
Ⅰ. 이디야커피가 스타벅스 근처에 있을까?
-
https://www.starbucks.co.kr/store/store_map.do?disp=locale%27
-
사이트 구조 확인
- 스타벅스 주소 (서울시 한정)
- 이디야커피 주소 (서울시 한정)
- 두 브랜드 위치 비교 (동일브랜드 제외 100미터 안에 있는지 확인)
- 인접한 카페와 전체 카페 수의 비율이 20% 이상인 경우,
이디야커피가 스타벅스의 근처에 있는 것을 참으로 가정
Ⅱ. 스타벅스 웹크롤링
- 사전준비
from selenium import webdriver
from bs4 import BeautifulSoup
from urllib.request import urlopen
from tqdm import tqdm_notebook
import pandas as pd
import numpy as np
import time- 스타벅스 매장찾기 접근
driver = webdriver.Chrome("../driver/chromedriver") # "../driver/chromedriver.exe"
driver.get("https://www.starbucks.co.kr/store/store_map.do?disp=locale%27")
time.sleep(10)- 스타벅스 매장 위치 (서울 전체)
driver.find_element_by_class_name("loca_search").click() # 지역검색 클릭
time.sleep(2)
driver.find_element_by_class_name('sido_arae_box > li').click() # 서울 클릭
time.sleep(2)
driver.find_element_by_class_name("set_gugun_cd_btn").click() # 서울 전체 클릭
time.sleep(2)- 페이지 전체 html 코드 가져오기
# 현재 페이지의 HTML 전체 코드를 가져온다
html = driver.page_source
# 가져온 HTML 코드를 라인별로 구분한다
soup = BeautifulSoup(html, 'html.parser')- 스타벅스 매장 수 확인
len(starbucks_seoul_list) # 599호점

- 스타벅스 [매장명], [매장주소] 크롤링
starbucks_list = []
for item in starbucks_soup_list : # 서울에 599 store
store_name = item.select('strong')[0].text.strip()
store_address = str(item.select('p.result_details')[0]).split('<br/>')[0].split('>')[1]
starbucks_list.append([store_name,store_address])- 데이터프레임 생성
