
Residual Learning
학습하고자 하는 함수
𝐻(𝑥)를 직접 학습하는 것이 아니라, 입력 𝑥 에 대한 잔차(residual)인𝐹(𝑥) = 𝐻(𝑥) − 𝑥를 학습하는 것이다.
→ 원하는 출력 𝐻(𝑥) 대신 잔차 함수 𝐹(𝑥) = 𝐻(𝑥) − 𝑥를 학습하고,
최종 출력은 𝑦 = 𝐹(𝑥) + 𝑥로 계산된다.
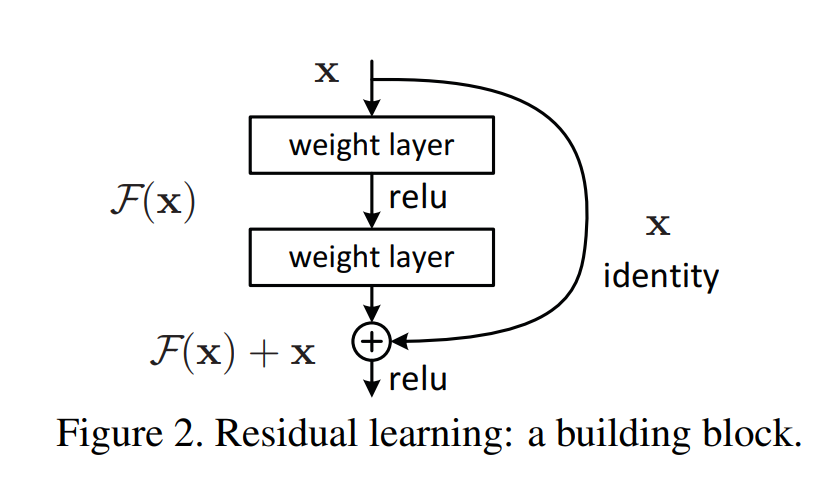
논문에서는 하나의 block을 다음과 같이 정의한다.
- x: 입력 벡터
- 𝑦: 출력 벡터
- 𝐹(𝑥,{𝑊𝑖}): 학습할 잔차 함수 (예: 두 개의 층으로 구성된 𝐹=𝑊2⋅𝜎(𝑊1𝑥), 𝜎는 ReLU)
- F(x) + x는 shortcut connection과 원소별 덧셈(element-wise addition)으로 구현됨.
- 마지막에 비선형함수 ReLU(σ)를 한 번 더 적용 (즉, σ(y))
ResNet 논문에서 저자들은 original mapping(unreferenced mapping)보다는 residual mapping(referenced mapping)을 최적화하는 문제가 더 쉽다고 가정한다.
만약 어떤 함수 𝐻(𝑥)의 최적 해가 항등 함수(identity mapping)라면,
(𝐻(𝑥) = 𝑥 가 최적인 경우)
𝐻(𝑥) = 𝐹(𝑥) + 𝑥이므로, 𝐻(𝑥) = 𝑥가 되려면 𝐹(𝑥) = 0이 되어야 한다.
항등(identity) 함수란? 항등적으로 자기 자신과 같은 값을 대응시키는 함수.
f(x) = x인 함수
입력 𝑥 를 그대로 출력으로 만드는 항등 함수를 직접 학습하기보다는,
𝑥 와의 차이(residual)인 𝐹(𝑥)를 0으로 만드는 것이 더 학습하기 쉬울 수 있다고 한다.
일반적인 CNN과의 차이점
1. 학습 대상의 차이
일반적인 CNN은 입력을 직접 원하는 출력 함수 로 학습하려고 한다.
반면, ResNet은 대신 입력과 출력의 차이인 잔차(residual) 를 학습한다.
최종 출력은 로 계산되며, 이는 신호의 흐름을 더 원활하게 만들어준다.
2. Skip Connection 도입 여부
일반적인 CNN에는 skip connection이 존재하지 않지만,
ResNet은 identity shortcut (skip connection)을 사용하여 입력을 출력에 더해주는 구조를 가진다.
이로 인해 학습이 훨씬 쉬워지고, 깊은 네트워크에서도 성능 저하 없이 효과적으로 학습할 수 있다.
3. Degradation 문제 해결
네트워크가 깊어질수록 일반적인 CNN에서는 training error가 증가하는 문제가 있었지만, ResNet은 Residual 구조 덕분에 이러한 문제를 해결할 수 있다.
이는 실험적으로도 깊은 네트워크에서 더 낮은 error를 보이며 검증되었다.
4. Gradient 흐름의 개선
ResNet은 skip connection 덕분에 gradient가 identity 경로를 통해 더 깊은 레이어까지 안정적으로 전달될 수 있어, gradient vanishing(기울기 소실) 문제를 완화한다. 이는 네트워크가 더 깊어져도 학습이 가능한 중요한 이유 중 하나이다.
5. 추가 연산 또는 파라미터 비용
ResNet의 skip connection은 단순한 identity mapping이기 때문에 추가적인 연산이나 파라미터가 거의 발생하지 않으며, 성능 향상 대비 효율적인 구조라고 할 수 있다.
Shortcut connection(Skip Connection)
Shortcut connection은 하나 이상의 레이어를 건너뛰는 연결 방식으로,
일반적으로 항등 함수(identity mapping)를 수행하며, 그 출력을 기존 레이어의 출력에 더한다.
