0. 들어가기에 앞서...
여기서 df는 dataframe으로 행과 열로 이루어진 판다스 dataframe 객체를 의미한다.
유용한 팁들
- dir() : 객체의 모든 속성, 메서드 이름을 나열
my_list = [1, 2, 3]
print(dir(my_list))
- help() : 객체의 설명서(docstring) 출력
my_list = [1, 2, 3]
help(my_list)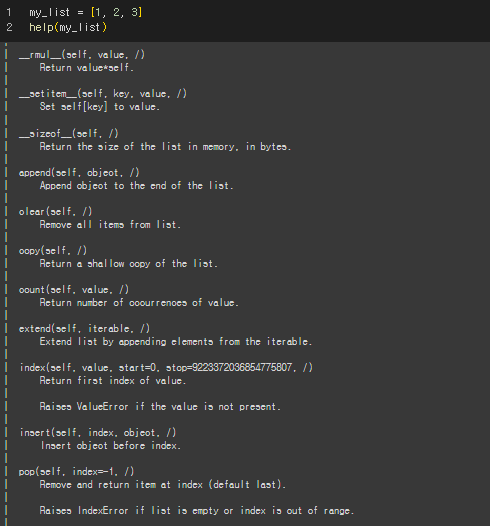
1. read_csv("", index_col=0)
index_col을 통하여 CSV 파일을 읽을 때 데이터 프레임의 인덱스를 특정 칼럼으로 지정할 수 있다.
예를 들면
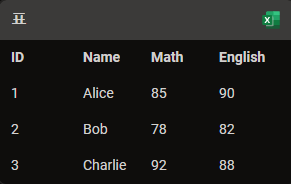
이랬던 것이 index_col=0 을하면
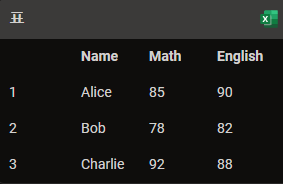
이렇게 되는 느낌
이렇게 된 순간부터는 이제 각 행에 대하여 ID 값을 통하여 고유하게 식별할 수 있게 된다.
예컨데, df.loc[1] 이렇게 하면 Alice의 데이터를 가져올 수 있게 되는 것.
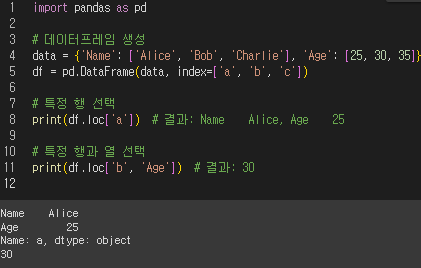
df.loc ??
df.loc는 Pandas 데이터프레임에서 특정 행과 열에 접근하거나 데이터를 선택할 때 쓰는 indexing 방법이다.
df.loc[행_라벨] : 특정 행을 선택한다.
df.loc[행라벨, 열라벨] : 특정 행과 열을 선택한다.
이외에도 특정 조건을 넣을 수 있다
**df.loc[df[1열]<=100]
위와 같은 형식인데
결과적으로는 df[df[1열 <= 100]]과 같다.
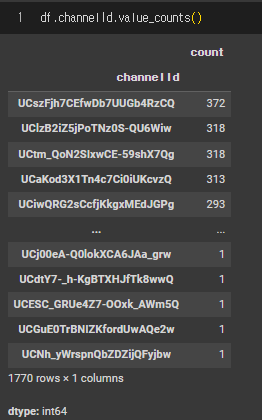
2. df.칼럼이름.value_counts()
해당 칼럼에서의 value 값들을 세준다.
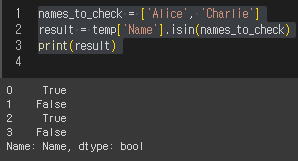
3. df.칼럼이름.isin()
특정 값들이 해당 열에 존재하는 지 여부를 확인해 준다.
이 메서드는 boolean 시리즈를 반환하여 각 행이 조건에 만족하는지 여부를 확인해준다.
4. df.drop_duplicates()
말 그대로 중복 행을 제거해준다.
변화 키워드와 같이 많이 쓰임. 중복 제거해줘야 제대로 셀 수 있음.
