
ReLU Nonlinearity
일반적으로 뉴런의 출력 함수는 tanh(x)나 시그모이드 함수 f(x) = (1 + e^(-x))^(-1)와 같은 포화형 비선형 함수를 사용해왔지만,
이러한 함수는 경사하강법을 통한 학습 속도가 매우 느리다는 단점이 있다.
포화형 함수
함수의 입력 값이 너무 작거나 너무 크면, 출력 값이 어느 일정한 범위에 수렴(고정) 되어버리는 함수
| 함수 | 포화 여부 | 문제점 |
|---|---|---|
| Sigmoid, Tanh | 포화형 | 입력이 크거나 작으면 gradient 거의 0 |
| ReLU | 비포화형 | 학습 빠르고 gradient 잘 전달됨 |
그래서 f(x) = max(0, x) 형태의 학습 속도가 훨씬 빠른 ReLU (Rectified Linear Unit) 를 제안했다.
실제로 CIFAR-10 데이터셋에서 ReLU를 사용한 CNN은 같은 구조의 tanh 네트워크보다 훨씬 적은 반복 횟수로 25%의 훈련 오류율에 도달했다.
ReLU 외에도 다양한 대체 비선형 함수가 연구되어 왔다.
예를 들어 Jarrett 등은 f(x) = |tanh(x)| 함수가 특정 정규화 및 풀링 방식과 잘 맞는다고 주장했지만, 그 연구는 과적합 방지에 초점을 맞췄고, ReLU의 학습 속도 향상 효과와는 다르다.
ReLU를 쓰면 학습이 훨씬 빨라서 대규모 모델 학습이 가능해졌다.
→ CNN 발전에 중요한 역할
<출처: Alex Krizhevsky et al., "ImageNet Classification with Deep Convolutional Neural Networks", NeurIPS 2012>
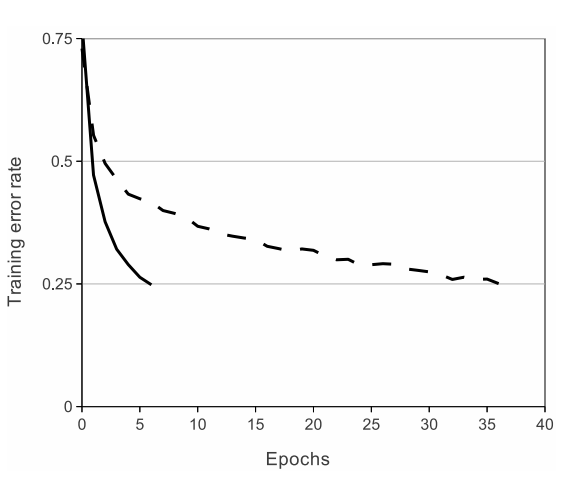
그래프는 ReLU를 사용한 4층 CNN(실선)이, tanh 함수를 사용한 동일한 구조의 CNN(점선)보다 CIFAR-10 데이터셋에서 훈련 오류율 25%에 도달하는 속도가 6배 빠르다는 것을 보여준다.
이러한 ReLU의 효과는 네트워크 구조에 따라 정도의 차이는 있지만, 전반적으로 항상 포화형 함수(tanh 등)를 쓴 모델보다 훨씬 더 빠르게 학습된다고 한다.
Training on Multiple GPUs
GTX 580 GPU 한 개는 메모리가 3GB밖에 되지 않아, 큰 신경망을 학습시키기엔 부족하다.
학습 데이터셋으로 주어지는 120만장의 이미지는 모델을 학습시키기에 충분한 양이었지만, 그 개수와 크기는 GPU가 감당할 수가 없었다고 한다.
그래서 저자들은 두개의 GPU에 네트워크를 분산시켰다.
병렬화 방식 (두 GPU 분할 구조)
네트워크의 절반 뉴런(커널)을 각 GPU에 배치하고, 일부 레이어에서만 통신하도록 설계했다.
