1. Long Context... 왜 필요한가?
ICL(In-context Learning)에서 매우 편리하다.
시스템 프롬프트를 길게 줄 수도 있고 이를 기반으로 더 다양한 Task와 효율성을 얻을 수 있다.
NLP 외에 CV 등의 Task 에서도 Long Context는 매우 중요
단순 텍스트 외에 영상, 사진, 음성 같은 경우에는 필연적으로 Long Context를 쓸 수 밖에 없다.
2. Lost in the Middle
LLM은 중간에 있는 정보에 대해서 매우 성능이 낮다.
Quality vs Length
- 다수의 모델이 긴 Context를 지원하고 있지만 실효성 있는 Length를 지원하고 있지는 않다.
- 모델이 지원한다 주장하는 것과 실제는 매우 다른 실정 !
3. Long-Context를 실현하기 위한 기반 기술
3.1 Positional Embedding
Transformer에서는 문장 내 토큰 위치에 대해서 정보를 제공하는데, 이때 token의 상대적 위치에 대한 정보는 놓치게 된다.
512까지 학습되었던 적은 있겠지만, 513번째 토큰에 대한 case는 학습한 적이 없다면 해당 정보에 대한 학습력이 매우 떨어지게 됨
또한 Absolute position embedding은 토큰 간 거리(상대적 위치정보)를 잘 보존하지 못한다는 단점이 있다.
3.2 Relative Position Embedding
그래서 등장한것이 상대위치 임베딩...
토큰 간의 거리에 대한 가깝고 먼 정보를 제공한다.
다만, 계산이 쉽지 않고 절대적 위치가 없다는 단점이 있다.
3.3 Rotary Position Embedding (RoPE)
Token Embedding을 위치 index 만큼 회전시키고 Embedding 간 내적(각도)로 상대적 위치를 보존한다.
sin, cos을 통해서 회전 변환 해주는 것인데, 360을 10만, 20만, 100만으로 쪼갠다고 하면 그래도 360 도 안에서 노는 것이라 모델이 아예 이해 못하는 것은 아님
4. 모든 모델이 RoPE 방식으로 작동중인가?
ALiBi
출처: https://arxiv.org/pdf/2108.12409
-
