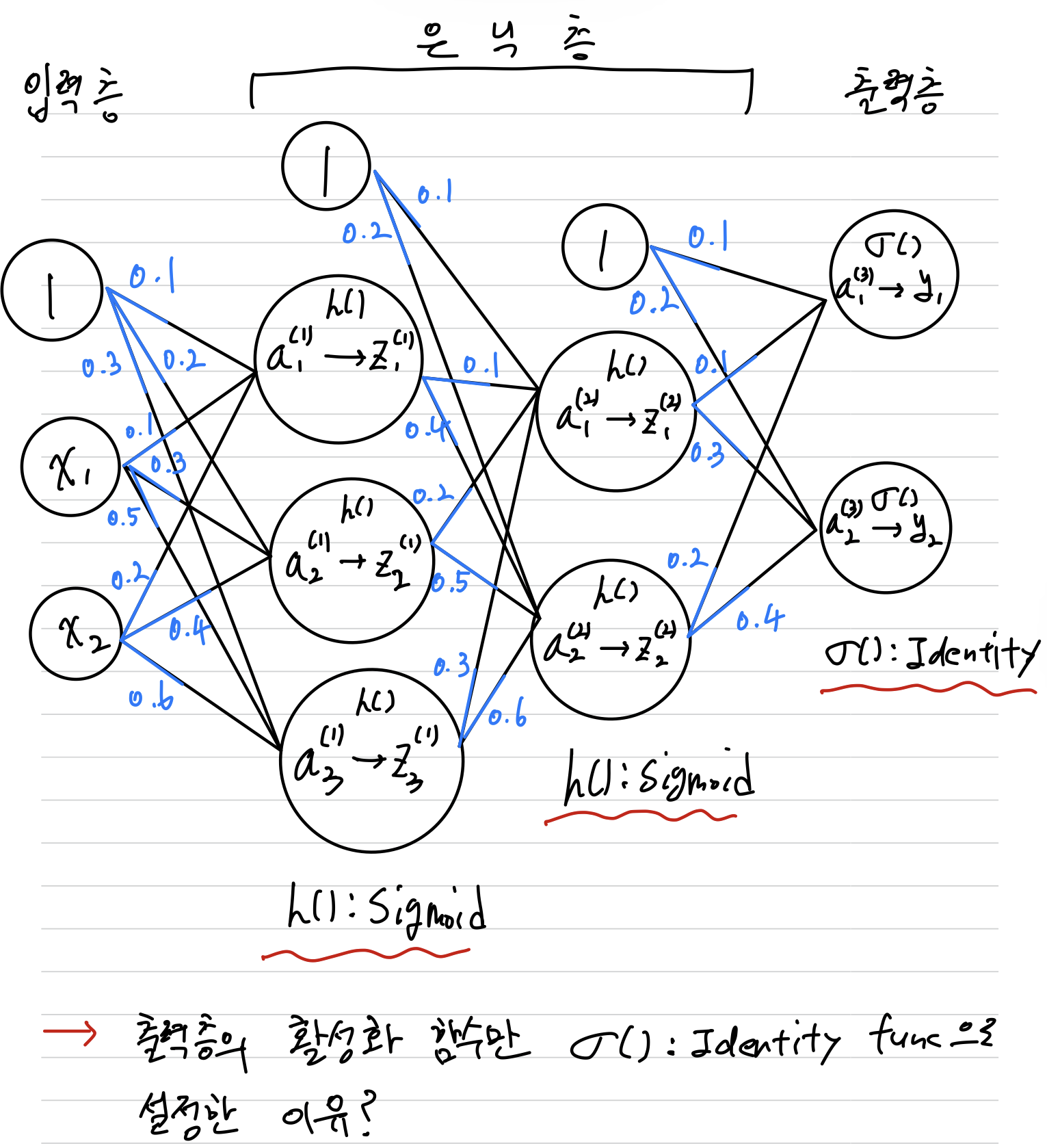
Hidden Layer의 Activation Function으로 Sigmoid Function을 사용했지만,
Output Layer의 Activation Function으로 Identity Function을 사용한 이유는
➡️ Output Layer의 Activation Function은 풀고자 하는 문제의 성질에 맞게 정한다. 회귀에는 Identity Function을, 2클래스 분류에는 Sigmoid Function을, 다중 클래스 분류에는 Softmax Function을 사용하는 것이 일반적이다.