Shortcut connection은 두 개의 Layer를 건너뛰므로 Skip Connection 이라고도 한다.
Shortcut connection(Skip Connection)의 장점
- 단순히 입력 x를 더하는 것이기 때문에 추가적인 파라미터가 필요하지 않고 복잡하지 않다.
- Residual 구조를 도입하여 identity mapping이 최적일 경우 잔차 함수 F(x)를 0으로 밀면 블록이 입력을 그대로 전달하므로, optimizer가 identity 함수에 가까운 솔루션을 쉽게 찾을 수 있다.
ResNet이 해결한 문제
Degradation Problem
깊은 신경망(Deep Neural Network)은 일반적으로 더 좋은 성능을 내지만, 층을 너무 깊게 쌓으면 오히려 성능이 저하되는 문제가 발생한다. (degradation problem)
degradation problem 이란?
모델이 깊어지면 accuracy가 포화되고, 성능이 낮아진다.(degrade)
아래 그래프는 ResNet 논문에서 제시된 실험 결과로,
CIFAR-10 데이터셋을 학습시킨 20-layer와 56-layer의 plain network의 성능을 비교한 것이다.
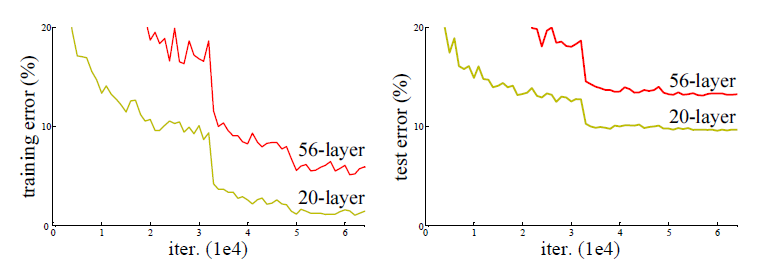
실험 결과 training error 가 더 깊은 네트워크에서 더 높게 나타났으며, test error 역시 더 악화되었다.
더 깊은 네트워크가 항상 더 나은 성능을 보장하지 않으며, 경우에 따라 학습 자체가 어려워질 수 있다는 것을 보여준다.
이 현상은 과적합 때문이 아니라, 깊은 네트워크 자체가 학습하기 어려워지기 때문이라고 한다.
vanishing gradient & Optimization Difficulty
기존의 shallower model 위에 identity layer만 추가해도 성능이 동일해야 하지만,
일반적인 CNN에서는 deeper network가 이 구성 가능한 해조차 제대로 학습하지 못했다.
✨ ResNet은 일반적으로 발생하는 vanishing gradient나 최적화 어려움을 구조적으로 완화한다.
-
ResNet 구조에서는 shortcut connection을 통해 입력 𝑥 가 나중의 layer로 직접 전달되며, gradient가 역전파될 때도 마찬가지로 중간 layer를 거치지 않고 전달될 수 있는 경로를 형성한다.
-
네트워크가 매우 깊어져도, gradient가 소실되지 않고 뒷부분까지 잘 전달되어 vanishing gradient 문제를 간접적으로 완화한다.
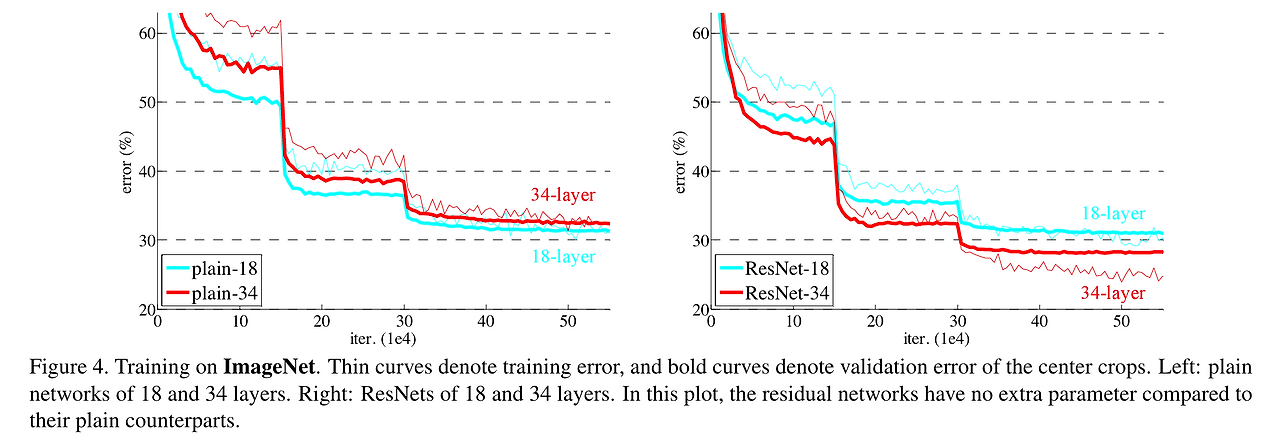
-
Plain network의 경우, 네트워크의 깊이가 깊어질수록 오히려 오차가 증가하지만,
Residual network에서는 네트워크가 더 깊어질수록 오차가 감소한다.
→ degradation 문제 해결! -
동일한 layer depth를 가진 네트워크에서 동일한 iteration 시점을 비교해보면,
Residual network의 training/test error가 더 낮게 나타난다.
→ Residual Learning을 통해 네트워크가 더 쉽게 학습될 수 있음을 실험적으로 확인할 수 있다.