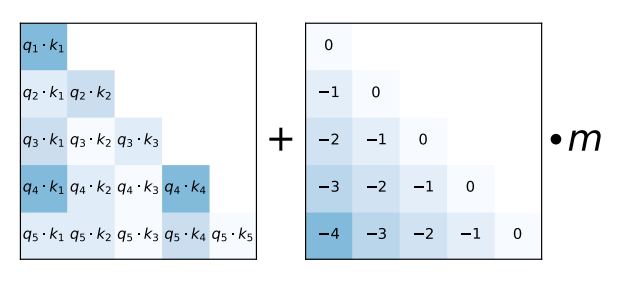
Attention with Linaer Biases
길이가 늘어나도 0N 만큼의 연산만 증가되도록 하는 방법. -
태생적으로 2048으로 학습되었어도 4096을 적용해도 괜찮겠음 구조가 되어있음
-
MPT, BLOOM, Replit 등의 모델들에 있어서 Context window를 늘리는 데 기여함
핵심은 input 토큰의 수가 늘어날수록 성능이 떨어지는 문제를 해결하기 위하여 key와 query 간의 거리에 비례하여 attention score를 penalize 한다는 것
- 다만, 현재 대세인 모델은은 RoPE 사용중
5. 핵심: 위치정보의 기억
결국은 위치정보를 어떻게 제공해줄 것인지가 긴 Context에 대한 이해에 중요했는데, 이때 메모리 사용량은 한없이 늘어날 것이다. 그래서 등장한 것이 바로 Ring Attention
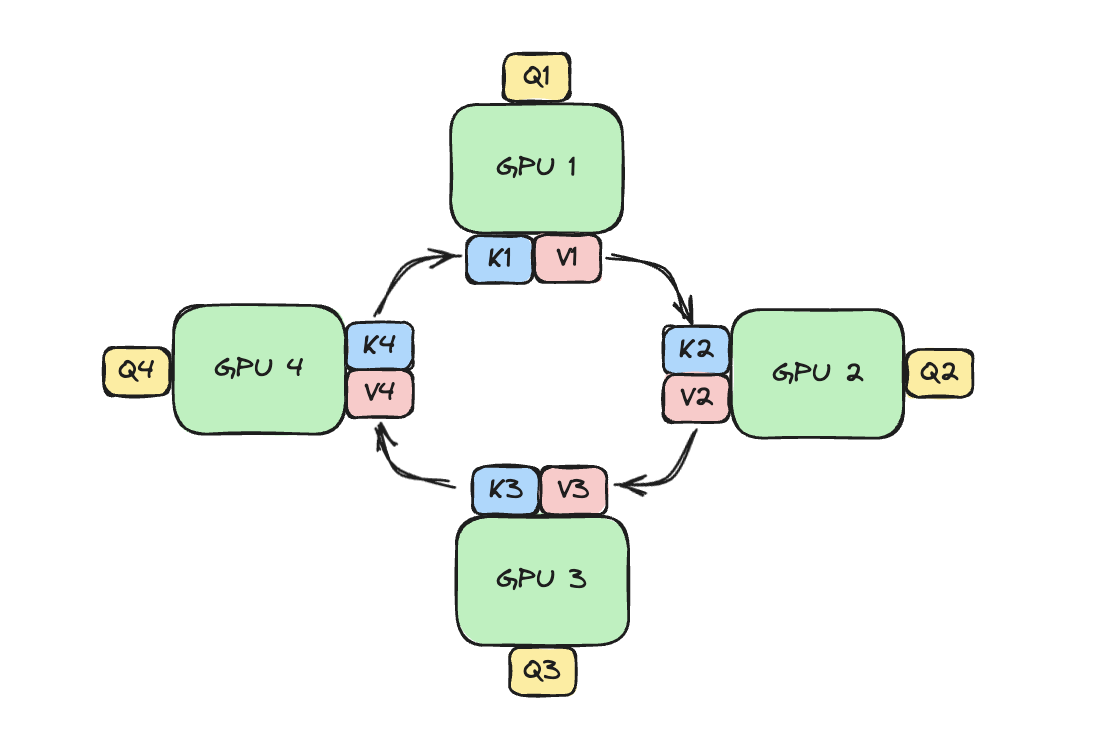
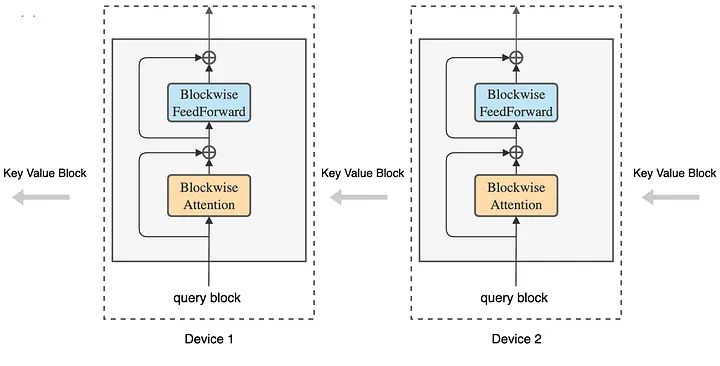
Ring Attention
Transformer를 Block 단위로 쪼개고, Key-Value를 Block에서 Block으로 넘긴다.
출처: https://coconut-mode.com/posts/ring-attention/
- 각 Device가 Query Block을 보유하고, Key-value block이 Device를 돌아다니면서 Attention 계산
출처: https://medium.com/@iamtanujsharma/breaking-the-boundaries-understanding-context-window-limitations-and-the-idea-of-ring-attention-170e522d44b2
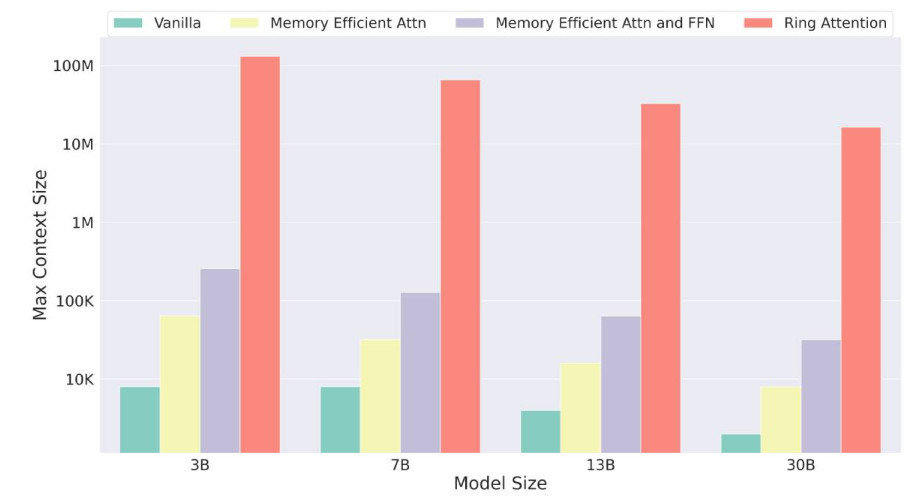
Memory Efficiency
- Ring Attention을 사용하게 되면, device 개수 만큼 더 긴 Context를 학습 및 추론 가능하게 된다.
출처: https://blog.infinix.co/tw/2023/10/28/ai_model_ring_attention
