
ResNet 구현
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
from torch.utils.data import DataLoaderCIFAR-10 데이터셋 로딩
transform = transforms.Compose([
transforms.RandomHorizontalFlip(),
transforms.RandomCrop(32, padding=4),
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465),
(0.2023, 0.1994, 0.2010))
])
trainset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=128, shuffle=True, num_workers=2)
testset = torchvision.datasets.CIFAR10(root='./data', train=False, download=True, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=100, shuffle=False, num_workers=2)BasicBlock 정의
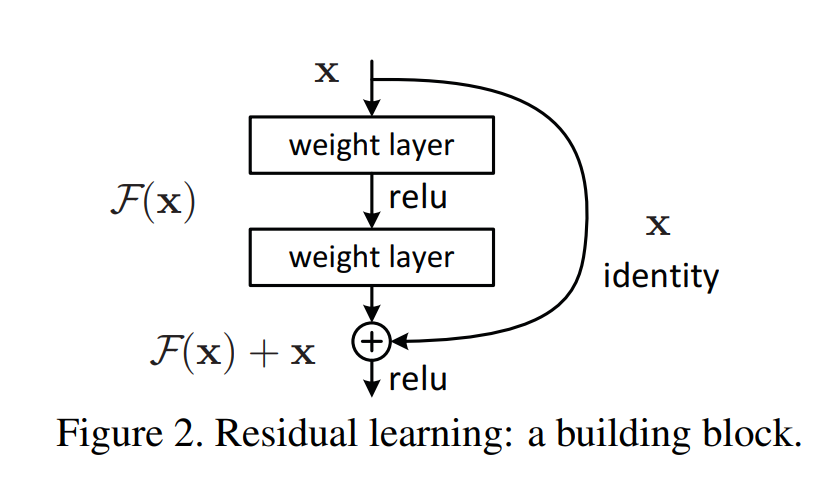
conv1: 첫 번째 3x3 Conv (stride로 크기 조절 가능)
bn1: 첫 번째 BatchNorm
conv2: 두 번째 3x3 Conv
bn2: 두 번째 BatchNorm
identity: 입력x(skip 연결용)
downsample: 입력과 출력 크기가 다를 경우 사용되는 1x1 Conv
expansion: 출력 채널 확장 비율 (BasicBlock은 1)
forward()흐름 : Conv → BN → ReLU → Conv → BN → +skip → ReLU
class BasicBlock(nn.Module):
expansion = 1 # 출력 채널 수 확장 배수 (ResNet-18/34에서는 1)
def __init__(self, in_channels, out_channels, stride=1, downsample=None):
super(BasicBlock, self).__init__()
self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=3,
stride=stride, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(out_channels)
self.relu = nn.ReLU(inplace=True)
self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3,
stride=1, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(out_channels)
self.downsample = downsample
def forward(self, x):
# skip 연결을 위한 identity 저장
identity = x
if self.downsample is not None:
identity = self.downsample(x)
out = self.relu(self.bn1(self.conv1(x)))
out = self.bn2(self.conv2(out))
out += identity # residual connection (skip)
out = self.relu(out)
return outResNet 클래스 정의
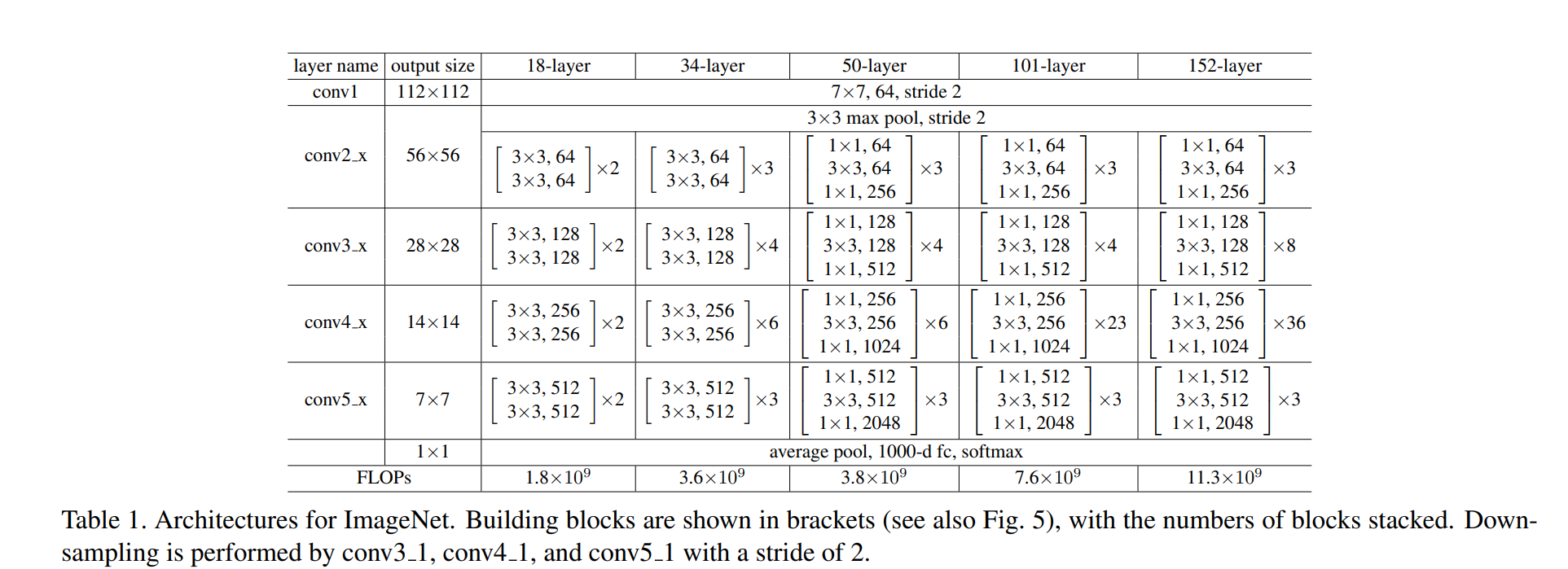
CIFAR-10의 이미지 크기: 32×32
처음부터 7×7, stride=2로 줄이면 너무 빨리 정보가 줄어들고 손실이 크다.
논문에서도 CIFAR-10 실험에서는 3×3, stride=1 사용했다고 명시되어 있다.
class ResNet(nn.Module):
def __init__(self, block, layers, num_classes=10):
super(ResNet, self).__init__()
self.in_channels = 64
self.conv1 = nn.Conv2d(3, 64, kernel_size=3, stride=1, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(64)
self.relu = nn.ReLU(inplace=True)
