
Ⅰ. 머신러닝
1. 머신러닝이란

Ⅱ. Iris Classification
목표 : petal과 sepal의 length, width로 품종을 구분할 수 있을까?
1. 데이터 관찰
- 데이터 관찰(python)
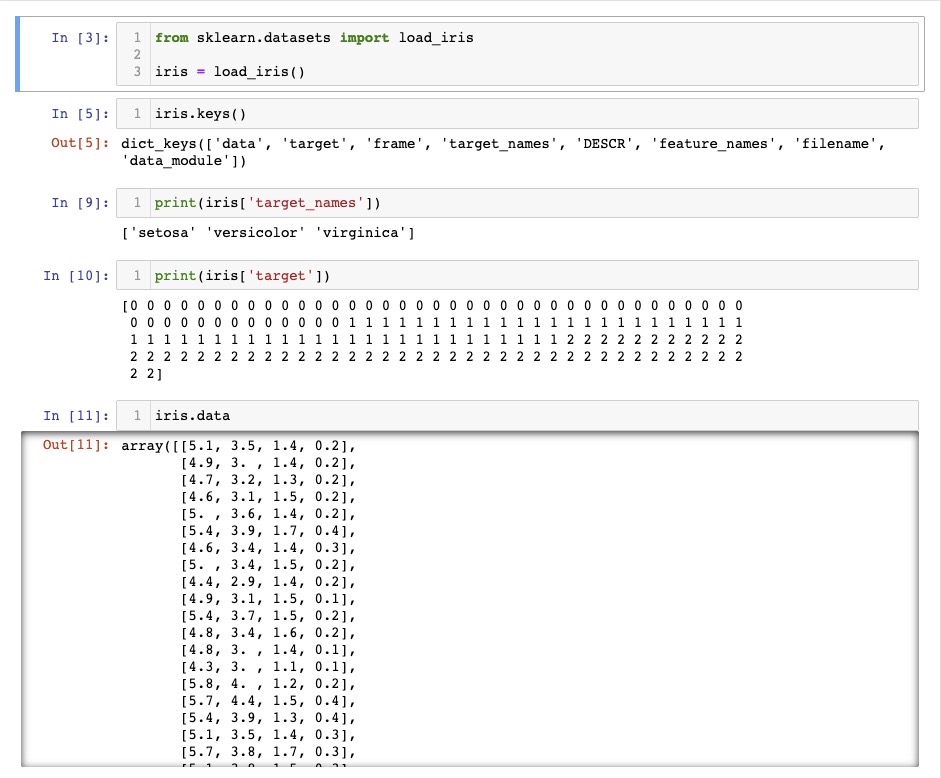
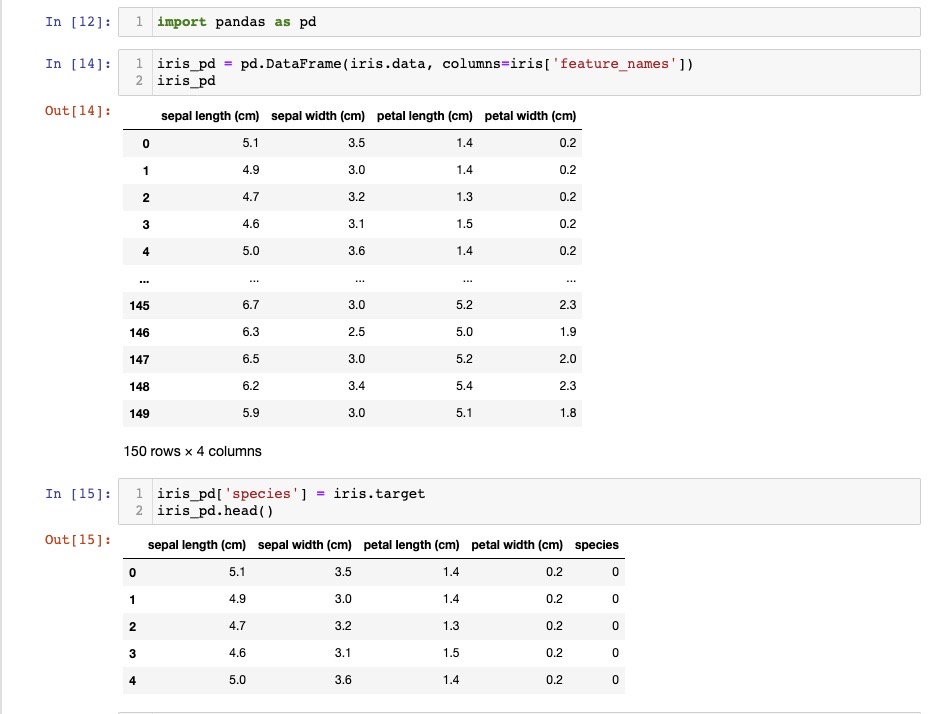
- 데이터프레임 생성, 품종 추가
- pairplot 확인
sns.pairplot(iris_pd, hue='species')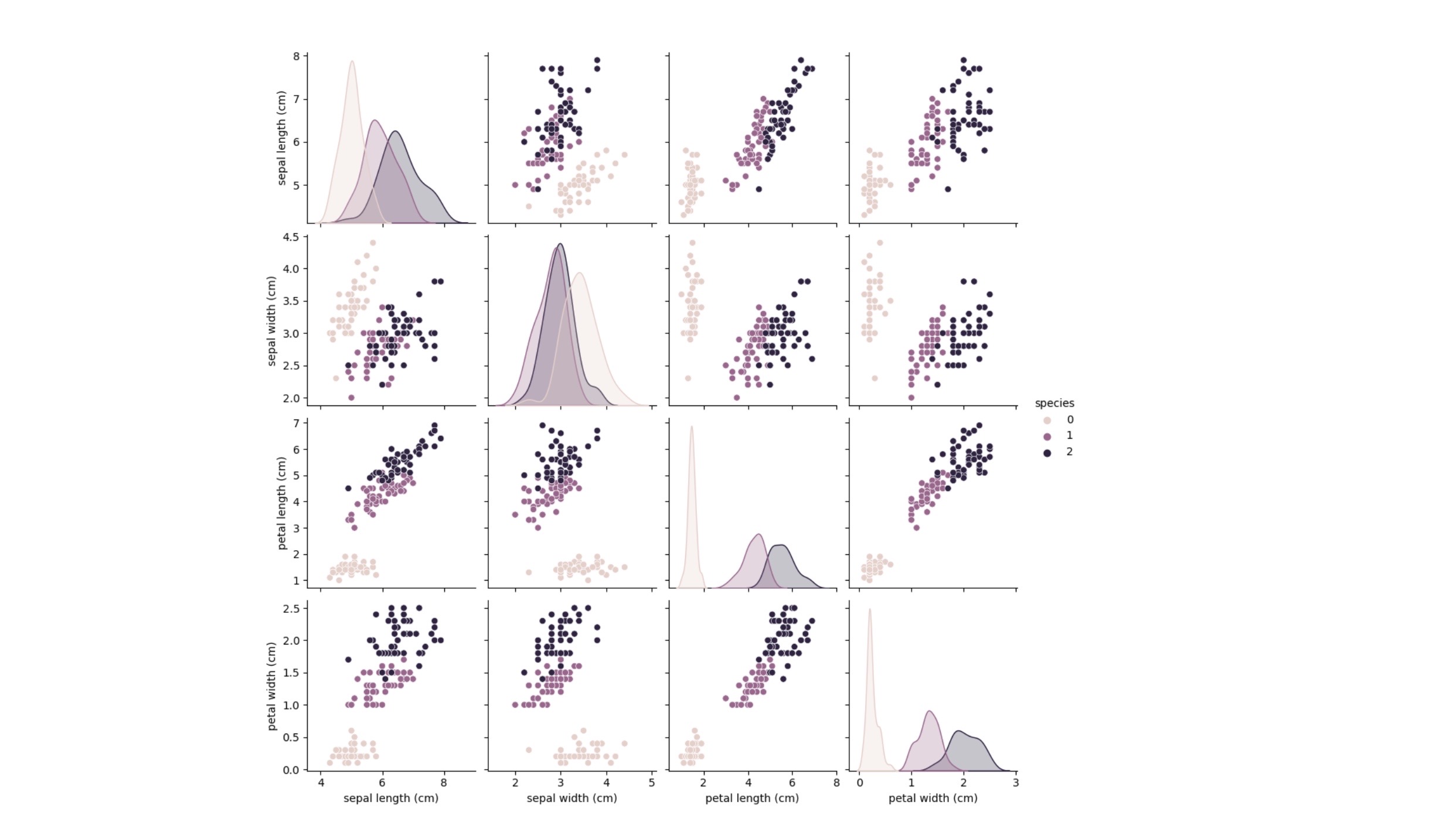
