
Ⅰ. AWS RDS
1. Database 생성 후 접근 가능한 사용자 계정 만들기
# aws 연결
import mysql.connector
conn = mysql.connector.connect(
host = "localhost",
user = "oneday",
password = "1234",
database = "oneday"
)
cursor = conn.cursor(buffered=True)create database oneday default character set utf8m4;
create user 'oneday'@'%' identified by '1234';
grant all on oneday.* to 'oneday'@'%';
show grants for 'oneday'@'%';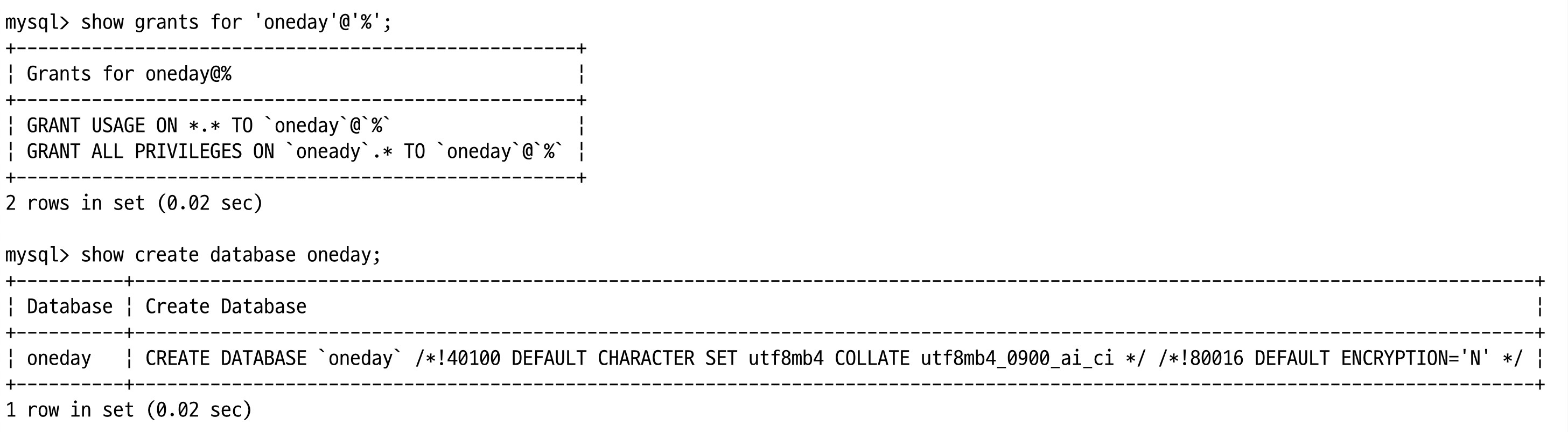
2. 스타벅스 이디야 데이터를 저장할 테이블 생성
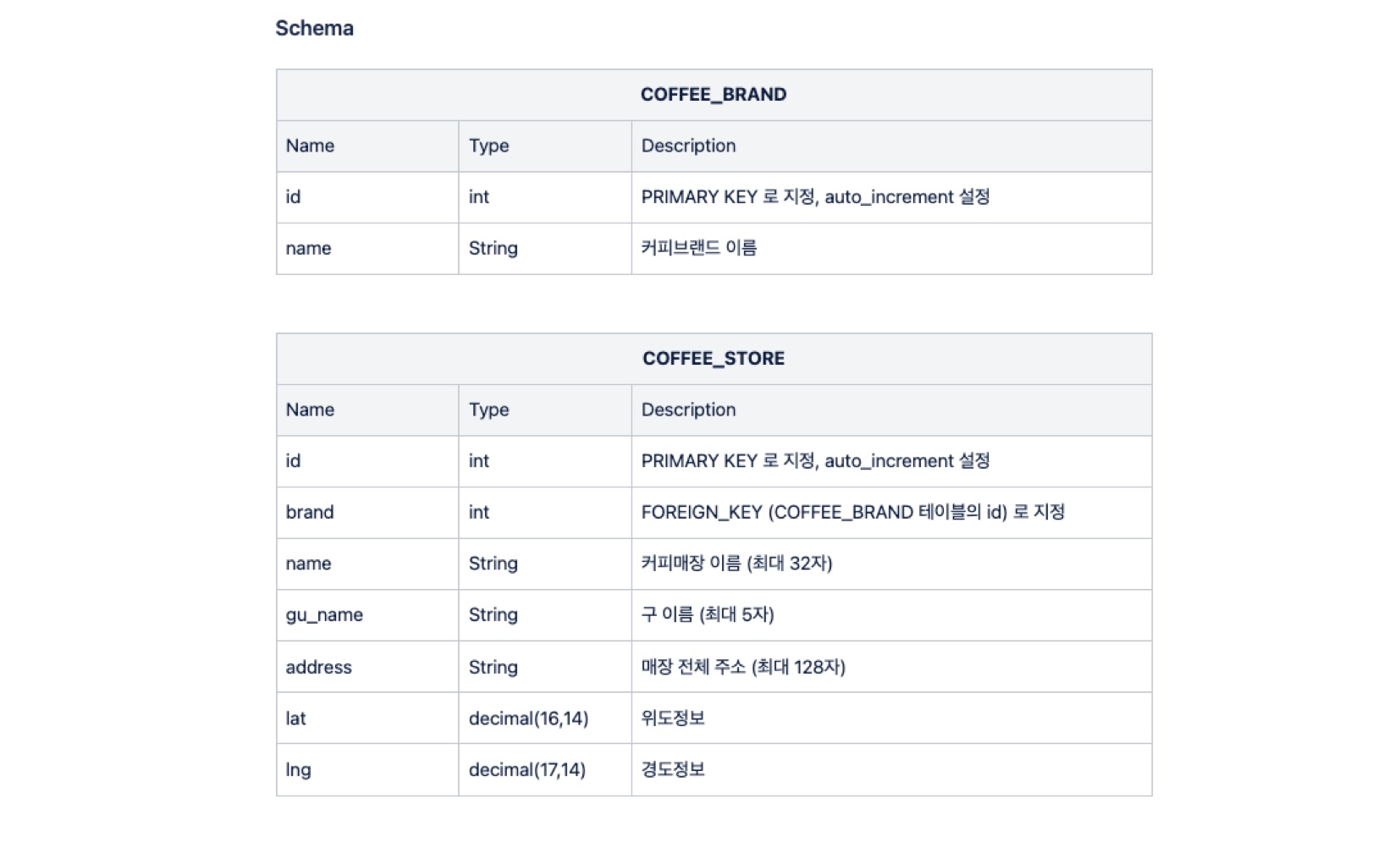
use oneday;
create table COFFEE_BRAND
(
id int NOT NULL AUTO_INCREMENT PRIMARY KEY,
name varchar(10)
);
create table COFFEE_STORE
(
id int NOT NULL AUTO_INCREMENT PRIMARY KEY,
brand int NOT NULL,
name varchar(32) NOT NULL,
gu_name varchar(5) NOT NULL,
address varchar(128) NOT NULL,
lat decimal(16,14) NOT NULL,
lng decimal(17,14) NOT NULL,
FOREIGN KEY (brand) REFERENCES COFFEE_BRAND(id)
);
3. Python 코드로 COFFEE_BRAND 데이터 입력
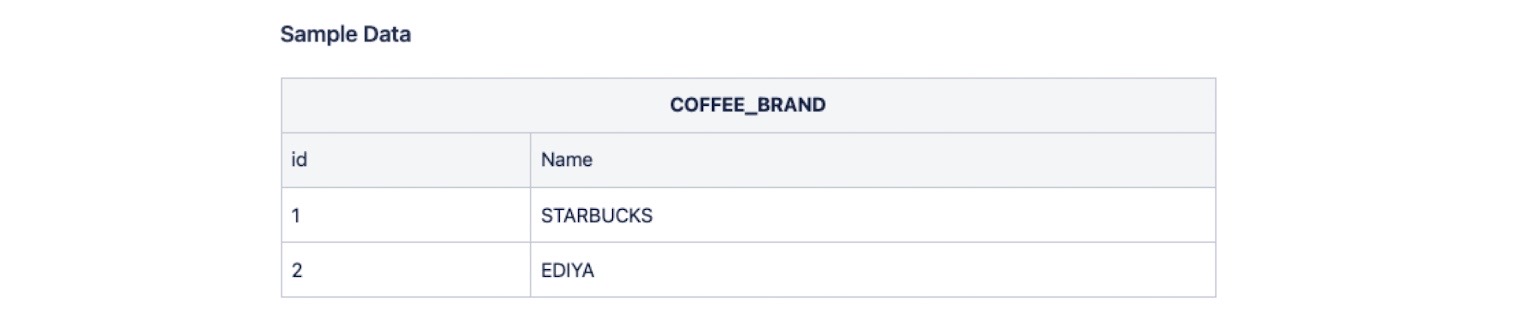
cursor.execute("insert into COFFEE_BRAND (name) values ('STARBUCKS'), ('EDIYA')")
cursor.execute("select * from COFFEE_BRAND")
result = cursor.fetchall()
for row in result:
print(row)
Ⅱ. 데이터 수집
1. 스타벅스 데이터 수집
import pandas as pd
import warnings
from selenium import webdriver
from selenium.webdriver.common.by import By
from bs4 import BeautifulSoup
from tqdm import tqdm_notebook
warnings.simplefilter('ignore')
# 1. 스타벅스 페이지 접근
url = 'https://www.starbucks.co.kr/store/store_map.do?disp=locale'
driver = webdriver.Chrome('driver/chromedriver')
driver.get(url)
# 팝업창 닫기 (예외처리)
from selenium.common.exceptions import NoSuchElementException
try:
driver.find_element(By.CSS_SELECTOR, '.holiday_notice_close a').click()
except NoSuchElementException as e:
print(e)
# 2. 서울 선택
driver.find_element(By.CSS_SELECTOR, '.set_sido_cd_btn').click()
# 3. 서울 전체 선택
driver.find_element(By.CSS_SELECTOR, '.set_gugun_cd_btn').click()
# BeautifulSoup
html = driver.page_source
dom = BeautifulSoup(html, 'html.parser')2. 가져온 스타벅스 데이터를 AWS RDS(sql) COFFEE_STORE에 바로 입력
# 6. 전체 데이터 수집
sql = "insert into COFFEE_STORE (brand, name, gu_name, address, lat, lng) values (1, %s, %s, %s, %s, %s)"
for content in tqdm_notebook(seoul_list):
title = content['data-name']
address = content.select_one('p').text[:-9]
lat = content['data-lat']
lng = content['data-long']
gu_name = address.split()[1]
cursor.execute(sql, (title, gu_name, address, lat, lng))
conn.commit()
driver.quit()# 7. 파일 읽기
cursor.execute("select count(*) from COFFEE_STORE")
result = cursor.fetchall()
result
- 입력된 데이터 총 개수 확인
cursor.execute("select * from COFFEE_STORE limit 5")
result = cursor.fetchall()
for row in result:
print(row)
- 입력된 데이터 상위 5개 쿼리 결과 확인
3. 이디야커피 데이터 가져오기
import mysql.connector
import time
import pandas as pd
import warnings
from selenium import webdriver
from selenium.webdriver.common.by import By
from bs4 import BeautifulSoup
from tqdm import tqdm_notebook
warnings.simplefilter('ignore')
url = 'https://www.ediya.com/contents/find_store.html#c'
driver = webdriver.Chrome('driver/chromedriver')
driver.get(url)
driver.find_element(By.CSS_SELECTOR, '#contentWrap > div.contents > div > div.store_search_pop > ul > li:nth-child(2) > a').click()
search_keyword = driver.find_element(By.CSS_SELECTOR, '#keyword')
search_button = driver.find_element(By.CSS_SELECTOR, '#keyword_div button')
time.sleep(1)
sql = "INSERT INTO COFFEE_STORE (brand, name, gu_name, address, lat, lng) VALUES (2, %s, %s, %s, %s, %s)"
