
👉웹 크롤링
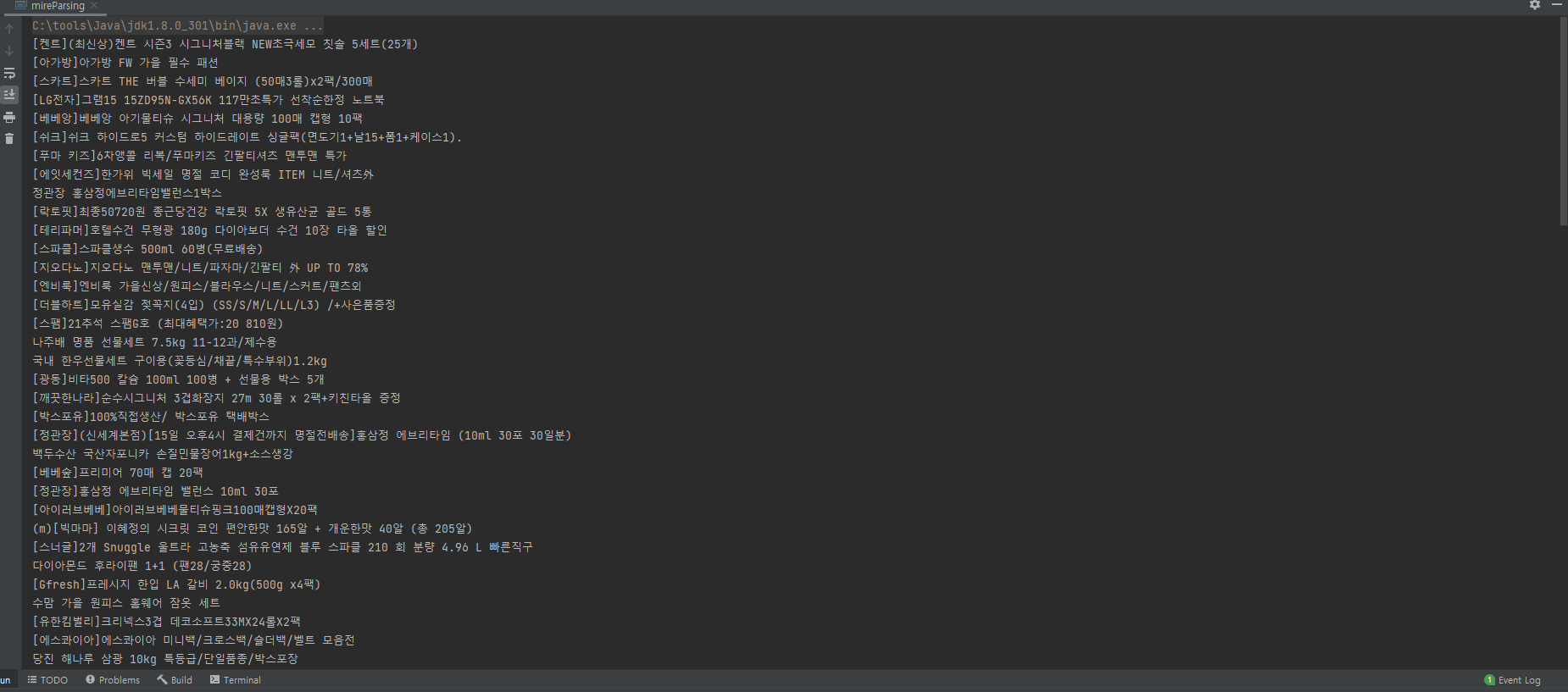
어제 알고리즘 공부에서 트리순회 쪽을 공부했는데 웹크롤링에 대해서 잠깐 집고 넘어갔으나 예제 말고 다른 사이트를 크롤링 해보았습니다. 첫번째는 지마켓 상품리스트입니다.
