
파드 스케줄링
꼭 알아야 하는 개념이다.
nodeName
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: myapp-rs-nn
spec:
replicas: 2
selector:
matchLabels:
app: myapp-rs-nn
template:
metadata:
labels:
app: myapp-rs-nn
spec:
nodeName: kube-node1 #특정 파드를 특정 노드에 배치시킬 수 있다.
containers:
- name: myapp
image: ghcr.io/c1t1d0s7/go-myweb:alpine기본적으로 모든 복제본이 같은 노드에 배치되기 때문에 고가용성에 문제가 발생할 수 밖에 없다. 따라서 잘 사용하지 않는다.

모두 같은 노드에 배치된 것을 확인할 수 있다.
노드네임은 어피니티, 안티 어피니티, 테인트와 톨러레이션을 무시한다. 스케줄러에 의해 배치되는 것이 아닌 사용자가 강제로 배치하는 것이기 때문이다.
nodeSelector
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: myapp-rs-ns
spec:
replicas: 2
selector:
matchLabels:
app: myapp-rs-ns
template:
metadata:
labels:
app: myapp-rs-ns
spec: #파드의 스펙
nodeSelector:
gpu: highend #nodeSelector의 값, gpu label값이 highend인 것에만 배치
containers:
- name: myapp
image: ghcr.io/c1t1d0s7/go-myweb:alpinekubectl label node kube-node1 gpu=lowend
kubectl label node kube-node1 gpu=highend
kubectl label node kube-node1 gpu=highend
이와 같이 공통적인 레이블을 설정했을 때, yaml 파일의 내용대로라면 gpu가 highend인 노드에만 배치할 수 있다. 노드는 동일한 레이블을 가진 노드를 여러 개 만들 수 있기 때문에 레이블을 통해 노드를 특정 구릅으로 묶을 수 있다.
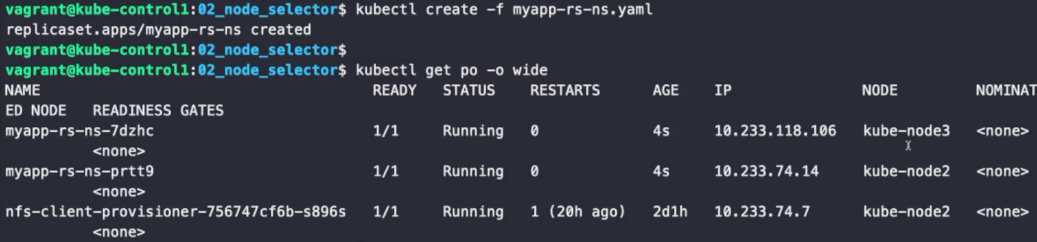
gpu 레이블이 highend인 노드에만 배치된 것을 확인할 수 있다. 기본적으로 파드를 특정 노드에 배치시키기에 가장 편한 것은 노드의 레이블을 이용하는 것이다.
어피니티 (affinity)

CKA에 나오므로 꼭 알아둬야 한다
어피니티를 통하면 파드를 정말 원하는 상태로 배치할 수 있다. 어피니티/안티-어피니티 기능은 표현할 수 있는 제약 종류를 크게 확장한다. 어피니티는 엔터프라이즈 환경에서 VM과 시스템 사이의 친화성을 의미하던 말이다. 이를 쿠버네티스 환경에서도 설정할 수 있다.
어피니티의 종류는 세 가지가 있다. 노드 어피니티, 파드 어피니티, 파드의 안티 어피니티이다.
노드 어피니티
노드와 파드 간의 친화성을 의미한다. 노드 어피니티는 노드 셀렉터와 비슷하다.
- requiredDuringSchedulingIgnoredDuringExecution
하드 개념이다. 스케줄링이 될 때(처음 만들어질 때) 요구한다. 실행되는 중에는 무시된다. 이미 배치된 것은 절대 바뀌지 않는다는 뜻이다. 규칙이 만족되지 않으면 스케줄러가 파드를 스케줄링할 수 없다. 이 기능은 nodeSelector와 유사하지만, 좀 더 표현적인 문법을 제공한다.- nodeSelectorTerms
무조건 지켜져야 하는 것이므로 가중치가 없다. 노드에 있는 레이블을 설정하면 된다.
