Data Science
1.Classification - Logistic Regression
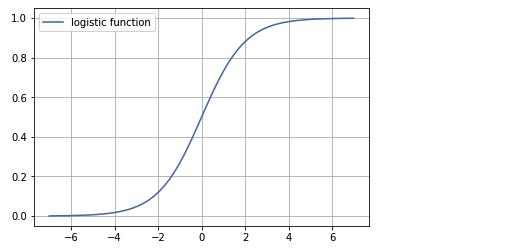
Logistic Regression is a statistical model that models the probability of one event taking place by having the log-odds (the logarithm of the odds) fo
2.Regression - Linear Regression
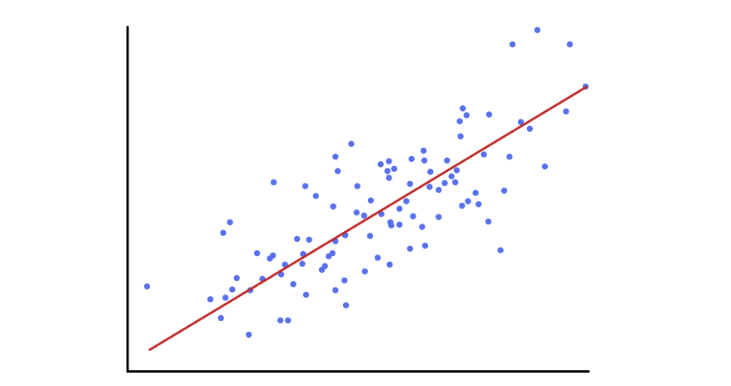
Linear regression is a linear approach for modelling the relationship between a scalar response and one or more explanatory variables (also known as
3.Classification - Decision Tree
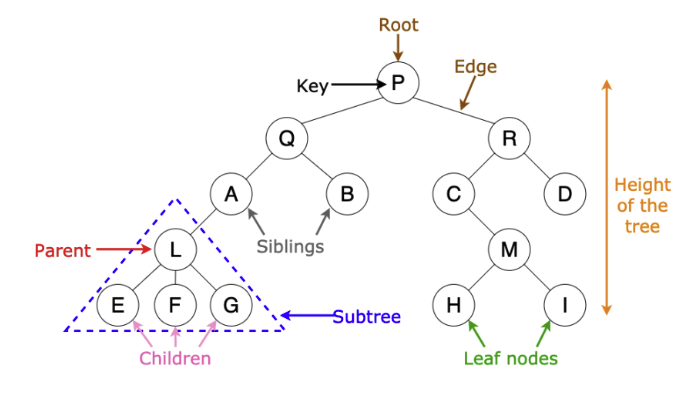
Decision tree is a decision support tool that uses a tree-like model of decisions and their possible consequences, including chance event outcomes, re
4.Classification - Random Forest
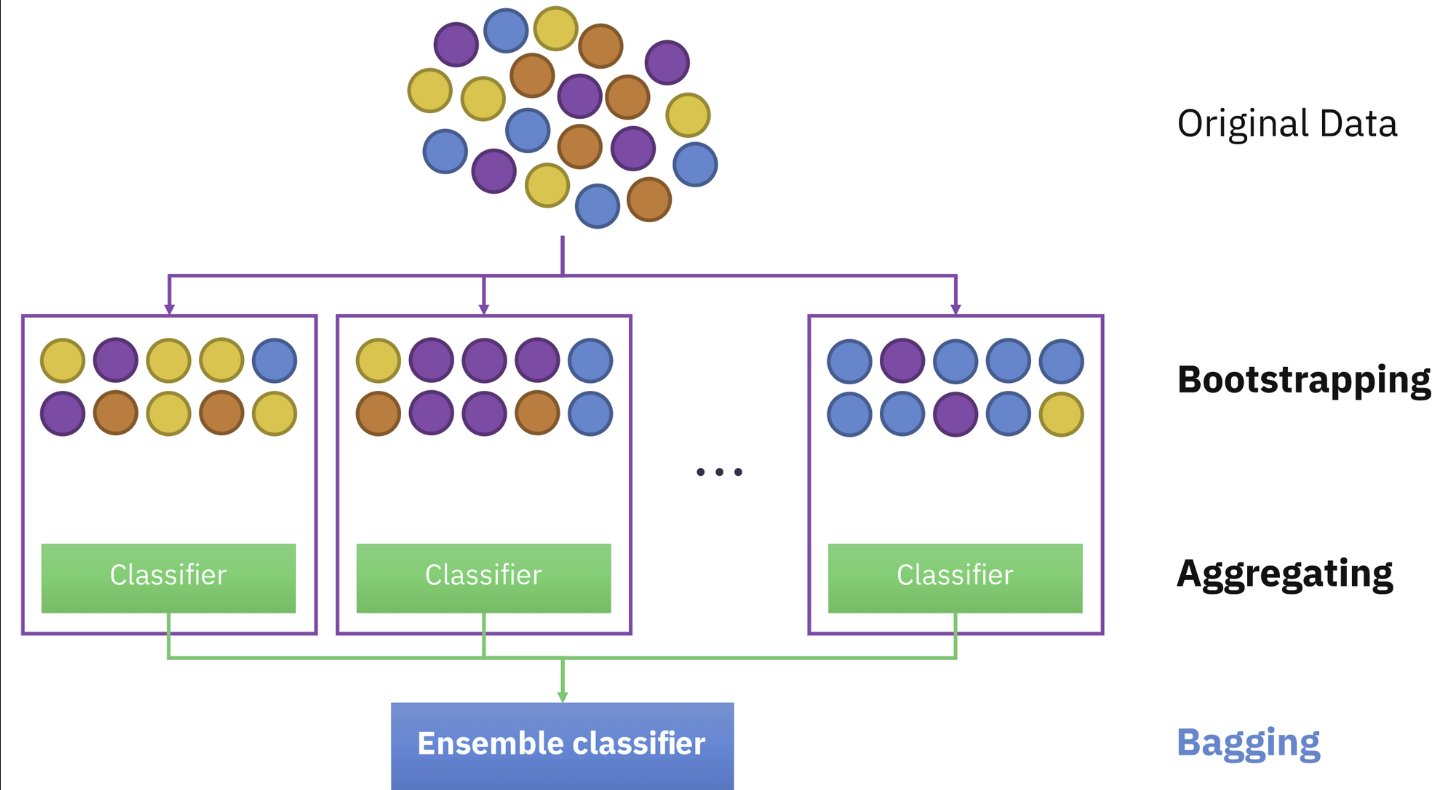