sns.pairplot(data=iris_pd, vars=['petal length (cm)', 'petal width (cm)'], hue='species', height=4)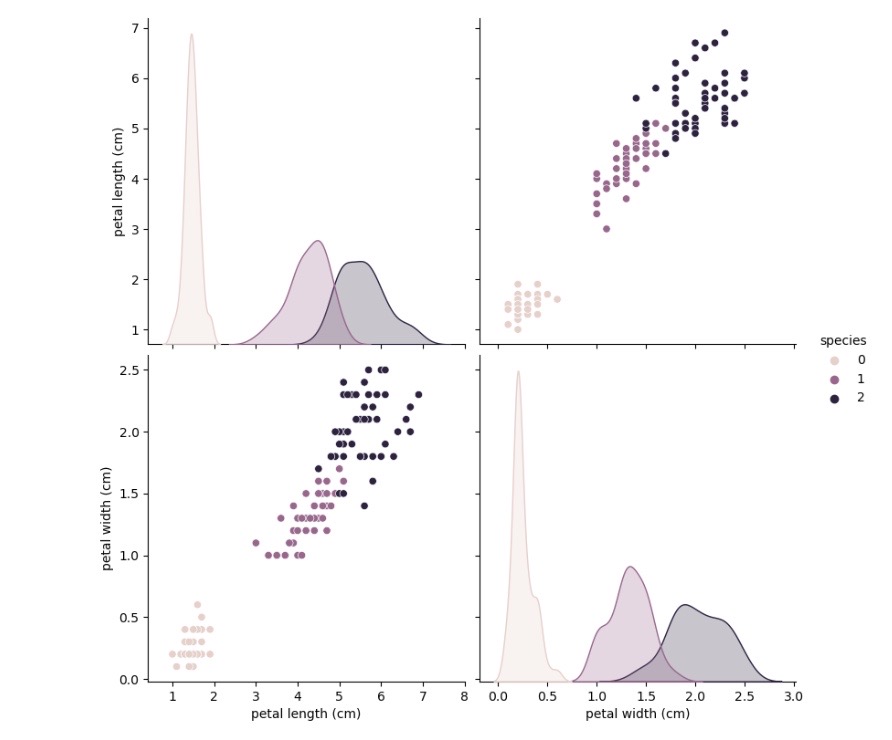
- iris 3종에 대한 구분이 가능할 것으로 보인다.2. 데이터 나누기
- Decision Tree를 이용한 Iris 분류
from sklearn.tree import DecisionTreeClassifier
iris_tree = DecisionTreeClassifier()
---
# fit(학습할 데이터) # 정답 # petal length & width
iris_tree.fit(iris.data[:, 2:], iris.target) 
