
시작하기 전에 결론부터
쿼리를 개선하고, 페이지네이션을 달아주고, 그걸 개선해서 480 페이지 조회 기준 25초 > 21초 > 5초 > 872ms 로 응답속도를 줄였음.
- 쿼리는 데이터를 왕창 넣고(넣은 뒤에) 다시 확인할 것!
- 있던 페이지네이션도 다시 보자.
- Offset Pagination 은 index only scan 으로!!
- DB 공부 하자!!
0. 배경
현재 회사에서 진행하고 있는 프로젝트의 핵심만 간략히 설명하자면 DB에 모든 로직이 들어있는 2티어 설치형 프로그램을 3티어 웹 버전으로 전환하는 작업이다. DB 테이블은 약 1100여개에, 페이지수는 (기존보다 많이 줄어서) 730여 페이지 정도 된다.
기존 프로그램은 쿼리나 DB 튜닝이 제대로 안 되었는지, 그리고 설치형의 특징인지는 모르겠지만 페이지네이션(Pagination) 처리도 전혀 안 되어 있어 데이터가 좀 많다 싶으면 페이지 로딩이 엄청나게 느렸다. 심한 건 페이지 하나 뜨는데 1~3분 넘게 걸리기도 했다.
절대적으로 페이지네이션이 필요한 상황인데, 테이블 하단에 전체 개수가 노출되는 방향으로 기획이 잡혔고, 데이터가 실시간으로 마구 추가되는 페이지도 아니고, 그 외의 몇몇 이유로 Cursor 페이지네이션 대신 Offset 페이지네이션을 기본으로 채택하게 되었다. (참조 - Offset 기반 Pagination & Cursor 기반 Pagination)
백엔드 프레임워크는 Django에 FastAPI 컨셉을 도입한 Django Ninja란 걸 사용했다.
1. 문제인식
Django Ninja에 Pagination 기능이 있어 리스트로 결과를 반환하는 API엔 전부 @paginate(CustomPagination) 란 데코레이션을 달아 처리하도록 했다.
개발 초기엔 데이터가 다 들어있질 않아 속도가 빠르니 페이지네이션 기능도 잘 동작한다고 생각했는데 이게 웬걸. 기존 데이터를 다 옮겨놓고나니 어떤 페이지는 API 하나의 응답속도가 평균 1분 10초가 나왔다.
또다른 문제는 첫 페이지 뿐 아니라 다음 페이지로 넘어갈 때도 그만큼 걸린다는 것.
두 번째 문제는 캐시를 달아 해결할 수도 있겠지만, 애초에 페이지네이션이 안 되는 게 문제의 근원이라 차근차근 원인을 파악해보니 역시나 @paginate로 넘어가기 전에 쿼리셋이 실행(evaluate) 되고 있었다.
수정을 하려면 Django Ninja 내부 소스를 고쳐야하는 상황이라 Django Ninja의 paginate를 쓰지 않기로 결정했다. 그리고 그 전에 (다른 팀원이 짠) 해당 쿼리도 수정할 여지가 있는지 살펴보았다.
2. 쿼리 튜닝
해당 쿼리는 대충 다음과 같았다.
qs_list = A_Model.obejcts.filter(**filter_condition).select_related().annotate(
ab=Subquery(B_Model.objects.filter(~~),
cd=Subquery(C_Model.objects.filter(~~),
).order_by('d_model__some_col')불필요해보이는 select_related() 가 들어있는데 지우기 전에 qs_list.explain() 과 query로 해당 쿼리셋을 살펴보고, Postman 으로 실제 응답시간을 체크해보았다.
참고로 이전까진 자동으로 생성되는 스웨거가 너무 편해 브라우저에서 API 테스트를 다 했지만, 해당 테이블은 row 하나당 데이터도 많아, 고작 100개로 (전체 데이터는 약 60000개) 잘라와도 브라우저 메모리가 full이 나는지 응답시간과 관계없이 프리징이 나 Postman으로 테스트를 했다. Postman이 응답시간 체크도 간편하고.