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.io.FileWriter;
import java.io.IOException;
public class mireParsing {
public static void main(String[] args) {
String url = "https://www.gmarket.co.kr/";
String selector1 = "div.box__information div.text__name";
Document doc = null;
try {
doc = Jsoup.connect(url).get();
} catch (IOException e){
System.out.println(e.getMessage());
}
Elements titles = doc.select(selector1);
for(Element element: titles){
System.out.println(element.text());
}
}
}
크롤링은 자기가 DOM 객체에 대한 작은 이해와 원하는 node를 현재 나의 코드에는 selector 부분에 잘 입력하면 문제없이 진행 될 것입니다. 하지만 이렇게 순탄하게 크롤링을 하던 도중 문제의 오류를 만나게 되었죠. 오류는 : Java PKIX path building failed 미래기술마당페이지링크를 크롤링하려 할 때 등장한 오류입니다.
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.io.IOException;
public class mireTextSave {
public static void main(String[] args){
String url = "https://rnd.compa.re.kr/total/saleTechResult.do";
String selector1 = "div.thmb3 a img";
Document doc = null;
try {
doc = Jsoup.connect(url).get();
} catch (IOException e){
System.out.println(e.getMessage());
}
Elements titles = doc.select(selector1);
for(Element element: titles){
System.out.println(element.attr("src").toString());
}
}
}
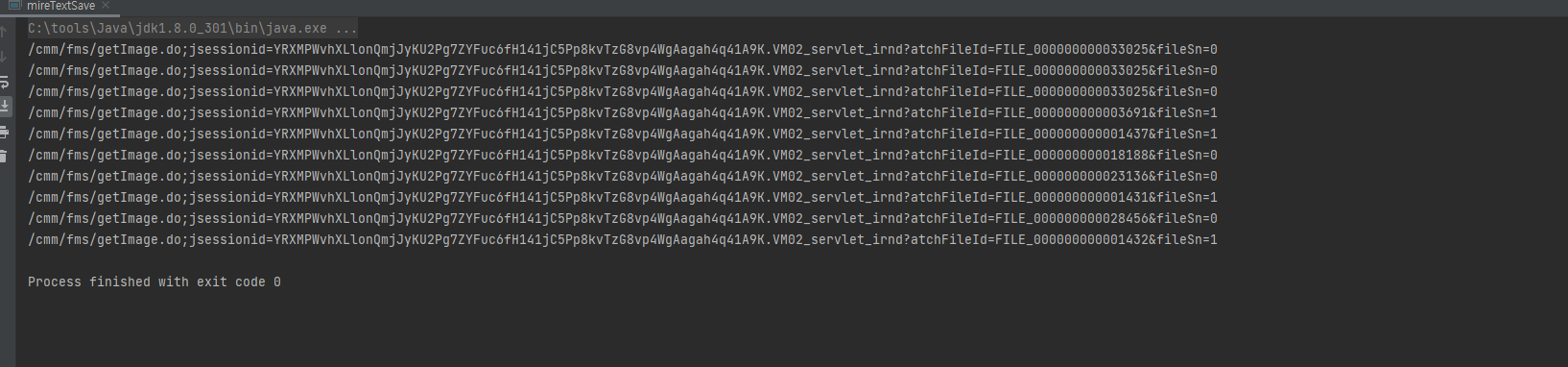
security.validator쪽에 걸려서 보안쪽 문제인가 라는 생각이 들어 구글링을 해보았습니다. 인증서가 있을 때의 해결 방법은 여러 곳에서 다루었지만 인증서가 없기에 이곳 저곳을 헤매이다 권진호님의 블로그에서 해답을 얻었습니다.
먼저 인증서가 있을 경우 :
인증서를 $JAVA_HOME/lib/security/cacerts (Java의 CAfile 저장소) 에 추가해 주면 됩니다. 이제 문제는 인증서가 없을 경우입니다.