예)
| 계층 | GPU 간 통신 여부 | 이유 |
|---|---|---|
| 3층 | 있음 (두 GPU가 서로 데이터를 공유함) | 3층의 뉴런은 2층의 모든 출력을 다 받아야 하므로 |
| 4층 | 없음 (GPU 내부에서만 데이터 사용) | 4층의 뉴런은 같은 GPU에 있는 3층 뉴런 출력만 사용 |
→ 통신량을 제한하면서도 계산량은 유지하여 효율적으로 병렬 처리한다.
이러한 구조는 Cire¸san 등의 columnar CNN과 유사하지만, 완전히 독립적이지 않고 GPU 간 연결이 있다.
Local Response Normalization
ReLU는 포화하지 않기 때문에 입력 정규화가 필수는 아니다.
ReLU는 양수 입력만 있으면 학습이 가능해서, 일반적으로는 입력 정규화를 하지 않아도 된다.
하지만 일종의 정규화(normalization)를 적용하면 일반화 성능이 더 좋아짐을 발견했다.
정규화 방식
각 뉴런의 출력값 를 정규화하여 로 바꾼다.
𝑖 : 커널 번호
(x,y) : 공간 위치
N : 해당 레이어의 전체 커널 수
𝑛 : 동일한 공간 위치에 있는 인접한 커널 맵 수
k, α, β: 하이퍼파라미터
논문에서는 각 값을 k=2, n=5, α=, β = 0.75 로 설정
LRN은 인접한 채널끼리의 출력값을 정규화(normalize)하여 경쟁을 유도하는 방식이다.
ReLU는 음수를 0으로 만들기 때문에, 양의 값이 계속 쌓이면 특정 뉴런이 너무 커지는 현상이 생긴다.
LRN은 뉴런끼리 경쟁하게 만들어서 특정 뉴런이 독점적으로 커지는 것을 방지한다.
LRN은 top-1과 top-5 error rate를 각각 1.4%와 1.2%까지 줄었다고 한다.
4계층 CNN은 정규화 없이는 13%의 테스트 오류율을 달성했고, 정규화를 통해 11%의 테스트 오류율을 달성했다고 한다.
Overlapping Pooling
Pooling Layer는 같은 커널 맵 안에서 인접한 뉴런들의 출력을 요약한다.
기존 CNN에서는 풀링 영역이 서로 겹치지 않도록 구성했다. (예: stride = 2, kernel size = 2).
z × z : 풀링 영역의 크기 (예: 3×3)
s : 풀링 단위 간의 간격 =stride
s = z이면, 겹치지 않는(non-overlapping) 풀링
s < z이면, 겹치는(overlapping) 풀링
본 논문에서는 s = 2, z = 3을 사용함 → 겹치는 풀링 적용
겹치는 풀링(overlapping pooling)을 사용했더니
Top-1 오류율이 0.4% 감소, Top-5 오류율이 0.3% 감소하였고,
과적합(overfitting)이 덜 발생하였다고 한다.
Overall Architecture
전체 구성
총 8개의 학습 가능한 레이어로 구성
- 5개: Convolutional Layer (합성곱 층)
- 3개: Fully-connected Layer (완전 연결 층)
마지막 레이어는 1000개 클래스에 대한 Softmax 출력으로 이어진다.
