배경
최근 스타트업, 대기업 가릴 것 없이 데이터 분석이 유행이다. DDD(Data Driven Decision, 데이터 기반 의사결정)를 하기 위해 많은 회사에서 데이터 직무에 투자를 하고있다.
데이터가 작을 때에는 Google Analytics와 같은 툴을 사용하면 되지만, 데이터가 많아지고 디테일한 부분을 직접 분석하고 싶을 때 빅데이터 분석을 하게 된다.
기존에 많이 사용되던 Hadoop MapReduce(맵리듀스)는, 디스크로부터 map/reduce하는 데이터를 불러오고, 처리한 결과를 디스크로 쓰기 때문에 읽기/쓰기 속도가 느리다는 단점이 있다. 또한 구현하고자 하는 기능에 비해 작업해야 하는 코드가 복잡했다
이러한 한계를 극복하기 위해 Apache Spark(스파크)가 등장하였고, 기존의 단점들을 보완하였다. 기존의 맵리듀스와 달리 스파크는 메모리로부터 map/reduce 하는 데이터를 불러오고, 처리하였다. 데이터를 메모리에서 처리하기 때문에 반복형이나 대화형 업무에서 월등히 좋은 성능을 보였다
Spark(스파크)란?
- 인-메모리 기반 통합 컴퓨팅 엔진
- 빅데이터 클러스터 환경에서 데이터를 병렬 처리 할 수 있는 오픈소스 소프트웨어
스파크 구성
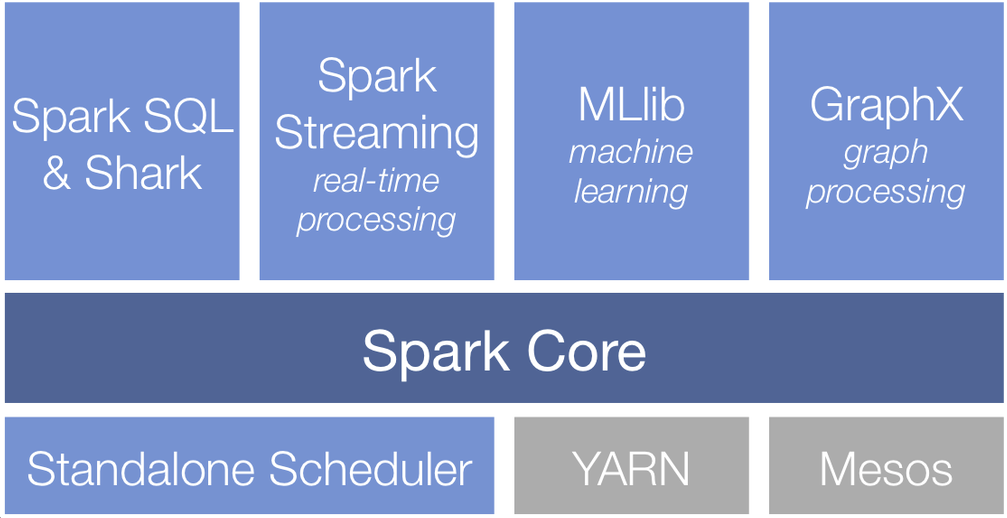
스파크 코어
- 작업 스케줄링, 메모리 관리, 장애 복구, 저장 장치와의 연동 등의 기본적인 기능들로 구성
- 탄력적 분산 데이터셋(RDD, Resilient Distributed Dataset)를 정의하는 API의 기반
=> RDD는 여러 컴퓨터 노드에 흩어져 있으면서 병렬 처리될 수 있는 아이템들의 모음
스파크 SQL
- 정형 데이터를 처리하기 위한 스파크 패키지
- SQL, 하이브 테이블, 파케이, JSON 등 다양한 데이터 소스 제공
- 아파치 하이브 SQL 변형 사용하여 데이터에 질의 보내기 가능
스파크 스트리밍
- 실시간 데이터 스트림을 가능하게 해주는 컴포넌트
ex) 웹 서버가 생성한 로그 파일, 메시지 큐 등 - RDD API와 거의 일치하는 형태의 API 지원
MLlib
- 스파크에서 머신러닝을 구현할 수 있는 라이브러리
- 분류, 회귀, 클러스터링 등 다양한 머신러닝 알고리즘 지원
그래프X
- 그래프를 다루기 위한 라이브러리
ex) SNS 친구 관계 그래프 - 스파크 SQL과 마찬가지로 스파크 RDD API 확장
- 그래프를 다루는 다양한 메소드와 일반적인 그래프 알고리즘 라이브러리 지원

데이터 엔지니어로 전향중인 백엔드 개발자입니다