A. 기존: select_related()
(불필요해 보이는) select_related() 가 붙어 있는 버전이다.
- explain: cost=0.86..1034043.89
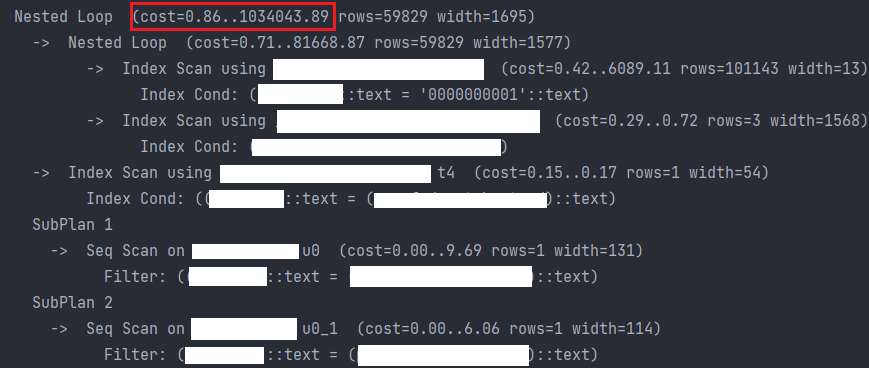
- query
SELECT *
FROM A_Table
INNER JOIN D_Table
INNER JOIN E_Table
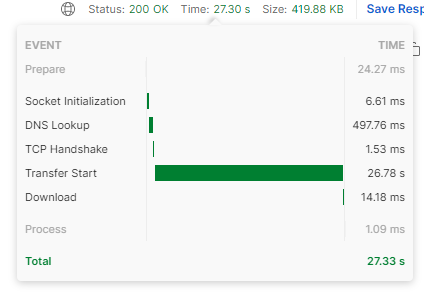
ORDER BY D_Tabel.some_col- 응답속도 : 25.86s (5회 평균)
| 1 | 2 | 3 | 4 | 5 | 평균 |
|---|---|---|---|---|---|
| 27.33s | 29.56s | 25.26s | 22.97s | 23.70s | 25.76s |
B. 변경: no select_related()
