
워크로드 리소스 (컨트롤러)
디플로이먼트, 레플리카셋, 스테이트풀셋, 데몬셋, 잡, 크론잡, 레플리케이션 컨트롤러의 기능으로 이루어져 있다. 디플로이먼트와 스테이트풀셋은 쿠버네티스의 최상위 컨트롤러이기 때문에 매우 중요하다.
레플리케이션 컨트롤러 (rc)
https://kubernetes.io/ko/docs/concepts/workloads/controllers/replicationcontroller/ 참조
ReplicaSet을 구성하는 Deployment가 현재 권장하는 레플리케이션 설정 방법이다.
레플리케이션 컨트롤러와 레플리카셋은 같은 기능을 구현하지만, 레플리케이션 컨트롤러는 나중에 없어질 예정이므로 레플리카셋을 사용하는게 권장된다.
레플리케이션 컨트롤러는 언제든지 지정된 수의 파드 레플리카(복제본)이 실행 중임을 보장한다. 복제본을 두는 근본적인 이유는 고가용성을 위해서인데, 이를 위해 사용하는 워크로드 리소스이다. 분산형 리소스의 구성을 쉽게 해준다.
apiVersion: v1
kind: ReplicationController
metadata:
name: nginx
spec:
replicas: 3 #복제본의 수
selector:
app: nginx
template: #pod의 오브젝트를 설명
metadata:
name: nginx
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx
ports:
- containerPort: 80kubectl get rc #rc의 내용을 확인한다
kubectl explain rc.spec.template #템플렛 정보를 확인replicas의 default 값은 1이므로 기본적으로 하나의 복제본이 생성된다.
레플리케이션 컨트롤러 파일을 실행하면, 레플리케이션 컨트롤러가 파드를 만들게 된다. 레플리케이션 컨트롤러가 파드를 어떻게 만들어야 하는지 설명한 것이 template이다. metadata는 파드의 스펙과 똑같다.
selector는 내가 관리할 파드들이 app: nginx라는 레이블을 가지는 파드만이라는 것을 알려준다. 레이블의 기능 중 하나인 리소스와 리소스의 연결을 셀렉터를 통해 구현할 수 있다. 셀렉터의 이름과 레이블의 이름은 무조건 같아야 한다.
파드를 수동으로 지우면 레플리케이션 컨트롤러 입장에선 세 개가 있어야 할 복제본이 하나가 줄어든 것이므로 삭제된 것이 확인된 순간 새로운 복제본을 하나 생성한다. 파드의 레이블을 변경하면 이 파드는 그 순간부터 레플리케이션 컨트롤러에서 관리하지 않는다. 따라서, 레플리케이션 컨트롤러는 복제본의 수를 맞추기 위해 하나의 복제본을 더 생성한다.
레이블을 다시 원래대로 바꿔 설정한 레플리카의 수가 넘어가면 넘어가는 수 만큼 삭제한다.
- 만들어진 파드의 로그를 확인하는 방법
kubectl logs pod/ngnix-xvbmz | head -2
kubectl logs rc/ngnix |head -2
kubectl logs rc ngnix | head -2레플리케이션 컨트롤러 메타데이터의 레이블은 셀렉터, 템플릿과 관련이 없다.
레플리카셋 (rs)
https://kubernetes.io/ko/docs/concepts/workloads/controllers/replicaset/ 참조
레플리카셋의 목적은 레플리카 파드 집합의 실행을 항상 안정적으로 유지하는 것이다. 이처럼 레플리카 셋은 보통 명시된 동일 파드 개수에 대한 가용성을 보증하는데 사용한다. 레플리카셋은 레플리케이션 컨트롤러를 대체하고 있다. 레플리케이션 컨트롤러와 다르게 api group이 apps이다.
레플리카셋은 레플리케이션 컨트롤러와는 다르게 셀렉터에 matchExpressions와 matchLabels라는 하위 필드가 있다. 레플리케이션 컨트롤러는 일치성 기준 요건만 사용할 수 있지만, 레플리카셋은 일치성 기준 요건과 집합성 기준 요건 두 가지 모두 지원한다.
레플리카셋은 matchLabels(일치성 기준 요건)를 주로 사용한다.