# petal length&width 150개 정답과 함께 학습 완료한 iris_tree에 150개 값만 가지고 예측하는 성능 확인
from sklearn.metrics import accuracy_score
y_pred_tr = iris_tree.predict(iris.data[:, 2:])
y_pred_tr
iris.target
3. Tree model
from sklearn.tree import plot_tree
plt.figure(figsize=(12,8))
plot_tree(iris_tree);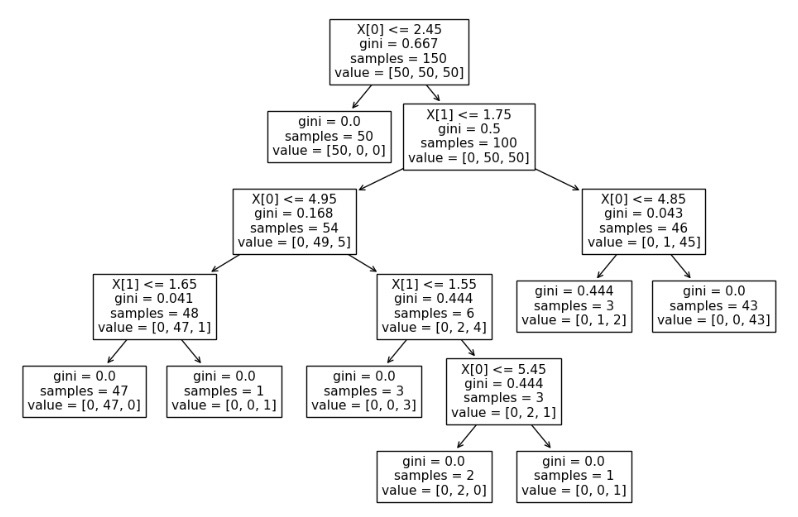
4. 결정 경계 확인
