
파드 지원 할당
쿠버네티스에서는 노드 하나에 여러 개 파드를 실행하는 일이 자주 있다. 이 때 자원 사용량이 많은 파드가 노드 하나에 모여 있다면 파드들의 성능이 나빠진다. 예를 들어 어떤 노드에는 파드가 없어 CPU나 메모리 같은 자원이 남고, 어떤 노드에는 파드들이 많아 프다에서 사용해야 하는 CPU나 메모리가 부족해 질 수 있다.
쿠버네티스에서는 이런 상황을 막기 위한 여러가지 방법이 있다. 가장 기본적으로는 파드를 설정할 때 각 컨테이너의 CPU나 메모리를 얼마나 사용할 수 잇는지 조건을 설정하는 것이다.
각 컨테이너에 대해, 리소스 제한 및 요청을 지정할 수 있다.
spec.containers[].resources.limits.cpu
spec.containers[].resources.limits.memory
spec.containers[].resources.limits.hugepages-<size>
spec.containers[].resources.requests.cpu
spec.containers[].resources.requests.memory
spec.containers[].resources.requests.hugepages-<size>apiVersion: v1
kind: Pod
metadata:
name: frontend
spec:
containers:
- name: app
image: images.my-company.example/app:v4
resources: #minimum
requests:
memory: "64Mi"
cpu: "250m"
limits: #maximum
memory: "128Mi"
cpu: "500m" #m은 밀리코어, 1000m=1core
- name: log-aggregator
image: images.my-company.example/log-aggregator:v6
resources:
requests:
memory: "64Mi"
cpu: "250m"
limits:
memory: "128Mi"
cpu: "500m"리소스를 설정하지 않으면, 호스트의 모든 자원을 사용할 수 있다는 의미가 된다. 실습과는 다르게, 실제 어플리케이션을 설정할 때는 프로브를 꼭 설정해 줘야 한다. CPU에는 밀리코어가 아니라 정수로 할당할 수도 있다. 1이 1코어, 0.5로 설정하면 500m이 된다.
requests는 반드시 할당하는 최소 용량이다. 리소스가 이만큼의 용량을 사용하든 사용하지 않든 이 만큼의 양을 무조건 할당한다. requests값 만큼의 리소스가 남아있지 않으면 파드는 생성되지 않는다. 하지만 limits는 보장해주지 않는다. requests와 limits의 값을 같게 해주면 항상 할당된 용량만큼을 사용한다.
처음 설정할 때는 충분하게 양을 잡아두는 편이 권장된다. 추후에 줄여나가면 되기 때문이다.
- milicore
CPU의 m은 밀리코어를 뜻한다. 1000m은 1코어를 의미한다. 코어가 쓰레드인지 코어인지는 케이스마다 다르다. 소켓은 코어, 코어는 쓰레드로 이루어져 있다. 하이퍼쓰레딩 기술을 사용하면 한 코어에 쓰레드가 두 개씩 있는 것이다. 사용하고 있는 가상머신을 기준으로는 1소켓에 코어가 2개, 코어당 쓰레드는 하나씩 있다. 그래서 총 쓰레드는 2개, CPU는 2개가 있는 상태이다.
apiVersion: v1
kind: Pod
metadata:
name: myapp-pod-req
spec:
containers:
- name: myapp
image: ghcr.io/c1t1d0s7/go-myweb:alpine
resources:
cpu: 200m
memory: 10Mi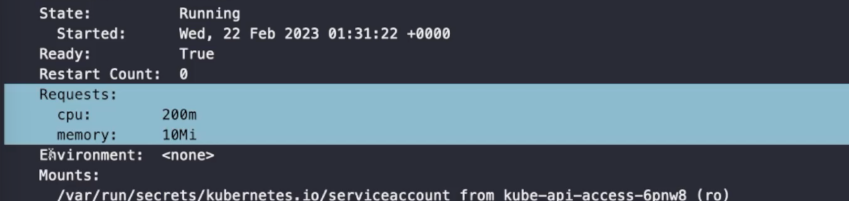
이 파드는 requests 만큼의 용량을 할당 받았다.
apiVersion: v1
kind: Pod
metadata:
name: myapp-pod-huge-req
spec:
containers:
- name: myapp
image: ghcr.io/c1t1d0s7/go-myweb:alpine
resources:
cpu: 4000m
memory: 4Gi 위와 같이 requests 양을 극도로 많이 할당하면 Pending 상태에서 만들어지지 않는다. 애초부터 배치가 되지 않는다.

