비트와 바이트 ⚡
컴퓨터가 이해할 수 있는 최소의 정보 단위는 0과 1이다.
컴퓨터는 이와 같은 0과 1의 조합으로 이루어진 정보들을 처리할 수 있다.
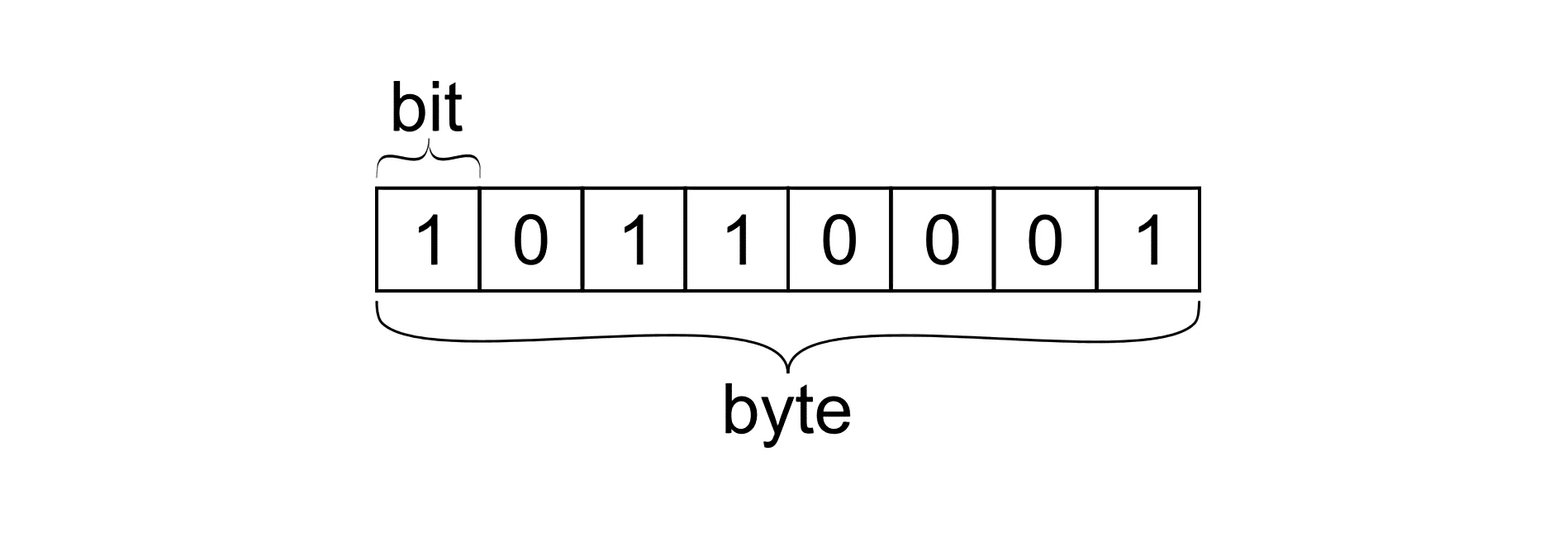
컴퓨터가 처리할 수 있는 가장 작은 단위의 정보가 비트(Bit)이다.
비트는 0 또는 1의 정보를 담을 수 있다.
한 비트당 두 가지의 경우를 나타낼 수 있으므로 n비트는 개의 정보를 나타낼 수 있다.
컴퓨터에서 데이터를 처리할 때 가장 기본적인 단위를 보통 1바이트를 사용하는데
1바이트는 8비트로 구성되어 있고 256가지의 정보를 나타낼 수 있다.
💡 갑자기 1바이트는 8비트를 보통 쓸까라는 궁금증이 생겨 찾아봤다...
보통 1바이트가 8비트인 이유 ❔❓
예전에는 4비트, 6비트를 1바이트로 처리하는 컴퓨터도 있었으나 현대의 컴퓨터는 대부분 8비트를 1바이트로 처리합니다.
검색을 해도 정확한 이유를 찾을 수 없지만 대부분의 의견은 비슷하고 합리적인 의견이라고 생각이 들었습니다. 따라서 아래의 의견들은 정확한 의견은 아닐 수 있습니다.
-
문자를 표현하는 코드들의 숫자가 7~8 비트로 충분했기 때문이다.