인증서가 없을 경우(코드상 처리) :
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import javax.net.ssl.HttpsURLConnection;
import javax.net.ssl.SSLContext;
import javax.net.ssl.TrustManager;
import javax.net.ssl.X509TrustManager;
import java.io.IOException;
import java.security.KeyManagementException;
import java.security.NoSuchAlgorithmException;
import java.security.SecureRandom;
import java.security.cert.X509Certificate;
public class mireTextSave {
public static void main(String[] args) throws NoSuchAlgorithmException
,KeyManagementException {
String htmlUrl = "https://rnd.compa.re.kr/total/saleTechResult.do";
TrustManager[] trustAllCerts = new TrustManager[] {
new X509TrustManager() {
public X509Certificate[] getAcceptedIssuers() {
return null;
}
public void checkClientTrusted(X509Certificate[] certs, String authType) {}
public void checkServerTrusted(X509Certificate[] certs, String authType) {}
}
};
SSLContext sc = SSLContext.getInstance("SSL");
sc.init(null, trustAllCerts, new SecureRandom());
HttpsURLConnection.setDefaultSSLSocketFactory(sc.getSocketFactory());
//추가된 코드
String url = "https://rnd.compa.re.kr/total/saleTechResult.do";
String selector1 = "div.thmb3 a img";
Document doc = null;
try {
doc = Jsoup.connect(url).get();
} catch (IOException e){
System.out.println(e.getMessage());
}
Elements titles = doc.select(selector1);
for(Element element: titles){
System.out.println(element.attr("src").toString());
}
}
}위 코드의 추가된 코드처럼 처리하면 인증서없이 크롤링을 할 수 있었습니다.
👉parser
jsoup는 HTML문서를 자바가 알아볼 수 있게 만드는 parser입니다. parser에 대한 이해를 하기전에 Parsing에 대해 설명드리겠습니다.
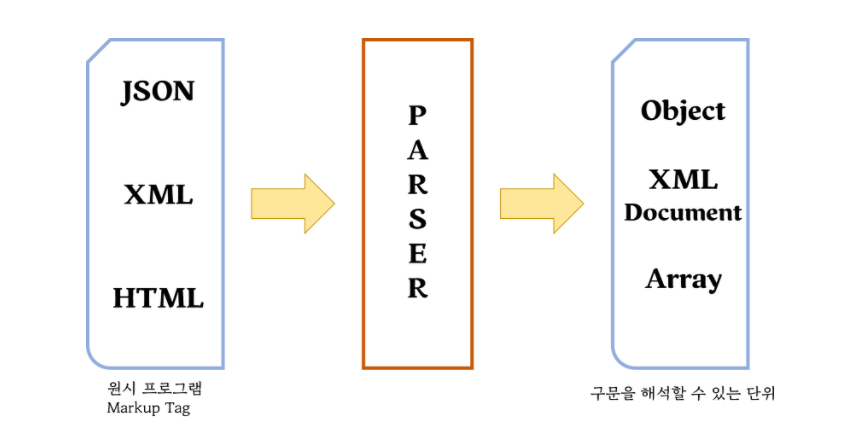
파싱위키백과링크의 사전적 의미는 구문분석이고 문장을 그것을 이루고 있는 구성 성분으로 분해하고 그들 사이의 위계 관계를 분석하여 문장의 구조를 결정하는 것을 말합니다. 컴퓨터과학에서 파싱은 일련의 문자열을 의미있는 토큰으로 분해하고 이들로 이루어진 파스 트리를 만드는 과정을 말합니다. 여기서 중요한 말은 분해입니다. 이렇게 데이터를 분해해서 가공할 수 있는 형태로 만드는 파싱과정을 파서가 합니다. 이러한 파서들은 Json, xml, html(원시 프로그램을 인터프리터, 컴파일러로)을 읽어드려서 여러 부분으로 해석해 파싱하는 역할을 합니다. 그림으로 보시면 다음과 같습니다.
예전에 api를 사용하려 했을 때 xml 형식의 데이터로 받아온 경우가 있었습니다. 그럴 때 xml을 parsing을 해주는 코드를 작성해서 사용했었는데 그 때에는 이러한 파싱에 개념도 제대로 모르고 사용했던 것 같습니다. 프로그래밍 공부는 정말 방대한 것 같습니다. 그래서 한번에 이해할 수 없는 것들이 너무 많은 것 같아요. 뭔가를 배우고 사용할 때 완벽하게 이해하고 사용할 수 없더라도 계속 공부를 하다보면 이러한 것들이 하나씩 채워지면서 느끼는 작은 행복감이 있는 것 같습니다. 너무 이해 안간다고 조바심은 내지 않고 차근차근 이해해간다면 언젠가는 큰 깨닳음이 있을거라 생각하고 계속 공부해야겠습니다.