간소화하여 코드 작성
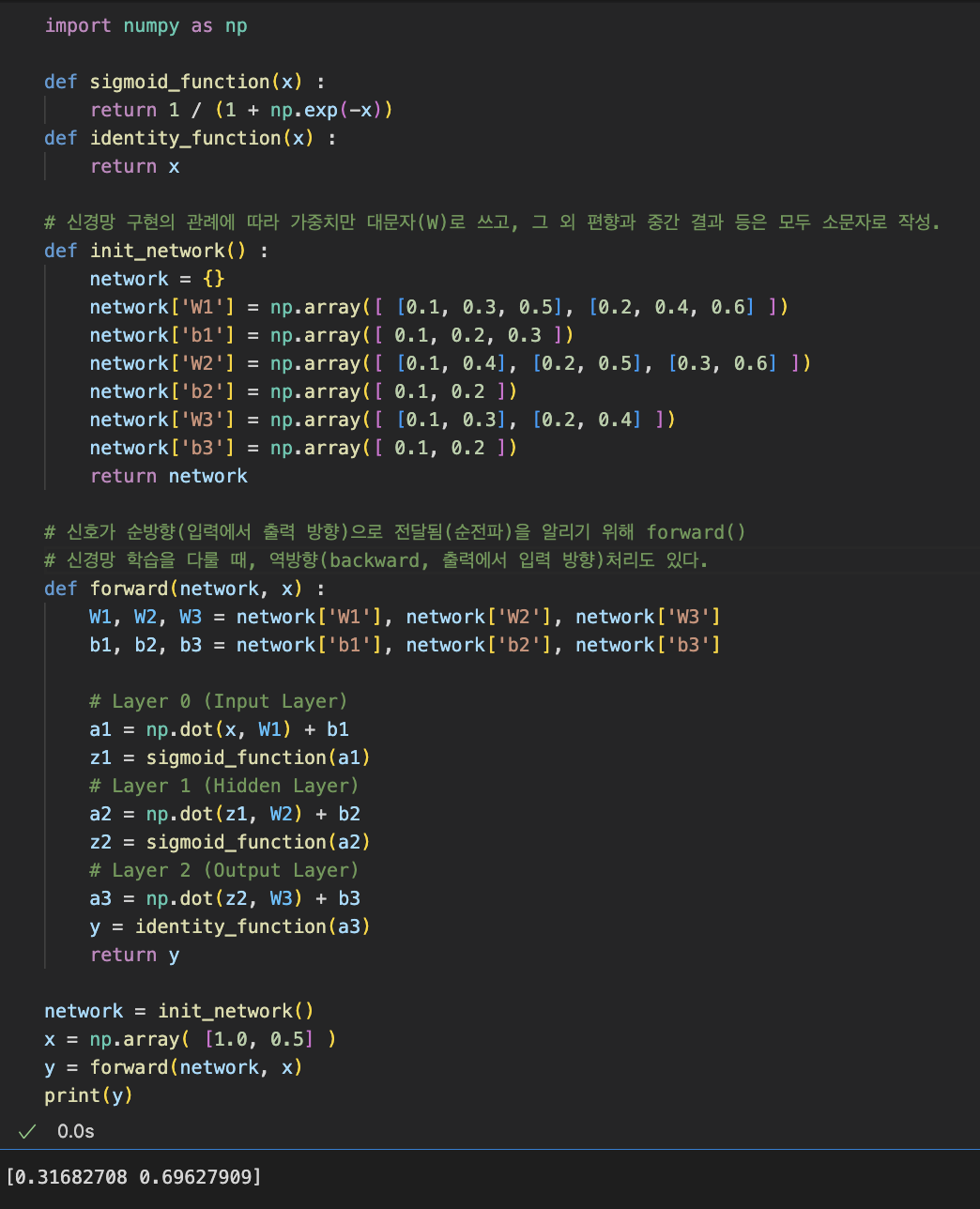
출력층 설계하기
신경망은 분류와 회귀 모두에 이용할 수 있다.