전자신호를 사람이 인식하는 문자로 저장을 했어야 했는데 영어의 대소문자 52자, 숫자 0~9, 제어문자(ctrl, alt, enter, space, NUL(문자열의 끝), BEL(비프음)), 특수문자 등을 포함시키는데 7비트 정도로 충분했다. -
패리티 비트의 도입
사실 1번에서 설명한 여러 문자들을 포함시켜도 7비트로 충분했을 것이다.
그러면 왜 8비트인가?
데이터 송수신의 오류를 검출하기 위해 패리티 비트를 추가하여 정보 전달 과정에서 오류가 생겼는지를 검사하기 위해 패리티 비트를 추가했기 때문일 것이다.
패리티 비트(Parity bit)🔍
정보의 전달 과정에서 오류가 생겼는지를 검사하기 위해 추가된 비트
비트와 바이트를 잘 이해해야 하는 이유 💁♂️
비트와 바이트를 잘 이해해야 하는 이유?
프로그래밍에서 변수를 선언할 때 어떤 데이터 타입이냐에 따라서 메모리에 얼마나 크게 공간이 확보되는지가 정해지는데 C, go, Rust와 같은 메모리가 넉넉하지 못한 환경에서 동작하는 프로그램 같은 경우에는 이런 데이터 타입을 알맞게 선택해서 효율적으로 작성하는 것이 중요하다.
1이라는 숫자를 2바이트, 4바이트 타입의 변수를 사용하면 메모리 낭비 발생 🤦♂️🤦♀️
프로그래밍 언어도 어디에 쓰이냐에 따라 데이터 타입이 세분화되어 있다.
아스키코드(ASCII Code) 🔠🔣
컴퓨터는 0과 1밖에 모르기 때문에 문자열을 표현해줄 방법이 필요했는데 숫자에 문자를 대응시키는 방법으로 문자를 표현해주었습니다.
사람들끼리 혹은 컴퓨터끼리 숫자마다 표현하는 문자가 다르면 불편하고 혼동이 올 수 있기 때문에 표준부호를 정해야 했고 이것이 아스키코드이다.
아스키코드는 영어만 있기 때문에 다양한 나라의 사람들이 컴퓨터를 사용하면서 다양한 표준들이 생겼고 점점 문자 표현에 충돌이 발생하고 새로운 기준이 필요해졌다.
유니코드(Unicode)
💱아스키코드 문제점을 해결하기 위해 등장한 국제 표준 코드
현재 또는 과거에 존재했던 다양한 언어의 문자를 처리하기 위한 국제 표준코드이며 2바이트의 유니코드가 등장했다.
하지만 2바이트로도 쓰지 않는 고어, 토속오 등을 담으려 하다보니 이마저도 부족했고 현재는 2바이트를 영역을 나누어(상위대행+하위대행) 총 개의 코드를 지정할 수 있고 2020년 기준 14만여개의 문자가 등록되어 있다.
텍스트 인코딩 📰
우리가 어떻게 현존하는 많은 문자열들을 바이너리 형태로 나타낼 것인지 그 규격을 약속을 하는 것이 텍스트 인코딩이다. 예전에는 각각 언어별로 나라마다 다양한 텍스트 인코딩이 존재했지만 서로 다른 인코딩 규격 때문에 웹사이트가 깨지거나 한글 문서가 읽어지지 않는 그런 문제점들이 많이 발생했는데 이것을 해결하기 위해 나온것이 UTF-8이란 인코딩이다.
UTF-8
UniCode Transformation For mat(8 bit) 가변길이 유니코드 인코딩
최근에 표준을 가장 많이 사용되고 있는 인코딩 방식
즉, 길이가 정해져 있지 않고 필요에 의해서 길어질 수 있는 것이다.
가변적으로 길이를 사용하는 이유는 기본적으로 유니코들은 1바이트에서 4바이트까지 사용한다.
아스키 문자들은 1바이트로 하나의 문자를 표현할 수 있는데 모든 문자를 4바이트를 사용하게 되면 메모리의 낭비로 이루어지기 때문에 표현 여부에 따라 길이를 가변하여 사용한다.
기존의 아스키뿐만 아니라 모든 유니코드를 나타낼 수 있는 통상적으로 많이 쓰이는 텍스트 인코딩
UTF-16
기본적으로 2바이트를 사용하고 있기 때문에
아스키코드와 같이 1바이트로 충분히 표현할 수 있음에도 불구하고 2바이트를 소모
그렇기 때문에 통상적으로 UTF-8을 사용