쿼리에서 select_related() 만 지웠다.
- explain: cost=0.71..1023975.62
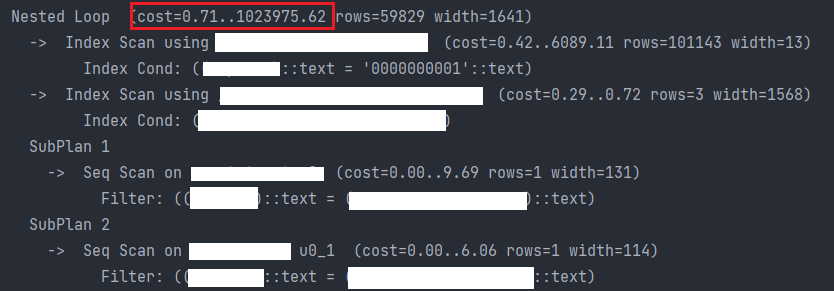
- query
SELECT *
FROM A_Table
INNER JOIN D_Table
ORDER BY D_Tabel.some_col- 응답속도 : 21.86s (5회 평균)
| 1 | 2 | 3 | 4 | 5 | 평균 |
|---|---|---|---|---|---|
| 23.70s | 21.84s | 21.54s | 21.39s | 20.83s | 21.86s |
A, B 비교
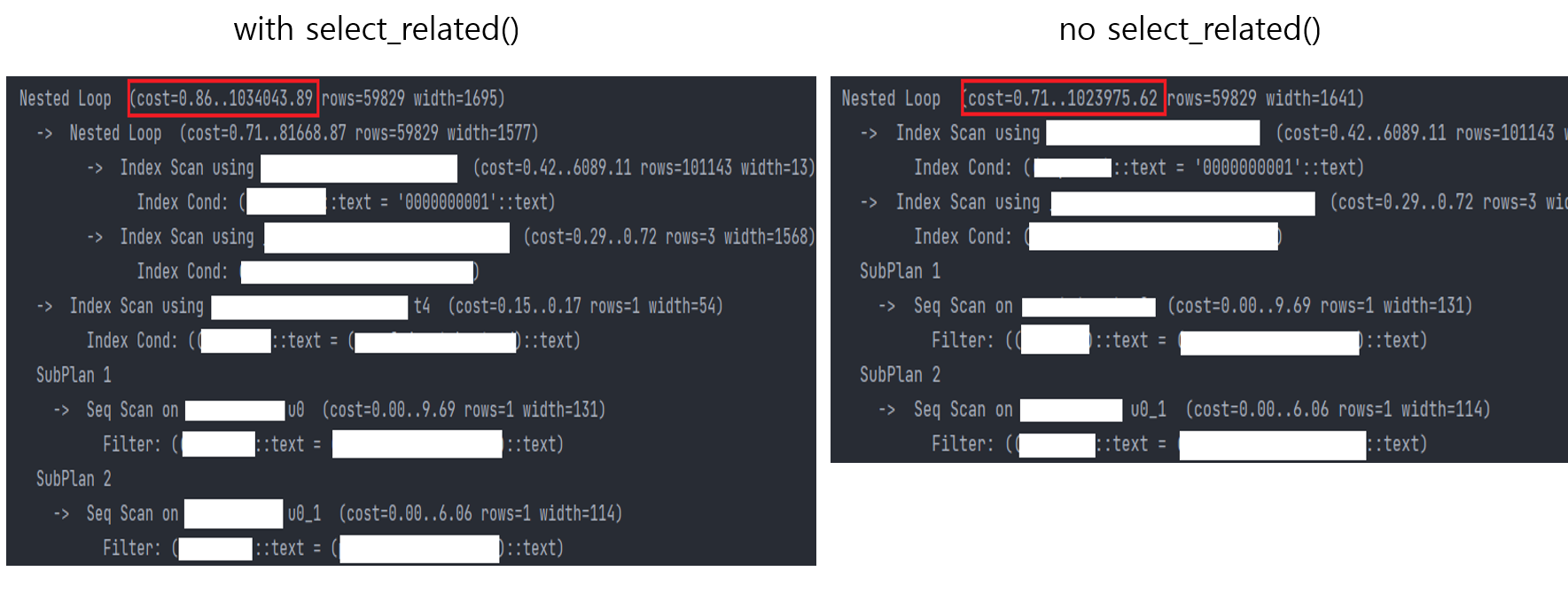
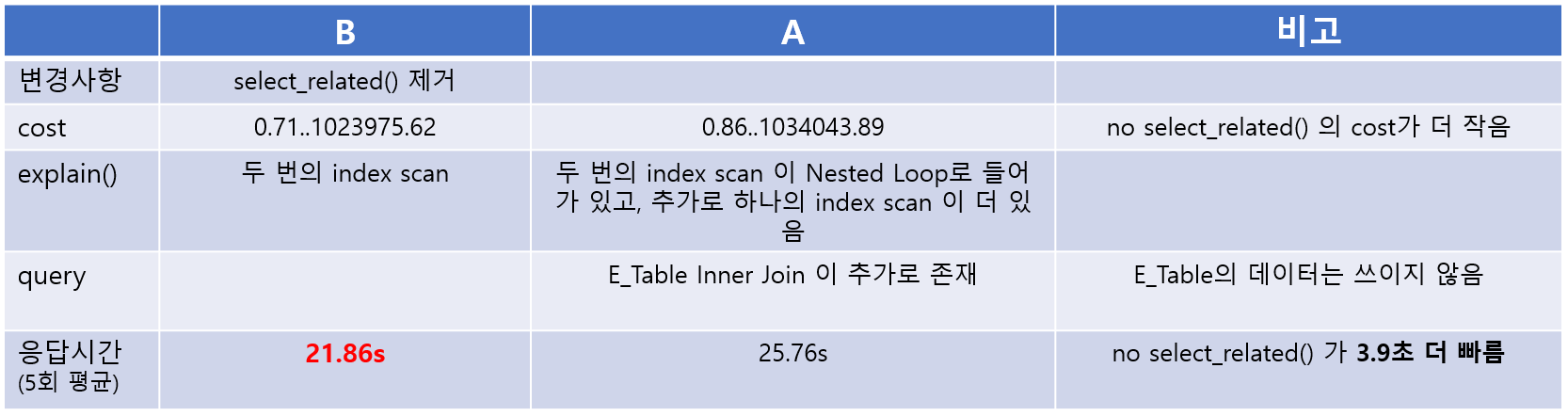
결론적으로 불필요한 쿼리를 제거함으로써 응답속도를 3.9초 더 빠르게 향상시킬 수 있었다.