for gu in gu_list:
try:
search_keyword.clear()
search_keyword.send_keys(gu)
search_button.click()
time.sleep(1)
html = driver.page_source
dom = BeautifulSoup(html, 'html.parser')
contents = dom.select('#placesList li')
for content in contents:
title = content.select_one('dt').text
address = content.select_one('dd').text
gu_name = address.split(' ')[1]
tmp = gmaps.geocode(address, language="ko")
tmp[0].get("formatted_address")
lat = tmp[0].get("geometry")["location"]["lat"]
lng = tmp[0].get("geometry")["location"]["lng"]
cursor.execute(sql, (title, gu_name, address, lat, lng))
conn.commit()
except Exception as e:
# 검색이 되지 않는 매장이 있어 예외처리 진행
print(e)
continue
driver.quit()
cursor.execute("SELECT COUNT(*) FROM COFFEE_STORE WHERE brand=2")
result = cursor.fetchone()
result[0]
- 입력된 데이터 총 개수 쿼리하여 결과 확인
cursor.execute("SELECT s.* FROM COFFEE_BRAND b, COFFEE_STORE s WHERE b.id = s.brand AND b.name LIKE 'EDIYA' LIMIT 10")
result = cursor.fetchall()
for row in result:
print(row)
- 입력된 데이터 상위 10개 쿼리하여 결과 확인
Ⅲ. 가져온 데이터를 쿼리로 조회
1. 스타벅스 매장 주요 분포 지역
- 매장수가 많은 상위 5개 구 이름, 매장 개수 출력
sql = "select s.gu_name, count(s.brand) from COFFEE_BRAND b, COFFEE_STORE s
where b.id = s.brand AND b.name='STARBUCKS'
GROUP BY s.gu_name
order by count(s.brand) desc
limit 9"
cursor.execute(sql)
result = cursor.fetchall()
for row in result:
print(row)
# 검색 결과
('강남구', 88)
('중구', 55)
('서초구', 48)
('마포구', 41)
('영등포구', 41)
('종로구', 40)
('송파구', 34)
('용산구', 25)
('강서구', 25)2. 이디야 매장 주요 분포 지역
- 매장수가 많은 상위 5개 구 이름, 매장 개수 출력
sql = "select s.gu_name, count(s.brand) from COFFEE_BRAND b, COFFEE_STORE s
where b.id = s.brand AND b.name='EDIYA'
GROUP BY s.gu_name
order by count(s.brand) desc
limit 9"
cursor.execute(sql)
result = cursor.fetchall()
