
1. Intro
1-1 Preliminaries
이 글은 아래 글을 읽은 사람을 대상으로 쓰여졌습니다.
- 1편 : Feature Store - why?
- 2편 : Feature store 핵심 개념
- 3편: Feasture store 구조
1-2. AWS
- AWS는 많은 회사에서 사용하고 있는 cloud 서비스이다.
- AWS에서는 feature store 서비스를 2020년말쯤 부터 시작했다.
- AWS Feature store의 특징과 사용법을 알아보자.
2. AWS Feature store 용어
- 2편 Feature store 핵심 개념에서 다룬 내용들이 그대로 aws에서 나온다.
2-1 Feature Definition
- Feature group을 생성할 때는 feature들의 타입을 정의해줘야 한다.
- Feature group을 생성할 때 Feature column 별로 데이터 타입을 json 형태로 넘기는데 이 정보를 Feature Definition이라고 부른다.
- 2-2 Feature group에 예시가 있다.
2-2 Feature group
- Feature group은 AWS에서도 똑같이 존재한다.
- Feature group은 RDS로 비유하면 일종의 테이블이다.
- 같은 종류의 feature들을 보관하게 된다.
- AWS에서는 아래 처럼 feature group의 현황을 볼 수 있다.
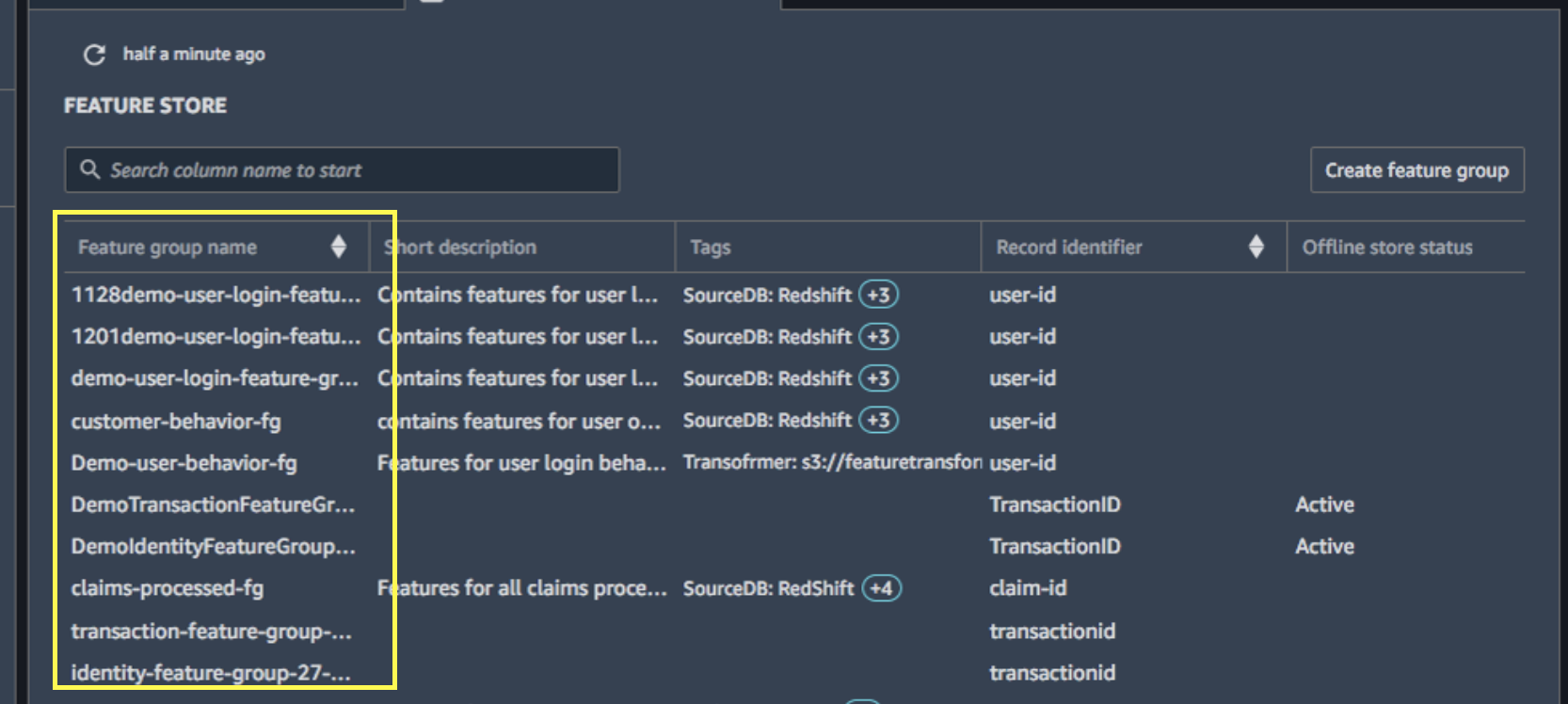
- 아래 그림 처럼 Feature group 생성시 Feature Definition(json 형태의 각 Feature column 별 데이터 타입)을 정해줘야 한다.
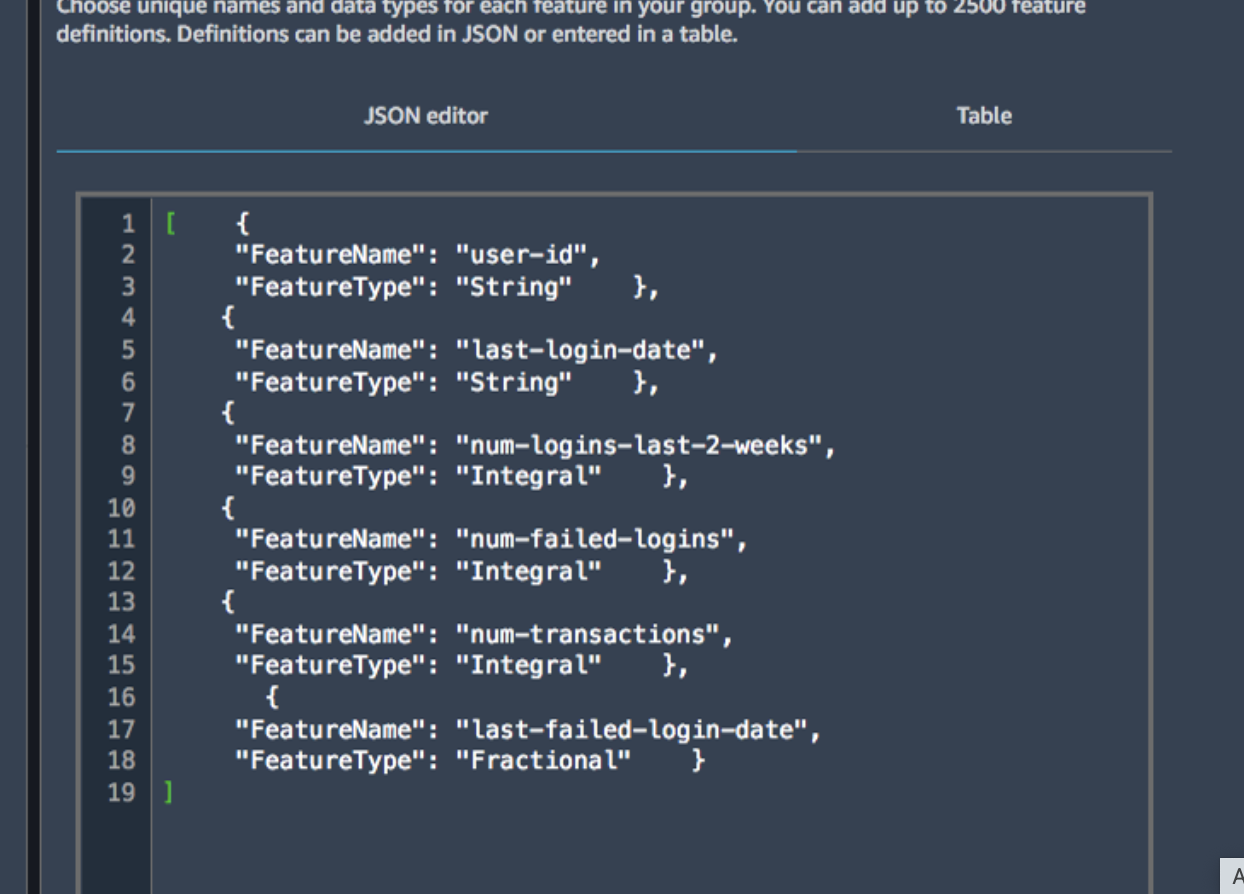
- RDS에 비유하면 다음과 같다.