다만 둘 중 어떤 문제냐에 따라 출력층에서 사용하는 활성화 함수가 달라진다.
일반적으로 회귀에는 Identity Function을, 분류에는 Softmax Function을 사용한다.
Identity Function(항등함수)
Identity Function(항등 함수)는 입력을 그대로 출력한다. 입력과 출력이 항상 같다는 뜻의 항등이다.
Softmax Function
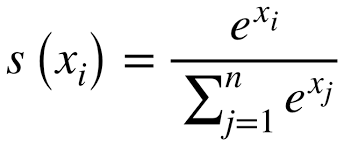
: 출력층의 뉴런 수
: 출력층의 뉴런 수 중 i번째 출력
Softmax Function의
분모는 모든 입력 신호의 지수 함수의 합으로 구성되고,
분자는 입력 신호 의 지수 함수로 구성된다.
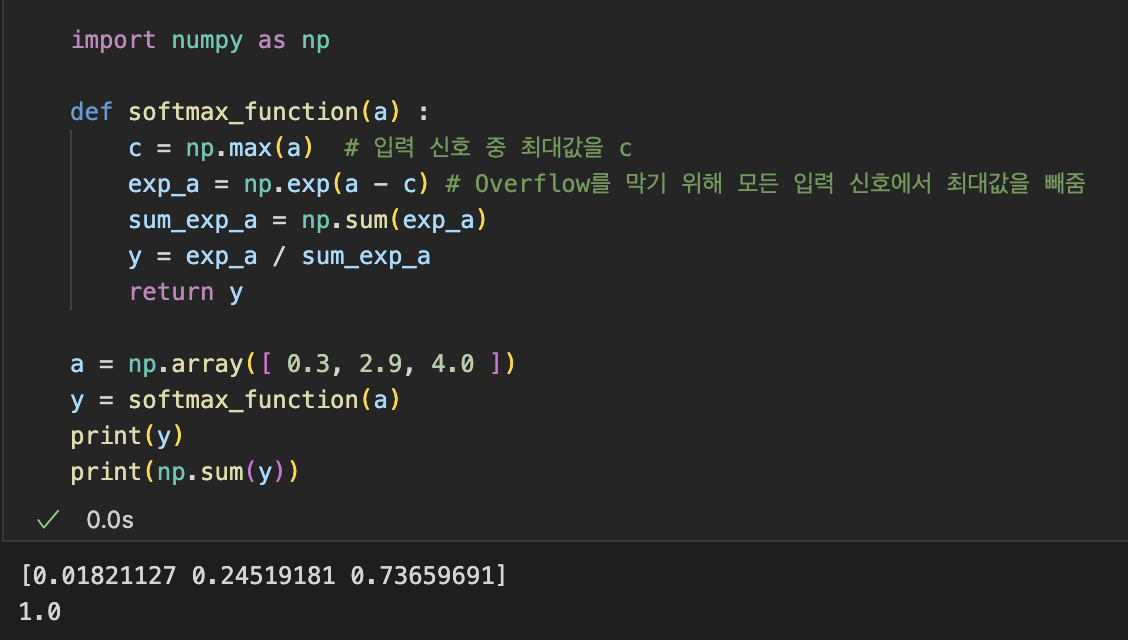
Softmax Function 구현 시 주의점
softmax() 함수를 코드로 작성할 때, Overflow 문제를 주의해야 한다.
Softmax Function은
Exponential(지수함수)를 사용하고 있기 때문에 아주 쉽게 매우 큰 값을 내뱉는다.
따라서 Overflow를 막기 위해서,
입력 신호 중 최댓값을 빼주면 올바르게 계산할 수 있다.
Softmax Function의 특징
- Softmax Function의 출력은 0~1.0 사이의 실수이다.
- Softmax Function의 출력의 총합은 1이다.
➡️ 이 성질로 인해, Softmax Function의 출력을확률로 해석할 수 있다.