CPU와 Memory가 충분하지 않기 때문에 생성할 수 없다는 메세지를 확인할 수 있다.
apiVersion: v1
kind: Pod
metadata:
name: myapp-pod-lim
spec:
containers:
- name: myapp
image: ghcr.io/c1t1d0s7/go-myweb:alpine
resource:
limits: #limits만 설정
cpu: 0.5
memory: 20Mi 
limits의 값만 설정하면 requests의 값이 limits의 값과 같도록 자동으로 설정된다. limits와 requests의 값을 같을 수 있지만 requests가 limits보다 클 수는 없다.
kubectl top pods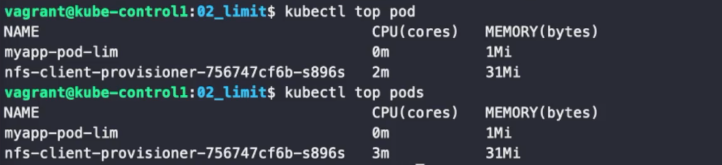

docker 의 top 명령어는 kubectl과의 top 명령어와는 다르다. docker의 top 명령어는 컨테이너의 프로세스 목록이 나오고, kubectl의 top 명령어는 기존 top 명령어처럼 컨테이너의 CPU, 메모리 현재 사용량을 보여준다. docker에서 메모리 사용량을 보려면 docker stats 명령어를 사용한다.
kubectl exec myapp-pod-lim -- sha256sum /dev/zero
CPU 부하 테스트를 명령어를 통해 걸어보면 limits 이상으로 올라가지 않는 것을 확인할 수 있다.

노드당 파드는 110개로 제한된다. Capacity는 총 양이고, Allocatable은 현재 할당할 수 있는 총 양이다.

종료되지 않는 파드들의 목록이다. 이 파드들의 CPU, Memory requests는 늘 할당되어 있다.
QoS Class
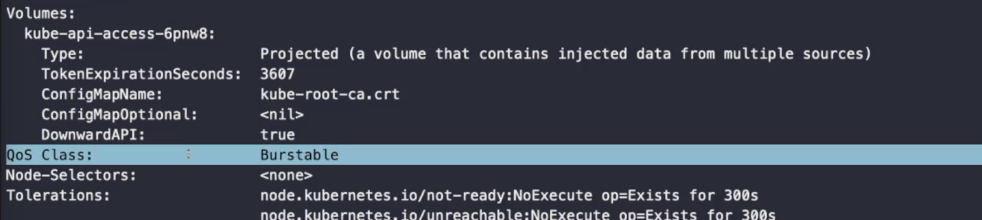
TCP 헤더의 TOS와 같다. 말 그대로 서비스의 품질이라는 뜻이다. 파드에 있는 어플리케이션의 품질을 뜻한다. 파드의 품질으로는 Guaranteed, Burstable, BestEffort가 있다.
BestEffort
최선을 다한다 정도의 의미이다. 품질을 좋게 하기 위해 최대한 노력해 보겠다는 의미라고 할 수 있다. Pod limits, request, CPU limits, request가 모두 없으면 BestEffort 상태로 나온다.
Burstable

Requests보다 limits가 큰 경우를 의미한다. 기본적으로 파드가 뜨게 되면 리퀘스트의 양 만큼 보장을 해 준다. 이 때 더 많은 메모리가 필요하면 비록 limits 만큼을 보장 받지는 못하더라도 limits의 양 까지 burst할 수 있다는 의미이다.