Random forests is an ensemble learning method for classification, regression and other tasks that operates by constructing a multitude of decision tre
5.Regression - XGBoost
XGBoost, which stands for Extreme Gradient Boosting, is a scalable, distributed gradient-boosted decision tree (GBDT) machine learning library. It pro
6.Regression - LightGBM
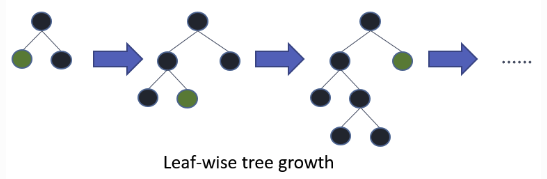
LightGBM is a gradient boosting framework that uses tree based learning algorithms.간단히, 기존 GBM들보다 훨씬 더 빠르게 학습이 되는 모델이다이미지 출처 : https://lightgbm.r
7.Clustering - K means
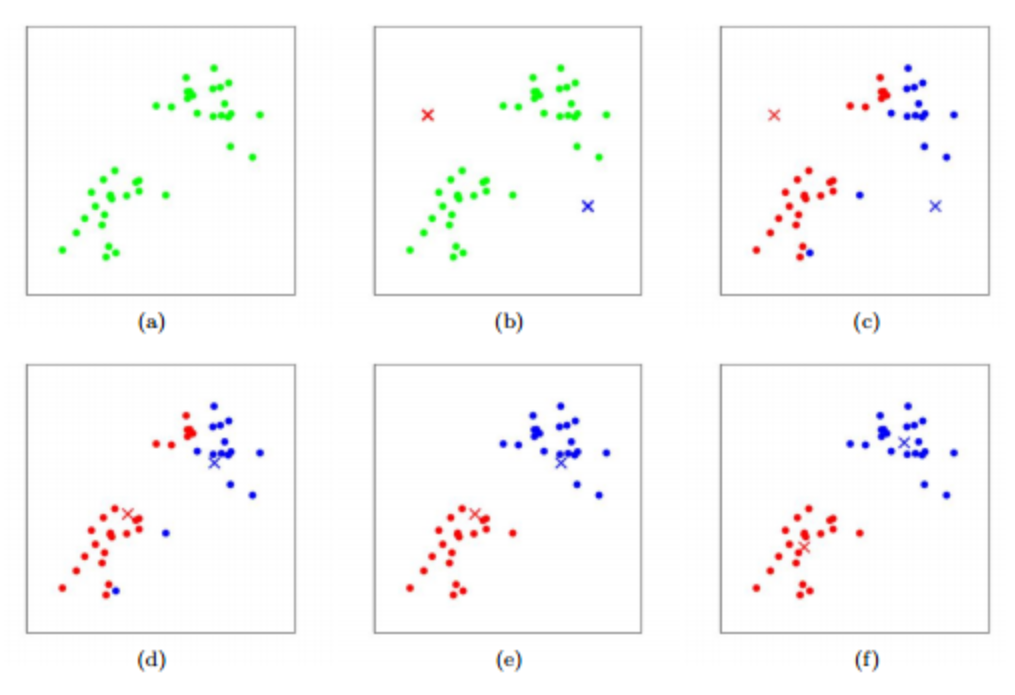
k-means clustering is a method of vector quantization, originally from signal processing, that aims to partition n observations into k clusters in whi
8.Clustering - Hierarchical Agglomerative Clustering (HCA)