- nodeSelectorTerms
- preferredDuringSchedulingIgnoredDuringExecution
소프트 개념이다. 스케줄링이 될 때(처음 만들어질 때) 선호한다. 실행되는 중에는 무시된다. 이미 배치된 것은 절대 바뀌지 않는다는 뜻이다. 스케줄러는 조건을 만족하는 노드를 찾으려고 노력한다. 해당되는 노드가 없더라도, 스케줄러는 여전히 파드를 스케줄링한다.- preference
실제로 선호하는 값을 설정하는 것이다.- matchExpressions
노드의 레이블이다. 노드의 레이블을 매칭 시킨다. - matchFields
노드의 필드이다. 노드의 스펙에 따른 필드 설정을 의미한다.
- matchExpressions
- weight
선호하는 값의 가중치를 의미한다. 가중치가 높은 것을 더 많이 반영한다. 정수값으로 설정한다.
- preference
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: myapp-rs-nodeaff
spec:
replicas: 2
selector:
matchLabels:
app: myapp-rs-nodeaff
template:
metadata:
labels:
app: myapp-rs-nodeaff
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution: #반드시 (hard)
nodeSelectorTerms:
- matchExpressions:
- key: gpu-model #gpu 모델이
operator: In
values:
- '3080' #3080 혹은 2080인 것만
- '2080'
preferredDuringSchedulingIgnoredDuringExecution: #선호 (soft)
- weight: 10 #가중치
preference:
matchExpressions:
- key: gpu-model
operator: In
values:
- titan #gpu 모델이 titan인걸 선호
containers:
- name: myapp
image: ghcr.io/c1t1d0s7/go-myweb:alpinekubectl label node kube-node1 gpu-model=3080
kubectl label node kube-node2 gpu-model=2080
kubectl label node kube-node3 gpu-model=1660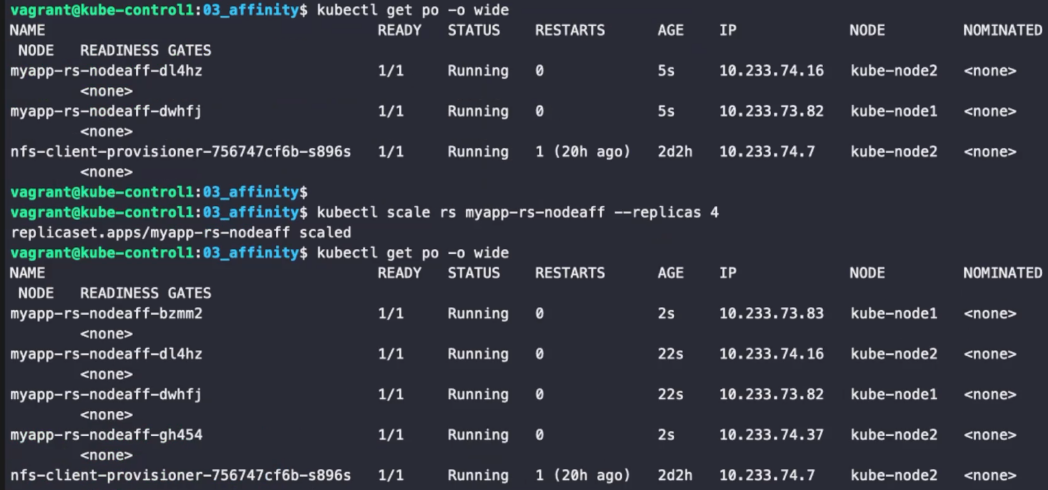
required에 설정된 레이블과 맞는 노드에만 배치된 것을 확인할 수 있다. 사실 노드셀렉터가 간편하기 때문에 노드 셀렉터를 사용하는 편이 훨씬 편하지만, 노드 어피니티는 소프트한 설정을 할 수 있다는 장점이 있다.
파드 어피니티와 파드의 안티 어피니티
파드 어피니티는 파드와 파드 간의 친화성을 의미한다. 파드의 안티 어피니티는 파드와 파드가 떨어져 있어야 하는 것을 의미한다. 파드 어피니티 역시 노드 어피니티와 마찬가지로
- requiredDuringSchedulingIgnoredDuringExecution
- preferredDuringSchedulingIgnoredDuringExecution
필드가 존재한다.
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: myapp-rs-aff-cache
spec:
replicas: 2
selector:
matchLabels:
app: myapp-rs-aff-cache
tier: cache #tier 레이블 값이 cache인 파드가 선택 됨
template:
metadata:
labels:
app: myapp-rs-aff-cache
tier: cache #파드의 레이블
spec:
affinity:
podAntiAffinity: #파드끼리 안 친하다 = 반드시 다른 노드에 배치되어야 한다
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions: #파드의 레이블
- key: tier
operator: In
values:
- cache #tier 레이블이 cache인 파드를 서로서로 붙여놓지 않는다.
topologyKey: "kubernetes.io/hostname" #노드의 레이블. 어피니티/안티 어피니티의 기준이다.
containers:
- name: myapp
image: ghcr.io/c1t1d0s7/go-myweb:alpinecache와 front는 세트이다.
