
파드 라이플사이클(생명주기)
https://kubernetes.io/ko/docs/concepts/workloads/pods/pod-lifecycle/ 참조
리소스가 만들어지기부터 더 이상 필요가 없어져 삭제될 때 까지의 주기를 생명주기라고 한다. 물리적인 서버보다 가상 머신이, 가상 머신보다 컨테이너가 생명 주기가 훨씬 짧다. 파드는 비교적 임시(계속 이어지는 것이 아닌) 엔티티로 간주된다. 따라서, 컨테이너는 최대한 상태(state)를 만들지 않는다.
파드가 만들어지면 스케쥴러를 통해 노드에 배치된다. 이 파드는 고유한 ID(UID)를 가지게 되는데, 이 ID는 바뀔 수 없다. 또한 파드의 생명 주기는 만들어진 노드에서 끝나야 한다. 배치된 파드는 다른 노드로 절대 다시 스케줄되지 않는다.
파드의 단계
파드가 라이프사이클 중 어느 단계에 해당되는지 표현하는 간단한 고수준의 요약이다. phase에 가능한 값은 다음과 같다.
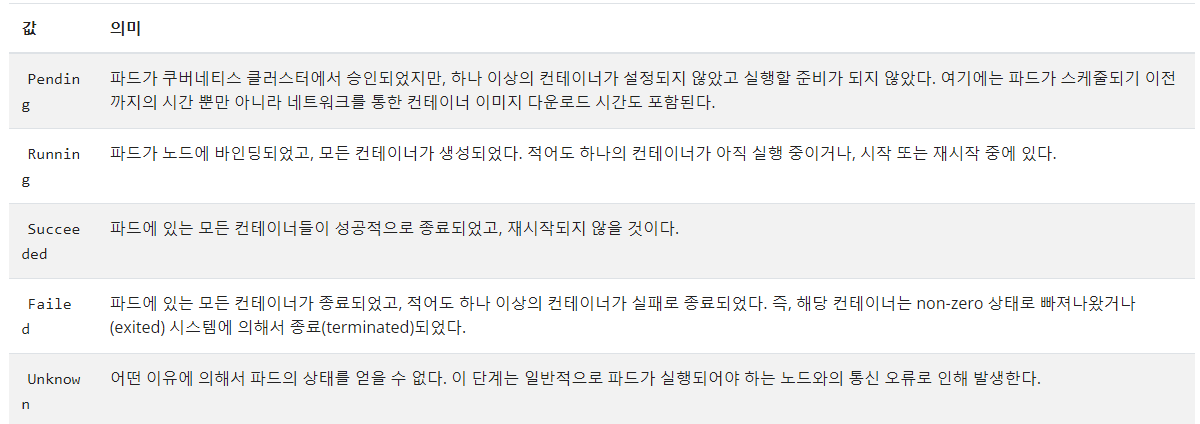
Singleton의 경우에는 관계없지만, 멀티 컨테이너인 경우 하나만 Running 상태에 있어도 phase 값이 Running으로 표현되므로 조심해야 한다.
Failed는 컨테이너를 종료했을 때 정상종료인 0이 아닌 다른 상태로 종료된 모든 상태를 의미한다.
Terminating은 엄밀히 말하면 파드의 단계는 아니다. 단순히 파드가 종료 중이라는 것을 의미한다.
파드에는 한 개 이상의 컨테이너가 존재할 수 있다. 이 컨테이너들도 Waiting, Runnig, Terminated의 세 가지의 상태로 구성된다.
컨테이너 재시작 정책
기본적으로 쿠버네티스의 컨테이너는 Self Healing 기능을 가지고 있어 오류가 발생하면(non-zero 상태일 때) 항상 자동으로 재시작한다. 도커는 기본적으로 컨테이너에 문제가 생겨도 자동으로 재시작 하지 않는다.(설정을 통해 재시작하도록 바꿀 수 있다.)
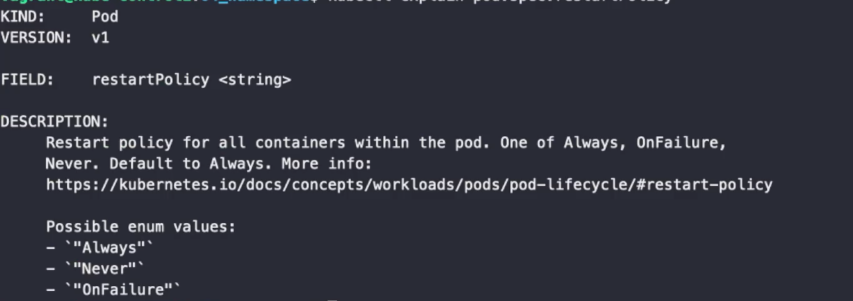
Always: 항상 재시작(기본)
Never: 재시작 하지 않음
OnFailure: non-zero 상태에서만 재시작
컨테이너 프로브
프로브는 컨테이너 내의 어플리케이션이 제대로 작동하고 있는지 진단한다. 쿠버네티스 입장에선 프로브 없이는 컨테이너가 Running 상태일 때, 컨테이너 안의 어플리케이션이 제대로 작동하는지 알아볼 수 있는 방법이 존재하지 않는다. 프로브는 kubelet을 통해 애플리케이션의 상태를 진단한다.