- 다항 로지스틱 회귀(Multinomial Logistic Regression)를 최대화
- 예측 분포에서 정답 라벨의 로그 확률을 평균적으로 최대화
| 층 | 설명 |
|---|---|
| Conv1 | 227×227×3 입력 이미지 → 11×11×3 커널 96개 사용 |
| ReLU | 모든 Conv 및 FC 레이어에 ReLU 적용 |
| Norm1 + MaxPool1 | Conv1 이후 Local Response Normalization + MaxPooling |
| Conv2 | 256개의 5×5×48 커널 사용 (입력은 Conv1의 정규화 + 풀링 출력) |
| Norm2 + MaxPool2 | Conv2 이후 Local Response Normalization + MaxPooling |
| Conv3 | 384개의 3×3×256 커널 |
| Conv4 | 384개의 3×3×192 커널 (이전과 GPU 분할 적용) |
| Conv5 | 256개의 3×3×192 커널 |
| MaxPool3 | Conv5 이후 MaxPooling 적용 |
| FC1, FC2 | Fully-connected layer: 각 4096 뉴런 |
| FC3 (출력) | 1000개의 클래스에 대한 Softmax 출력 |
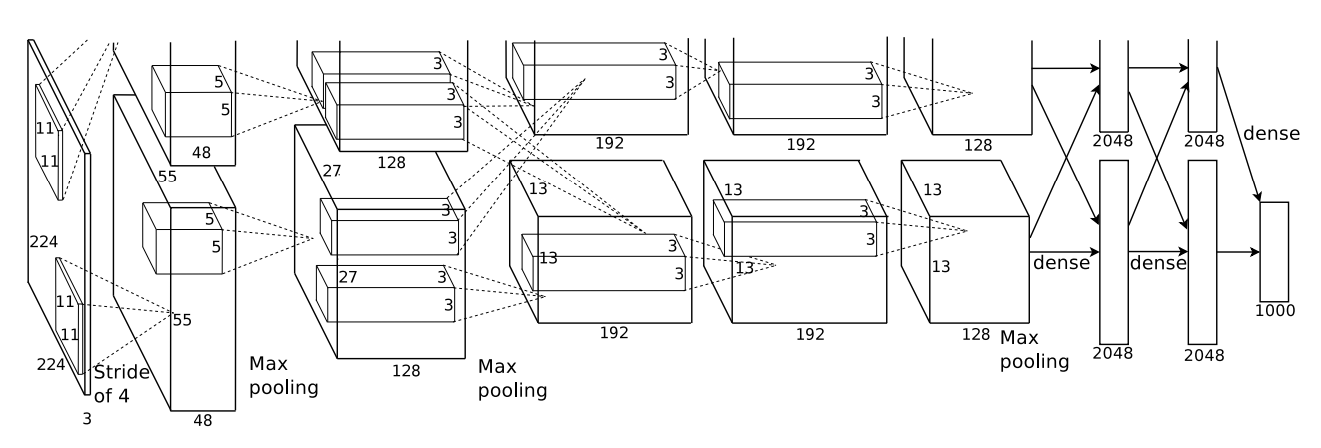
이 그림을 보면 GPU 2개를 사용하여 병렬 처리를 하고 있는데,
하나의 GPU는 그림의 위쪽 층들을, 다른 하나의 GPU는 아래쪽 층들을 담당한다.
두 GPU는 일부 특정 층에서만 통신을 주고받는다.
GPU 병렬 처리
- Conv2, Conv4, Conv5: 같은 GPU에 있는 커널 맵에만 연결
- Conv3: 이전 층의 모든 커널 맵과 연결
- FC 층들: 모든 뉴런이 이전 층의 모든 뉴런과 연결
Data Augmentation
AlexNet은 파라미터 수가 많아 과적합 위험이 크다.
이를 줄이기 위해 데이터 증강(Data Augmentation)을 사용하였다.
데이터 증강은 원본 이미지를 다양한 방식으로 변형하지만 레이블(정답)은 그대로 유지하는 방식이다.
이미지 증강은 CPU에서 실시간 처리되고, GPU는 학습을 계속 진행하여 추가 연산 부담 없다고 한다.
두 가지 데이터 증강 방식
1. 수평 반전 (= 좌우 반전)
256×256 이미지에서 랜덤으로 224×224 크롭해서 사용한다.
이 크롭된 이미지의 좌우 반전 이미지도 추가로 사용한다.
이런 방식으로 데이터셋 크기를 2048배로 증가시킨다.
다만 크롭된 이미지는 원본과 연관성이 높아 완전히 독립적인 샘플은 아니다.