- Feature group = 테이블
- Feature Name = colum 이름
- Feature Type = column type
2-3 Record identifier
- Record identifier는 이전 글 Feature store 핵심 개념의 Feature Key에 해당한다.
- Feature의 조인에서 활용된다.
2-4 Event time
- AWS Feature store는 이전 글 Feature store 핵심 개념의 event time과 정확히 일치하는 개념이 똑같은 이름으로 있다.
2-5 Ingest
- Feature store로 데이터를 넣는 것을 Ingest라고 부른다.
- Ingest는 put을 통해 이루어진다.
3.storage
- 모든 feature store는 두개의 storage를 가지고 있다.
- feature store의 storage 및 간단한 구조에 대해서는 이미 3편Feasture store 구조에서 다루었다.
3-1 Offline storage
-
aws feature store는 offline storage로 aws athena를 쓴다.
- 아테나는 서버리스하게 대화식 쿼리를 날릴 수 있는 aws의 서비스이다.
- 내부 엔진은 presto를 쓰는 것처럼 보인다.
-
AWS athena에 데이터가 저장되면 glue에도 스키마가 남게된다.
-
그러면 EMR에서 hive metastore로 쓸 수 있기 때문에 spark등에서 쓸 수 있게 된다.
-
실제로 feature group을 추가하고 나면 athena에 테이블이 추가된 것이 보인다.
3-2 Online storage
- Online storage로 어떤 DB 엔진을 쓰는지 알려진 것은 없다.
- 아마도 자체 구현인 것 같다.
- 특징은 다음과 같다.
- 같은 Record identifier 값을 여러 row가 가질 경우 event_time이 최신인 feature가 보관된다. (최신 보관 이유 : 2편 Feature store 핵심 개념)
- low latency (p95 latency lower than 10 milliseconds for a 15-kilobyte payload)
- high availabilty
- online feature가 필요 없다면 online storage로 쌓지 않고 관련 비용(GB당 월 0.4873 USD) 이 절약된다. feature group을 만들때 필요 여부를 반영하면 된다.
4. APIs
https://docs.aws.amazon.com/sagemaker/latest/dg/feature-store-introduction-notebook.html 참고 함
4-1. Create Feaute Group
customers_feature_group = FeatureGroup(
name=customers_feature_group_name, sagemaker_session=sagemaker_session
)
customers_feature_group.load_feature_definitions(data_frame=customer_data)
customers_feature_group.create(
s3_uri=f"s3://{s3_bucket_name}/{prefix}",
record_identifier_name=record_identifier_feature_name,
event_time_feature_name="EventTime",
role_arn=role,
enable_online_store=True
)- create feature group을 통해 feature group을 만들 수 있다.
- FeatureGroup.create로 만드는데, python 예시는 아래와 같다.