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: myapp-rs-aff-front
spec:
replicas: 2
selector:
matchLabels:
app: myapp-rs-aff-front
tier: frontend
template:
metadata:
labels:
app: myapp-rs-aff-front
tier: frontend
spec:
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: tier #tier 레이블이 프론트엔드인 파드는 무조건 떨어져서 생성된다.
operator: In
values:
- frontend
topologyKey: "kubernetes.io/hostname"
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: tier #tier 레이블이 캐시인 파드와 무조건 붙어야 한다.
operator: In
values:
- cache
topologyKey: "kubernetes.io/hostname"
containers:
- name: myapp
image: ghcr.io/c1t1d0s7/go-myweb:alpine해당 yaml 파일을 실행하면 파드 4개가 생성된다. topologyKey에 설정된 노드의 레이블이 설정되어 있는 노드를 기준으로 파드를 붙이거나 떨어뜨린다.
tier 레이블 값이 cache인 파드끼리는 서로 떨어지고, 이 것은 frontend 파드끼리도 마찬가지이다. 하지만 frontend 파드에서 파드 어피니티로 cache 파드를 설정했으므로, cache와 frontend는 같은 노드에 생성된다. 파드 어피니티가 설정되지 않으면 cache와 frontend처럼 함께 배치되어야 할 파드가 따로따로 배치될 수도 있다.
노드 간에도 네트워크로 연결이 되어 있으므로 다른 노드에 배치된 파드끼리 통신할 수 있지만 결국 네트워크의 홉 수가 증가하기 때문에 성능에 영향을 미칠 수 있다. 따라서 같은 노드에 배치되는 것이 빠르고 성능이 좋다.
예를 들어, 쿠버네티스를 AWS 환경에 올리게 되면 노드는 ec2 인스턴스가 된다. 이 ec2 인스턴스는 반드시 가용영역을 구분해야 한다. (서울로 예를 들면 가용 영역이 4개) 파드를 배치할 때 고가용성을 위해선 서로 다른 가용영역에 배치하는 편이 좋다. 실제로 가용 영역을 구분해주는 레이블이 있는데,topologyKey를 통해 해당 레이블로 구분해 주면 다른 가용 영역으로 배치시킬 수 있다.

이와 같이 cache가 배치된 파드에만 front가 배치된 것을 확인할 수 있다.
테인트(Taints), 톨러레이션(Tolerations)
테인트와 톨러레이션은 함께 작동하여 파드가 부적절한 노드에 스케줄되지 않게 한다. 하나 이상의 테인트가 노드에 적용되는데, 이것은 노드가 테인트를 용인하지 않는 파드를 수용해서는 안 된다는 것을 나타낸다. 테인트와 톨러레이션은 전용 노드, 특별한 하드웨어가 있는 노드에 주로 쓰인다.
지금까지는 파드가 특정 노드를 고르는 형태였다면, 테인트와 톨러레이션은 노드를 기준으로 생각한다. 노드 기준으로 어떤 파드는 해당 노드에 배치될 수 있는지, 배치될 수 없는지를 판단한다. 따라서, 테인트는 노드에만 설정 가능하다. 테인트는 노드에 역할을 부여한다고 말할 수 있다.
테인트와 톨러레이션은 항상 짝으로 작동한다. 톨러레이션은 비자와 비슷한 기능을 한다. 톨러레이션은 파드에 설정되어 테인트에 부여된 역할에 파드가 합당한지 아닌지 확인한다.
effect 필드 값의 효과는 다음과 같다.