self.layer1 = self._make_layer(block, 64, layers[0])
self.layer2 = self._make_layer(block, 128, layers[1], stride=2)
self.layer3 = self._make_layer(block, 256, layers[2], stride=2)
self.layer4 = self._make_layer(block, 512, layers[3], stride=2)
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Linear(512 * block.expansion, num_classes)
def _make_layer(self, block, out_channels, blocks, stride=1):
downsample = None
if stride != 1 or self.in_channels != out_channels * block.expansion:
# shortcut 에서 입력 x를 F(x)의 출력 크기와 같게 만들어주기 위한 처리
# 크기가 다르거나 채널 수가 다르면 그냥 더할 수 없기 때문
downsample = nn.Sequential(
# 1x1 Convolution: 입력 채널 → 출력 채널로 변환하고, stride를 적용해 크기도 맞춤
nn.Conv2d(self.in_channels, out_channels * block.expansion,
kernel_size=1, stride=stride, bias=False),
# Batch Normalization: 정규화로 학습 안정화
nn.BatchNorm2d(out_channels * block.expansion),
)
layers = []
layers.append(block(self.in_channels, out_channels, stride, downsample))
self.in_channels = out_channels * block.expansion
for _ in range(1, blocks):
layers.append(block(self.in_channels, out_channels))
return nn.Sequential(*layers)
def forward(self, x):
x = self.relu(self.bn1(self.conv1(x)))
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.fc(x)
return xResNet-18 or ResNet-34 선택
def ResNet18():
return ResNet(BasicBlock, [2, 2, 2, 2])
def ResNet34():
return ResNet(BasicBlock, [3, 4, 6, 3])학습 & 평가 함수 정의
train_losses = []
test_accuracies = []
def train(model, device, trainloader, optimizer, criterion, epoch):
model.train()
running_loss = 0.0
for inputs, targets in trainloader:
inputs, targets = inputs.to(device), targets.to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, targets)
loss.backward()
optimizer.step()
running_loss += loss.item()
avg_loss = running_loss / len(trainloader)
train_losses.append(avg_loss)
print(f"Epoch {epoch} - Loss: {avg_loss:.4f}")
def test(model, device, testloader):
model.eval()
correct = 0
total = 0
with torch.no_grad():
for inputs, targets in testloader:
inputs, targets = inputs.to(device), targets.to(device)
outputs = model(inputs)
_, predicted = torch.max(outputs.data, 1)
total += targets.size(0)
correct += (predicted == targets).sum().item()