Softmax Function Python 구현 코드의 결과에서
"73.6% 확률로 2번째 클래스, 24.5% 확률로 1번째 클래스, 1% 확률로 0번째 클래스다"와 같이 확률적인 결론을 낼 수 있다.
기계학습의 문제 풀이는 학습과 추론의 두 단계를 거쳐 이뤄진다.
학습 단계에서는 모델을 학습하고, 추론 단계에서는 모델로 미지의 데이터에 대해서 추론(분류)을 수행한다.
신경망을 학습시킬 때는 출력층에서 Softmax Function을 사용하지만, 추론 단계에서는 exp(지수함수)에 드는 자원 낭비를 줄이고자 출력층의 Softmax Function은 생략하는 것이 일반적이다.
출력층의 뉴런 수 정하기
출력층의 뉴런 수는 풀려는 문제에 맞게 적절히 정해야 한다.
분류에서는 분류하고 싶은 클래스 수로 설정하는 것이 일반적이다.
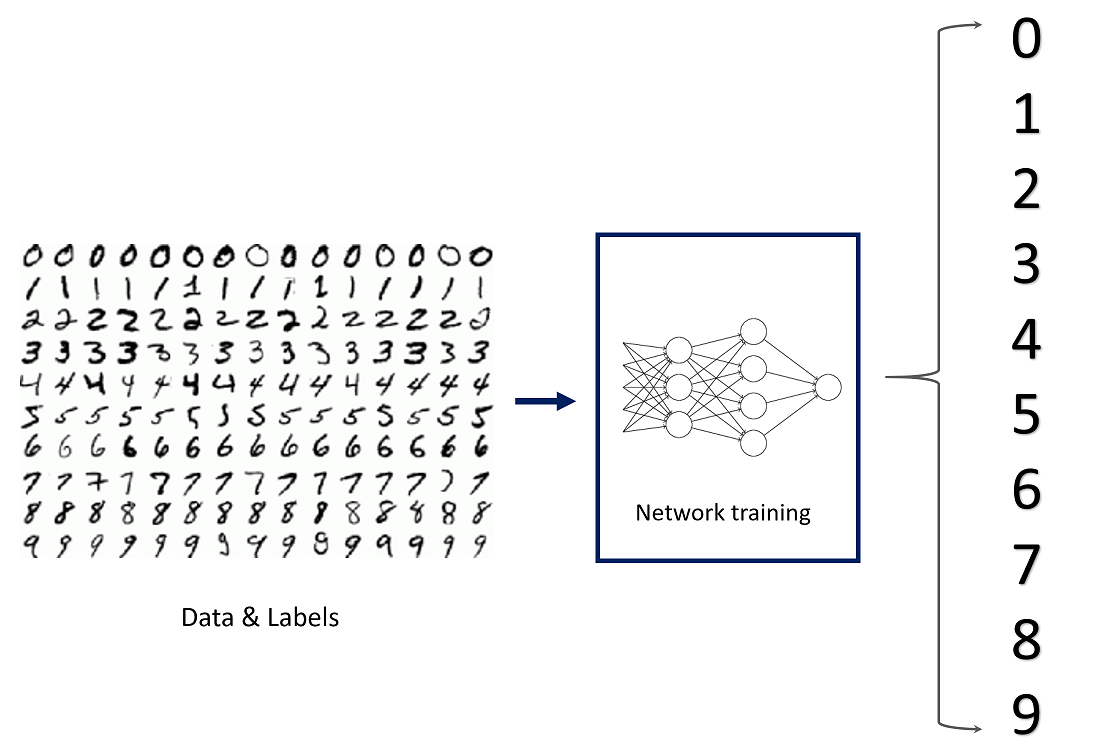
예를 들어, 입력 이미지를 0~9 중 하나로 분류하는 문제라면 위의 사진처럼 출력층의 뉴런을 10개로 설정한다.
손글씨 숫자 인식
- 이미 학습된 매개변수를 사용하여 학습 과정은 생략, 추론 과정만 구현.
- 이 추론 과정을 신경망의
순전파(forward propagation)라고 한다. - 기계학습과 마찬가지로 신경망도 두 단계를 거쳐 문제를 해결한다.