원 노드 클러스터의 경우 해당 명령어를 반드시 실행해야 한다.
kubectl taint nodes --all node-role.kubernetes.io/control-plane- #제거
#json 형태로 node.spec.taints 항목에 설정된 테인트를 볼 수 있다. 현재는 컨트롤 노드에만 설정되어 있다.
kubectl get nodes kube-control1 -o jsonpath='{.spec.taints}'
[{"effect": "NoSchedule", "key": "node-role.kubernetes.io/master"}]
#파드가 해당 key에 부합하는 톨러레이션이 없으면 effect 행동(스케줄링 금지)를 한다.
kubectl get nodes kube-node1 -o jsonpath='{.spec.taints}'
kubectl get nodes kube-node2 -o jsonpath='{.spec.taints}'
kubectl get nodes kube-node3 -o jsonpath='{.spec.taints}'kubectl taint nodes node1 key1=value1:NoSchedule #value가 없을수도 있다.kubectl taint node kube-node1 env=production:NoSchedule #파드가 배치되지 않은 노드에 taint 설정
노드1에 설정된 것을 확인할 수 있다.
kubectl taint node kube-node1 env- #taint 해제톨러레이션이 없는 경우
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: myapp-rs-notol
spec:
replicas: 1
selector:
matchLabels:
app: myapp-rs-notol
tier: backend
template:
metadata:
labels:
app: myapp-rs-notol
tier: backend #티어가 백엔드
spec:
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: tier
operator: In
values:
- cache #캐시를 안티 어피니티 = 노드1에서밖에 배치안됨
topologyKey: "kubernetes.io/hostname"
containers:
- name: myapp
image: ghcr.io/c1t1d0s7/go-myweb:alpinekubectl create -f myapp-rs-notol.yaml

안티 어피니션과 톨러레이션이 없기 때문에 배치되지 않고 Pending 상태에 머물러 있는것을 확인할 수 있다.
톨러레이션이 있는 경우
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: myapp-rs-tol
spec:
replicas: 1
selector:
matchLabels:
app: myapp-rs-tol
tier: backend
template:
metadata:
labels:
app: myapp-rs-tol
tier: backend
spec:
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: tier
operator: In
values:
- cache #캐시를 안티 어피니티
topologyKey: "kubernetes.io/hostname"
tolerations: #톨러레이션이 있음
- key: env #키
operator: Equal
value: production #값
effect: NoSchedule
containers:
- name: myapp
image: ghcr.io/c1t1d0s7/go-myweb:alpine
노드1에 배치된 것을 확인할 수 있다.
커든(cordon), 드레인(drain)
커든은 해당되는 노드에 스케줄링이 불가능하도록 설정한다. 즉, 더 이상 파드가 배치되지 않도록 한다는 의미이다. 커든은 보통 유지보수를 위해 우선 스케줄링을 막을 때 사용한다.
kubectl cordon kube-node3
SchedulingDisabled라고 STATUS가 설정되어 있는 것을 확인할 수 있다.
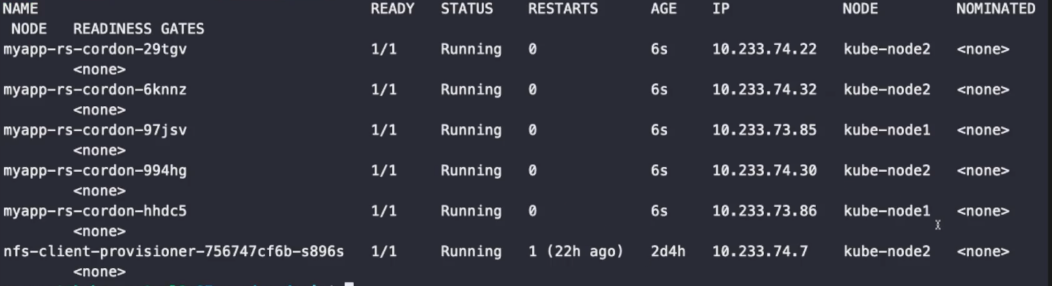
node3에 배치되어 있지 않은 것을 확인할 수 있다.
kubectl uncordon kube-node3 #커든을 해제하여 다시 스케줄링될 수 있도록 한다.drain은 해당 노드에 이미 배치되어 있는 모든 파드를 퇴거(Evict) 시킨다.
kubectl drain kube-node3
해당 명령어를 실행하면 에러가 뜰 때가 있다. 하지만 데몬셋에서 관리하는 파드는 복제본 컨트롤러가 아니기 때문에 없어지면 작동하지 못한다. 복제본 컨트롤러가 관리하는 파드는 자동으로 재생성되어 문제되지 않는다.
kubectl drain kube-node3 --ignore-daemonsets명령어를 사용하면 데몬셋이 관리하는 파드들도 삭제할 수 있다. 드레인한 후 파드를 재시작해도 코든이 되어 있다. 이 cordon을 uncordon 명령어를 사용하여 수동으로 풀어줘야 한다. 자동으로 cordon이 되기 때문에 drain할 때 따로 cordon을 해줘야 할 필요는 없다.