# !pip install mlxtend
from mlxtend.plotting import plot_decision_regions
plt.figure(figsize=(14,8))
plot_decision_regions(X=iris.data[:, 2:], y=iris.target, clf=iris_tree, legend=2)
plt.show()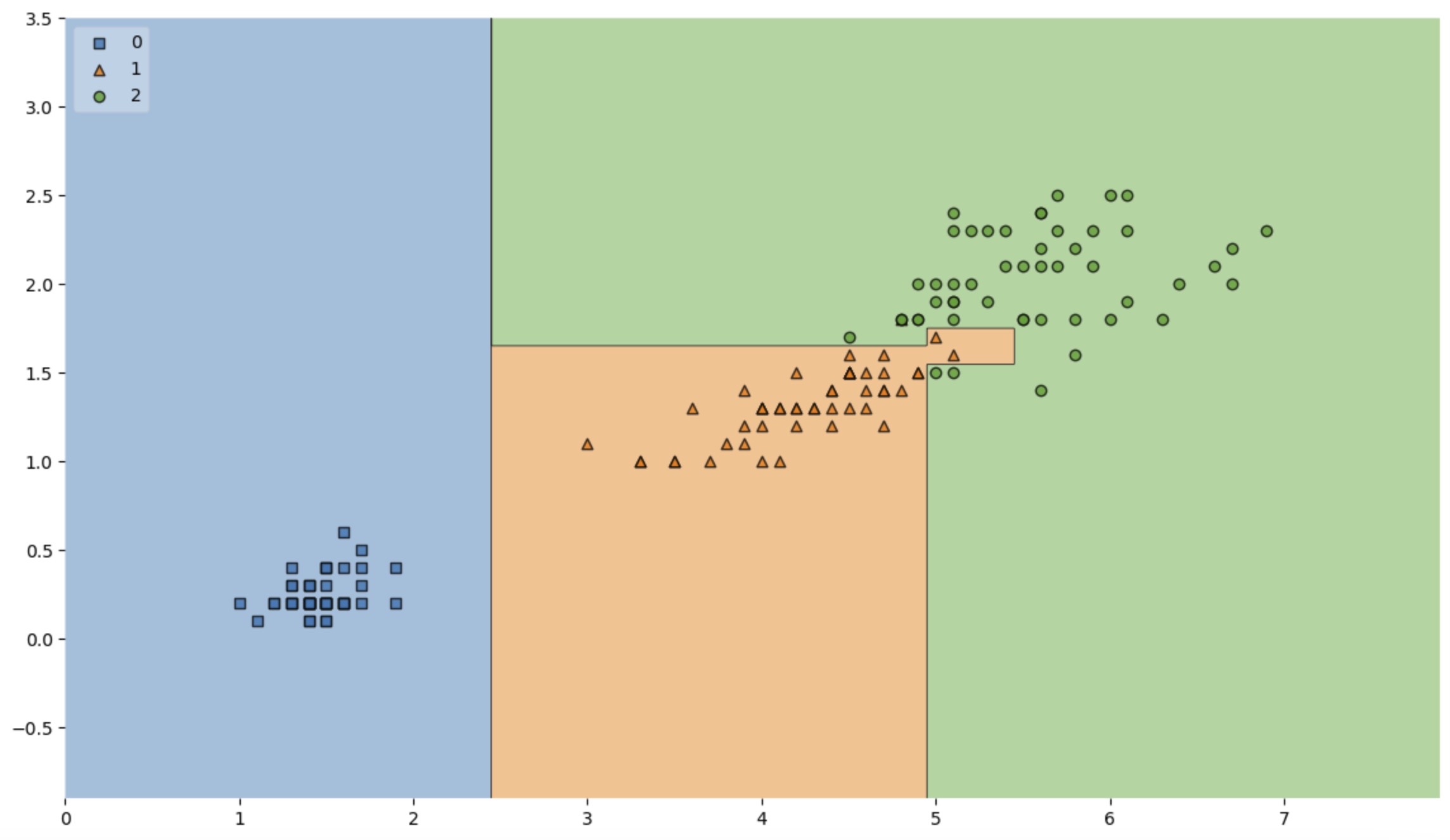
5. 정확도 계산
y_pred_tr = iris_tree.predict(iris.data[:, 2:])
accuracy_score(iris.target, y_pred_tr)
- 너무 복잡한 경계면은 모델의 성능을 나쁘게 만든다.