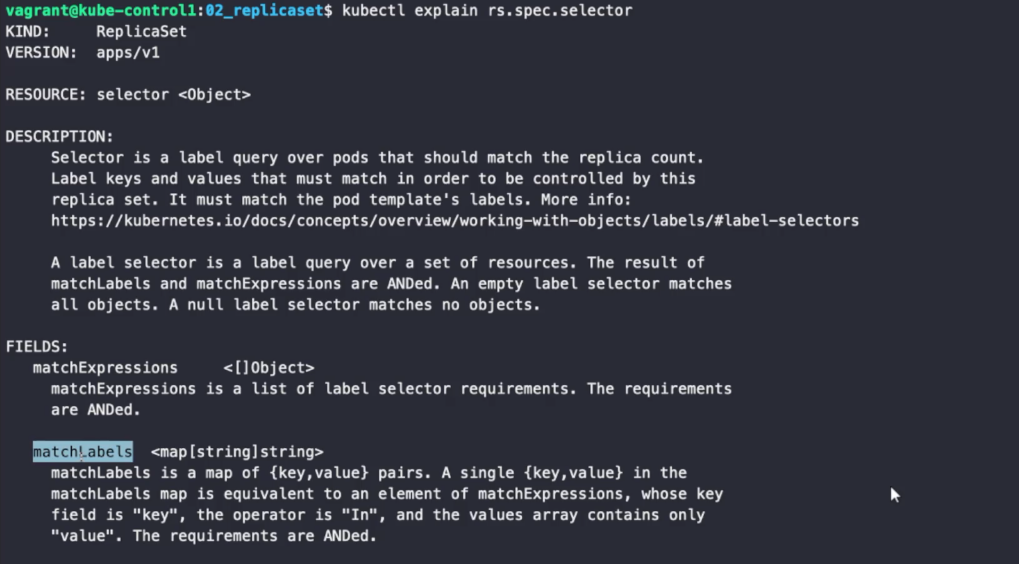
matchLabels
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: frontend
labels:
app: guestbook
tier: frontend
spec:
# 케이스에 따라 레플리카를 수정한다.
replicas: 3
selector:
matchLabels:
tier: frontend #일치
template:
metadata:
labels:
tier: frontend #일치
spec:
containers:
- name: php-redis
image: gcr.io/google_samples/gb-frontend:v3matchLabels는 템플릿의 labels와 항상 일치 해야 한다.
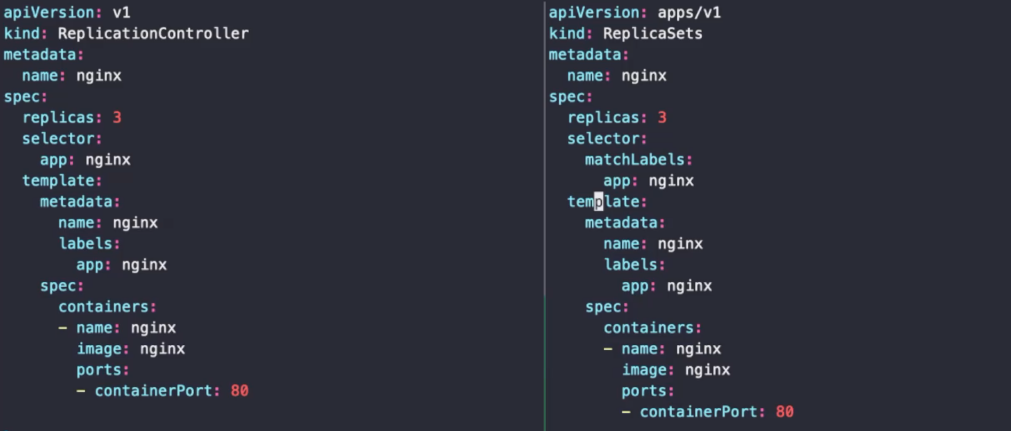
좌측과 우측은 동일한 기능을 가진다.
matchExpressions
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: myapp-rs-exp
spec:
replicas: 3
selector:
matchExpressions:
- key: app #셀렉터를 할 키
operator: In #연산자
values:
- myapp-rs-exp #In은 value가 있어야 하고, notIn은 value가 없어야 한다.