프로브의 종류


프로브는 컨테이너마다 설정할 수 있다. 프로브의 종류는 각각 프로빙의 목적이 다르다. 하지만, 기본적으로 체크 메커니즘은 exec, grpc, httpGet, tcpSocket으로 공통적이다.
- livenessProbe
컨테이너 안의 어플리케이션이 작동하는지 체크한다.
kubectl explain pod.spec.containers | grep Probe #프로브 종류 확인체크 메커니즘
-
exec
명령어로 실행한다. 상태 코드가 0으로 종료되면 성공이다. -
grpc
gRPC를 사용하여 원격 프로시저 호출을 수행한다. -
httpGet
Get 메세지를 보내 200이상 400미만 의 값이면 성공으로 간주한다. (100번대: information, 200번대: 성공, 300번대: 리다이렉션, 400번대: 클라이언트 오류, 500번대: 서버 오류) 일반적으로 사용한다. -
tcpSocket
TCP 포트가 열려 있는지 확인한다.
체크 메커니즘의 결과는 Success(통과), Failure(실패), Unknown(진단 자체가 실패) 세 가지로 리턴된다.
livenessProbe
apiVersion: v1
kind: Pod
metadata:
name: myapp-pod-liveness
spec:
containers:
- name: myapp
image: ghcr.io/c1t1d0s7/go-myweb:alpine
ports:
- containerPort: 8080
protocol : TCP
livenessProbe:
httpGet: #httpGet 방식으로 진단
path: /health
port: 8080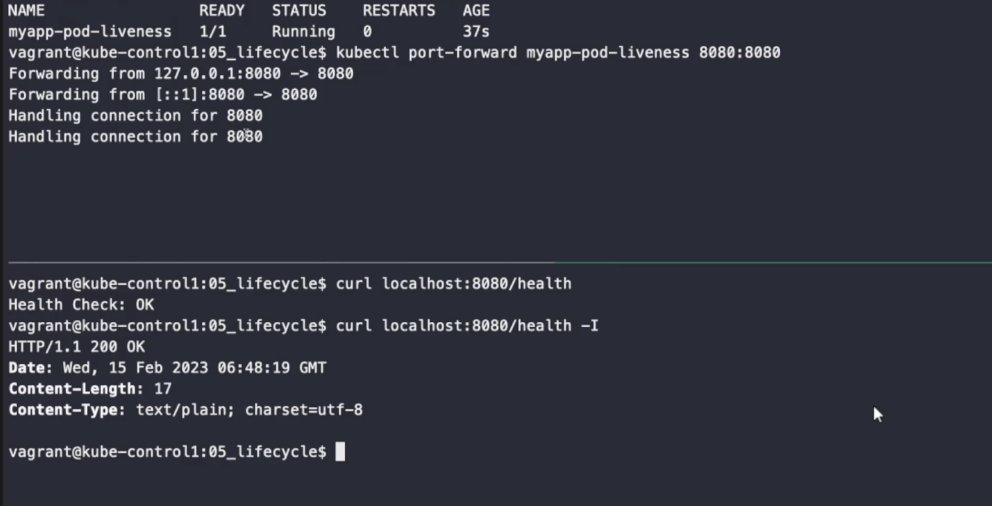
200OK 를 통해 정상적으로 작동하고 있다는 것을 확인할 수 있다.
kubectl describe pod myapp-pod-liveness
http-get 방식, http://:8080/health 경로를 진단
-
period
10초마다 한 번씩 진단 -
timeout
1초 안에 응답이 오지 않으면 실패한 것으로 간주 -
delay
period에 지연을 줌 -
failure
한 번 실패했다고 바로 실패 처리를 해 버리면 좋지 않으므로 연속으로 3번 실패하면 실패 처리 (재시작)
apiVersion: 1
kind: Pod
metadata:
name: myapp-pod-liveness-404
spec:
containers:
- name: myapp
image: ghcr.io/c1t1d0s7/go-myweb:alpine
ports:
- containerPort: 8080
protocol: TCP
livenessProbe:
httpGet:
path: /health?code=404 #일부러 404 오류가 나도록 세팅
port: 8080kubectl create -f myapp-pod-liveness-404.yaml
kubectl get pod -w #-w는 watch 옵션으로 해당되는 리소스의 목록을 foreground 상태에서 실시간으로 볼 수 있다.