- 내 데이터를 벗어나서 일반화할 수 있을까?
Ⅲ 데이터 분리
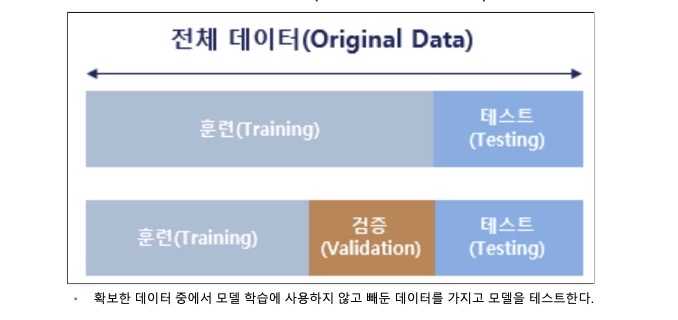
1. 시작
from sklearn.datasets import load_iris
import pandas as pd
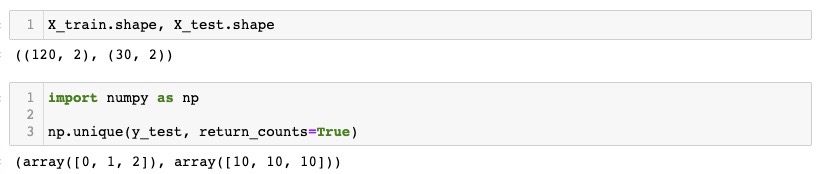
iris = load_iris()2. 훈련/테스트용 분리
X_train, X_test, y_train, y_test = train_test_split(features, labels,
test_size=0.2,
stratify=labels, # 항목당 추출 비율 동일하게
random_state=13)- 확인
3. Tree model
from sklearn.tree import DecisionTreeClassifier
iris_tree = DecisionTreeClassifier(max_depth=2, random_state=13)
iris_tree.fit(X_train, y_train)- 학습시 일관성을 위해 random_state는 일정하게
- 모델을 단순화하기 위해 max_depth를 조정 (2)
import matplotlib.pyplot as plt
from sklearn.tree import plot_tree
plt.figure(figsize=(12,8))
plot_tree(iris_tree);
