1. 모델의 아키텍쳐를 바꾸지 않고 어떻게 성능을 향상시킬 수 있을까?
1.1 토큰화(Tokenization)
- 주어진 말뭉치를 토큰으로 나뉘는 것을 말한다
- 어떻게 하느냐에 따라 의미가 달라질 때가 많다.
서브워드 토큰화
- 주어진 말뭉치를 서브워드로 단위로 나눈다.
- 인지적으로 알고 있는 워드 단위로 토큰화를 하게 되면 vocab이 너무나 커지기 때문에
- 이러한 문제를 해결하기 위해 제시된 것이 바로 Subword Tokenization이다.
- OOV문제를 완화
1.2 BPE
가장 빈도수가 높은 유니그램 쌍을 하나의 유니그램으로 통합해준다.
Bottom - up 방식 접근
서브워드 토크나이징을 어떻게 하느냐에 따라 성능이 많이 달라질 수 있는데, 그 방법론중 하나가 BPE
한국어에서는 형태소 기반 서브워드 토큰화가 가장 유리하다.
BPE 같은 범용적 토크나이징도 좋지만, 단순히 나누기 보다 형태소를 고려한 토크나이징이 성능에 더 좋을 수 있다. 형태소 분석 이후 BPE 같은 것을 적용하는 방법도 있다.
2. 데이터 증강이란?
-
원본 데이터를 변환하거나 새로운 데이터를 추가하여 데이터를 늘리는 방법
-
총 3가지 방법이 있는데
-
Rule-Based Techniques: 쉽게 연산 가능하도록 사전 정의된 변형 방식을 적용함.
실제 우리 과제에도 있는데
SR(유의어 대체),
RI(랜덤하게 노이즈 추가),
RS(랜덤하게 위치 교체),
RD(랜덤하게 삭제)
등의 방법론들을 konlpy를 통해 직접 적용해 볼 수 있다.- 완전 전통적인 자연어 처리 !
-
Example interpolation Techniques
MixUp을 적용하여 둘 이상의 실제 예시로부터 선형 보강법을 통해 새로운 샘플을 생성하는 방법임.
자연어 처리에서 많이 사용하지는 않는다. -
Model-Based Techniques
Seq2Seq나 언어 모델을 사용한 기법이다.
대표적으로 Back-Translation(BT) 같은 대표적인 방법론이 있다.
또한 문장을 paraphrase를 GPT와 같은 모델을 통해 진행할 수도 있다.
-
3. Data Filtering
- 데이터 클리닝이랑 다르다
데이터 필터링은 실제 데이터를 제거해버리고
데이터 클리닝의 경우에는 실제 데이터를 제거하지는 않고 불순물을 좀 걸러주는 느낌이다.
데이터 클리닝은 데이터 전처리와 비슷한 개념 ! (불용어 없애는 등)
- 병렬 말뭉치(Parallel Corpus)
두개 이상의 번역된 문서를 모은 말뭉치로, 문장 대 문장 혹은 문단 대 문단으로 구축되어 있다.
주로 두 개 이상의 언어를 지원하는 같은 웹 사이트를 크롤링하여 구축한다.- 위키피디아
- OPUS: 영어, 드라마 자막 사이트
- AI Hub
- 병렬 말뭉치 필터링(Parallel Corpus Filtering)
양질의 데이터를 고르기 위해 수행하는 것- 언어 감지 필터: 문장 쌍이 내가 원하는 언어인가? (어떤 언어인지 자동으로 분류해 주는 기술 활용)
- 수용 가능성 필터: 문장 쌍이 수용가능할 정도로 유사한가? 잘 만들어 졌는가?
- 도메인 필터: 타겟한 도메인에서 벗어난 내용인지 확인
필터링을 많이 하면 좋은가?
- 모델의 강건성을 위해서는 일정부분 노이즈가 필요하다
- 아니다 성능을 위해서는 일단 노이즈를 최대한 제거하는 것이 맞다.
4. Systhetic Data
-
합성 데이터
- 크롤링/크라우드 소싱 등으로 수집한 데이터 말고 통계적, 전산학적으로 생성한 데이터
- 생성모델 기반의 합성 데이터가 굉장히 중요해지고 있음
- GPT가 실제 데이터를 생성하고 라벨링해주고 있다.
