이상거래 탐지 관련 머신러닝을 공부하다가(Kaggle : Credit card fraud detection), 성능 지표에 대한 개념을 맞닥뜨려 본 게시물을 작성하게 되었다.
오늘 포스팅 하는 Classification Evaluation Metrics(분류 성능 지표)에는 accuracy, precision, recall, F1 score 등의 평가지표들이 있다. 이러한 평가지표들을 알아보기 전에 Confusion Matrix(혼동 행렬)을 먼저 짚고 넘어간다
Confusion Matrix(혼동행렬)
Confusion Matrix란, 모델이 예측한 라벨(Predicted Class)와 타겟의 실제 라벨(Actual Class)을 비교하기 위한 표이다.
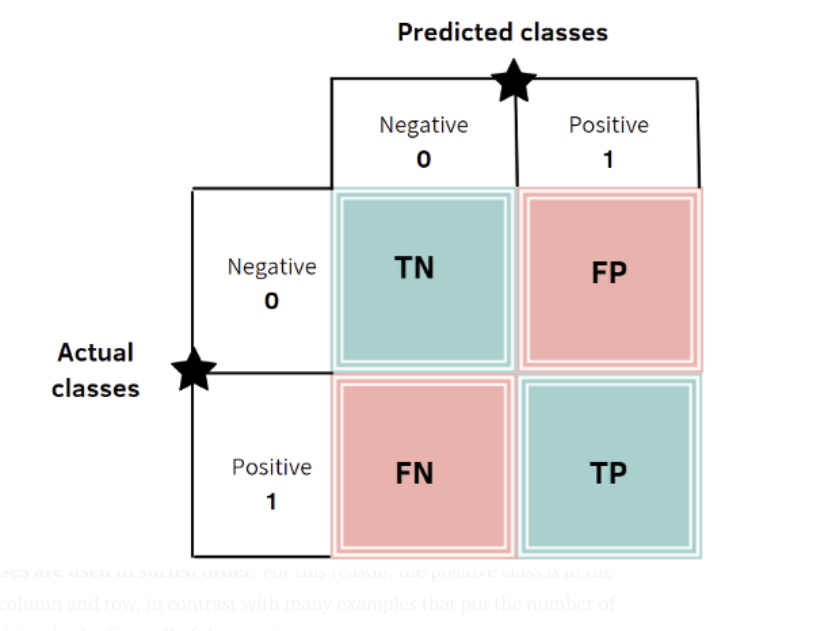
- True Positive: 실제 True인 정답을 True라고 예측 (정답)
- True Negative: 실제 False인 정답을 False라고 예측 (정답)
- False Positive: 실제 False인 정답을 True라고 예측 (오답)
- False Negative: 실제 True인 정답을 False라고 예측 (오답)
평가 지표

Accuracy
- 정확하게 분류된 개수 / 총 데이터 수. 가장 직관적이고 간단한 분류성능 평가지표
- 그러나 Data sample 비율에 영향을 많이 받는다
ex) 100개 중 1개의 outlier가 있다고 가정했을 때, 모든 데이터를 True라고 예측하면 실제로는 outlier를 잡아내지 못했음에도 99%의 정확도를 낸다
Precision
- True라고 예측한 데이터 중 실제로 타겟이 True인 경우의 비율
Recall
- 실제 True인 데이터 중 True로 예측된 경우의 비율
ex) 암 검출, 테러범 혹은 금융사기 적발과 같이 잡아내지 못했을 때 심각한 손해를 주는 경우 사용(Recall이 높아야함)
F1 Score
- Trade-off 관계가 있는 precision과 recall에 대한 종합적인 평가를 하기 위한 지표
- 데이터 분포가 균일하지 않을 때 사용되기 때문에 실제로는 accuracy보다 많이 사용된다

데이터 엔지니어로 전향중인 백엔드 개발자입니다