3번의 실패(10초) + 재시작(1초) = 33초 뒤에 재시작하는 것을 볼 수 있다.
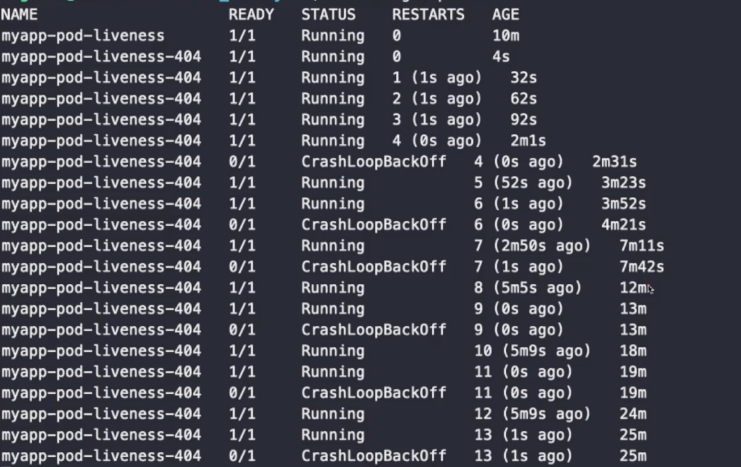

애플리케이션을 시작하는 것은 리소스를 많이 잡아먹는 작업이므로, 재시작이 반복되면 CrashLoopBackOff 이후 재시도의 간격이 점점 늘어난다(최대 5분). 컨테이너 시작 후 10분 동안 아무런 문제도 없으면 재시작 시간이 초기화된다. 이는 컨테이너 재시작 정책과 관련있다.
readinessProbe
컨테이너가 요청을 처리할 준비(Ready)가 되었는지 여부를 나타낸다. 만약 준비성 프로브(readiness probe)가 실패한다면, 엔드포인트 컨트롤러는 파드에 연관된 모든 서비스들의 엔드포인트에서 파드의 IP주소를 제거한다. 준비성 프로브의 초기 지연 이전의 기본 상태는 Failure 이다. 만약 컨테이너가 준비성 프로브를 지원하지 않는다면, 기본 상태는 Success 이다.
서비스의 엔드포인트에 등록할지 안할지 여부를 결정한다.
apiVersion: apps/v1
kind: Replicaset
metadata:
name: myapp-rs-readiness
spec:
replicas: 3
selector:
matchLabels:
app: myapp-rs-readiness
template:
metadata:
labls:
app: myapp-rs-readiness
spec:
containers:
- name: myapp
image: ghcr.io/c1t1d0s7/go-myweb:alpine
readinessProbe:
exec:
command:
- ls
- /var/ready #exec 방식의 경우 리턴 코드가 0인 경우만 성공이다. 실패하면 엔드포인트에 등록x
ports:
- containerPort: 8080 kubectl create -f myapp-rs-readiness.yaml
kubectl create -f myapp-svc-readiness.yaml
kubectl get rs,pod,svc,ep #아무것도 Ready되지 않아 엔드포인트 등록이 되지 않음
curl 10.233.57.30 #실행되지 않는다
# kubectl exec pod이름 -- 명령어
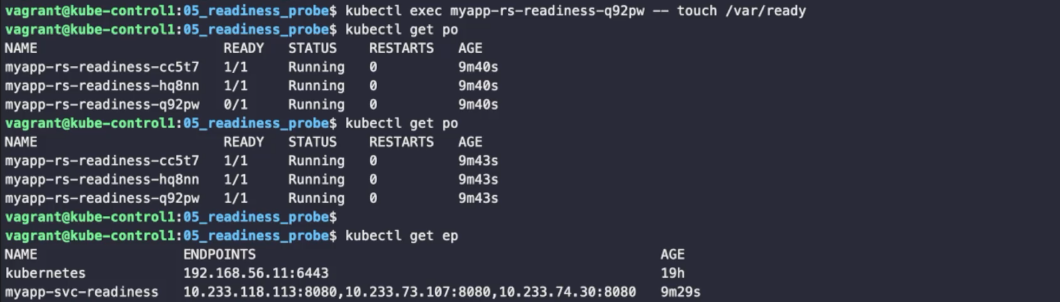
kubectl exec <pod이름> -- touch /var/ready
#readinessProbe 성립, ready 상태로 바뀌고 엔드포인트 등록이 된다.
