1. 강의 목표
-
다양한 상황에서 AI 모델을 최적화하고 경량화 하는 방법을 탐색
-
AI 경량화 기술과 접근 방식의 이해
-
파라미터 효율을 중시한 AI 모델 학습
-
최적화 기술을 통한 성능 향상 방법 숙지
-
여러 GPU로 학습하는 방법
2. Why? 최적화, 경량화
-
실시간 처리
-
저자원 환경
-
에너지 효율성
AI 모델의 거대화로 계산 자원량이 기하급수적으로 늘었는데, 이런 환경에서 거대한 모델을 그대로 운영하기에는 다양한 현실적인 문제들이 생김.
따라서 경량화와 최적화 없이는 사실상 AI서비스는 불가함.
3. AI Model Lightweighting
- 모델경량화
AI 모델의 크기를 줄이고, 계산비용을 감소시키되 모델의 성능은 최대한 유지하는 것- Pruning
가지치기 - Knowledge Distillation
지식 증류 - Quantization
양자화
- Pruning
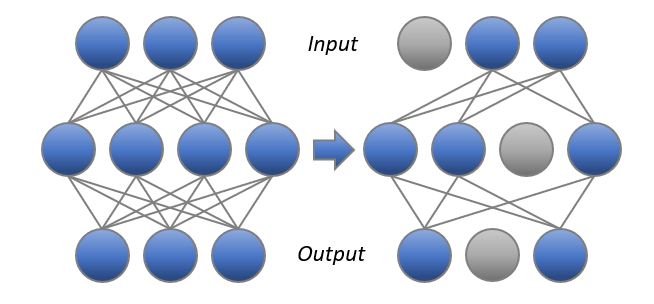
3.1 Pruning: 가지치기
-
학습된 모델에서 중요도가 낮은 뉴런이나 연결을 제거하여 모델의 크기와 계산 비용을 줄이는 기법
-
Structured Pruning
뉴런, 채널, 혹은 레이어 전체를 제거하는 방식
-
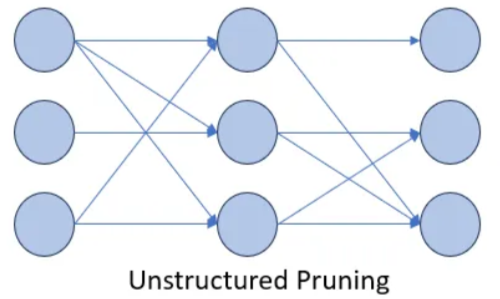
Unstructured Pruning
연결된 가중치를 개별적으로 검증하여 독립적으로 제거하는 방식
-
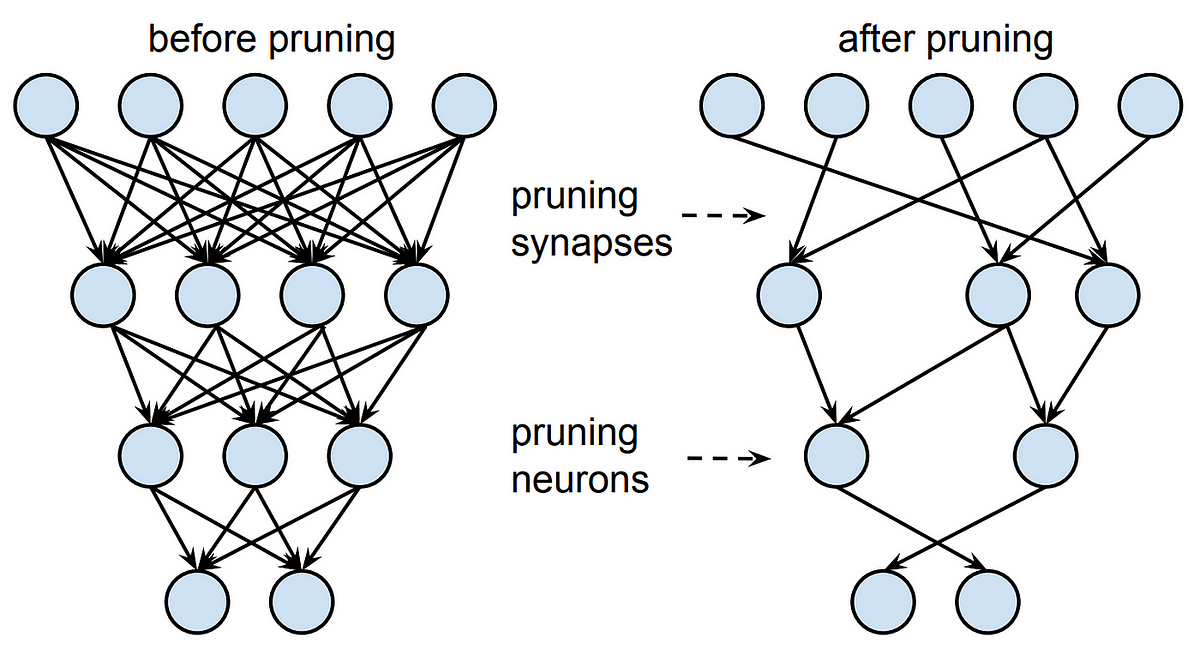
출처: https://blogs.novita.ai/understanding-the-difference-structured-vs-unstructured-neural-pruning/
3.2 Knowledge Distillation (지식증류)
-
고성능의 Teacher 모델로부터 지식을 전달받아 Student 모델을 학습시키는 기법
-
경량화의 한종류로써 성능 저하를 최소화하며 모델을 압축하는 하나의 방법임.
