
Ⅰ. 셀프주유소는 더 저렴한가?
-
사이트 구조 확인
- 주유소명
- 주소
- 브랜드
- 휘발유 / 경유 가격
- 셀프 여부
- 세자장 여부
- 충전소 여부
- 경정비 여부
- 편의점 여부
- 24시간 운영 여부
- 구
- 위도, 경도
-
결론
- 가격 비교
Ⅱ. 주유소 웹 크롤링
- 필요한 모듈 import
from selenium import webdriver
from bs4 import BeautifulSoup
from urllib.request import urlopen
from tqdm import tqdm_notebook
from matplotlib import font_manager as fm
from matplotlib import rc
import time
import pandas as pd
import googlemaps
import matplotlib
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np- 페이지 접근
# 페이지 접근
import time
# 페이지 접근
url = "https://www.opinet.co.kr/searRgSelect.do"
driver = webdriver.Chrome("../driver/chromedriver") # Windows: +.exe
driver.get(url)
time.sleep(3)
# 팝업창으로 전환
driver.get(url)
# 팝업창 닫아주기
driver.close()
time.sleep(3)
# 메인화면 창으로 전환
driver.switch_to_window(driver.window_handles[-1])
# 접근 URL 다시 요청
driver.get(url)- 지역검색창 - 서울
sido_select = driver.find_element_by_id("SIDO_NM0")
sido_select.send_keys("서울")- 리스트 확인
gu_select = driver.find_element_by_id("SIGUNGU_NM0")
gu_list = gu_select.find_elements_by_tag_name("option")
gu_names = [item.get_attribute("value") for item in gu_list]
gu_names = gu_names[1:]
gu_names- 현재 페이지의 HTML 전체 코드를 가져오고, 라인별로 구분
html = driver.page_source
soup = BeautifulSoup(html, 'html.parser')- 데이터 크롤링
oil_info = []
for gu_name in tqdm_notebook(gu_names):
time.sleep(1)
driver.find_element_by_id("SIGUNGU_NM0").send_keys(gu_name)
req = driver.page_source
soup = BeautifulSoup(req, "html.parser")
info = soup.find(id = "body1").find_all("tr")
for item in info :
name = item.find("a").text.strip()
brand = item.find("img")['alt']
address = item.find("a")['href'].split(",")[-11].replace("'","")
gasoline_cost = item.find_all("td", class_ = "price")[0].text.strip()
diesel_cost = item.find_all("td", class_ = "price")[1].text.strip()
# self 유무 조건식
if item.find("span", class_= "ico") != None:
if item.find("span", class_= "ico").text == '셀프':
self="Y"
else : self="N"
else : self="N"
gu = address.split(" ")[1]
data = {
"name" : name,
"gu" : gu ,
"brand" : brand,
"address" : address,
"gasoline" : gasoline_cost,
"diesel" : diesel_cost,
"self" : self
}
oil_info.append(data)
len(oil_info)- 가솔린, 디젤 데이터 형식을 float으로 변환
df_final["gasoline"] = df_final["gasoline"].astype("float")
df_final["diesel"] = df_final["diesel"].astype("float")- 데이터프레임 정리
df_oil = pd.DataFrame(oil_info)
df_oil.tail()
- 세차장 데이터 수집
wash_info = []
driver.find_element_by_id("CWSH_YN").click()
for gu_name in tqdm_notebook(gu_names):
time.sleep(1)
driver.find_element_by_id("SIGUNGU_NM0").send_keys(gu_name)
req = driver.page_source
soup = BeautifulSoup(req, "html.parser")
info = soup.find(id = "body1").find_all("tr")
for item in info :
address = item.find("a")['href'].split(",")[-11].replace("'","")
wash = 'Y'
data = {
"address" : address,
"wash" : wash
}
wash_info.append(data)
len(wash_info)
- 세차장 데이터 확인
df_wash = pd.DataFrame(wash_info)
df_wash.tail()
- 세차장 데이터 업데이트 및 NaN 데이터 N으로 채우기
df_final = pd.merge(df_oil, df_wash, on = "address", how = 'left')
df_final = df_final.fillna("N")
df_final.tail(5)
- 경정비 데이터 수집
fix_info = []
driver.find_element_by_id("CWSH_YN").click()
time.sleep(1)
driver.find_element_by_id("MAINT_YN").click()
for gu_name in tqdm_notebook(gu_names):
time.sleep(1)
driver.find_element_by_id("SIGUNGU_NM0").send_keys(gu_name)
req = driver.page_source
soup = BeautifulSoup(req, "html.parser")
info_find = soup.find(id = "body1")
if info_find != None :
info = info_find.find_all("tr")
for item in info :
address = item.find("a")['href'].split(",")[-11].replace("'","")
fix = 'Y'
data = {
"address" : address,
"maintenance" : fix
}
fix_info.append(data)
else : continue
len(fix_info)
- 경정비 데이터 확인
