
Ⅰ. 데이터 탐색
Ⅱ. 생존자 예측
1. 데이터 확인
titanic.info()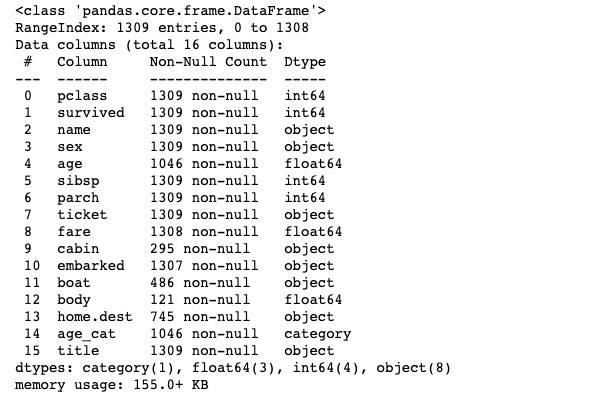
- LabelEncoder를 이용해 성별 컬럼을 숫자로 변경
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
le.fit(titanic['sex'])2. gender 컬럼 추가
titanic['gender'] = le.transform(titanic['sex'])
titanic.head()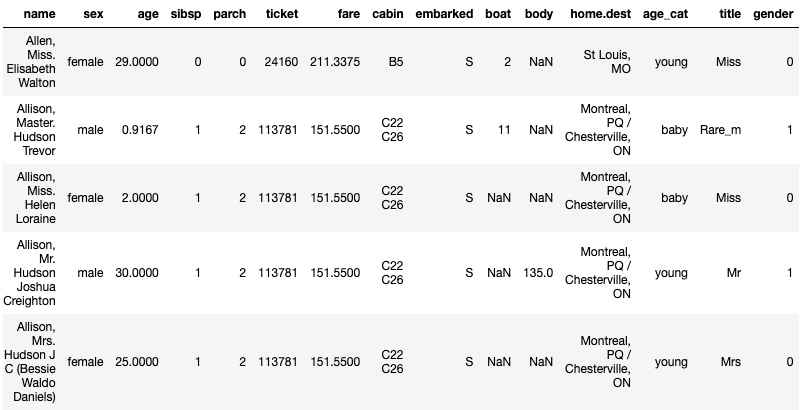
3. 결측치 제거
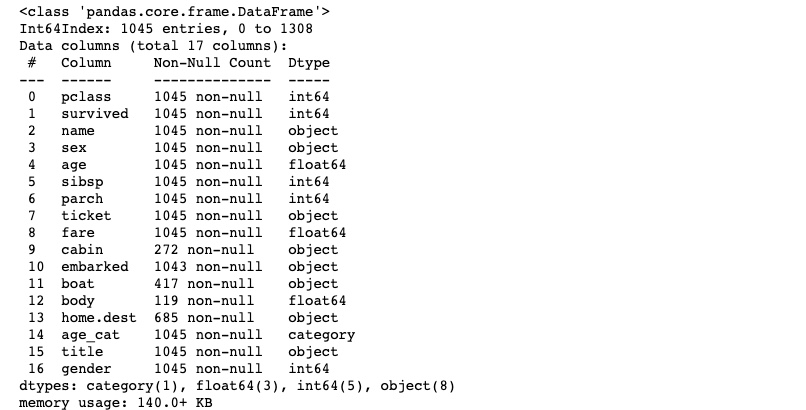
4. 특성 선택, 데이터 분리
from sklearn.model_selection import train_test_split
X = titanic[['pclass', 'age', 'sibsp', 'parch', 'fare', 'gender']]
y = titanic['survived']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.8, random_state=13)5. DecisionTree
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
dt = DecisionTreeClassifier(max_depth=4, random_state=13)
dt.fit(X_train, y_train) # 특성과 라벨 주고 훈련
- 위 모델에서 정확성은 약 76%
6. 디카프리오 형님의 생존율
# [['pclass', 'age', 'sibsp', 'parch', 'fare', 'gender']] 등실, 나이, 부모, 자녀, 요금, 성별
import numpy as np
dicaprio = np.array([[3, 18, 0, 0, 5, 1]])
print('Dicaprio : ', dt.predict_proba(dicaprio)[0, 1])
- 생존률 : 약 22%
7. 윈슬렛 누나의 생존률
winslet = np.array([[1, 16, 1, 1, 100, 0]])
print('Winslet : ', dt.predict_proba(winslet)[0, 1])- 생존률 : 100%

3D 모델러의 개발 도전기