- 선생 모델은 좀 크고 웅장한 반면, 학생모델의 경우 작고 가벼운 모델을 사용함
-
세부 기법
- White-box KD:
Llama와 같이 공개된 모델을 교사모델로 사용하여 학습하는 경우- Logit-based KD, Feature-based KD
- Black-box KD:
ChatGPT와 같이 비공개 모델을 교사모델로 활용하여 학습하느 ㄴ경우- Imitation Learning
3.3 Quantization: 양자화
- White-box KD:
-
모델의 가중치와 활성화률 낮은 비트 정밀도로 변환하여 저장 및 계산 효율성을 높이는 기법.
예를들면 32비트 부동소수점을 8비트 정수로 변환4. AI Model Lightweight Re-training
-
모델 크기와 Fine-tuning
- 생성형AI 모델의 발전에 따라 모델 크기가 점진적으로 커지고 있음
- Fine-tuning은 모델의 모든 파라미터를 업데이트 하는 방법
- 비용 문제
큰 모델일수록 학습 비용(training time, memory) 증가
- 비용 문제
-
PEFT: Parameter-Efficient Fine-Tuning
-
PEFT 기법은 훈련된 모델을 자원 효율적인 방식으로 재학습하는 방법론
-
최대한 작은 파라미터를 학습하면서 Full-fine tuinig하는 것과 비슷한 성능을 내는 것이 목표
-
세부 기법
- Adapter
- Low-Rank Adaptation (LoRA)
-
4.1 Adapter
- 기존 네트워크의 가중치는 고정한 채로 레이어 사이에 새로운 Layer를 추가하여 해당 부분만 학습
- 파인튜닝과 비교했을 때 3.6% 가량의 파라미터만 추가학습하여 학습했을 때 비슷한 성능에 도달
4.2 LoRA: Low-Rank Adaptation
- 어댑터와 비슷한 방식이지만 병렬적으로 처리하는 방식을 활용
4. 병렬 컴퓨팅: AI Model Memory Optimization
-
대규모 언어모델들은 애초에 요즘 단일 GPU로는 절대 학습 못하게 나온다...!
-
DIstributed Training
- 모델을 여러 개의 GPU로 분산시켜 GPU에 한 번에 들어가지 않는 큰 모델도 학습 가능하도록 함
- GPU- 3 모델 학습 예시
모델: 700기가 ㅋㅋ
GPU: A100 40GB짜리 18개...
- GPU- 3 모델 학습 예시
- 모델을 여러 개의 GPU로 분산시켜 GPU에 한 번에 들어가지 않는 큰 모델도 학습 가능하도록 함
-
병렬컴퓨팅? 병렬적으로 처리할 대상을 뭘로 설정하느냐
- 데이터 병렬화
큰 데이터를 여러 GPU들에 분할하여 동시에 처리함으로써 학습 속도를 높임
모델 학습 속도 증가 - 모델 병렬화
큰 모델을 여러 GPU들에 분할함으로써 하나의 GPU로는 처리할 수 없는 대형 모델도 처리가 가능하다. - 메모리 효율성 증가
- 데이터 병렬화