3. Django Paginator - Offset Pagination 적용
쿼리 수정을 통해 약 4초를 향상시켰지만 여전히 API 한 번에 21초나 걸리면 답이 없다.
기존엔 함수를 paginate로 감싸는 방식이었지만 없애고 함수 내부에 Django Paginator 를 달아주는 걸로 변경했다.
B. 기존: paginate() & no select_related()
@paginate(CustomPaginator)
def list_api() -> QuerySet:
...
return qs_listC. 변경: Django Paginator
def list_api() -> dict: # 스키마를 맞추기 위해 dict로 반환
...
paginator = Paginator(qs_list, page_size) # Django Paginator
page_obj = paginator.get_page(page)
qs_list_of_page = page_obj.object_list
print(qs_list_of_page.explain()) # explain() 출력
result = {
....
}
return result- explain: cost=0.71..1712.21
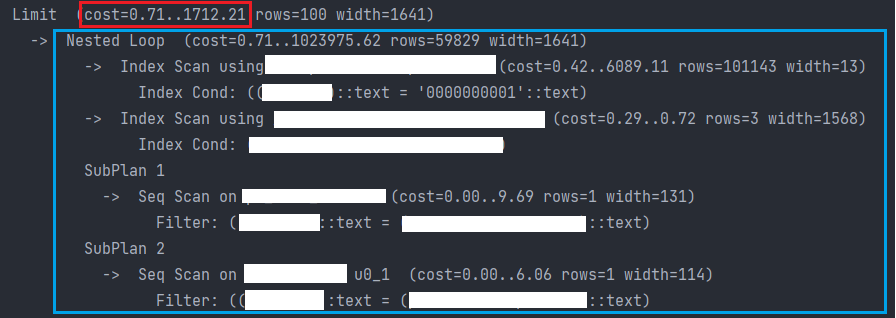
explain() 출력을 보면, 파란색 부분은 (당연하게도) B와 동일하고, B를 Limit로 슬라이싱했다는 걸 알 수 있다.
- 응답속도 : 562.966ms (5회 평균)
| 1 | 2 | 3 | 4 | 5 | 평균 |
|---|---|---|---|---|---|
| 445.7ms | 780.21ms | 462.32ms | 580.43ms | 546.17ms | 562.966ms |
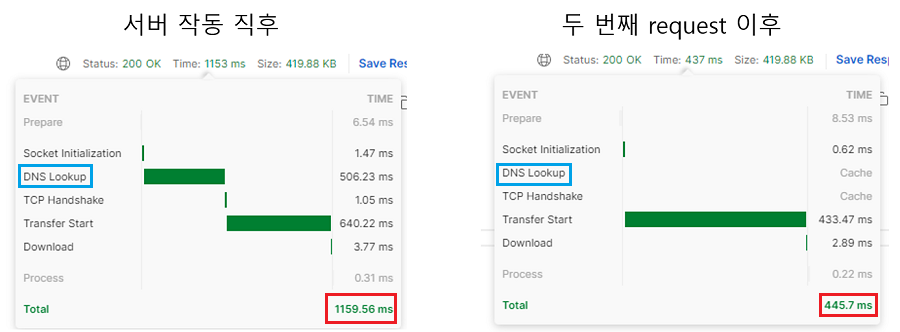
응답속도는 서버를 새로 띄운 뒤 측정을 하면 DNS(Domain Name Sever) 찾는 데 시간이 걸린다. A, B에선 이후에 걸린 시간이 워낙 길어 막대로는 표시가 되지도 않았지만, 속도가 1초 대로 떨어지면 그것도 영향이 크다. 따라서 서버 띄운 직후의 request는 제외하고 측정하였다.