- 아래 코드는 다음과 같은 순서로 이루어져 있다.
load_feature_definitions통해서Feature Definition을 정의함- 예제에서는 pandas df로 부터 자동으로 Feature Definition을 정의하는 편리한 방법을 쓴다.
- 직접 정의해줘도 된다.
create를 통해 실제 Feature group을 정의하게 된다.
- create를 쓸때 넘기는 parameter를 살펴 보자 .
- s3_uri
- 내 feature 데이터가 s3의 어떤 경로로 저장될지 설정할 수 있다.
- record_identifier_name
- 어떤 컬럼이 key가 될지 알려줘야 한다.
- event_time_feature_name
- 어떤 컬럼이 event_time 컬럼이름인지 알려줘야 한다.
- AWS sagemaker는 event_time을 넘기는 것이 필수다!
- enable_online_store
- 서빙을 위해 low latency의 online storage를 쓸지 여부이다.
- True로 하면 GB당 저장 비용이 s3와 별개로 청구된다.
- role_arn
- feature group 생성에 쓸 iam role 이름
- 관련 권한이 있어야함
- aws에서 만들어둔 policy 있음 : AmazonSageMakerFeatureStoreAccess
- s3_uri
4-2. Put
- 아래 처럼 ingest를 하면 손쉽게 feature를 넣을 수 있다.
customers_feature_group.ingest(
data_frame=customer_data, max_workers=3, wait=True
)- dataframe의 row 개수만큼 요청으로 간주한다.
- 따라서 비용생각한다고 여러개를 한번에 put할 필요 없고, 단건을 자주 여러개 넣어도 괜찮다.
4-3. List
- studio를 사용하면 gui로도 볼 수 있지만, 아래 처럼 전체 Feature를 보거나 특정 Feature group의 정보를 볼 수 있다.
(sagemaker_session.
boto_session.
client('sagemaker', region_name=region).
list_feature_groups()
)# We use the boto client to list FeatureGroups
customers_feature_group.describe()4-4. GET
- 아래 처럼
Feature group과Record Identifier name에 해당하는 값을get_record를 통해 부르면 feature 값을 return 해준다. - 배치로도 부를 수 있다.
- batch get의 경우 각건에 대해 비용이 청구되는지는 안 알아봤다..
- production에서 쓰려면 알아봐야 할 것 같다.
customer_id = 573291
sample_record = (sagemaker_session.
boto_session.
client('sagemaker-featurestore-runtime',region_name=region).
get_record(FeatureGroupName=customers_feature_group_name,
RecordIdentifierValueAsString=str(customer_id))
)
########
all_records = sagemaker_session.
boto_session.
client("sagemaker-featurestore-runtime", region_name=region).
batch_get_record(
Identifiers=[
{
"FeatureGroupName": customers_feature_group_name,
"RecordIdentifiersValueAsString": ["573291", "109382", "828400", "124013"],
},
{
"FeatureGroupName": orders_feature_group_name,
"RecordIdentifiersValueAsString": ["573291", "109382", "828400", "124013"],
},
]
)
4-5. Querying
-
AWS feature store에 넣은 데이터들은 모두 athena + glue + s3에 저장된다.
-
as_hive_ddl로 glue에 저장될 hive ddl을 알아낼 수 있다.print(feature_group.as_hive_ddl()) -
table이름은 아래처럼 athena_query().table_name으로 얻을 수 있다.
identity_query = identity_feature_group.athena_query()
transaction_query = transaction_feature_group.athena_query()
identity_table = identity_query.table_name
transaction_table = transaction_query.table_name- 다음은 몇가지 쿼리 예시이다. (이거 복붙해서 가져옴)
- 아래 쿼리들은 AWS sagemaker를 안 쓰더라도 응용해서 쓸일이 많다. SQL에 익숙하지 않으면 봐두자.