- key: env
operator: Exists #key가 있는지 없는지만 확인
template:
metadata:
labels:
app: myapp-rs-exp
env: dev
spec:
containers:
- name: myapp
image: ghcr.io/c1t1d0s7/go-myweb:alpine
ports:
- containerPort: 8080데몬셋(ds)
https://kubernetes.io/ko/docs/concepts/workloads/controllers/daemonset/ 참조
데몬셋은 모든(또는 일부) 노드(컨트롤플레인을 포함한) 가 파드의 사본을 실행하도록 한다. 백그라운드에서 실행되는 프로세스 형태를 모두 데몬이라고 한다. 노드가 클러스터에 추가되면 파드도 추가된다. 노드가 클러스터에서 제거되면 해당 파드는 가비지(garbage)로 수집된다. 데몬셋을 삭제하면 데몬셋이 생성한 파드들이 정리된다. 데몬셋은 레플리카셋과 다르게 복제본을 제공하지 않는다.
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: myapp-ds
spec:
selector:
matchLabels:
app: myapp-ds
template:
metadata:
labels:
app: myapp-ds
spec:
nodeSelector: #노드 셀렉터가 pod spec에 지정되어 있다.
node: development
containers:
- name: myapp
image: ghcr.io/c1t1d0s7/go-myweb:alpine
ports:
- containerPort: 8080데몬셋은 무조건 노드에 하나씩 생성된다. 다만, 컨트롤플레인은 사용자가 생성한 일반적인 파드는 배치되지 않도록 되어 있으므로 생성되지 않는다. 데몬셋은 별도의 설정 필요 없이 노드가 새로 생성되면 자동으로 하나씩 생성된다.
복제본은 균등하게 배분하는 것 보다는 갯수가 중요하지만, 데몬셋은 무조건 하나의 노드에 하나씩 생성된다. 따라서, 노드의 상태에 따라 생성되지 않는 상황이 나올 수도 있다.
데몬셋은 보통 인프라를 지원하기 위한 인프라로 작동한다. 데몬셋의 대표적인 용도는 다음과 같다.
- 모든 노드에서 클러스터 스토리지 데몬 실행
- 모든 노드에서 로그 수집 데몬 실행
- 모든 노드에서 노드 모니터링 데몬 실행
데몬셋은 모든 노드가 아니라 일부 노드에만 배치할 수 있다. 이 때 사용하는 것이 노드 셀렉터이다. 노드 셀렉터는 노드의 레이블이 일치하는지 본다. 노드 셀렉터는 파드의 스펙을 작성하는 곳에 사용할 수 있다.

잡(Jobs)
https://kubernetes.io/ko/docs/concepts/workloads/controllers/job/ 참조
잡은 배치 그룹에 위치해 있다. 잡에서 하나 이상의 파드를 생성하고 지정된 수의 파드가 성공적으로 종료 될 때까지 계속해서 파드의 실행을 재시도한다. rc, rs, ds 등의 컨트롤러는 어플리케이션을 계속적으로 실행할 수 있도록 보장하는 것이지 종료를 보장하지는 않는다. 하지만 잡은 어플리케이션의 종료를 보장하므로, 어플리케이션이 제대로 종료되지 않으면 어플리케이션을 재시작한다.
간단한 사례는 잡 오브젝트를 하나 생성해서 파드 하나를 안정적으로 실행하고 완료하는 것이다. 첫 번째 파드가 실패 또는 삭제된 경우(예로는 노드 하드웨어의 실패 또는 노드 재부팅) 잡 오브젝트는 새로운 파드를 기동시킨다.
apiVersion: batch/v1
kind: Job
metadata:
name: pi
spec:
completions: 3 #완료 횟수
parallelism: 3 #병렬
backoffLimit: 3 #재시작 횟수
activeDeadlineSeconds: 3 #3초 안에 스케쥴링이 되지 않는 작업이 있는지 체크
template:
spec:
containers:
- name: pi
image: perl:5.34.0
command: ["perl", "-Mbignum=bpi", "-wle", "print bpi(2000)"]#커맨드는 entrypoint를 대체한다.
restartPolicy: Never
backoffLimit: 4

completions는 작업이 완료한 횟수를 나타낸다.
parallelism을 통해 작업을 병렬로(동시에) 실행시킬 수 있다.