Guaranteed

CPU와 Pod의 requests와 limits의 양=CPU와 Memory 값이 모두 같아야 한다. requests는 무조건 보장하는 것이므로 limits와 requests의 값이 같으면 무조건 limits의 양 만큼 보장할 수 있기 때문이다.
파드는 kubelet이 제어하게 된다. 만약 노드에 파드가 많아 CPU, 메모리에 압박을 받게 되면 BestEffort 상태의 Pod부터 실행시키지 않는다. 그 다음은 Burstable 상태의 Pod를 중지시키고, 마지막까지 보장하는 것은 Guaranteed 상태의 Pod이다. 우선순위가 높기 때문이다.
metrics server
해당 애드온을 통해 모든 노드의 CPU, 메모리, 파드들의 CPU, 메모리 양을 실시간으로 측정(metric) 한다. top 명령어를 통해 실시간으로 메모리를 확인할 수 있는 것은 metrics server가 있기 때문이다. 따라서 메모리 사용량을 확인하기 위해선 해당 애드온을 다운로드 받아야 한다. 애드온이지만 필수라고 할 수 있다.
리밋 레인지
apiVersion: v1
kind: LimitRange
metadata:
name: myapp-limitrange
spec:
limits:
- type: Pod
min:
cpu: 50m #파드에 설정할 수 있는 최소값
memory: 5Mi
max:
cpu: 1 #파드에 설정할 수 있는 최대값
memory: 1Gi
- type: Container
defaultRequest: #request의 기본값
cpu: 100m
memory: 10Mi
default: #limit의 기본값
cpu: 200m
memory: 100Mi
min: #컨테이너에설정할 수 있는 최소값
cpu: 50m
memory: 5Mi
max: #컨테이너에설정할 수 있는 최대값
cpu: 1
memory: 1Gi
maxLimitRequestRatio: #비율
cpu: 4 #4배수이므로 6배 등은 설정할 수 없다.
memory: 10
- type: PersistentVolumeClaim
min: #스토리지 최소값
storage: 10Mi
max: #스토리지 최대값
storage: 1Gi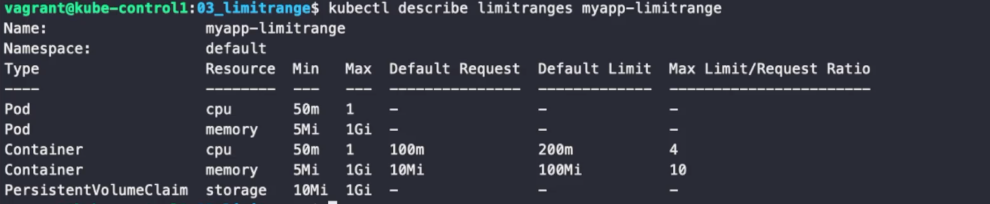
설정한 값을 확인할 수 있다.

최대 사용할 수 있는 MAX 값을 넘어서는 파일을 실행하면 만들어지지 않는다. limitrange를 설정하지 않았을 때에는 Pending 상태에서 넘어가지 않지만, 설정하면 아예 생성부터 안 된다.
request 값과 limit 값을 설정하지 않아도 자동으로 default limitrange에 설정한 값대로 설정된다.
리소스 쿼터 (resource quota)
apiVersion: v1
kind: ResourceQuota
metadata:
name: myapp-quota-cpumem
spec:
hard:
requests.cpu: 500m
requests.memory: 200Mi
limits.cpu: 1000m
limits.memory: 1Gi #최대값리밋 레인지와 비슷하게 작동한다.
apiVersion: v1
kind: ResourceQuota
metadata:
name: myapp-quota-object
spec:
hard:
pods: 10
replicationcontrollers: 2
secrets: 10
configmaps: 10
persistentvolumeclaims: 5 #PVC는 5개 만들 수 있지만
services: 5
services.loadbalancers: 1
services.nodeports: 2
nfs-client.storageclass.storage.k8s.io/persistentvolumeclaims: 2
#nfs-client를 이용하면 2개만 만들 수 있다.각각 리소스의 갯수를 제한할 수 있다.
apiVersion: v1
kind: ResourceQuota
metadata:
name: myapp-quota-storage
spec:
hard:
requests.storage: 10Gi
nfs-client.storageclass.storage.k8s.io/requests.storage: 2Gi스토리지의 용량을 제한하는 것도 가능하다.
