
AlexNet 구현
ImageNet Classification with Deep CNNs 논문 구조 참고
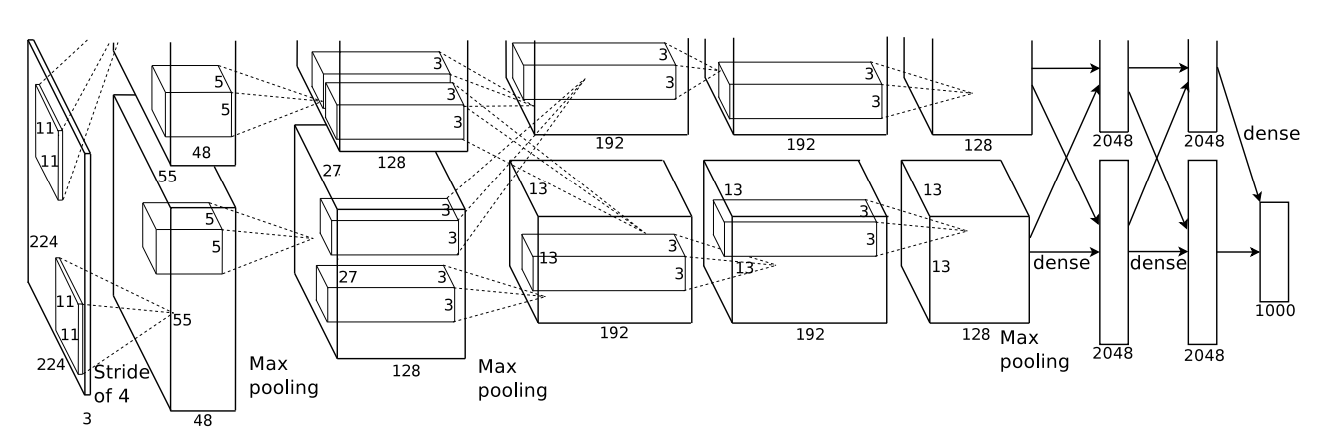
class AlexNet(nn.Module):
def __init__(self, num_classes):
super(AlexNet, self).__init__()
self.features = nn.Sequential(
nn.Conv2d(3, 96, kernel_size=11, stride=4, padding=0),
nn.ReLU(inplace=True),
nn.LocalResponseNorm(5, alpha=1e-4, beta=0.75, k=2),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(96, 256, kernel_size=5, stride=1, padding=2),
nn.ReLU(inplace=True),
nn.LocalResponseNorm(5, alpha=1e-4, beta=0.75, k=2),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(256, 384, kernel_size=3, stride=1, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(384, 384, kernel_size=3, stride=1, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(384, 256, kernel_size=3, stride=1, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2)
)
self.classifier = nn.Sequential(
nn.Dropout(0.5),
nn.Linear(256 * 6 * 6, 4096),
nn.ReLU(inplace=True),
nn.Dropout(0.5),
nn.Linear(4096, 4096),
nn.ReLU(inplace=True),
nn.Linear(4096, num_classes)
)
def forward(self, x):
x = self.features(x)
x = x.view(x.size(0), 256 * 6 * 6)
x = self.classifier(x)
return xAlexNet 입력 사이즈: 224 vs 227
논문에서는 224×224?
AlexNet 논문인
ImageNet Classification with Deep Convolutional Neural Networks (Krizhevsky et al., 2012)의 Figure 2에서는 입력 이미지의 크기를 다음과 같이 설명하고 있다.
"The input images in Figure 2 are 224 × 224 × 3-dimensional."
하지만, 사실은 227×227이 맞다!
논문 저자들이 공개한 실제 구현 코드와 실험 로그에 따르면, 입력 사이즈는 227 × 227 × 3이 맞지만, 이후에 커뮤니티와 논문 발표 자료에서 저자들이 직접 오류를 인정하고 정정한 내용이라고 한다.
