스파크 구조
스파크는 크게 스파크 어플리케이션, 클러스터 매니저로 구성되어 있다

- 스파크 어플리케이션 : 실제로 작업을 수행하는 역할
- 클러스터 매니저 : 스파크 어플리케이션 사이에 자원 중계하는 역할
스파크 어플리케이션
Spark Driver(스파크 드라이버)와 Executor(익스큐터)로 구성된다
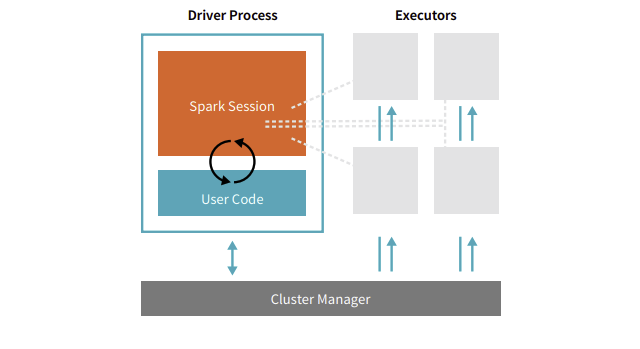
1. Driver Process(드라이버 프로세스, Spark Driver)
- 하나의 노드에서 실행되며, 스파크 전체의 main()함수 실행
- 스파크 어플리케이션 내의 정보 유지/관리
- 사용자 프로그램이나 입력에 대한 응답
- 배포 및 스케줄링
- 사용자가 구성한 사용자 프로그램을 task단위로 변환하여 Executor로 전달
2. Executor Process(익스큐터 프로세스, Executor)
- 다수의 worker 노드에서 실행되는 프로세스
- 스파크 드라이버가 할당한 작업(task)을 수행하여 결과 반환
- 클러스터 매니저에 의하여 스파크 어플리케이션에 할당 => 스파크 어플리케이션이 종료된 후에 할당에서 해방
- 1개의 Spark Driver + N개의 Executor = 스파크 어플리케이션
- 서로 다른 스파크 어플리케이션 사이의 직접적인 데이터 공유 불가능
클러스터 매니저
- 스파크와 붙이거나 뗄 수 있는 Pluggable한 컴포넌트
- 스파크 어플리케이션의 리소스를 효율적으로 분배하는 역할
- Spark StandAlone, 하둡 YARN, 메소스 등이 있다
스파크 어플리케이션 실행 과정
- 사용자가
spark-submit을 통해 어플리케이션 제출 - Spark Driver(스파크 드라이버)가 main() 실행하며 SparkContext 생성
- Spark Context가 클러스터 매니저와 연결
- 스파크 드라이버가 클러스터 매니저로부터 익스큐터 실행을 위한 리소스 요청
- Spark Context는 작업 내용을 task 단위로 분할하여 익스큐터에 보냄
- 각 익스큐터는 작업을 수행한 후 결과 저장
Spark Submit
- 클러스터 매니저에게 Spark Application을 제출하는 툴
spark-submit \
--class <main-class> \
--master <master-url> \
--deploy-mode <deploy-mode> \ # 실행한 스파크 어플리케이션의 드라이버 프로그램이 어디서 실행되는가
--conf <key>=<value> \ # 복수로 지정 가능
... other options \
<app jar | python file | R file>Deploy Mode
- Client 모드
- Driver Program은 spark-submit의 일부로 실행됨 (SparkSubmit)
- Driver Program의 출력을 콘솔에서 직접 확인 가능 (stdout, stderr)
- Application이 실행하는 동안 Worker Node에 계속 연결되어 있음
- Cluster 모드
- Driver Program이 클러스터 내의 Worker Node 중 하나에서 실행
- 실행 후 개입하지 않는 방식 (제출 후 연결 끊김)
- 파이썬 지원 X
Dependency Libraries
- Cluster Node들에 해당 라이브러리가 위치해야 함
- 파이썬의 경우 클러스터의 파이썬 패키지 매니저를 사용하여 직접 설치
- --py-files 옵션을 사용하여 라이브러리 제출 (.zip, .egg or .py files)
Master URL
- local
워커 쓰레드 하나로 로컬에서 스파크 구동 - local[K]
K개의 워커 쓰레드로 로컬에서 스파크 구동 - local[*]
가능한 많은 워커 쓰레드로 로컬에서 스파크 구동

데이터 엔지니어로 전향중인 백엔드 개발자입니다