
Ⅰ. Download Target Data
Data 출처
- Source: 서울시 열린데이터
# Load DataFrame
import pandas as pd
df_target = pd.read_csv('./datas/report.txt', sep='\t')
df_target.head()
Ⅱ. 문제
1. DataFrame 불러오기 & 전처리
- 문제 1-1) 0, 1, 2번 index의 row를 제거하고 index를 초기화 하세요(기존 index는 삭제(drop)하세요).
df_target=df_target.drop(index=[0, 1, 2])
df_target=df_target.reset_index(drop=True)
df_target.head()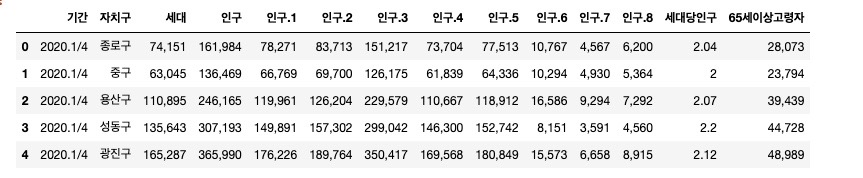
- 문제 1-2) 현재의 컬럼명(current_columns)을 아래 new_columns와 같이 변경하세요.
current_columns = ['기간', '자치구', '세대', '인구', '인구.1', '인구.2', '인구.3', '인구.4', '인구.5', '인구.6', '인구.7', '인구.8', '세대당인구', '65세이상고령자']
new_columns = ['기간', '자치구', '세대', '합계', '남자', '여자', '한국인 계', '한국인 남자', '한국인 여자', '등록외국인 계', '등록외국인 남자', '등록외국인 여자', '세대당인구', '65세이상고령자']
df_target = df_target.rename({'인구':'합계', '인구.1':'남자', '인구.2':'여자', '인구.3':'한국인 계', '인구.4':'한국인 남자', '인구.5':'한국인 여자', '인구.6':'등록외국인 계', '인구.7':'등록외국인 남자', '인구.8':'등록외국인 여자'}, axis=1)
df_target.head()
- 문제 1-3) 천단위 구분자 " , "를 제거하고, data의 type을 int 또는 float으로 변경하세요.
- 기간, 자치구: 변경 없음
- '세대', '합계', '남자', '여자', '한국인 계', '한국인 남자', '한국인 여자', '등록외국인 계', '등록외국인 남자', '등록외국인 여자', '65세이상고령자': 천단위 구분자 "," 제거 및 int로 타입 변경
- 세대당인구': float으로 타입 변경
df_target['세대'] = df_target['세대'].str.replace(',', '')
df_target['세대'] = df_target['세대'].astype('int64')
df_target['합계'] = df_target['합계'].str.replace(',', '')
df_target['합계'] = df_target['합계'].astype('int64')
df_target['남자'] = df_target['남자'].str.replace(',', '')
df_target['남자'] = df_target['남자'].astype('int64')
df_target['여자'] = df_target['여자'].str.replace(',', '')
df_target['여자'] = df_target['여자'].astype('int64')
df_target['한국인 계'] = df_target['한국인 계'].str.replace(',', '')
df_target['한국인 계'] = df_target['한국인 계'].astype('int64')
df_target['한국인 남자'] = df_target['한국인 남자'].str.replace(',', '')
df_target['한국인 남자'] = df_target['한국인 남자'].astype('int64')
df_target['한국인 여자'] = df_target['한국인 여자'].str.replace(',', '')
df_target['한국인 여자'] = df_target['한국인 여자'].astype('int64')
df_target['등록외국인 계'] = df_target['등록외국인 계'].str.replace(',', '')
df_target['등록외국인 계'] = df_target['등록외국인 계'].astype('int64')
df_target['등록외국인 남자'] = df_target['등록외국인 남자'].str.replace(',', '')
df_target['등록외국인 남자'] = df_target['등록외국인 남자'].astype('int64')
df_target['등록외국인 여자'] = df_target['등록외국인 여자'].str.replace(',', '')
df_target['등록외국인 여자'] = df_target['등록외국인 여자'].astype('int64')
df_target['65세이상고령자'] = df_target['65세이상고령자'].str.replace(',', '')
df_target['65세이상고령자'] = df_target['65세이상고령자'].astype('int64')
df_target['세대당인구'] = df_target['세대당인구'].astype('float64')
2. 원하는 정보 얻기
- 문제 2-1) 권역 Column 추가
df_target.insert(loc=2, column='권역', value=('도심권', '도심권', '도심권', '동북권', '동북권', '동북권', '동북권', '동북권', '동북권', '동북권', '동북권', '서북권', '서북권', '서북권', '서남권', '서남권', '서남권', '서남권', '서남권', '서남권', '서남권', '동남권', '동남권', '동남권', '동남권'))
- 문제 2-2) 2-1에서 만든 DataFrame을 이용하여 Pandas의 pivot_table 메소드를 활용하여 각 권역별 아래 값의 합을 구하고, '합계'를 기준으로 내림차순 정렬하세요.