오토 스케일링
Horizontal Pod Autoscaling
쿠버네티스에서, HorizontalPodAutoscaler 는 워크로드 리소스(예: 디플로이먼트 또는 스테이트풀셋)를 자동으로 업데이트하며, 워크로드의 크기를 수요에 맞게 자동으로 스케일링하는 것을 목표로 한다. 수평 스케일링은 부하 증가에 대해 파드를 더 배치하는 것을 뜻한다. 이는 수직 스케일링(쿠버네티스에서는, 해당 워크로드를 위해 이미 실행 중인 파드에 더 많은 자원(예: 메모리 또는 CPU)를 할당하는 것)과는 다르다.
부하량이 줄어들고, 파드의 수가 최소 설정값 이상인 경우, HorizontalPodAutoscaler는 워크로드 리소스(디플로이먼트, 스테이트풀셋, 또는 다른 비슷한 리소스)에게 스케일 다운을 지시한다.
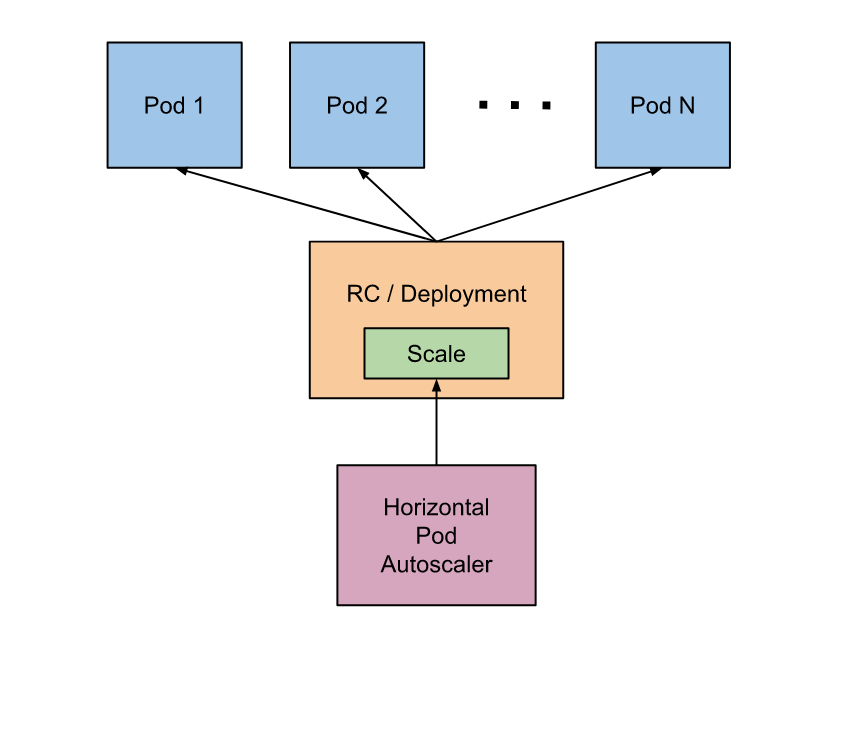
수평적으로 스케일링을 하기 위해선 복제본을 제공해주는 컨트롤러(rs, sts)가 필요하다. HPA 리소스가 자동으로 컨트롤러를 기준에 따라 수정해 준다. 알고리즘은 다음과 같다.
원하는 레플리카 수 = ceil[현재 레플리카 수 * ( 현재 메트릭 값 / 원하는 메트릭 값 )]ceil(올림) 으로, 공식의 값이 4.5 라면 레플리카를 5개로 조정한다.
kubectl explain hpa.sepc --api-version autoscailing/v1 #버전 선택 가능apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: myapp-hpa-cpu
spec:
scaleTargetRef: #참조 대상
apiVersion: apps/v1
kind: Deployment
name: myapp-deploy-hpa #얘의 복제본을 조정하겠다.
minReplicas: 2 #2개부터
maxReplicas: 10 #10개까지
metrics: #V1에서는 CPU만 측정할수 있었지만 V2에서는 모두 측정할 수 있다.