왜 227이 맞는가? (계산 근거)
합성곱 신경망(CNN, Convolutional Neural Network)에서 합성곱(convolution) 연산 후 출력 feature map의 크기를 계산하는 공식은 다음과 같다.
𝐼: 입력 이미지의 크기 (예: 가로 또는 세로 길이)
𝐾: 커널(필터)의 크기 (예: 3이면 3x3 필터)
𝑃: 패딩(Padding)의 크기
𝑆: 스트라이드(Stride)의 크기
1 번째 Convolution 레이어는 다음과 같은 구조를 가진다.
커널 크기: 11 × 11
스트라이드: 4
패딩: 0
이 조건에서 입력 이미지가 227 × 227일 때만 출력 크기가 정수가 된다.
Output = ((227 - 11) / 4) + 1 = (216 / 4) + 1 = 54 + 1 = 55
→ 출력 Feature Map: 55 × 55
이 값이 다음 레이어들과 정확하게 연결된다.
반면, 224 입력을 사용할 경우:
Output = ((224 - 11) / 4) + 1 = 53.25 + 1 = 54.25 ❌ (소수점)
→ 불완전한 출력 크기 발생 → 레이어 연결 오류 또는 정합성 문제 발생 가능
따라서 AlexNet 모델을 구현할 때는 논문 이미지에 나와 있는 224 × 224가 아닌,
정확한 논문 구현을 따르기 위해 227 × 227 크기의 입력 이미지를 사용해야한다.
1 번째 Convolution 레이어에서 가로와 세로의 크기가 55이며 채널의 수는 커널의 개수인 96으로 설정되어 55 x 55 x 96의 결과를 얻어낼 수 있다.
하지만 총 2개의 GPU를 사용하여 커널을 절반으로 나누어 가져 가기 때문에 하나의 GPU는 55 x 55 x 48 의 결과를 받는다.
다음은 큰 값이 주변에 영향을 주지 못하도록 하는 Response Normalization을 진행하고 stride(2), kernel(3x3) 의 Max Pooling을 진행한다.
Output = ((55 - 3) / 2) + 1 = 27
→ 출력 Feature Map: 27 × 27
| Layer | 입력 크기 | 커널 크기 / 개수 | Stride / Pad | 출력 크기 | 활성화 & 정규화 | Pooling 결과 |
|---|---|---|---|---|---|---|
| Conv1 | 227×227×3 | 11×11×3 / 96 | 4 / 0 | 55×55×96 | ReLU, LRN | 27×27×96 |
| Conv2 | 27×27×96 | 5×5×48 / 256 | 1 / 2 | 27×27×256 | ReLU, LRN | 13×13×256 |
| Conv3 | 13×13×256 | 3×3×256 / 384 | 1 / 1 | 13×13×384 | ReLU | 없음 |
| Conv4 | 13×13×384 | 3×3×192 / 384 | 1 / 1 | 13×13×384 | ReLU | 없음 |
| Conv5 | 13×13×384 | 3×3×192 / 256 | 1 / 1 | 13×13×256 | ReLU | 6×6×256 |
| Layer | 입력 크기 | 출력 크기 | 활성화 함수 | Dropout |
|---|---|---|---|---|
| FC1 | 6×6×256 = 9216 | 4096 | ReLU | O |
| FC2 | 4096 | 4096 | ReLU | O |
| FC3 | 4096 | 1000 | 없음 | X |
| Softmax | - | 1000 | Softmax | - |
전체 구조 간략 흐름 (Conv → FC)
입력 이미지: 227×227×3
↓
Conv1 → ReLU → Norm → Pool → 27×27×96
↓
Conv2 → ReLU → Norm → Pool → 13×13×256
↓
Conv3 → ReLU
↓
Conv4 → ReLU
↓
Conv5 → ReLU → Pool → 6×6×256
↓
Flatten → 9216차원
↓
FC1 (4096) → ReLU → Dropout
↓
FC2 (4096) → ReLU → Dropout
↓
FC3 (1000)
↓
Softmax → 클래스 확률