pop = pd.pivot_table(
df_target,
index='권역',
values=['합계', '세대', '여자', '한국인 계', '등록외국인 계', '65세이상고령자'],
aggfunc='sum'
)
pop = pop.sort_values('합계', ascending=False)
pop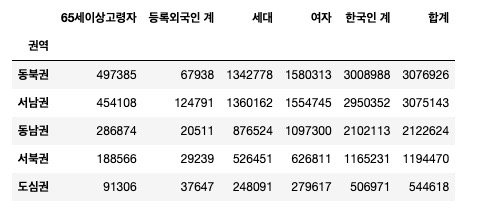
- 문제 2-3) 2-2에서 만든 Pivot Table을 이용하여 각 권역별 ['고령자비율', '외국인비율', '여성비율', '세대당인구'] 컬럼을 만들어 아래와 같이 값을 입력하고 '외국인비율'을 기준으로 오름차순 정렬하세요.
- 고령자비율: 65세이상고령자 / 합계 * 100
- 외국인비율: 등록외국인 계 / 합계 * 100
- 여성비율: 여자 / 합계 * 100
- 세대당인구: (합계 - 등록외국인 계) / 세대
pop['고령자비율'] = (
pop['65세이상고령자'] / pop['합계'] * 100
)
pop['외국인비율'] = (
pop['등록외국인 계'] / pop['합계'] * 100
)
pop['여성비율'] = (
pop['여자'] / pop['합계'] * 100
)
pop['세대당인구'] = (
(pop['합계'] - pop['등록외국인 계']) / pop['세대']
)
pop = pop.sort_values('외국인비율', ascending=True)
pop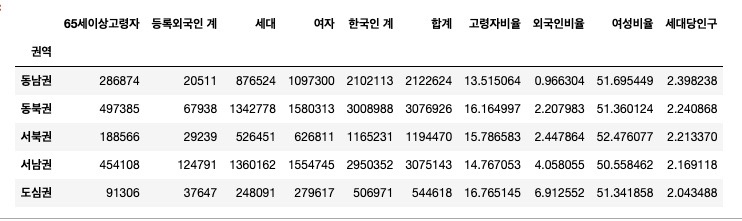
- 문제 2-4) 2-1에서 만든 DataFrame을 이용하여 각 구별 ['고령자비율', '외국인비율', '여성비율'] 컬럼을 만들어 아래와 같이 값을 입력하고 '세대당인구'을 기준으로 내림차순 정렬하세요.