import pandas as pd
columns = ['매장명', '매장주소']
seoul_starbucks = pd.DataFrame(starbucks_list, columns=columns)
seoul_starbucks.head() 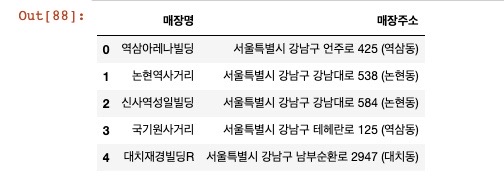
- 스타벅스 [매장주소]에서 [구] 추출
for eachAddress in seoul_starbucks["매장주소"]:
print(eachAddress.split()[1])- 데이터프레임에 [구]와 [브랜드] 추가
seoul_starbucks["구"] = [eachAddress.split()[1] for eachAddress in seoul_starbucks["매장주소"]] # 구 저장
seoul_starbucks["브랜드"] = "스타벅스"
seoul_starbucks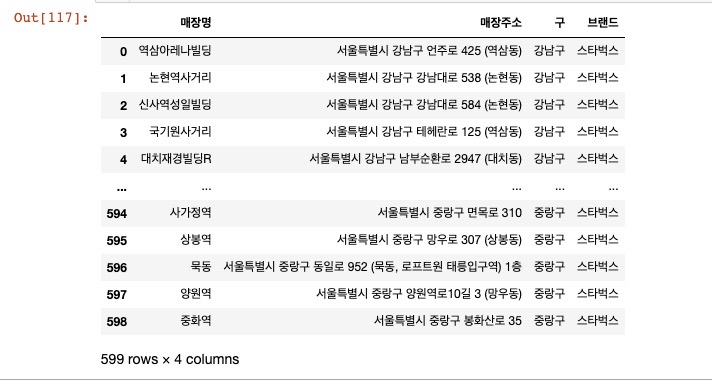
10. 저장 및 닫기
seoul_starbucks.to_csv("../data/P1. seoul_starbucks_raw.csv", sep=",", encoding="utf-8")
driver.close()Ⅲ. 이디야커피 웹크롤링
- 스타벅스의 "구" 리스트 불러오기
gu_list = list(seoul_starbucks["구"].unique())
len(gu_list)- 이디야커피 매장찾기 접근
driver = webdriver.Chrome("../driver/chromedriver") # "../driver/chromedriver.exe"
driver.get("https://www.ediya.com/contents/find_store.html#c")
time.sleep(10)- 주소 탭
driver.find_element_by_xpath('//*[@id="contentWrap"]/div[3]/div/div[1]/ul/li[2]/a').click()- "매장명", "매장주소", "구" 가져오기, "브랜드" 추가
# 전체 매장 정보를 저장할 초기화 변수 선언
ediya_list = []
# 구별 데이터 검색
for gu in tqdm_notebook(gu_list):
# 이디야 주소 검색어 초기화
driver.find_element_by_xpath('//*[@id="keyword"]').clear()
# 검색어 입력
driver.find_element_by_xpath('//*[@id="keyword"]').send_keys(f"서울 {gu}")
# 검색어 버튼 탭
driver.find_element_by_xpath('//*[@id="keyword_div"]/form/button').click()
html = driver.page_source