df_fix = pd.DataFrame(fix_info)
df_fix.tail()
- 경정비 데이터 업데이트 및 NaN데이터 N으로 채우기
df_final = pd.merge(df_final, df_fix, on = "address", how = 'left')
df_final = df_final.fillna("N")
df_final.tail(5)
- 충전소 데이터 수집
driver.find_element_by_id("LPG_BTN").click()
driver.find_element_by_id("SIDO_NM0").send_keys("서울")
charge_list = []
for gu_name in tqdm_notebook(gu_names):
time.sleep(1)
driver.find_element_by_id("SIGUNGU_NM0").send_keys(gu_name)
req = driver.page_source
soup = BeautifulSoup(req, "html.parser")
info = soup.find(id = "body1")
if info != None :
info_find = info.find_all("tr")
for item in info_find:
address = item.find("a")['href'].split(",")[-11].replace("'","")
charge = "Y"
data = {
"address" : address,
"charger" : charge
}
charge_list.append(data)
else : continue
len(charge_list)
- 충전소 데이터 확인
df_charge = pd.DataFrame(charge_list)
df_charge.tail()
- 충전소 데이터 업데이트 및 NaN 데이터 N으로 채우기
df_final = pd.merge(df_final, df_charge, on = "address", how = 'left')
df_final = df_final.fillna("N")
df_final.head()
Ⅲ. 위도/경도 (gmaps)
- gmaps 키 입력
google_maps_key = "AIzaSyAfUt64G3GBz-q0WUk8s4udRolATNQQLD4"
gmaps = googlemaps.Client(key=google_maps_key)- 위도, 경도 추가 및 확인
df_final["lat"] = np.nan
df_final["lng"] = np.nan
df_final.tail()
- 주유소 주소 데이터로 위도/경도 확인
for idx, rows in tqdm_notebook(df_final.iterrows()):
rows["address"]
tmp = gmaps.geocode(rows["address"], language="ko")
if tmp:
lat = tmp[0].get("geometry")["location"]["lat"]
lng = tmp[0].get("geometry")["location"]["lng"]
df_final.loc[idx, "lat"] = lat
df_final.loc[idx, "lng"] = lng
else:
print(idx, rows["address"])- 데이터 형식 확인 (Dtype, NaN값 등)
df_final.info()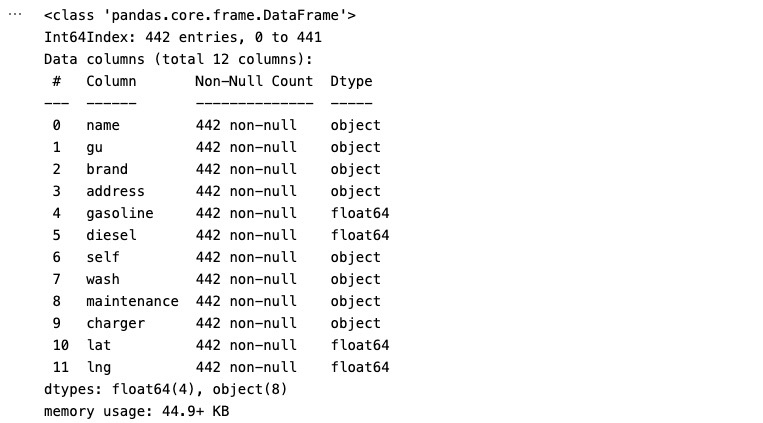
- 데이터프레임 확인
df_final.tail()
- 데이터프레임 저장
df_final.to_csv("../data/seoul_gas_station_data.csv", sep=",", encoding="utf-8")- 데이터프레임 불러오기 및 확인