- 고령자비율: 65세이상고령자 / 합계 * 100
- 외국인비율: 등록외국인 계 / 합계 * 100
- 여성비율: 여자 / 합계 * 100
df_target['고령자비율'] = (
df_target['65세이상고령자'] / df_target['합계'] * 100
)
df_target['외국인비율'] = (
df_target['등록외국인 계'] / df_target['합계'] * 100
)
df_target['여성비율'] = (
df_target['여자'] / df_target['합계'] * 100
)
df_target['세대당인구'] = (
(df_target['합계'] - df_target['등록외국인 계']) / df_target['세대']
)
df_target = df_target.sort_values('세대당인구', ascending=False)
df_target.head()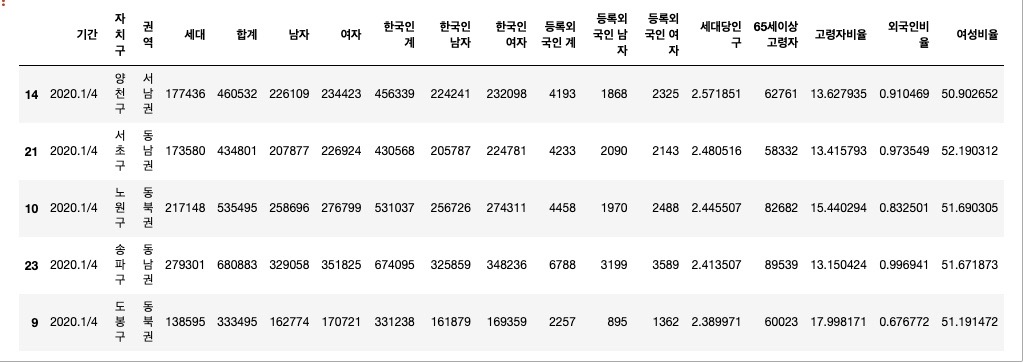
- 문제 2-5) 2-3에서 만든 DataFrame을 이용하여 ['고령자비율', '외국인비율', '여성비율', '세대당인구']간의 피어슨 상관계수 행렬(Correlation matrix)를 구하세요.
pop_correlation = pop[['고령자비율', '외국인비율', '여성비율', '세대당인구']]
pop_correlation = pop_correlation.corr()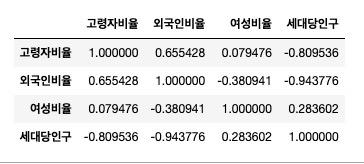
- 시각화
- Pandas DataFrame의 Plot기능, Matplotlib.pyplot, Seaborn 등 시각화 Library를 이용하여 문제와 같이 시각화하세요.
import platform
import matplotlib.pyplot as plt
from matplotlib import font_manager, rc
path = "c:/Windows/Fonts/malgun.ttf"
if platform.system() == "Darwin":
print("Hangul OK in your MAC")
rc("font", family = "Arial Unicode MS")
elif platform.system() == "Windows":
font_name = font_manager.FontProperties(fname=path).get_name()
print("Hangul OK in your Windows")
rc("font", family=font_name)
else:
print("Unknown system... sorry~")
plt.rcParams["axes.unicode_minus"] = False- 문제 3-1) 자치구별 고령자비율을 내림차순에 따라 barh 그래프로 시각화 하세요.
pop['고령자비율'].sort_values(ascending=True).plot(kind='barh', figsize=(5, 5))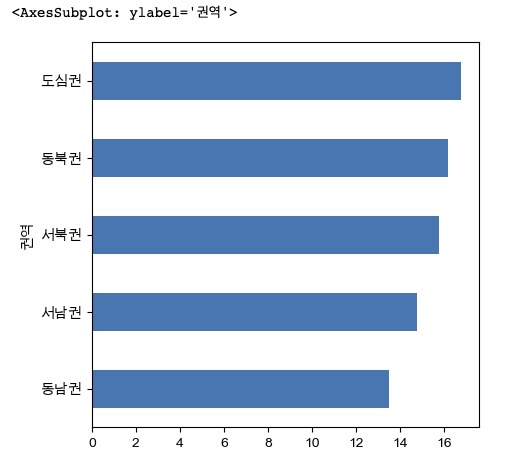
- 문제 3-2) 권역별 등록외국인 계를 PIE chart로 시각화 하세요.
import matplotlib.pyplot as plt
value = pop['등록외국인 계']
name = pop['등록외국인 계']
plt.pie(pop['등록외국인 계'], labels=pop.index)
plt.legend(pop['등록외국인 계'])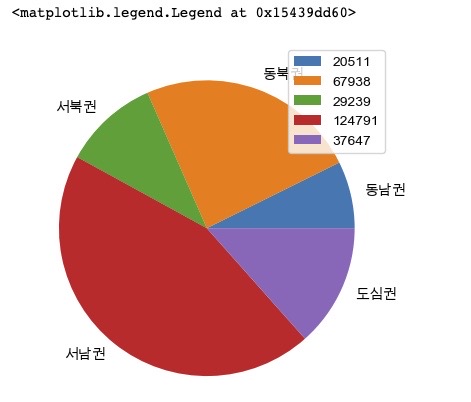
- 문제 3-3) 권역별 외국인비율을 Box plot으로 시각화 하세요.