soup = BeautifulSoup(html, "html.parser")
ul_tag = soup.find("ul", id="placesList")
dl_all = ul_tag.find_all("dl")
for dl in dl_all:
store_name = dl.find("dt").text.strip()
store_address = dl.find("dd").text.strip()
gu = address.split()[1]
each = {
"매장명":store_name, "매장주소":store_address, "구":gu, "브랜드":"이디야커피"
}
ediya_list.append(each)- 이디야커피 매장 수 확인
len(ediya_list)
-
스타벅스와 이디야커피가 동일한 형식의 데이터프레임인지 확인
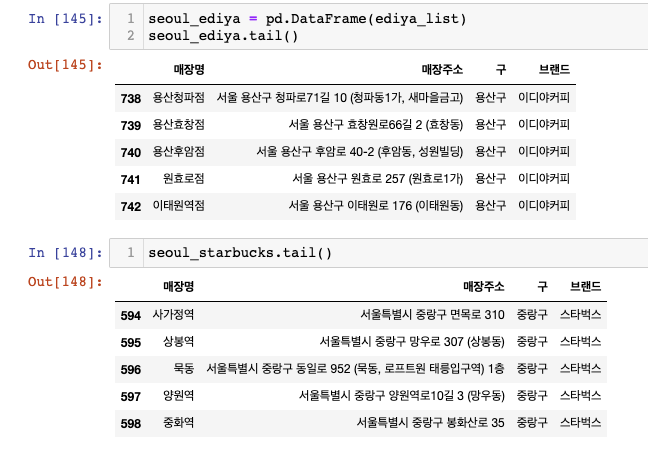
-
두 데이터프레임을 concat으로 이어붙이기
seoul_cafe = pd.concat([seoul_starbucks, seoul_ediya])
seoul_cafe
8. 드라이버 정리
driver.quit()Ⅳ. 위도 / 경도 데이터
- 사전 준비
import googlemaps
google_maps_key = "AIzaSyAfUt64G3GBz-q0WUk8s4udRolATNQQLD4"
gmaps = googlemaps.Client(key=google_maps_key)
gmaps- 데이터프레임에 위도와 경도 값을 NaN데이터로 추가
seoul_cafe["위도"] = np.nan
seoul_cafe["경도"] = np.nan
seoul_cafe.tail()
3. 위도, 경도 데이터 테스트
tmp[0].get("geometry")["location"]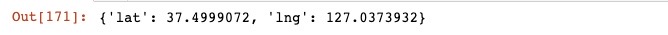
4. 위도, 경도 데이터 가져오기, 결측값 확인
for idx, rows in tqdm_notebook(seoul_cafe.iterrows()):
rows["매장주소"]
tmp = gmaps.geocode(rows["매장주소"], language="ko")
if tmp:
lat = tmp[0].get("geometry")["location"]["lat"]
lng = tmp[0].get("geometry")["location"]["lng"]
seoul_cafe.loc[idx, "위도"] = lat
seoul_cafe.loc[idx, "경도"] = lng
else:
print(idx, rows["매장주소"])
- 결측값인 10개 store 제거 (행 기준, axis=0)
seoul_cafe = seoul_cafe.dropna(axis=0)- 인덱스 재지정
seoul_cafe.reset_index(inplace=True)
seoul_cafe.tail()