for row in result:
print(row)
# 검색 결과
('강서구', 45)
('강남구', 44)
('영등포구', 41)
('송파구', 39)
('마포구', 37)
('종로구', 31)
('성북구', 31)
('중구', 30)
('노원구', 30)3. 구별 브랜드 각각의 매장 개수 조회
- 구 이름, 브랜드 이름, 매장 개수 출력
sql = "select s.gu_name, s.count STARBUCKS, e.count EDIYA
from (select gu_name, count(brand) count from COFFEE_STORE WHERE brand = 1 GROUP BY gu_name) s,
(select gu_name, count(brand) count from COFFEE_STORE WHERE brand = 2 GROUP BY gu_name) e
where s.gu_name = e.gu_name"
cursor.execute(sql)
result = cursor.fetchall()
for row in result:
print(row)
# 검색 결과 (구, 스타벅스, 이디야)
('은평구', 12, 26)
('서대문구', 23, 21)
('마포구', 41, 37)
('강남구', 88, 44)
('강북구', 6, 20)
('강서구', 25, 45)
('관악구', 12, 28)
('광진구', 19, 24)
('금천구', 13, 23)
('노원구', 14, 30)
('도봉구', 4, 24)
('동작구', 11, 23)
('서초구', 48, 29)
('성북구', 15, 31)
('송파구', 34, 39)
('양천구', 17, 27)
('영등포구', 41, 41)
('종로구', 40, 31)
('중구', 55, 30)
('강동구', 17, 27)
('구로구', 13, 29)
('동대문구', 9, 25)
('성동구', 14, 22)
('용산구', 25, 14)
('중랑구', 8, 28) Ⅳ. CSV파일로 저장
import pandas as pd
sql = "select *
from (select s.id s_id, b.name s_brand, s.name s_name, s.gu_name s_gu, s.address s_address, s.lat s_lat, s.lng s_lng
from COFFEE_STORE s, COFFEE_BRAND b
where b.id = s.brand and b.name like 'STARBUCKS') st,
(select s.id e_id, b.name e_brand, s.name e_name, s.gu_name e_gu, s.address e_address, s.lat e_lat, s.lng e_lng
from COFFEE_STORE s, COFFEE_BRAND b
where b.id = s.brand and b.name like 'EDIYA') ed
order by st.s_id, ed.e_id"
cursor.execute(sql)
result = cursor.fetchall()
num_fields = len(cursor.description)
field_names = [i[0] for i in cursor.description]
df = pd.DataFrame(result)
df.columns = field_names
df.to_csv('coffee_output.csv', index = False, encoding = "utf-8")
conn.close()
3D 모델러의 개발 도전기