df_target.boxplot(column=("외국인비율"), by="권역", figsize=(12, 8))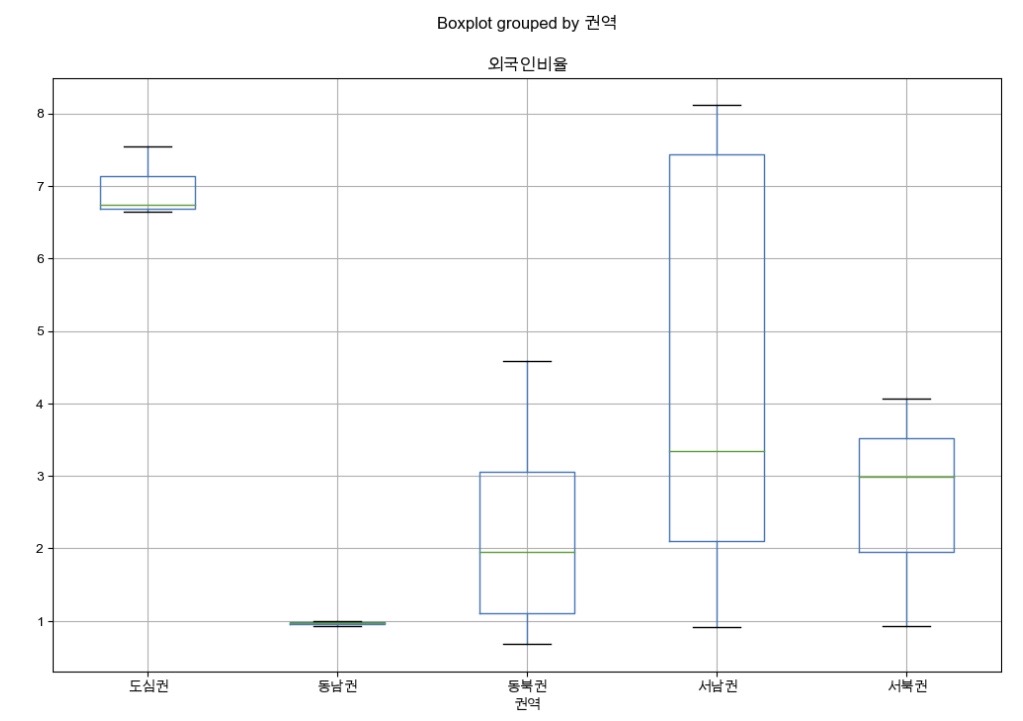
- 문제 3-4) 자치구별 외국인비율-세대당인구를 Scatter plot에 나타내고, 상관관계에 따른 Regression Line을 시각화 하세요. (10점)
import seaborn as sns
sns.regplot(x=pop['외국인비율'], y=pop['세대당인구'], data=pop)
plt.show()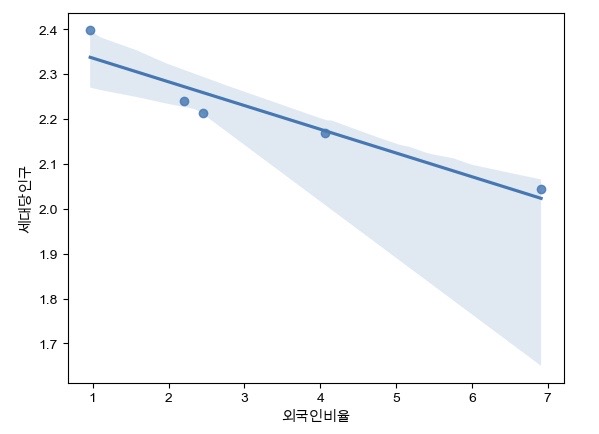

3D 모델러의 개발 도전기
안녕하세요 혹시 EDA테스트2 화장품 성분분석한 코드도 있으신가요?