acc = 100. * correct / total
test_accuracies.append(acc)
print(f"Test Accuracy: {acc:.2f}%")학습 실행
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = ResNet18().to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.1, momentum=0.9, weight_decay=5e-4)
for epoch in range(1, 21):
train(model, device, trainloader, optimizer, criterion, epoch)
test(model, device, testloader)Epoch 1 - Loss: 1.8159
Test Accuracy: 41.33%
Epoch 2 - Loss: 1.3742
Test Accuracy: 54.24%
Epoch 3 - Loss: 1.0897
Test Accuracy: 60.59%
Epoch 4 - Loss: 0.9244
Test Accuracy: 61.79%
Epoch 5 - Loss: 0.7831
Test Accuracy: 73.11%
Epoch 6 - Loss: 0.6663
Test Accuracy: 70.32%
Epoch 7 - Loss: 0.6057
Test Accuracy: 76.06%
Epoch 8 - Loss: 0.5549
Test Accuracy: 75.32%
Epoch 9 - Loss: 0.5326
Test Accuracy: 76.56%
Epoch 10 - Loss: 0.5069
Test Accuracy: 73.87%
Epoch 11 - Loss: 0.4839
Test Accuracy: 80.96%
Epoch 12 - Loss: 0.4724
Test Accuracy: 79.57%
Epoch 13 - Loss: 0.4548
Test Accuracy: 81.89%
Epoch 14 - Loss: 0.4430
Test Accuracy: 78.55%
Epoch 15 - Loss: 0.4355
Test Accuracy: 81.28%
Epoch 16 - Loss: 0.4293
Test Accuracy: 80.54%
Epoch 17 - Loss: 0.4165
Test Accuracy: 80.10%
Epoch 18 - Loss: 0.4113
Test Accuracy: 77.80%
Epoch 19 - Loss: 0.3988
Test Accuracy: 81.92%
Epoch 20 - Loss: 0.3912
Test Accuracy: 80.08%학습 결과 시각화 (Loss & Accuracy 그래프)
plt.figure(figsize=(12,5))
plt.subplot(1,2,1)
plt.plot(train_losses, label='Train Loss')
plt.title('Training Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.grid(True)
plt.legend()
plt.subplot(1,2,2)
plt.plot(test_accuracies, label='Test Accuracy', color='green')
plt.title('Test Accuracy')
plt.xlabel('Epoch')
plt.ylabel('Accuracy (%)')
plt.grid(True)
plt.legend()
plt.tight_layout()
plt.show()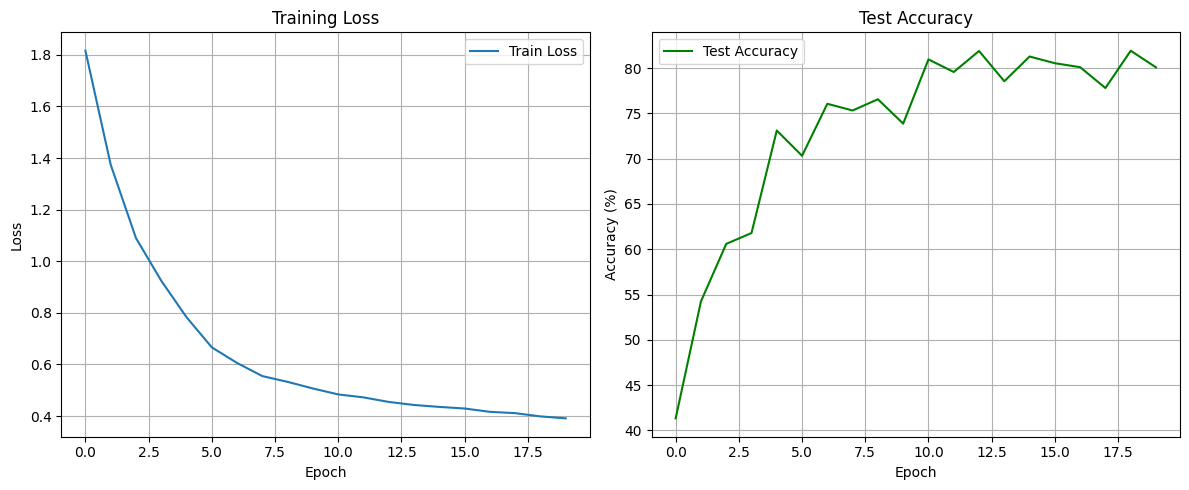
일반 CNN과 ResNet의 비교
일반 CNN
class SimpleCNN(nn.Module):
def __init__(self):
super(SimpleCNN, self).__init__()
self.features = nn.Sequential(
nn.Conv2d(3, 32, kernel_size=3, padding=1), # 32x32
nn.ReLU(),
nn.MaxPool2d(2), # 16x16
nn.Conv2d(32, 64, kernel_size=3, padding=1),
nn.ReLU(),
nn.MaxPool2d(2), # 8x8
nn.Conv2d(64, 128, kernel_size=3, padding=1),
nn.ReLU(),