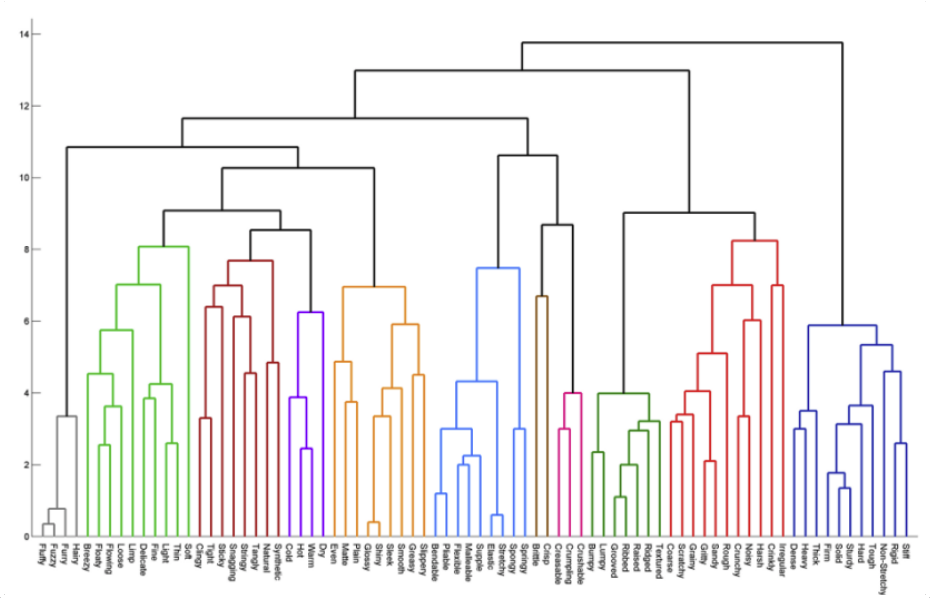
Hierarchical Agglomerative Clustering (HCA) is a method of cluster analysis which seeks to build a hierarchy of clusters. Because this is 'Agglomerati
9.Clustering - Spectral Clustering
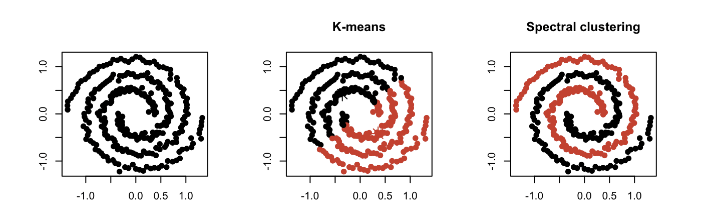
Spectral clustering techniques make use of the spectrum (eigenvalues) of the similarity matrix of the data to perform dimensionality reduction before
10.train_test_split

Credit card fraud detection 커널을 진행하다가, 해당 커널에 테스트 데이터셋이 분리되어 있지 않아 셀프로 데이터셋을 분리하며 알게된 정보를 공유하고자 한다머신러닝 모델에 Train 데이터를 전부 학습시킨 후 Test 데이터에 모델을 적용했을 때 성
11.Evaluation Metric - Classification

이상거래 탐지 관련 머신러닝을 공부하다가(Kaggle : Credit card fraud detection), 성능 지표에 대한 개념을 맞닥뜨려 본 게시물을 작성하게 되었다. 오늘 포스팅 하는 Classification Evaluation Metrics(분류 성능 지표