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 70
# targetCPUUtilizationPercentage: 70 V1에선 이렇게!apiVersion: apps/v1
kind: Deployment
metadata:
name: myapp-deploy-hpa
spec:
replicas: 3
selector:
matchLabels:
app: myapp-deploy-hpa
template:
metadata:
labels:
app: myapp-deploy-hpa
spec:
containers:
- name: myapp
image: ghcr.io/c1t1d0s7/go-myweb:alpine
resources:
requests: #스케일링의 기준은 request이다!!
cpu: 50m
memory: 5Mi
limits:
cpu: 100m
memory: 20Mi
ports:
- containerPort: 8080스케일링의 기준은 limits가 아닌 requests이다.
kubectl exec myapp-deploy-hpa-57f5f475d-zgs8x -- sha256sum /dev/zero명령어를 통해 부하를 테스트해 보자.
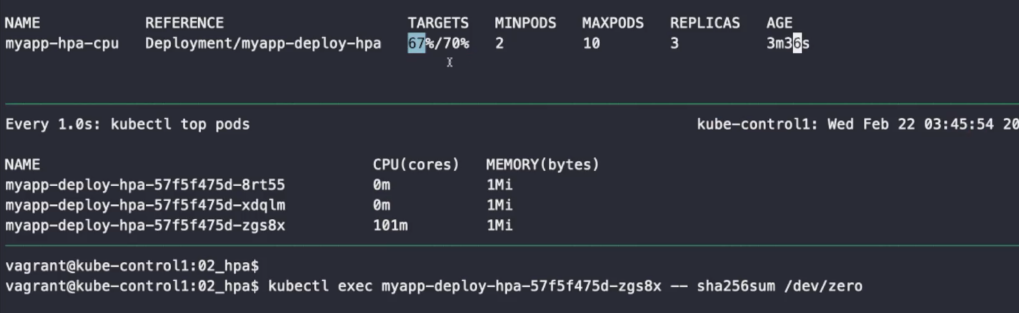
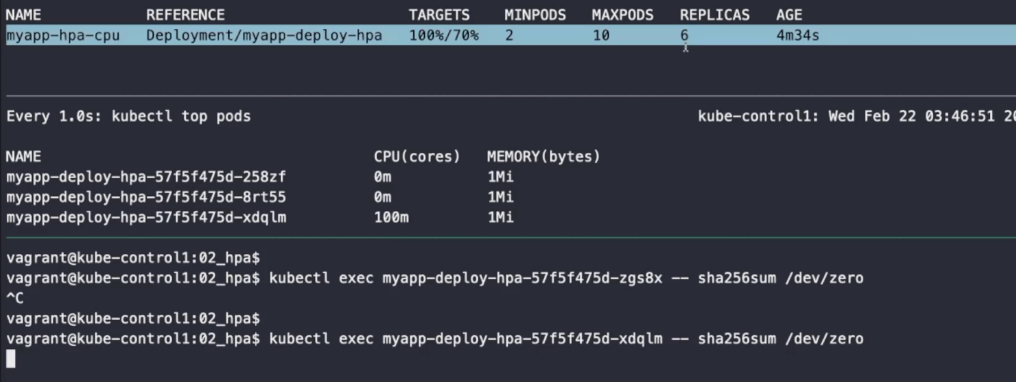

부하가 늘어나 복제본의 수도 늘어난 것을 확인할 수도 있다.
- stabilizationWindowSeconds
실제 리소스가 기준치에서 계속 왔다갔다 할 때가 있다. 이 때 즉시 스케일업 하거나 스케일다운하면 오히려 스케일링할 때 리소스가 더 많이 들게 된다. 이것을 방지하기 위해 기준 이하 혹은 이상으로 설정한 시간 이상 지속되어야 스케일업/스케일다운 하도록 하는 세팅이다.