다음은 잡 설정 예시이다. 예시는 파이(π)의 2000 자리까지 계산해서 출력한다. 이를 완료하는 데 약 10초가 소요된다. 잡은 종료를 실행하기 때문에 restartPolicy를 기본값인 Always에서 Never 혹은 OnFailure로 바꾸지 않으면 실행되지 않는다.
kubectl apply -f https://kubernetes.io/examples/controllers/job.yaml
watch -n1 kubectl get jod,pods
kubectl get job,pods #내용 확인
kubectl logs pi-44xrx # 파드 중 하나를 표준 출력으로 확인반드시 종료되는 작업은 잡으로 실행하는 것이 좋다. 또한, 셀렉터는 웬만하면 지정하지 않는다.
크론잡(cj)
https://kubernetes.io/ko/docs/concepts/workloads/controllers/cron-jobs/ 참조
비교적 최근에 stable이 되었다. (v1.21) 크론잡은 반복 일정에 따라 잡을 만든다. 크론잡은 잡을 크론 형식으로 쓰여진 주어진 일정에 따라 주기적으로 동작시킨다.
크론잡은 잡을 만들어 잡을 특정 반복 일정마다 실행시킨다. 크론잡이 잡을 생성하고, 생성된 잡이 파드를 생성한다. 레이블이나 셀렉터는 지정하지 않는다.
apiVersion: batch/v1
kind: CronJob
metadata:
name: hello
spec: #cronjob의 스펙
schedule: "* * * * *"
jobTemplate:
spec: #job의 스펙
template:
spec: #pod의 스펙
containers:
- name: hello
image: busybox:1.28
imagePullPolicy: IfNotPresent
command:
- /bin/sh
- -c
- date; echo Hello from the Kubernetes cluster
restartPolicy: OnFailure
# ┌───────────── 분 (0 - 59)
# │ ┌───────────── 시 (0 - 23)
# │ │ ┌───────────── 일 (1 - 31)
# │ │ │ ┌───────────── 월 (1 - 12)
# │ │ │ │ ┌───────────── 요일 (0 - 6) (일요일부터 토요일까지;
# │ │ │ │ │ 특정 시스템에서는 7도 일요일)
# │ │ │ │ │ 또는 sun, mon, tue, wed, thu, fri, sat
# │ │ │ │ │
# * * * * *apiVersion: batch/v1
kind: CronJob
metadata:
name: myapp-cj
spec:
schedule: "* * * * *"
jobTemplate:
spec:
template:
metadata:
labels:
app: myapp-cj
spec:
restartPolicy: OnFailure
containers:
- name: sleep
image: busybox
command: ["sleep", "50"]kubectl create -f myapp-cj.yaml
watch -n1 kubectl get cj,job,pod
# 50초 정도가 지나면 파드가 종료된다. 약 1분이 지나면 하나의 잡이 실행된다.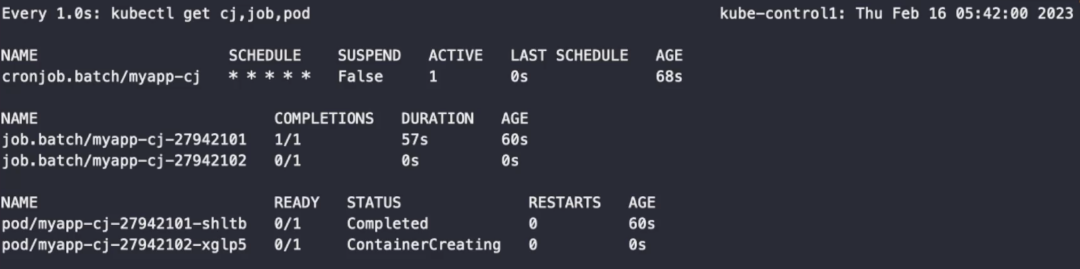


성공한 잡에 대한 히스토리는 3개, 실패한 잡의 히스토리는 1개가 저장된다.

이전 작업과 현재 작업이 동시에 존재하는 것을 concurrencyPolicy라고 한다. 이를 허용하거나 금지할 수 있다. 기본은 허용되어 있다. 금지하면 작업이 종료되기 전까지 다음 스케쥴링이 실행되지 않는다. Replace로 설정하면 다음 스케쥴링이 시작되면 이전에 시작한 작업을 종료한다.
startingDeadlineSeconds는 설정한 시간이 넘어간 작업이 있는지 확인한다. 있으면 실행한다. 이를 지정하지 않으면 이전에 스케쥴링 되지 않은 작업이 있으면 그냥 넘어간다.