테스트 시에는 5개의 위치(4 모서리 + 중앙)에서 크롭된 이미지와 그 이미지들의 수평 반전까지 포함해 총 10개의 패치로 예측한 후 평균을 낸다. → 성능 향상
2. RGB 색상 왜곡 (PCA 색상 증강)
이미지 전체 RGB 픽셀 값을 이용해 PCA(주성분 분석)를 수행한다.
각 이미지에 대해 주성분 방향으로 색상 밝기 조정한다.
이미지에 조명 변화, 색상 변화를 인위적으로 적용한다.
[p₁, p₂, p₃] · [α₁λ₁, α₂λ₂, α₃λ₃]ᵀ
- pᵢ : RGB 픽셀의 주성분 방향
- λᵢ : 대응하는 고유값
- αᵢ : 평균 0, 표준편차 0.1인 정규분포에서 샘플링한 값
이 방법은 조명과 색상 변화에도 객체를 인식할 수 있도록 돕는 자연스러운 변형이다.
결과적으로 Top-1 오류율이 1% 이상 감소하였다고 한다.
Dropout
Dropout은 학습 중 일부 뉴런을 무작위로 꺼서 과적합을 줄이고,
테스트에서는 모든 뉴런을 평균적으로 반영하는 방식으로 일반화 성능을 높이는 기법이다.
AlexNet에서는 드롭아웃이 1번째와 2번째 Fully connected 레이어에 적용되어 있다.
드롭아웃이 없다면 과적합이 심하게 발생한다고 한다.
단점이 있다면, 드롭아웃을 쓰면 학습 수렴 시간이 약 2배 늘어난다고 한다.
Details of learning
옵티마이저 설정
- 최적화 방식: 확률적 경사 하강법(SGD)
- 배치 크기: 128
- 모멘텀(momentum): 0.9
- 가중치 감쇠(weight decay): 0.0005
초기화 설정
- 가중치 초기화: 평균 0, 표준편차 0.01인 정규분포에서 샘플링
- Bias 초기화:
- Conv2, Conv4, Conv5, FC(hidden) 층: 1로 초기화
- 그 외 나머지 층: 0으로 초기화
학습률(learning rate) 설정
- 초기값: 0.01
- 검증 오차가 더 이상 개선되지 않을 때, 학습률을 1/10로 감소한다.
- 학습 중 총 3번 감소하게 된다.
학습 시간
- 전체 학습 데이터: 약 120만 장
- 총 학습 epoch: 약 90번 반복
- 학습 소요 시간: 약 5~6일 소요
- 사용 GPU: NVIDIA GTX 580 (3GB) 2개
Results
AlexNet은 ILSVRC-2010과 2012 대회에서 기존 모델들보다 10% 이상 낮은 오류율을 기록하며 이미지 분류 분야에 획기적인 성능 향상을 가져왔다.
- 학습된 합성곱 커널을 보면, 다양한 주파수 및 방향성 필터, 컬러 블롭(덩어리) 등을 학습했음을 확인할 수 있다.
- GPU 1의 커널: 색상과 무관한 필터 중심 (무채색)
- GPU 2의 커널: 색상에 민감한 필터 중심
-
다양한 테스트 이미지에 대해 Top-5 예측 결과를 확인할 수 있다.
-
CNN의 마지막 FC 은닉층(4096차원) 출력 벡터를 사용해 이미지 간 유사도를 계산한다.
유클리디안 거리가 가까울수록 네트워크는 두 이미지를 의미적으로 유사하다고 판단하여 실제로 픽셀이 달라도 의미상 유사한 이미지들을 잘 찾아낸다. -
오토인코더로 벡터를 이진 코드로 압축하면 훨씬 더 빠르고 효율적인 의미 기반 이미지 검색이 가능하다.
→ 원시 픽셀 기반 방식보다 훨씬 정확한 검색 결과를 제공할 수 있다.