(학습 데이터를 사용해 가중치 매개변수를 학습, 추론 단계에서는 앞서 학습한 매개변수를 사용하여 입력 데이터를 분류.)
MNIST Dataset
- MNIST Image Dataset은 28*28 size의 회색조 이미지이며, 각 픽셀은 0~255까지 값을 갖는다.
- 훈련용 이미지 60,000장 / 테스트 이미지 10,000장
Loading Dataset
load_mnist() 함수의 인수로는
-
normalize: 입력 이미지의 픽셀값을 0.0~1.0 사이의 값으로 정규화할지를 결정. (bool)
True ➡️ 0.0 ~ 1.0
False ➡️ 0 ~ 255
(데이터를 특정 범위로 변환하는 처리를정규화(Normalization)라고 하고,
신경망의 입력 데이터에 특정 변환을 가하는 것을전처리(Preprocessing)이라고 한다.)- Preprocessing을 통해 식별 능력을 개선하고 학습 속도를 높이는 등의 사례가 많아지고 있다. 위에서는 255로 나누는 단순한 정규화를 수행했지만, 현업에서는 데이터 전체의 분포를 고려해 전처리하는 경우가 많다. 예를 들어 데이터 전체 평균과 표준편차를 이용하여 데이터들이 0을 중심으로 분포하도록 이동하거나 데이터의 확산 범위를 제한하는 정규화를 수행한다. 그 외에도 전체 데이터를 균일하게 분포시키는 데이터 백색화(Whitening) 등도 있다.
-
flatten: 입력 이미지를 평탄하게, 즉 1차원 배열로 만들지 결정. (bool)
True ➡️ 1차원 배열 형태로 (1 x 784)
False ➡️ 3차원 배열 (1 x 28 x 28) -
one_hot_label: one-hot encoding 형태로 저장할지를 결정.