# train 데이터에 대한 accuracy 확인
from sklearn.metrics import accuracy_score
y_pred_tr = iris_tree.predict(iris.data[:, 2:])
accuracy_score(iris.target, y_pred_tr)
- train 데이터에 대한 accruacy 확인
- iris 데이터는 단순해서 accruacy가 높게 나타남
4. 훈련용 데이터 결정 경계 확인
from mlxtend.plotting import plot_decision_regions
plt.figure(figsize=(14,8))
plot_decision_regions(X=X_train, y=y_train, clf=iris_tree, legend=2)
plt.show()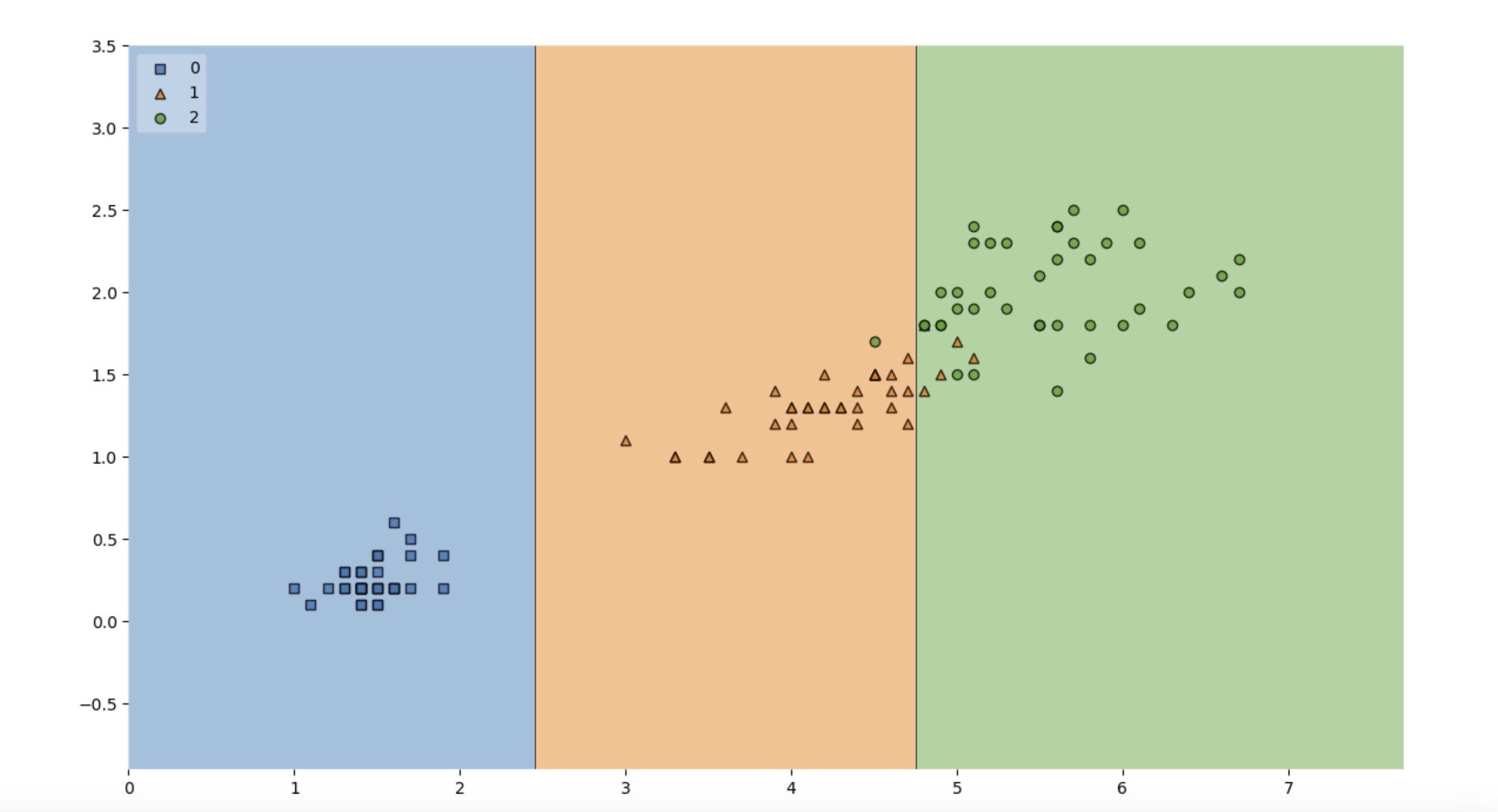
# test 데이터에 대한 accuracy 확인
y_pred_test = iris_tree.predict(X_test)
accuracy_score(y_test, y_pred_test)
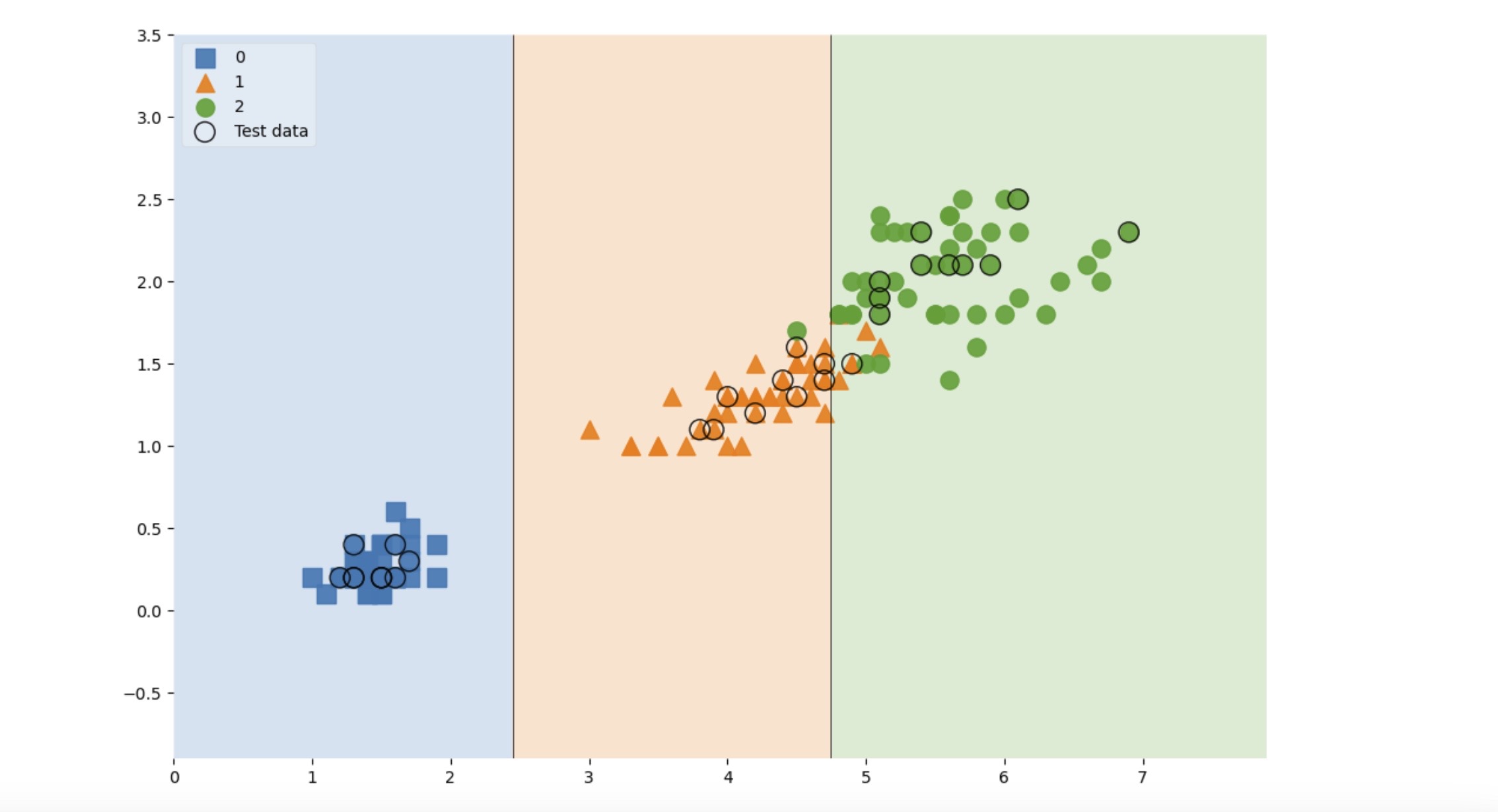
5. 전체 데이터에서 관찰
scatter_highlight_kwargs = {'s':150, 'label':'Test data', 'alpha':0.9}