- show
SELECT * FROM <FeatureGroup.DataCatalogConfig.DatabaseName>.<FeatureGroup.DataCatalogConfig.TableName> LIMIT 1000 - Latest snapshot without duplicates
SELECT * FROM (SELECT *, row_number() OVER (PARTITION BY <RecordIdentiferFeatureName> ORDER BY <EventTimeFeatureName> desc, Api_Invocation_Time DESC, write_time DESC) AS row_num FROM <FeatureGroup.DataCatalogConfig.DatabaseName>.<FeatureGroup.DataCatalogConfig.TableName>) WHERE row_num = 1; - Latest snapshot without duplicates and deleted records in the offline store
SELECT * FROM (SELECT *, row_number() OVER (PARTITION BY <RecordIdentiferFeatureName> ORDER BY <EventTimeFeatureName> desc, Api_Invocation_Time DESC, write_time DESC) AS row_num FROM <FeatureGroup.DataCatalogConfig.DatabaseName>.<FeatureGroup.DataCatalogConfig.TableName>) WHERE row_num = 1 and NOT is_deleted; - Time Travel without duplicates and deleted records in the offline store
SELECT * FROM (SELECT *, row_number() OVER (PARTITION BY <RecordIdentiferFeatureName> ORDER BY <EventTimeFeatureName> desc, Api_Invocation_Time DESC, write_time DESC) AS row_num FROM <FeatureGroup.DataCatalogConfig.DatabaseName>.<FeatureGroup.DataCatalogConfig.TableName> where <EventTimeFeatureName> <= timestamp '<timestamp>') -- replace timestamp '<timestamp>' with just <timestamp> if EventTimeFeature is of type fractional WHERE row_num = 1 and NOT is_deleted
- show
4-6 CLI
- https://docs.aws.amazon.com/cli/latest/reference/sagemaker-featurestore-runtime/index.html
- cli로도 api가 제공된다.
5. 비용 분석
- 2021년 10월 12일 기준 비용은 아래와 같다.
- 대규모 트래픽일 경우 초당 백만건의 get 요청을 처리한다면 달에 5억원이 청구된다.
- redis로 직접 구현시 상당히 많은 비용을 아낄 수 있다.
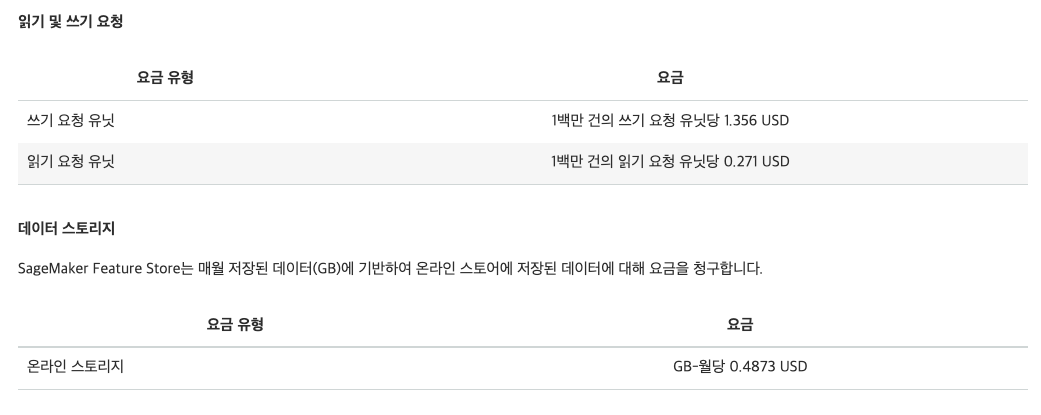
6. Reference
[1]https://sagemaker.readthedocs.io/en/stable/amazon_sagemaker_featurestore.html
[2]https://aws.amazon.com/ko/sagemaker/feature-store/
[3]https://docs.aws.amazon.com/sagemaker/latest/dg/feature-store-create-feature-group.html
[4]https://aws.amazon.com/ko/sagemaker/pricing

Machine Learning Engineer: recsys, mlops