- "index" 삭제
del seoul_cafe["index"]
seoul_cafe.tail()
- 데이터프레임 최종본 저장
seoul_cafe.to_csv("../data/seoul_coffee_king.csv", sep=",", encoding="utf-8")Ⅴ. 지도 시각화
- 사전 준비
import json
import folium
import warnings
warnings.simplefilter(action="ignore", category=FutureWarning)- 지도 시각화
- 서울 지도에 브랜드 상징색 원을 반경 100m로 그리기
my_map = folium.Map(location=[37.5502, 126.982], zoom_start=10.5, tiles="Stamen Toner")
my_map
for idx, rows in seoul_cafe.iterrows():
if rows["브랜드"] == "스타벅스":
brand_color = "darkgreen"
brand_fill_color = "green"
elif rows["브랜드"] == "이디야커피":
brand_color = "darkblue"
brand_fill_color = "blue"
folium.Circle(
location = [rows["위도"], rows["경도"]],
radius=100,
popup = rows["매장주소"],
tooltip = rows["매장명"],
color=brand_color,
fill_color=brand_fill_color
).add_to(my_map)
my_map- 전체 사진
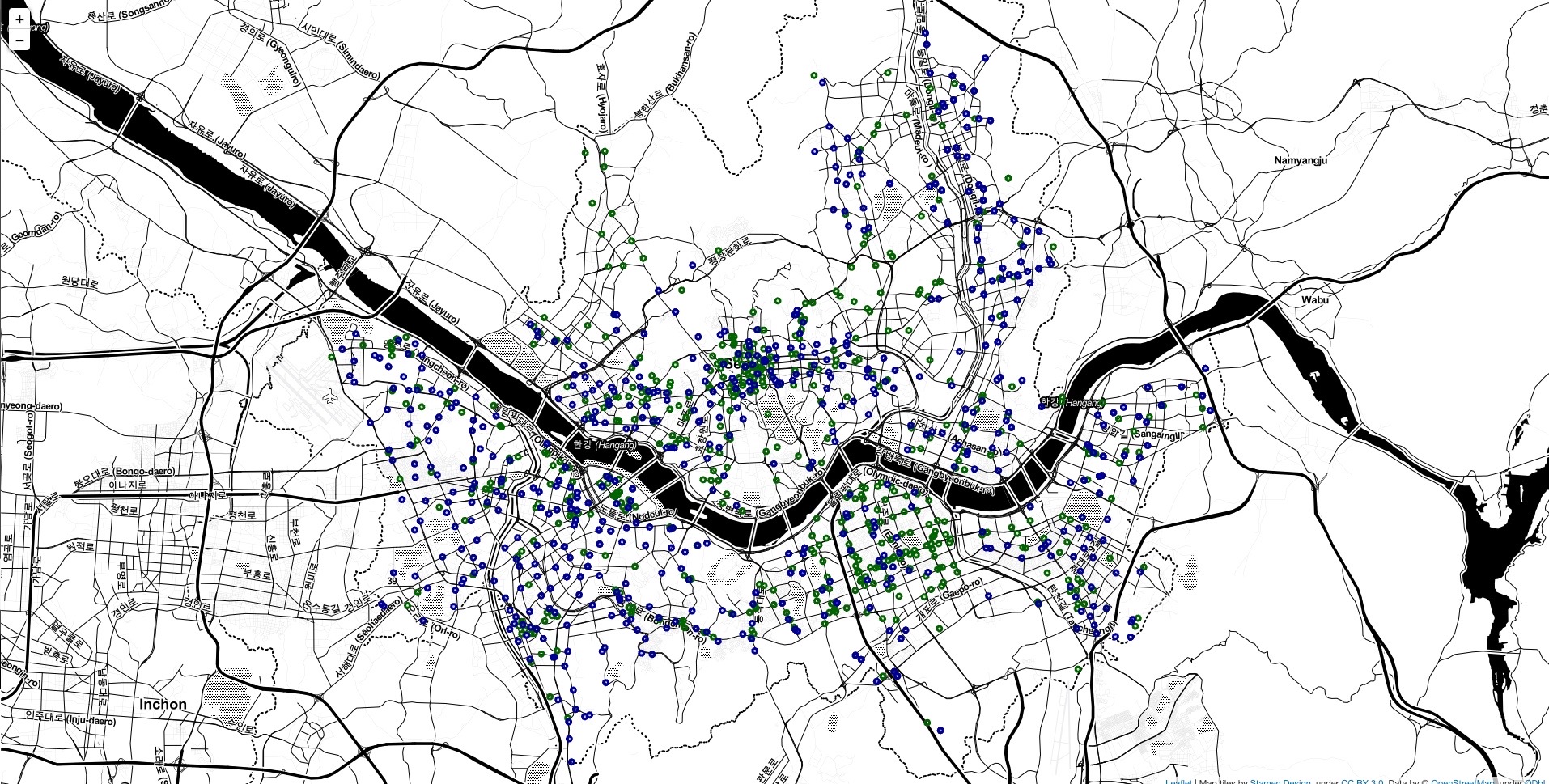
- 부분 확대 사진
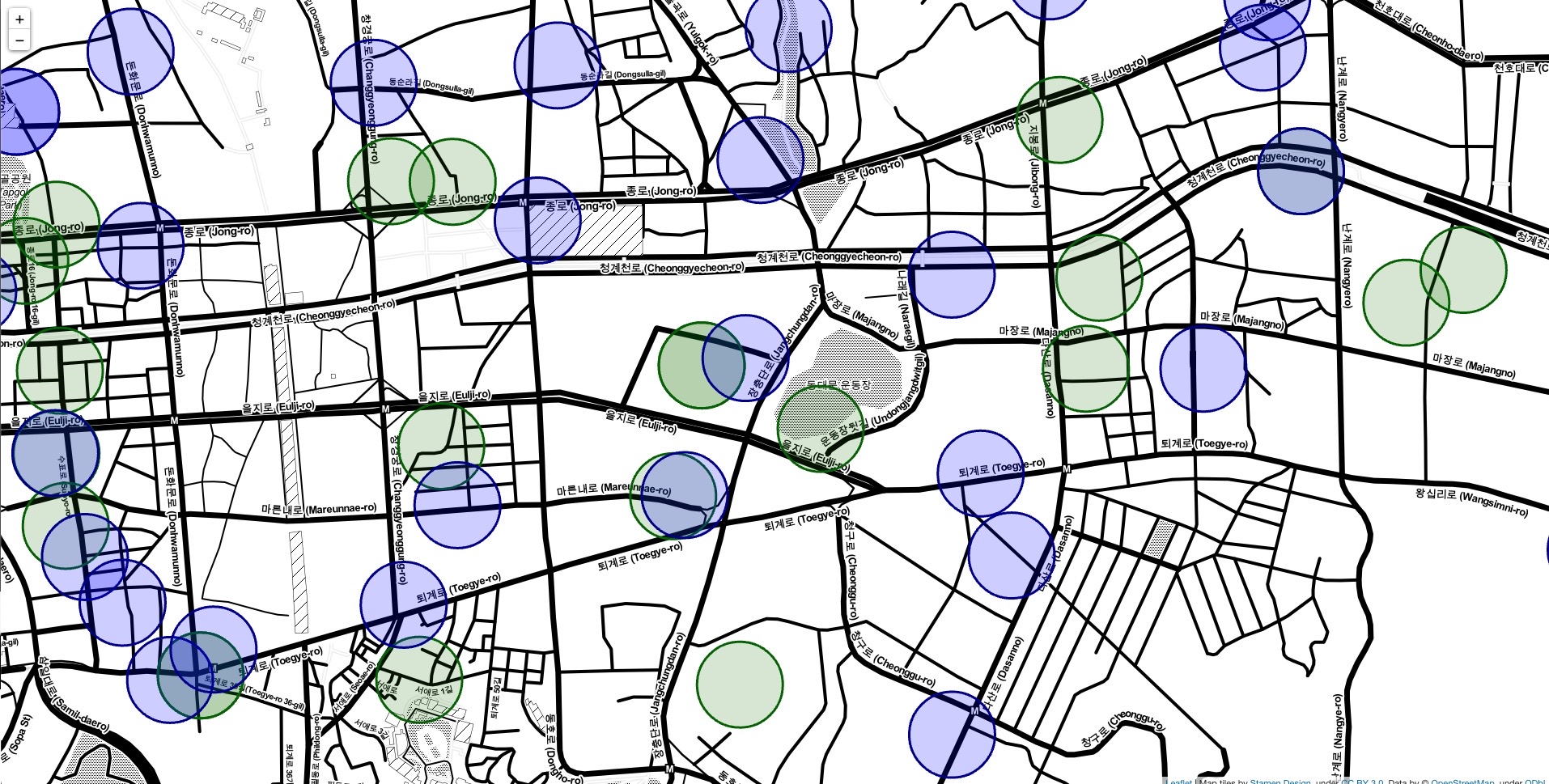
- 100m 이내 겹치는 상권 직접 확인 후 정리
seoul_cafe_distance_check = pd.read_csv("../data/seoul_coffee_king(100m).csv", encoding="utf-8", index_col=0)
seoul_cafe_distance_check.head() 
- 100m 이내 겹치는 점포 수 확인
seoul_cafe_distance_check.info()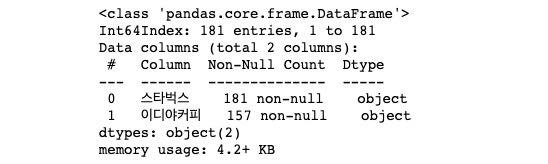
Ⅵ. 정리 및 결론
-
스타벅스
- 총 점포 : 599곳 / 인접한 점포 : 181곳 -
이디야커피
- 총 점포 : 743곳 / 인접한 점포 : 157곳 -
인접도 = 21.16%
- (스타벅스 인접 점포 수 + 이디야 인접 점포 수) / (스타벅스 총 점포 수 + 이디야 총 점포 수) * 100
결론 : 인접도가 20%보다 높으므로 이디야커피가 스타벅스 근처에 있다고 볼 수 있다.

3D 모델러의 개발 도전기