kubectl exec <pod이름> -- rm /var/ready
#삭제되어 ready 상태에서 해제, 엔드포인트에서도 제거.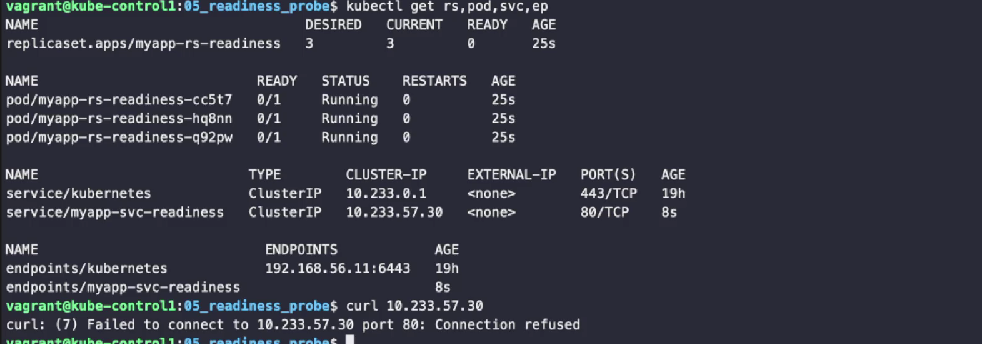
startupProbe
startupProbe는 컨테이너 내의 애플리케이션이 시작되었는지를 체크한다. 어플리케이션이 작동되었다고 판단한 후 livenessProbe 혹은 readnessProbe를 작동시킨다.
livenessProbe는 33초 뒤에 재시작하므로, 크기가 커 실행하는 데에 30초 이상의 시간이 걸리는 컨테이너 들이 제대로 실행되었는지 판단하지 못하고 다시 재시작을 걸어버린다. 이와 같이 무거운 어플리케이션을 작동시키는 경우, 애플리케이션에 아무런 문제가 없는데도 불구하고 계속해서 재시작되는 경우가 생긴다. 이러한 문제를 해결하기 위해 startupProbe가 만들어졌다.
정상적으로 실행되는 코드
apiVersion: v1
kind: Pod
metadata:
name: myapp-pod-liveness
spec:
containers:
- name: myapp
image: ghcr.io/c1t1d0s7/go-myweb:alpine
ports:
- containerPort: 8080
protocol : TCP
startupProbe: #startupProbe가 작동해야 livenessProbe가 작동
httpGet: /health
port: 8080
livenessProbe:
httpGet: #httpGet 방식으로 진단
path: /health
port: 8080startupProbe가 404 오류가 생기고, livenessProbe는 정상적으로 작동될 때
apiVersion: v1
kind: Pod
metadata:
name: myapp-pod-liveness
spec:
containers:
- name: myapp
image: ghcr.io/c1t1d0s7/go-myweb:alpine
ports:
- containerPort: 8080
protocol : TCP
startupProbe: #startupProbe가 작동해야 livenessProbe가 작동
httpGet: /health?code=404
port: 8080
livenessProbe:
httpGet: #httpGet 방식으로 진단
path: /health
port: 8080 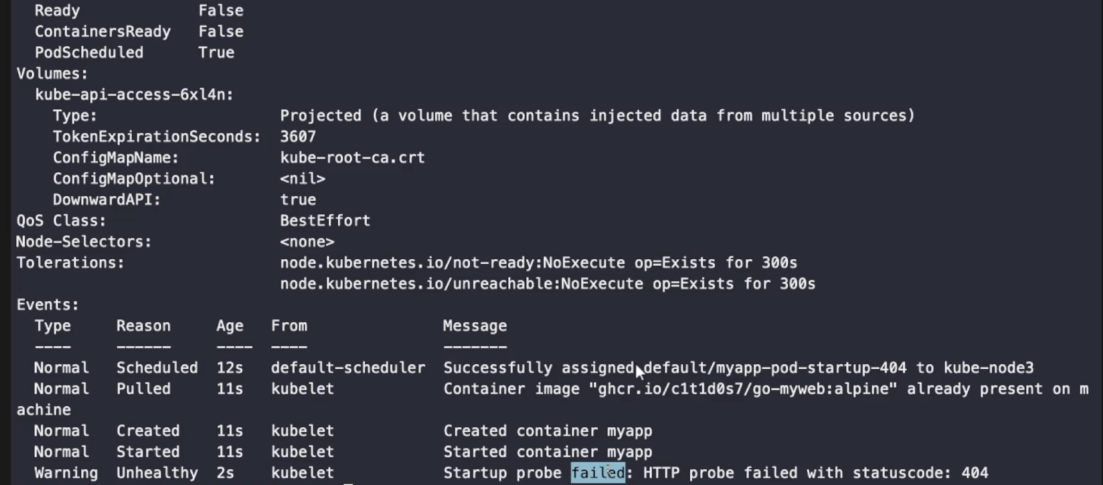
startupProbe가 정상적으로 작동되지 않기 때문에 livenessProbe가 작동되지 않는다.

Ready가 안 되는 것을 확인할 수 있다.
어플리케이션의 작동 여부를 확인하기 위해 프로브는 반드시 세팅하는 것이 추천된다.