B, C 비교

단지 limit 만 더 했을 뿐인데 응답속도가 21.3초(약 97.4%) 가량 줄어들어 단위가 s 에서 ms 으로 달라졌다. 충분히 만족스러운 개선이긴한데... 이걸로 충분할까?
4. OffsetPagination의 한계
C 방식의 sql 쿼리를 보면 다음과 같다. B에 LIMIT만 추가되었다. Page는 1이다. 이걸 C-1이라 하자.
SELECT *
FROM A_Table
INNER JOIN D_Table
ORDER BY D_Tabel.some_col
LIMIT 100Offset 그러니까 Page를 480으로 늘리면 쿼리가 다음과 같아진다. 이걸 이제 C-480이라 하자.
SELECT *
FROM A_Table
INNER JOIN D_Table
ORDER BY D_Tabel.some_col
LIMIT 100 OFFSET 47900그렇다면 응답속도는 얼마나 차이가 날까?
C-480: 480 페이지
C에서 페이지(offset)만 늘려보았다.
-
explain: cost=819810.47..821421.98 - cost만 바뀌고 나머지는 동일

-
응답속도: 5.084s
| 1 | 2 | 3 | 4 | 5 | 평균 |
|---|---|---|---|---|---|
| 5.48s | 4.87s | 4.98s | 5.04s | 5.05s | 5.084s |
C-1, C-480 비교

응답속도 단위가 ms에서 다시 s로 바뀌었다. cost는 819810.47..821421.98 로 0.71에서 어마어마하게 늘어났는데, ..를 사이에 두고 앞 뒤로는 크게 차이가 나지 않는다.
5. cost란?
이 시점에서 explain에서 출력되는 cost를 어떻게 이해해야 하는지 알아보자.
이 블로그에 따르면 cost는 데이터베이스의 통계(statistics) 자료를 이용해 계산된다고 한다.
cost=0.71..1712.21 같은 게 어떤 의미인지 이해하는 게 중요한데, 위의 블로그에 따르면 .. 의 왼쪽 0.71은 해당 쿼리의 첫 번째 row를 가져오는 비용이고, 오른쪽 1712.21은 전체 rows를 가져오는 데 드는 비용이라고 한다.
그래서 B의 cost는 0.71..1023975.62 이고, 그걸 그대로 100번째 rows 까지만 슬라이싱한 쿼리인 C-1의 cost는 0.71..1712.21으로, 첫 번째 row를 가져오는 비용은 동일한데 나머지 총량이 달라지니 두 번째 비용이 크게 차이나는 것이다.
하지만 cost가 응답속도에 동일한 비율로 비례하는 것은 아니다.
C-1와 C-480의 마지막 cost 차이는 1712.21 대 821421.98로 C-480의 cost가 약 480배 정도 더 큰데, 응답속도는 고작(?) 10배 정도 밖에 차이가 나질 않는다.
6. D - index only scan 적용
C-480의 응답시간이 10배나 되는 이유는 Offset 방식의 경우 데이터 블록에 접근한 후 그 Row를 버리기 때문이라고 한다.
바로 데이터 블록에 접근한 후에 그 Row들을 버리기 때문이다. 따라서 데이터블록에 접근하는 것을 최소화한다면 성능 개선을 꾀할 수 있다. 인덱스가 걸린 것들만 select 해 오면 되는 것이다. 이렇게 select 하는 것들까지 모두 들어가 있는 Index를
Covering Index라 부르고, 이 커버링 인덱스를 이용하는 스캔을Index Only Scan이라 부른다.
방법은 간단한데, 아래처럼 해당 구간의 pk만 따로 빼내 다시 한 번 filter를 걸어주는 것이다.
