
Pandas 라이브러리
✅ Pandas 란?
Pandas(Python Data Analysis Library) 는 파이썬에서 데이터 조작과 분석을 위한 가장 핵심적인 라이브러리
- 엑셀의 스프레드시트와 비슷한 테이블 형태의 데이터를 다룰 수 있음
- 결측치(null인 값) 처리, 데이터 변환, 집계 등 전처리 작업의 핵심 도구
- 시각화와 머신러닝으로 연결되는 데이터 파이프라인의 중심
✅ 패키지 란?
코드 뭉치를 하나의 포장지로 포장 해 놓은 형태
- 하나의 큰 파일 캐비닛 안에 여러 폴더들이 있는 모습
- 각 폴더는 특정 주제나 기능을 가진 파일들을 담고 있음
- 패키지는 이렇게 관련된 파일들을 폴더로 묶어서 체계적으로 정리하는 방법
라이브러리 import
#라이브러리 import
import pandas as pd
pd.__version__Series와 DataFrame의 개념
✅ Series = 컬럼, 리스트와 배열과 비슷하지만 더 강력한 기능 제공
✅ DataFrame = 멀티컬럼
✅ Method = 클래스의 기능
ages = pd.Series([25,30,35,28,32])
print("Series 예제:")
print(ages)[결과 값]

#ages의 타입 알아보기
print(f"타입:{type(ages)}")➡️ type = 내장 함수
➡️ ages= 파라미터 & 매개변수

DataFrame으로 바꾸기
#원래 알고 있던 출력 값
data = {
'name' : ['김철수','이영희','박민수','최지은']
,'age' : [25,30,35,28]
,'city' : ['서울','부산','대구','인천']
}
data[결과 값]

#DataFrame으로 바꾸기
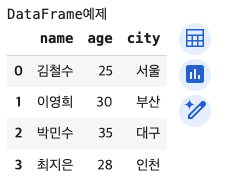
data = {
'name' : ['김철수','이영희','박민수','최지은']
,'age' : [25,30,35,28]
,'city' : ['서울','부산','대구','인천']
}
data[결과 값]
#디버깅 작업
type(df)[결과 값]
DataFrame 실습하기
# 실습용 데이터 생성
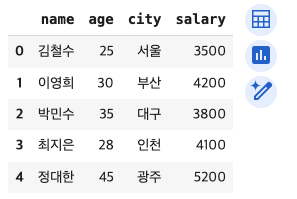
df = pd.DataFrame({
'name': ['김철수', '이영희', '박민수', '최지은', '정대한'],
'age': [25, 30, 35, 28, 45],
'city': ['서울', '부산', '대구', '인천', '광주'],
'salary': [3500, 4200, 3800, 4100, 5200]
})
df[결과 값]
#데이터 형태 읽는 방법
#속성(attribute): 명사 / 매서드(Method) = 동사
df.shape #shape은 속성[결과 값]

✅ 결과 값: 행렬 (5 by 4)
#컬럼명 확인
df.columns[결과 값]

# df.index: 인덱스 정보 확인
df.index[결과 값]

✅ 결과 값 해석: 0에서 시작해서 5에서 멈추고 1단계씩 증가한다.
# df.dtypes: 각 컬럼의 데이터 타입 확인
df.dtypes[결과 값]

✅ 결과 값 해석: name,city 컬럼은 str타입, age,salary 컬럼은 int 타입
# 전체 컬럼명 변경
df.columns = ['이름', '나이', '도시', '연봉']
#속성에는 값을 할당할 수 있다. 반대로 매써드에는 값을 할당할 수 없다.
print("변경된 컬럼명:")
print(df.columns.tolist())[결과 값]

✅ columns: 속성, tolist() 매써드
DataFrame 실습하기 2 (w.타이타닉)
# 타이타닉 데이터셋 불러오기
url = "https://raw.githubusercontent.com/datasciencedojo/datasets/master/titanic.csv"
titanic = pd.read_csv(url)
titanic[결과 값]

#타이타닉 데이터 형태 알아보기
print("데이터 불러오기 성공!")
titanic.shape[결과 값]

