네부캠 파이팅
1. 문제의 제기
프로젝트를 진행하며 훈련까지 정상적으로 마치고(loss 잘 떨어짐) 실제 저장된 prediction.csv를 보니까 아래와 같이 비정상적이게 저장된 모습을 발견
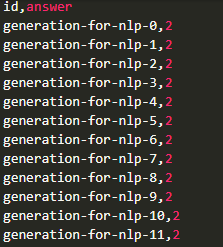
이와 관련하여 어떤 코드가 문제가 되고 어떻게 해결해 나갈지 아래에서 서술한다.
2. 주요 코드
2.1 기존 Loigt 코드
outputs = model(
tokenizer.apply_chat_template(
messages,
tokenize=True,
add_generation_prompt=True,
return_tensors="pt",
).to(DEVICE)
)
logits = outputs.logits[:, -1].flatten().cpu()
# 여기서 보이는 logits 과연 무엇인가?- 여기서 보이는 logits 는 outputs.logits를 슬라이싱 [:, -1] 한 값이고
- 이는 입력된 문장 전체를 처리한 후, 마지막 위치에서 예측한 다음 토큰이 올 자리의 전체 vocab 대상의 확률 분포를 의미한다.
- 실제 해당 값을 뽑으면 수많은 텐서값이 나오는데 그 사이즈가 vocab 사이즈와 일치한다.
-
지금 프로젝트에서는 Causal 하게 이어질 전체 입력 바로 직후의 토큰 확률 분포 중 1,2,3,4,5 에 해당하는 로짓들 중 가장 argmax 한 것을 가져오는 식으로 prediction.csv에 들어갈 토큰을 고르고 있다.
-
그런데 이때 위 Logit 말고도 유심히 봐야할 것이 바로
tokenizer.chat_template과DataCollatorForCompletionOnlyLM에 인자로 들어가는 아래response_template이다.
2.2 chat_template
기존 baseline chat_template은 아래와 같다.
{% if messages[0]['role'] == 'system' %}
{% set system_message = messages[0]['content'] %}
{% endif %}
{% if system_message is defined %}
{{ system_message }}
{% endif %}
{% for message in messages %}
{% set content = message['content'] %}
{% if message['role'] == 'user' %}
{{ '<start_of_turn>user\n' + content + '<end_of_turn>\n<start_of_turn>model\n' }}
{% elif message['role'] == 'assistant' %}
{{ content + '<end_of_turn>\n' }}
{% endif %}
{% endfor %}위 양식은 jinja2 템플릿 으로 이와 관련하여 짧게 설명하자면
모델에 넣는 input을 chat_template에 맞춰 바꿔주는 역할을 한다.
중요한 부분은 바로 이 부분
{{ '<start_of_turn>user\n' + content + '<end_of_turn>\n<start_of_turn>model\n' }}
바로 위 부분에서
왜 <start_of_turn>model\n 이것까지 포함되었는지가 중요하다.
아니 깔끔하게 떨어지는 거면
아래와 같은 방식이 맞지 않을까?
{{ '<start_of_turn>user\n' + content + '<end_of_turn> }}
일반적인 경우에는 맞을 수 있다.
보통 모델이 생성할 때 <|start_of_turn|>과 같은 SOT토큰 내지는 BOS토큰 먼저 내뱉고 시작하는 경우는 많이들 봤을 테니,,,
그런데 우리 프로젝트에서는
앞선 Logit 에서 봤듯이
모델에게 입력을 준후 바로 처음 생성되는 토큰의 확률분포에서 1,2,3,4,5에 스코프를 주고서
해당 값중 가장 높은 값을 argmax를 통해
추출해 내는바,
모델이 입력되는 input을 대상으로 가장 처음 생성할 토큰은 <|start_of_turn|>이 아니다.
우리가 생성해야할 토큰은 그 자체로 정답이 바로 될 수 있는 1 2 3 4 5 중에 하나인 것이다.
따라서 현재 모델은 학습하기로
<start_of_turn>model\n 이후에 답에 해당하는 content를 내뱉게끔 학습되었으므로
본 프로젝트를 진행하면서 Logit기반으로 답변을 생성하는 경우에 쓰는 템플릿은
아래와 같은 형식 (user, assistant 간의 깔끔한 구분)이면 안되고
{%- if messages[0]['role'] == 'system' -%}
{%- set system_message = messages[0]['content'] -%}
{%- endif -%}
{%- if system_message is defined -%}
{{ '<|im_start|>system\n' + system_message + '<|im_end|>\n' }}
{%- endif -%}
{%- for message in messages -%}
{%- set content = message['content'] -%}
{%- if message['role'] == 'user' -%}
{{ '<|im_start|>user\n' + content + '<|im_end|>\n' }}
{%- elif message['role'] == 'assistant' -%}
{{ '<|im_start|>assistant\n' + content + '<|im_end|>\n' }}
{%- endif -%}
{%- endfor -%}baseline 코드처럼 아래와 같은 형식이어야 한다.
{% if messages[0]['role'] == 'system' %}
{% set system_message = messages[0]['content'] %}
{% endif %}
{% if system_message is defined %}
{{ '<|im_start|>system\n' + system_message + '<|im_end|>\n' }}
{% endif %}
{% for message in messages %}
{% set content = message['content'] %}
{% if message['role'] == 'user' %}
{{ '<|im_start|>user\n' + content + '<|im_end|>\n<|im_start|>assistant\n' }}
{% elif message['role'] == 'assistant' %}
{{ content + '<|im_end|>\n' }}
{% endif %}
{% endfor %}(스페셜 토큰만 바꿨을 뿐 기존 baseline과 비슷하다.)
이대로 해야만 Logit 기반 모델에서, baseline 코드상에서 에러가 발생하지 않는다.