nn.MaxPool2d(2), # 4x4
)
self.classifier = nn.Sequential(
nn.Linear(128*4*4, 256),
nn.ReLU(),
nn.Linear(256, 10)
)
def forward(self, x):
x = self.features(x)
x = x.view(x.size(0), -1)
x = self.classifier(x)
return xResNet
class BasicBlock(nn.Module):
expansion = 1
def __init__(self, in_channels, out_channels, stride=1, downsample=None):
super(BasicBlock, self).__init__()
self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=stride, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(out_channels)
self.relu = nn.ReLU(inplace=True)
self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(out_channels)
self.downsample = downsample
def forward(self, x):
identity = x
if self.downsample is not None:
identity = self.downsample(x)
out = self.relu(self.bn1(self.conv1(x)))
out = self.bn2(self.conv2(out))
out += identity
out = self.relu(out)
return out
class ResNet(nn.Module):
def __init__(self, block, layers, num_classes=10):
super(ResNet, self).__init__()
self.in_channels = 64
self.conv1 = nn.Conv2d(3, 64, kernel_size=3, stride=1, padding=1, bias=False) # CIFAR-10
self.bn1 = nn.BatchNorm2d(64)
self.relu = nn.ReLU(inplace=True)
self.layer1 = self._make_layer(block, 64, layers[0])
self.layer2 = self._make_layer(block, 128, layers[1], stride=2)
self.layer3 = self._make_layer(block, 256, layers[2], stride=2)
self.layer4 = self._make_layer(block, 512, layers[3], stride=2)
self.avgpool = nn.AdaptiveAvgPool2d((1,1))
self.fc = nn.Linear(512 * block.expansion, num_classes)
def _make_layer(self, block, out_channels, blocks, stride=1):
downsample = None
if stride != 1 or self.in_channels != out_channels * block.expansion:
downsample = nn.Sequential(
nn.Conv2d(self.in_channels, out_channels * block.expansion, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(out_channels * block.expansion),
)
layers = []
layers.append(block(self.in_channels, out_channels, stride, downsample))
self.in_channels = out_channels * block.expansion
for _ in range(1, blocks):
layers.append(block(self.in_channels, out_channels))
return nn.Sequential(*layers)
def forward(self, x):
x = self.relu(self.bn1(self.conv1(x)))
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.fc(x)