...
limit = (page-1) * page_size
qs_list1 = qs_list[limit: limit + page_size] # 쿼리셋 offset
qs_list_of_page = qs_list.filter(pk__in=qs_list1) # 위의 쿼리셋의 인덱스만 filtering
...sql 쿼리를 보면 더 이해가 쉽다.(아마도)
# C-480
SELECT *
FROM A_Table a
ORDER BY a.some_col
LIMIT 100 OFFSET 47900;
# D-480
SELECT *
FROM A_Table a
INNER JOIN
(SELECT aa.id
FROM A_Table aa
LIMIT 100 OFFSET 47900
) AS b -- b는 C-480과 동일한데 id만 select한 것
ON b.id = p.id
ORDER BY a.some_col
LIMIT 100;D-1
-
explain: cost=983.98..2560.23 - HashAggregate 같은 게 더 생겼다.
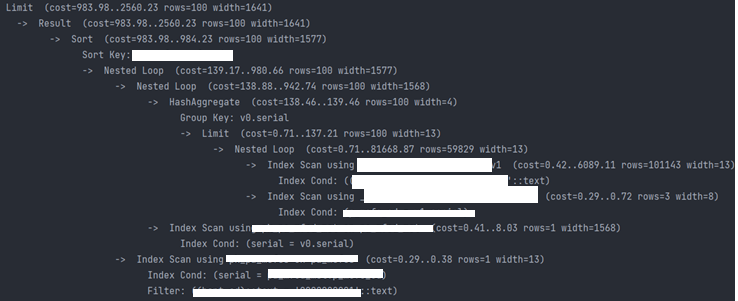
-
응답속도 : 578.06ms
| 1 | 2 | 3 | 4 | 5 | 평균 |
|---|---|---|---|---|---|
| 554.23ms | 598.82ms | 572.45ms | 508.89ms | 655.91ms | 578.06ms |
D-480
- explain: cost=20347.69..21923.94
- 응답속도: 872.49ms
| 1 | 2 | 3 | 4 | 5 | 평균 |
|---|---|---|---|---|---|
| 806.62ms | 921.87ms | 931.37ms | 868.22ms | 834.36ms | 872.488ms |
C-1, C-480, D-1, D-480 비교
- C-1과 D-1을 비교해보면, D-1이 비용과 응답속도가 조금 더 크지만 무의미한 수준으로 미세하다.

- 반면, Offset 47900 (page 480)인 쪽은 둘의 차이가 극명하다. 커버링 인덱스를 이용한 Index Only Scan 방식을 적용한 D-480의 경우 그냥 offset만 한 것에 비해 4.2초 정도 빨라졌고, 1페이지를 조회한 것과 비교해도 사람이 거의 느끼기 힘들 정도의 차이(약 300ms) 정도 밖에 나질 않는다.

7. 추가 - 캐시
앞서 말했듯 기획상 전체 카운팅이 들어갈 수 밖에 없는 상황이다. C-1, D-1으로 테스트를 해보니 카운팅을 뺐을 때 시간이 거의 절반(560ms > 280ms)으로 줄어들었다. 물론 미미한 수준이지만, 데이터가 늘어날 수록 전체 카운팅에 걸리는 시간이 많아질 것이다.
데이터가 실시간으로 생성되거나, 전체 개수의 정합성이 매우 중요한 상황은 아니기 때문에 최초 조회시만 카운팅을 하거나 캐싱을 하는 식으로 더 발전시킬 여지가 있을 것 같다.
회고
솔직히 DB를 이론적으로 깊이 공부한 적이 아직 없다. 그런 상황에서 개선법을 고민하고 찾아가며 응답속도를 25초에서 850ms으로 줄여보니 그 쾌감이 장난이 아니다.
이 일(?) 며칠 후에 또 느린 쿼리를 발견해 속도를 개선시킨 경험이 이어졌는데, 이런 경험을 할 수록 DB 공부를 따로 깊이 해야겠다는 생각이 커진다. (일단 CKA부터 따고!!)