모델이 첫번째로 내뱉는 토큰이 곧 바로 content에 해당하는 내용이어야 하기 때문!
그렇다면 response_template은 뭔가요?
라고할 수 있는데 그 또한 chat_template과 엮어서 중요한 개념이다. 아래에서 설명한다.
2.3 response_template
DataCollatorForCompletionOnlyLM
위 클래스에 인자로 들어가는 것으로 위 클래스에 인자로 response_template를 넣어주게 되면
모델 학습 과정에서
모델에 input으로 들어오는 학습 대상인 문장 중
response_template을 포함한 이전 token들의 label을 -100으로 설정해 줘서
모델이 입력으로 들어온 모든 부분을 학습할 필요 없이
이게 없다면 모델은 그냥 주어진 문장 처음부터 순서대로 쭉 예측을 진행함;;그게 causalLM의 학습방식이기 때문
주어진 입력에 대한 대답 (response_template 이후 토큰들) 만을 학습하게끔 해준다.
따라서 입력되는 원문(input)에 reponse_template에 해당하는 값이 없다면 전부 -100 처리가 되기에 loss 계산에서 제외가 되는 것.
따라서 반드시
Chat_template과 맞춰서 해당 템플릿에서 사용한 Specail Token을 기준으로 설정해주는 것이 중요하다.
ex) <|im_start|>assistant\n
ex) <|strat_of_turn|>model\n
Chat_template에서 쓴 것과 response_template을 맞춰주지 않으면 학습이 진행 되지 않음을 다시 한번 유의!
참고사항
위 정리글에서는 chat_template에 관하여 가시성있도록 줄바꿈과 tab을 섞어 보여줬으나
실제 chat_template을 custom할 때에는
아래와 같이 하게 되면 실제 model 입력에 줄바꿈, tab, 공백 같은 문자들이\n, \t, \s등으로 들어가게 된다.
이점에 주의하자즉,
{% if messages[0]['role'] == 'system' %} {% set system_message = messages[0]['content'] %} {% endif %} {% if system_message is defined %} {{ '<|im_start|>system\n' + system_message + '<|im_end|>\n' }} {% endif %} {% for message in messages %} {% set content = message['content'] %} {% if message['role'] == 'user' %} {{ '<|im_start|>user\n' + content + '<|im_end|>\n<|im_start|>assistant\n' }} {% elif message['role'] == 'assistant' %} {{ content + '<|im_end|>\n' }} {% endif %} {% endfor %}이렇게 하면 안 되고
아래처럼 줄글로 작성해야 한다.
이렇게 안하면 각종 오류메시지에 직면하게 되고 실제로 학습에 영향을 주는 것으로 보인다.{% if messages[0]['role'] == 'system' %}{% set system_message = messages[0]['content'] %}{% endif %}{% if system_message is defined %}{{ '<|im_start|>system\n' + system_message + '<|im_end|>\n' }}{% endif %}{% for message in messages %}{% set content = message['content'] %}{% if message['role'] == 'user' %}{{ '<|im_start|>user\n' + content + '<|im_end|>\n<|im_start|>assistant\n' }}{% elif message['role'] == 'assistant' %}{{ content + '<|im_end|>\n' }}{% endif %}{% endfor %}
3. 문제의 해결
요약하자면 base_line 코드에서 사용하고자하는 모델에 맞춰
chat_template을 수정할 때에 baseline 코드에서 신경써야할 부분은 총 3가지라고 할수 있다.
3.1 chat_template
"{% if messages[0]['role'] == 'system' %}{% set system_message = messages[0]['content'] %}{% endif %}{% if system_message is defined %}{{ '<|im_start|>system\n' + system_message + '<|im_end|>\n' }}{% endif %}{% for message in messages %}{% set content = message['content'] %}{% if message['role'] == 'user' %}{{ '<|im_start|>user\n' + content + '<|im_end|>\n<|im_start|>assistant\n' }}{% elif message['role'] == 'assistant' %}{{ content + '<|im_end|>\n' }}{% endif %}{% endfor %}",
위와 같은 chat_template 설정에 있어서
모델이 생성하는 첫 토큰이 바로 content에 해당할 수 있도록
{% if message['role'] == 'user' %}{{ '<|im_start|>user\n' + content + '<|im_end|>\n<|im_start|>assistant\n' }}{% elif message['role'] == 'assistant' %}{{ content + '<|im_end|>\n' }
위 부분을 반드시 유념할 것.
3.2 response_template
chat_template을 고쳐줬다면 이에 맞춰서 학습한 부분을 제대로 지정해주기 위하여
스페셜토큰을 제대로 반영하여 아래처럼 수정해 줄 것!
response_template = "<|im_start|>assistant\n"3.3 compute_metircs
def compute_metrics(evaluation_result):
logits, labels = evaluation_result
print('logits:', logits)
print('labels:', labels)
labels = np.where(labels != -100, labels, tokenizer.pad_token_id)
labels = tokenizer.batch_decode(labels, skip_special_tokens=True)
labels = list(map(lambda x: x.split("<|im_end|>")[0].strip(), labels))
labels = list(map(lambda x: int(x) - 1, labels))위 부분은 accuracy 계산에 사용되는 학습 외의 부분이라 앞서 설명하지 않았지만
base_line 상에서 스페셜 토큰에 따라 변경되는 값이기에 에러메시지를 보고 싶지 않다면
위 코드 중
<|im_end|> 이 값을
변경하고자 하는 모델의 special token 중에서 알맞은 값으로 바꿔준다.
기존 베이스라인에서의 값은
<end_of_turn>였다.
4. Reference
원빈님 Linkdein
재복님 블로그
감사합니다... 감사합니다...
부캠러들에게 조금이라도 도움이 되길 원하며...