return x
def ResNet18():
return ResNet(BasicBlock, [2, 2, 2, 2])학습 & 테스트 함수
def train_model(model, name, epochs=10):
model = model.to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.1, momentum=0.9, weight_decay=5e-4)
train_losses = []
test_accuracies = []
for epoch in range(epochs):
model.train()
running_loss = 0.0
for inputs, targets in trainloader:
inputs, targets = inputs.to(device), targets.to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, targets)
loss.backward()
optimizer.step()
running_loss += loss.item()
avg_loss = running_loss / len(trainloader)
train_losses.append(avg_loss)
# Test
model.eval()
correct = 0
total = 0
with torch.no_grad():
for inputs, targets in testloader:
inputs, targets = inputs.to(device), targets.to(device)
outputs = model(inputs)
_, predicted = torch.max(outputs.data, 1)
total += targets.size(0)
correct += (predicted == targets).sum().item()
acc = 100. * correct / total
test_accuracies.append(acc)
print(f"[{name}] Epoch {epoch+1}/{epochs} - Loss: {avg_loss:.4f}, Accuracy: {acc:.2f}%")
return train_losses, test_accuracies모델 학습
simplecnn = SimpleCNN()
resnet18 = ResNet18()
loss_simple, acc_simple = train_model(simplecnn, "SimpleCNN", epochs=10)
loss_resnet, acc_resnet = train_model(resnet18, "ResNet18", epochs=10)[SimpleCNN] Epoch 1/10 - Loss: 1.7672, Accuracy: 45.11%
[SimpleCNN] Epoch 2/10 - Loss: 1.5219, Accuracy: 48.79%
[SimpleCNN] Epoch 3/10 - Loss: 1.4166, Accuracy: 51.56%
[SimpleCNN] Epoch 4/10 - Loss: 1.3607, Accuracy: 52.87%
[SimpleCNN] Epoch 5/10 - Loss: 1.3331, Accuracy: 53.54%
[SimpleCNN] Epoch 6/10 - Loss: 1.2855, Accuracy: 57.27%
[SimpleCNN] Epoch 7/10 - Loss: 1.2661, Accuracy: 54.14%
[SimpleCNN] Epoch 8/10 - Loss: 1.2458, Accuracy: 57.81%
[SimpleCNN] Epoch 9/10 - Loss: 1.2193, Accuracy: 62.40%
[SimpleCNN] Epoch 10/10 - Loss: 1.2148, Accuracy: 57.02%
[ResNet18] Epoch 1/10 - Loss: 2.0147, Accuracy: 39.30%
[ResNet18] Epoch 2/10 - Loss: 1.5072, Accuracy: 49.21%
[ResNet18] Epoch 3/10 - Loss: 1.2572, Accuracy: 57.31%
[ResNet18] Epoch 4/10 - Loss: 1.0546, Accuracy: 64.65%
[ResNet18] Epoch 5/10 - Loss: 0.9294, Accuracy: 61.77%