# 처음 5행 확인
print("처음 5행:")
titanic.head() #괄호 안에 보고 싶은 값 개수만큼 숫자 넣기[결과 값]
✅ head(): 메써드, 데이터 프레임의 처음 5행을 불러온다.
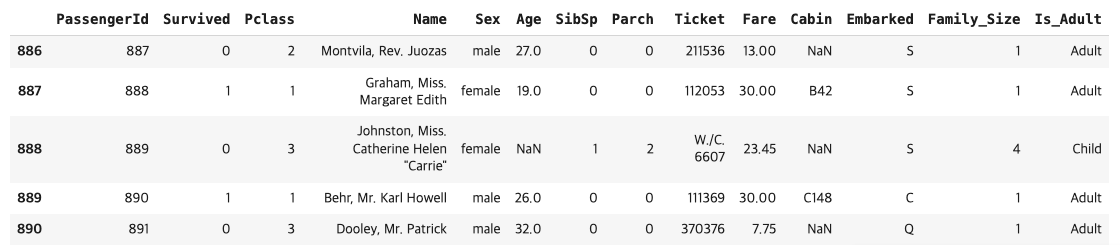
# 끝 5행 확인
titanic.tail() #괄호 안에 보고 싶은 값 개수만큼 숫자 넣기[결과 값]
# 전체적인 데이터 정보 확인
print("데이터 정보:")
titanic.info()
#714 non-null은 null이 아닌 값이 714개가 있다는 것
#결측치(null인 값)와 연결이 되어있다.[결과 값]
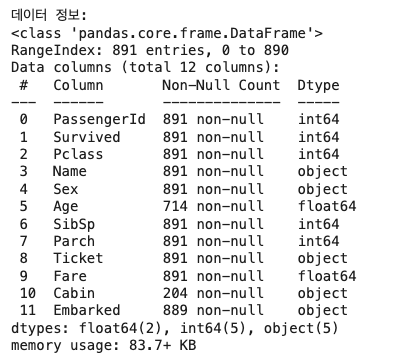
- 총 행 수와 컬럼 수
- 각 컬럼의 데이터 타입
- 결측치(null) 개수
- 메모리 사용량
- 기본 통계 정보 확인
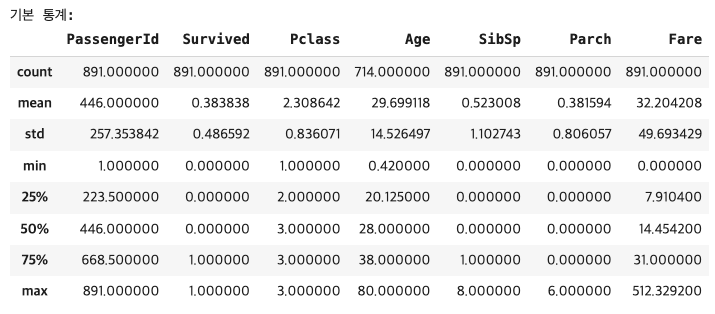
# 기본 통계 정보 확인
print("기본 통계:")
titanic.describe()[결과 값]
# iloc: 위치(정수) 기반 선택
#라벨(인덱스 이름) 기반으로 선택
print("첫 번째 행:")
titanic.iloc[0][결과 값]

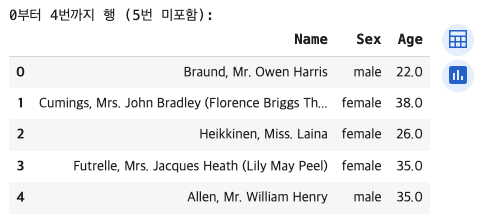
# 여러 행 선택 (끝 미포함)
print("0부터 4번까지 행 (5번 미포함):")
titanic.iloc[0:5, [3, 4, 5]]
# 3, 4, 5번째 컬럼
#0:5 인덱스 범주[결과 값]
# loc: 라벨(인덱스 이름) 기반 선택
print("0번 인덱스 행:")
print(titanic.loc[0])[결과 값]

# 여러 행 선택 (끝 포함)
print("0부터 4번까지 행:")
titanic.loc[0:4, ['Name', 'Age', 'Sex']][결과 값]

# 여성 승객만 선택
females = titanic[titanic['Sex'] == 'female']
#타이타닉이 두 번 들어감
#타이타닉이라는 전체 데이터 프레임에서 ['sex'] 컬럼에서 값이 ['female']인 애들만 추출
print(f"여성 승객 수: {len(females)}")[결과 값]

#30세 미만 여성 승객 선택
young_females = titanic[(titanic['Sex'] == 'female') & (titanic['Age']< 30)]
print(f"30세 미만 여성 승객 수:{len(young_females)}")✅ or 대신에 | (파이프 연산)
✅ and 대신에 &
✅ 글자로 쓰면 오류 남
[결과 값]