(one-hot encodig은 [0,0,1,0,0]처럼 정답을 뜻하는 원소만 1이고 나머지는 모두 0인 배열.)
True ➡️ one-hot encoding하여 저장
False ➡️ '7'이나 '2'와 같이 숫자 형태의 레이블을 저장.

Batch 처리
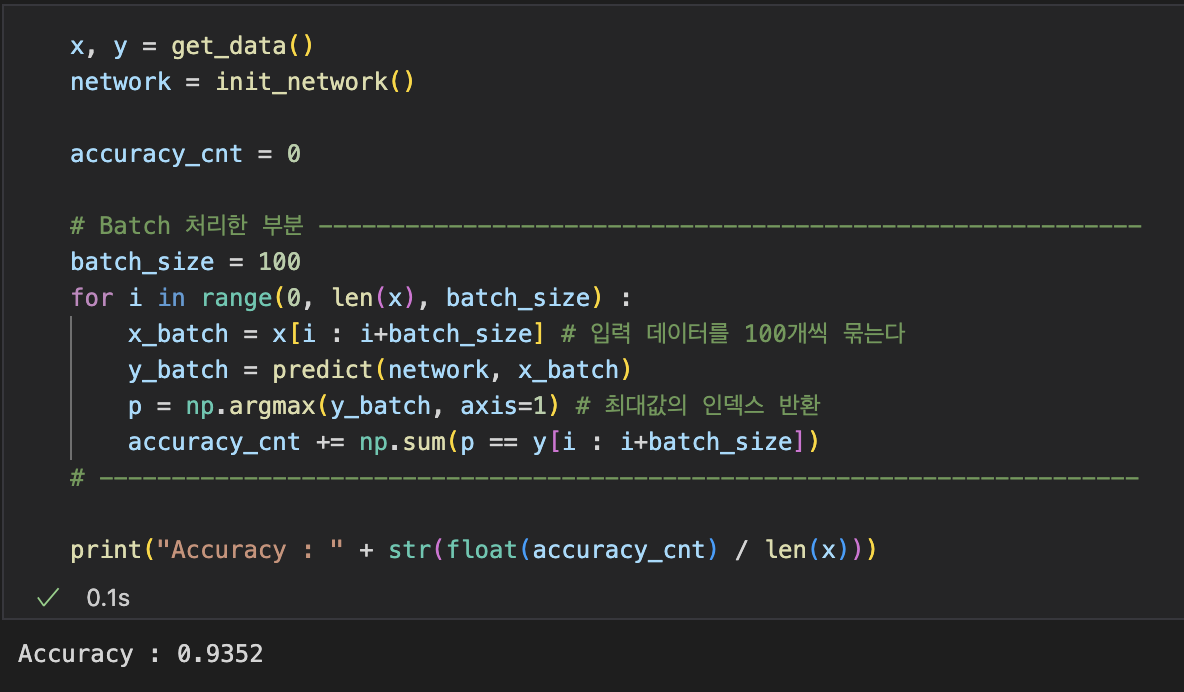
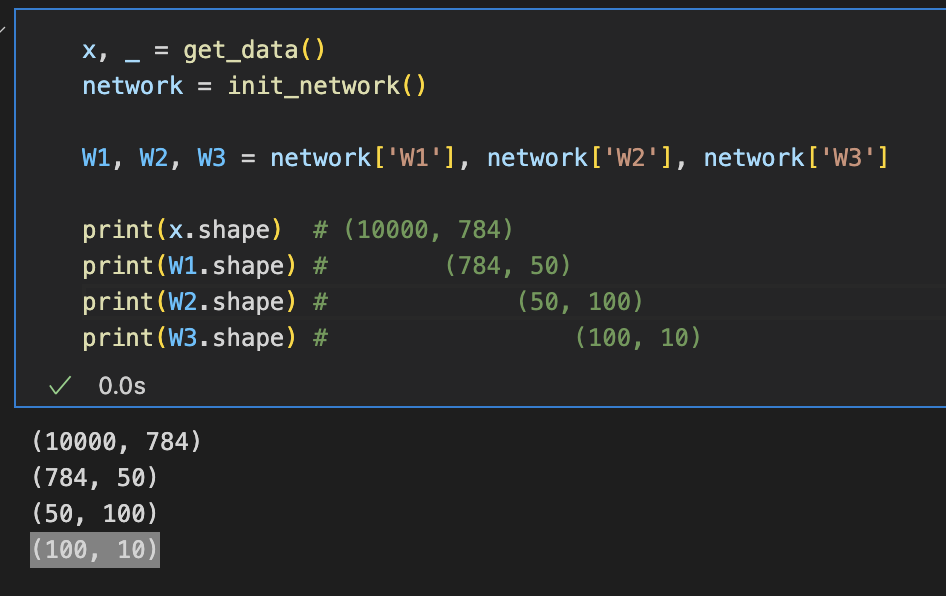
입력 데이터의 shape : 100 X 784, 출력 데이터의 shape : 100 X 10
이는 100장 분량 입력 데이터의 결과가 한 번에 출력됨을 나타낸다. --> 이처럼 하나로 묶은 입력 데이터를 배치(batch) 라고 한다.
Batch 처리의 장점
- 수치 계산 라이브러리 대부분이 큰 배열을 효율적으로 처리할 수 있도록 최적화되어 있기 때문
- 신경망에서는 데이터 전송이 병목으로 작용하는 경우가 자주 있는데, Batch 처리를 함으로써 버스에 주는 부하를 줄일 수 있다.
즉, 컴퓨터에서는 큰 배열을 한꺼번에 계산하는 것이 작은 배열을 여러 번 계산하는 것보다 빠르다.
정리
- 신경망에서는 Activation Function으로 Sigmoid Function과 ReLU 함수 같은 매끄럽게 변화하는 함수를 이용한다.
- Numpy 다차원 배열을 사용하여 신경망을 효율적으로 구현할 수 있다.
- 기계학습 문제는 회귀와 분류로 나뉜다.
- Output Layer의 Activation Function으로는 회귀에서는 주로 Identity Function을, 분류에서는 주로 Softmax Function을 이용한다.
- 입력 데이터를 묶은 것을 Batch라고 하며, 추론 처리를 이 Batch 단위로 진행하면 결과를 훨씬 빠르게 얻을 수 있다.