출처: 사진 출처
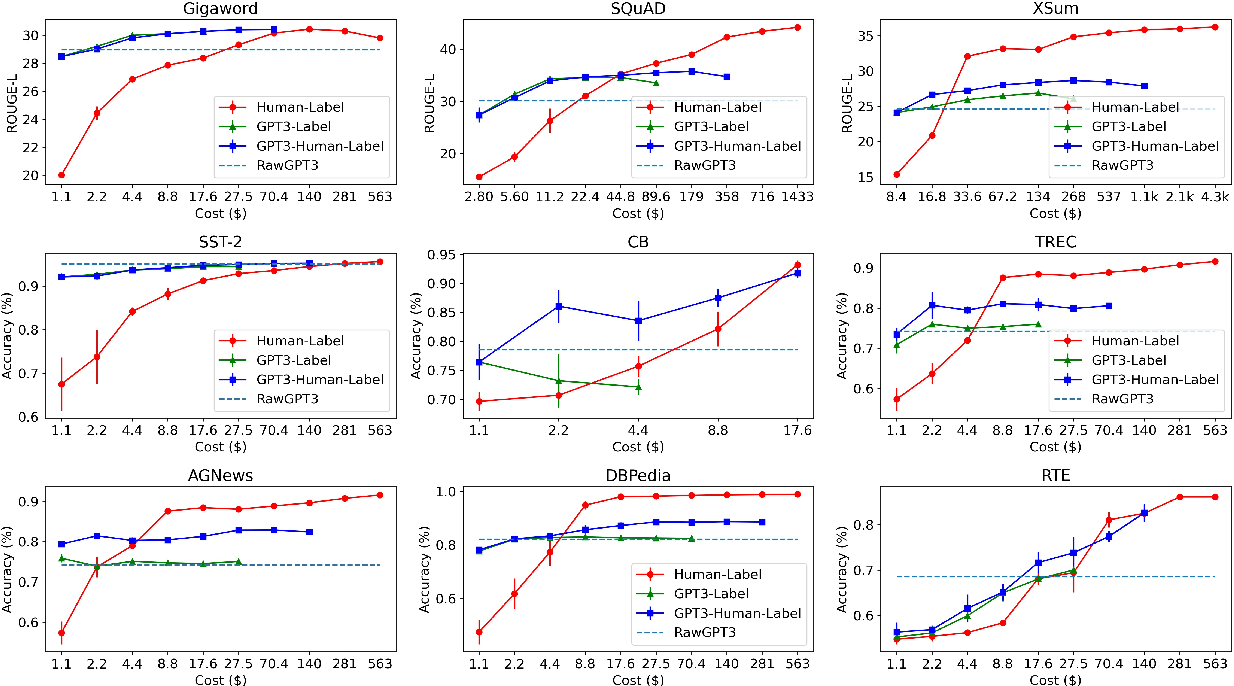
- 한국어 맞춤법 교정 연구에 필요한 데이터를 합성데이터로 실제 많이 생성중
5. Training Strategies
- 커리큘럼 학습
- 쉬운 내용부터 어려운 내용으로 단계적으로 모델을 학습하는 ML 기법
6. Data Measurement
데이터를 만들었으면 어떻게 평가해야할까?
평가에도 굉장히 신경써야 한다.
6.1 IAA
Inter-Annotator Agreement
- 2명 이상의 어노테이터가 생성한 레이블이 얼마나 일관성이 있는지에 관한 지표이다.
- 데이터의 품질 특히 일관성과 관련이 있고
- 주요 지표로는 다음과 같은 것이 있다.
- Cohen's Kappa
두 명의 평가자 사이의 동의 정도를 측정하는 지표- 우연의 일치 가능성을 고려하며
- -1에서 1사이의 값이 나오며
- 1에 가까울 수록 높은 일치도를 보여주는 것으로 판단
- Fleiss' Kappa
셋 이상의 평가자 간 동의 정도를 측정하는 지표- 여러 평가자 간 일치도 측정이 가능하며
- Cohen's Kappa의 확장버전이라고 볼 수 있다.
- Krippendorff's Alpha (많이 사용한다)
다양한 상황에서 사용 가능한 유연한 일치도 측정 지표- 여러 유형의 데이터에 적용 가능하며
- 결측치를 처리할 수 있고
- -1에서 1 사이의 값을 가진다.
- Cohen's Kappa
7. HCI: Human-Computer Interaction
- remind: 좋은 데이터란 무엇일까?
- 일관성 있고
- 중요한 케이스, 경계선을 형성하는 케이스를 포함한 데이터
- 예외 케이스가 포함된 데이터
- 적정한 사이즈를 가진 데이터
최근 AI 업계에서
데이터 품질을 과소평가하여 발생하는 하위 케이스의 복합적 이슈가 발생하는 중
그걸 뭐라하느냐? =>Data Cascade
데이터에서 잘못되면 Down Stream Task들이 다 영향을 받는다.
이 또한 Data-Centric의 관할 아래에 있음
- 좋은 데이터를 위한 체크리스트
- 전처리, 클리닝, 라벨링 단계가 있었는지?
- Raw Data를 별도로 저장했는가?
- 전처리, 클리닝, 라벨링 단계에서 사용한 SW에 대한 공개 여부
- meta data가 얼마나 informative한가?
- Versioning 체계가 잘 이루어졌는가?
- 데이터 저장 폴더가 직관적이고 깔끔한지 여부
데이터의 내재적인 특성을 고려한 필터링 말고, 모델의 출력을 모델의 성능을 끌어 올리기 위한 데이터 필터링이어야 한다... 데이터를 위한 데이터는 없다.
8. 요약
우리는 최종적으로 Model based Data-Centric AI에 이르러야 한다.
- DMOps와 같은 체계적인 Process
- 레이블 일관성을 고려하여, 작업자들의 주관이 들어가지 않도록 가이드라인을 설정해주고
- 데이터를 쉽게 생성, 제어할 수 있는 Tool을 적용하며
- Model의 결과를 방향성으로 지속적인 클렌징 과정을 거칠 수 있도록 해야한다.