# 1등석 또는 2등석 승객
first_second_class = titanic[titanic['Pclass'].isin([1, 2])]
print(f"1, 2등석 승객 수: {len(first_second_class)}")✅isin = where a in (mysql 기준)
[결과 값]

#Pclass의 값의 이름 구하기
titanic['Pclass'].unique()✅ uniqe() = distinct (mysql 기준)
[결과 값]

#결측치(null인 값)가 아닌 데이터 선택
# 나이 정보가 있는 승객만 선택
age_not_null = titanic[titanic['Age'].notna()] #notna = NaN의 줄임말
print(f"나이 정보가 있는 승객 수: {len(age_not_null)}")[결과 값]

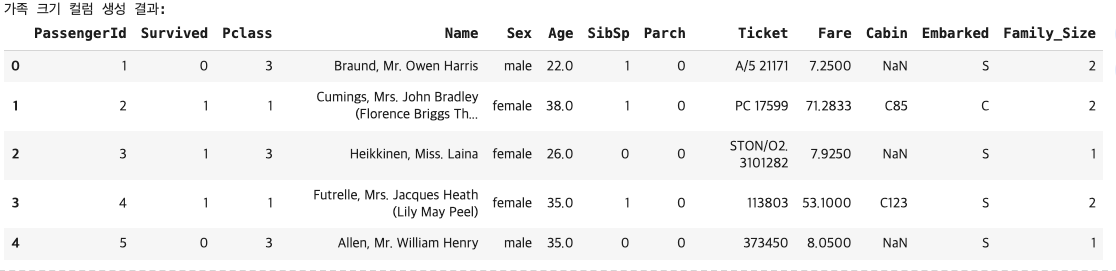
# 가족 크기 = 형제자매 + 부모/자녀 + 본인(1)
#기존 데이터 프레임에 컬럼 추가
titanic['Family_Size'] = titanic['SibSp'] + titanic['Parch'] + 1
# +1은 본인, titanic['Family_Size']는 파생컬럼
print("가족 크기 컬럼 생성 결과:")
titanic.head()[결과 값]
import numpy as np
# 성인/아동 구분
titanic['Is_Adult'] = np.where(titanic['Age'] >= 18, 'Adult', 'Child')
print("성인/아동 분포:")
titanic['Is_Adult'].value_counts()✅ np.where= count(),group by(mysql 기준)
[결과 값]

import numpy as np
# 성인/아동 구분
titanic['Is_Adult'] = np.where(titanic['Age'] >= 18, 'Adult', 'Child')
print("성인/아동 분포:")
titanic #원본데이터 맨 끝에 is_adult라는 컬럼 생성 확인[결과 값]
대표적인 매써드(Method) ⭐️중요⭐️
📌 대표적인 메서드
- 조회 및 탐색: 데이터를 탐색하고, 정보를 얻기 위한 메서드
ex) head() , tail() , describe() , info() 등
-
데이터 선택 및 필터링: 특정 조건에 맞는 데이터를 선택하거나 필터링하기 위한 메서드
ex)loc[],iloc[],query(),filter()등 -
데이터 조작 및 변형: 데이터를 추가, 삭제, 수정하거나 특정 조건에 맞게 변형하는 메서드
ex)append(),drop(),rename(),melt(),pivot()등 -
정렬 및 그룹화: 데이터를 특정 기준에 따라 정렬하거나 그룹화하기위한 메서드
ex)sort_values(),sort_index(),groupby()등 -
결합 및 병합: 두 개 이상의 데이터프레임을 결합하거나 병합하기 위한 메서드
ex)concat(),merge(),join()등 -
결측치 처리: 데이터프레임 내 결측치(누락된 데이터)를 처리하기 위한 메서드
ex)isnull(),notnull(),fillna(),dropna()등 -
통계 및 계산: 데이터의 기술 통계를 계산하거나 데이터에 대한 수학적 연산을 수행하는 메서드
ex)mean(),median(),sum(),std(),corr()등 -
변형 및 재구성: 데이터프레임의 구조를 변형하거나 데이터를 재구성하기 위한 메서드
ex)pivot(),pivot_table(),stack(),unstack()등 -
시계열 데이터 처리: 시계열 데이터를 처리하기 위한 특수 메서드 집합
ex)resample(),asfreq(),rolling()등