[ResNet18] Epoch 6/10 - Loss: 0.8137, Accuracy: 70.95%
[ResNet18] Epoch 7/10 - Loss: 0.7015, Accuracy: 72.78%
[ResNet18] Epoch 8/10 - Loss: 0.6298, Accuracy: 75.79%
[ResNet18] Epoch 9/10 - Loss: 0.5733, Accuracy: 76.71%
[ResNet18] Epoch 10/10 - Loss: 0.5420, Accuracy: 72.58%일반 CNN과 ResNet의 학습/성능 차이 비교 시각화
# 시각화
plt.figure(figsize=(12, 5))
plt.subplot(1, 2, 1)
plt.plot(loss_simple, label="SimpleCNN Loss")
plt.plot(loss_resnet, label="ResNet18 Loss")
plt.xlabel("Epoch")
plt.ylabel("Loss")
plt.title("Training Loss")
plt.legend()
plt.grid(True)
plt.subplot(1, 2, 2)
plt.plot(acc_simple, label="SimpleCNN Accuracy")
plt.plot(acc_resnet, label="ResNet18 Accuracy")
plt.xlabel("Epoch")
plt.ylabel("Accuracy (%)")
plt.title("Test Accuracy")
plt.legend()
plt.grid(True)
plt.tight_layout()
plt.show()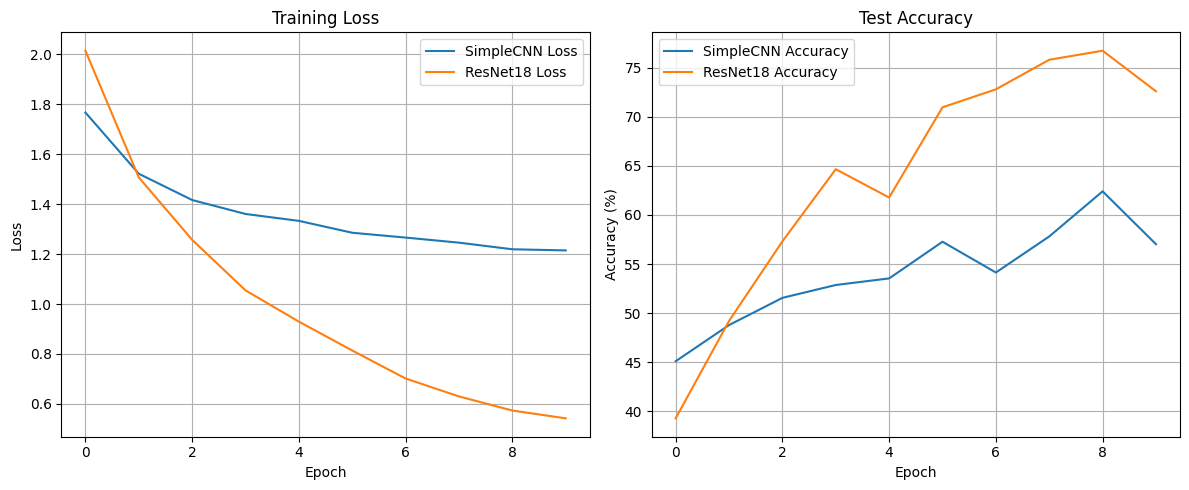
일반 CNN과 ResNet의 학습/성능 차이 비교 정리
- Training Loss (학습 손실)
- ResNet-18은 에폭이 진행됨에 따라 손실값이 빠르게 감소하며, 전체적으로 더 낮은 loss를 보인다.
- SimpleCNN은 loss가 천천히 줄어들고, 10 에폭이 지나도 1.2 근처에서 수렴한다.
→ ResNet이 더 빠르고 효과적으로 학습되었다.
- Test Accuracy (테스트 정확도)
- ResNet-18은 10 에폭 동안 꾸준히 정확도가 올라가며 최고 약 77% 수준까지 도달했다.
- SimpleCNN은 정확도가 최고 약 63% 수준으로 ResNet보다 낮고, 상승 폭도 작다.
→ 일반 CNN보다 ResNet이 훨씬 높은 성능을 보이는 것을 확인할 수 있다.
ResNet이 더 잘 학습되는 이유
ResNet(Residual Network)의 핵심 아이디어는 Residual Learning 이다.
모델이 학습해야 할 함수를 직접 학습하는 대신, 입력과 출력의 차이(Residual)를 학습한다.
Output = F(x) + x
- F(x): 합성곱(Convolution) 등의 연산을 통해 학습되는 함수
- x: 입력값을 그대로 더하는 skip connection(shortcut connection)
입력을 그대로 다음 레이어에 더해주는 이러한 구조 덕분에, 일반 CNN에 비해 다음과 같은 장점이 생긴다.
- 기울기 소실 문제 해결
- 일반적인 깊은 네트워크에서는 역전파 도중 기울기가 점점 작아져 학습이 거의 되지 않는 문제(vanishing gradient)가 발생한다.
- ResNet은 입력을 그대로 더해주는 skip connection 덕분에, 기울기가 직접 입력까지 전파되며 이 문제를 해결한다.
- 깊은 네트워크일수록 더 나은 성능
- 일반 CNN은 층이 깊어질수록 성능이 오히려 감소(degradation problem)할 수 있지만, ResNet은 네트워크를 깊게 만들수록 정확도가 계속 향상된다.
- ResNet이 잔차만 학습하기 때문에 학습이 상대적으로 더 쉽기 때문이다.
- 학습 안정성과 수렴 속도 개선
- Residual 구조는 네트워크가 더 빠르게 수렴하게 만들고, 학습 과정에서의 불안정성을 줄인다.
→ 깊은 네트워크에서도 학습이 잘 이루어지는 중요한 이유
- 실험을 통한 성능 향상 확인
- 실제로 ResNet-18, ResNet-34는 같은 조건에서 일반 CNN보다 더 높은 정확도와 더 빠른 수렴 속도를 보인다.
- 단순히 layer를 많이 쌓는 것보다, skip connection을 통해 잔차 학습 구조를 도입하는 것이 훨씬 효과적이다.

The light shines in the darkness.