**df.drop_duplicates('칼럼 이름', keep = 'last')
위와 같이 중복을 제거하고 맨 마지막을 남길 수도 있음
5. df.groupby(칼럼 이름)
말 그대로 해당 칼럼에 관하여 그룹화 시켜준다.
groupby는 다음 세가지 원칙을 따르는데
1. Split : 데이터를 지정된 기준에 따라 나누고
2. Apply : 각 그룹에 원하는 함수를 적용한 후
3. Combine : 결과를 다시 하나로 합친다.
다만

위와 같이 한다고 하여서 바로 뭐 프린트 되고 분석된 데이터프레임이 나오는 것은 아니고
대부분 사진과 같이 객체로 일단 저장되며.
통상 (집계)함수를 뒤에 붙여야 비로소 실제 결과를 볼 수 있다.
df.groupby('column_name')['value_column'].mean()
df.groupby('column_name')['value_column'].sum()
df.groupby('column_name')['value_column'].count()# value_counts()는 열을 지정해주지 않으면 전체 칼럼 기준으로 빈도 계산하게 됨. df.groupby(df.trending_date2.dt.day_name()).categoryId.value_counts() # 반면 size()는 각 그룹의 빈도가 나옴 df.groupby([df.trending_date2.dt.day_name(), 'categoryId'], as_index = False).size()
6. pd.to_datetime()
df.trending_date2 = pd.to_datetime(df.trending_date2)
특정 열의 데이터 형식을 pandas datetime 형식으로 바꿔준다.
그리고 여기서
pandas datetime 형식으로 바뀐 열에 대하여
df.trending_date2.dt.day_name()
이라고 하면
해당 날짜에서 요일 이름을 추출할 수 있다.
7. pivot()
.pivot()은 데이터를 재구조화하고 요약하는 데 사용되는 도구이다. 특히 데이터프레임을 행과 열의 조합으로 특정 값을 요약할 때 유용하다.
pivoted_df = df.pivot(index='index_column', columns='columns_column', values='values_column')-
index:
새로운 데이터프레임의 행을 구성할 컬럼. -
columns:
새로운 데이터프레임의 열을 구성할 컬럼. -
values:
재구조화된 데이터프레임의 셀 값을 채울 컬럼.
import pandas as pd
data = {
'date': ['2024-10-18', '2024-10-18', '2024-10-19', '2024-10-19'],
'category': ['A', 'B', 'A', 'B'],
'value': [10, 20, 15, 25]
}
df = pd.DataFrame(data)
pivoted_df = df.pivot(index='date', columns='category', values='value')
print(pivoted_df)
출력은 이하와 같음.
category A B
date
2024-10-18 10.0 20.0
2024-10-19 15.0 25.0
8. sort_values
Pandas 데이터프레임에서 특정 칼럼의 값에 따라 정렬하는 데 사용되는 메서드이다.
기본 사용 예시
df_sorted = df.sort_values(by=['column_name1', 'column_name2'])
ascending은 오름차순이 기본값이다. False로 두면 내림차순 !
df_sorted = df.sort_values(by='column_name', ascending=False)
na_position의 경우 결측값의 위치를 지정해준다. 기본값은 'last'로, 결측값은 마지막에 온다.
df_sorted = df.sort_values(by='column_name', na_position='first')
9. iloc
.iloc는 판다스에서 정수 기반 인덱싱을 통해 데이터프레임의 슽겆 위치에 있는 데이터를 선택하는 것에 사용된다.
df.iloc[0]
df.iloc[0,1]
df.iloc[:,0:2]
10. last()
groupby메서드와 자주 쓰이는 것으로, 각 그룹에서 마지막 행을 선택한다.
이게 마지막으로 들어오면 전체 칼럼에 대해 행을 보여준다.
video = video.sort_values('ct')
answer = video.groupby('videoname')[['ct', 'viewcnt']].last()
print(answer)11. reset_index()
기본적으로 reset_index()는 기존 인덱스를 데이터프레임의 새로운 열로 추가한다.
- 기본 사용 :
df_reset = df.reset_index()-
인덱스 드롭:
기존 인덱스를 보존하지 않고 제거할 때 사용.
df_reset = df.reset_index(drop=True)-
다중 인덱스 처리:
다중 인덱스 레벨 중 특정 레벨만 리셋할 때
df_multi = df.set_index(['A', 'B'])
df_reset = df_multi.reset_index(level='A')