df_final.csv = pd.read_csv("../data/seoul_gas_station_data.csv", encoding="utf-8", index_col=0)
df_final.csv.tail()
Ⅳ. 데이터 시각화
- 사전 준비 및 글꼴 설정
import matplotlib.pyplot as plt
import seaborn as sns
import platform
from matplotlib import font_manager, rc
get_ipython().run_line_magic("matplotlib", "inline")
# %matplotlib inline
path = "C;/Windows/Fonts/malgun.ttf"
if platform.system() == "Darwin":
rc("font", family = "Arial Unicode MS")
elif platform.system == "Windows":
font_name = font_mananger.Fontproperties(fname=path).get_name()
rc("font", family = "family=font_name")
else:
print("Unknown system. sorry~")- 가솔린과 디젤 가격 비교 (by="self")
# boxplot(feat. pandas)
df_final.boxplot(column=("gasoline", "diesel"), by="self", figsize=(12, 8))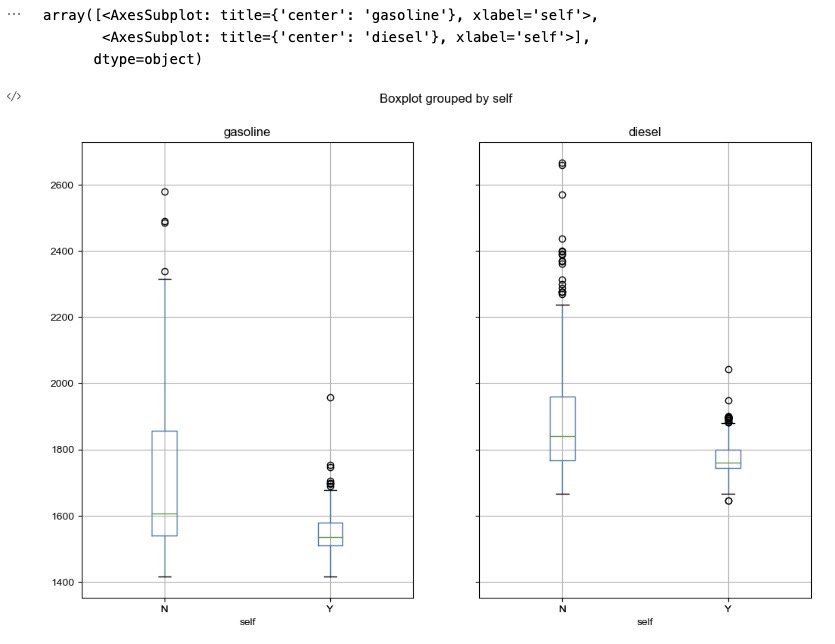
- 가솔린 가격 비교 (by="self")
# boxplot(feat. seaborn)
plt.figure(figsize=(12, 8))
sns.boxplot(x="self", y="gasoline", data=df_final, palette="Set3")
plt.grid(True)
plt.show()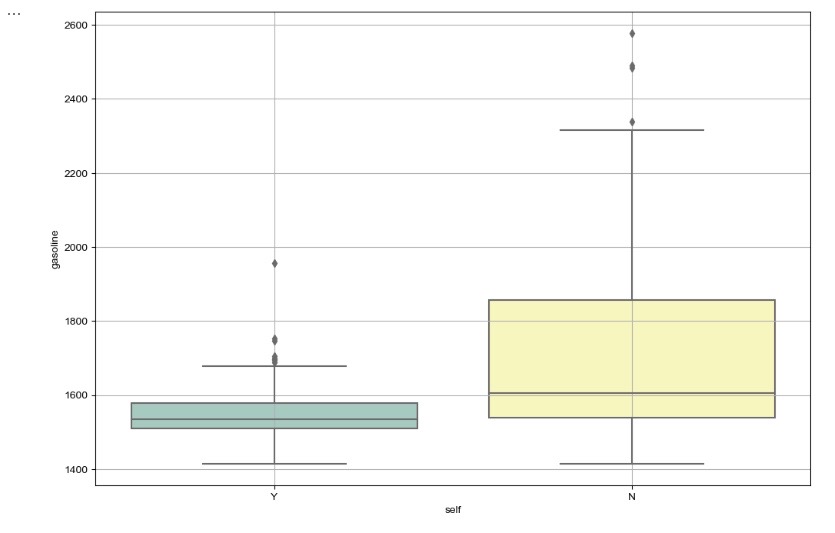
- 디젤 가격 비교 (by="self")
# boxplot(feat. seaborn)
plt.figure(figsize=(12, 8))
sns.boxplot(x="self", y="diesel", data=df_final, palette="Set3")
plt.grid(True)
plt.show()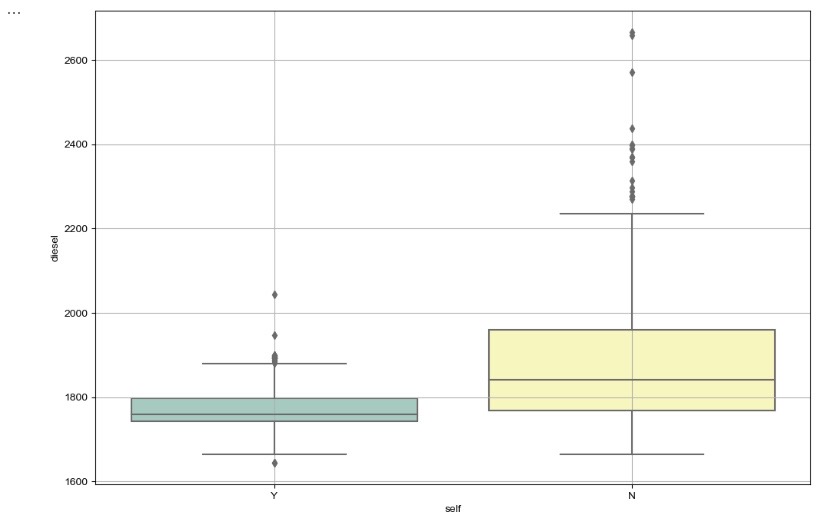
- 브랜드별 휘발유 가격 비교 (hue="self")
# boxplot(feat. seaborn)
plt.figure(figsize=(12, 8))
sns.boxplot(x="brand", y="gasoline", hue="self", data=df_final, palette="Set3")
plt.grid(True)
plt.show()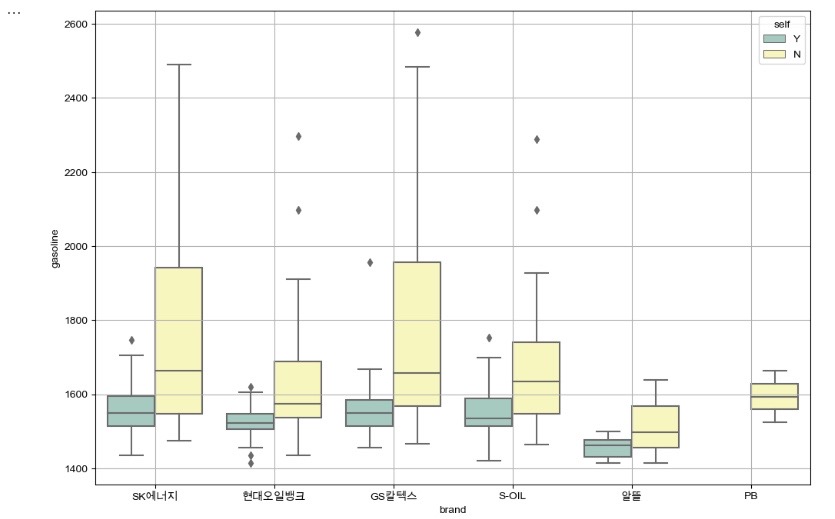
- 브랜드별 경유 가격 비교 (hue="self")
# boxplot(feat. seaborn)
plt.figure(figsize=(12, 8))
sns.boxplot(x="brand", y="diesel", hue="self", data=df_final, palette="Set3")
plt.grid(True)
plt.show()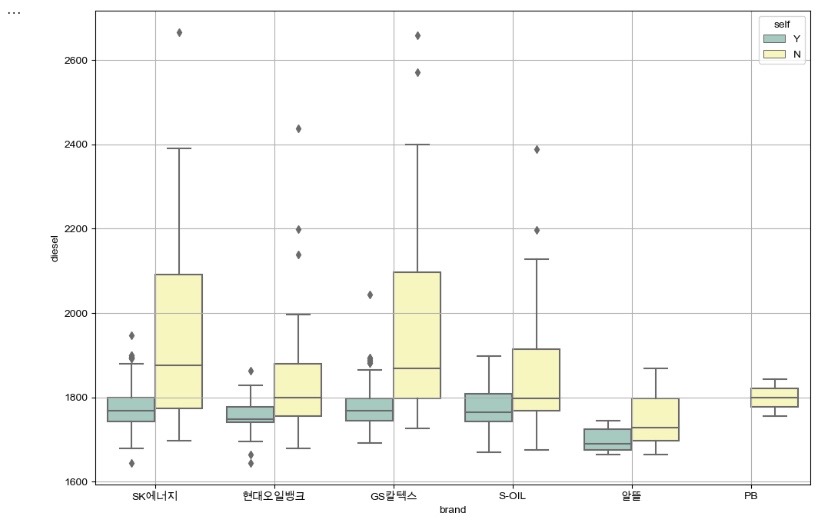
Ⅴ. 정리 및 결론
- boxplot으로 시각화한 결과 유종과 관계없이 IQR의 평균값이 셀프주유소가 전부 낮다.
- 셀프주유소의 IQR의 1.5배 이상 벗어난 값인 outlier값이 일반주유소의 IQR값에 포함되는 것을 알 수 있다.
결론 : 일반주유소보다 셀프주유소가 더 저렴하다고 볼 수 있다.

3D 모델러의 개발 도전기