scatter_kwargs = {'s':120, 'edgecolor':None, 'alpha':0.9}
plt.figure(figsize=(12,8))
plot_decision_regions(X=features, y=labels,
X_highlight=X_test, clf=iris_tree, legend=2,
scatter_highlight_kwargs=scatter_highlight_kwargs,
scatter_kwargs=scatter_kwargs,
contourf_kwargs={'alpha':0.2}
)
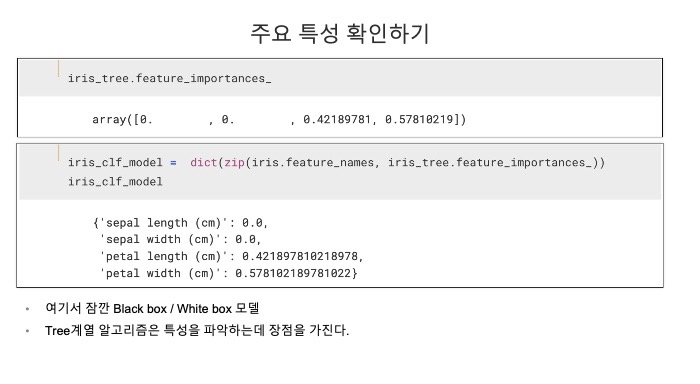
6. 전체 feature
features = iris.data
labels = iris.target
X_train, X_test, y_train, y_test = train_test_split(features, labels,
test_size=0.2,
stratify=labels, # 항목당 추출 비율 동일하게
random_state=13)
iris_tree = DecisionTreeClassifier(max_depth=2, random_state=13)
iris_tree.fit(X_train, y_train)- 전체 특성을 사용한 결정나무 모델
plt.figure(figsize=(12,8))
plot_tree(iris_tree);


3D 모델러의 개발 도전기