
성공적인 전환...but
CTO 님으로부터 위와 같은 평을 받으며 (트이타 링크 - 개발계 인플루언서시라 계정을 굳이 가리진 않았...) 기존 배포 시스템을 성공적으로 (우리 입장에서) 업그레이드했다.
그런데 2~3개월 뒤 아주 거한 장애를 맞이하게 된다. 바로 3주년 프로모션 장애.
예상을 훨씬 뛰어넘은 트래픽이기도 했지만, 트래픽이 늘어나더라도 서버 증설 등(쉽게 빠르게 할 수 있도록 세팅은 해놓은 상태)으로 사후 대처를 할 수 있을거라 생각했는데 모든 대처가 상황을 더 악화시키는 상황만 목도하며, 원인도 제대로 못 밝힌 채 새벽 4시까지 느려진 사이트를 붙잡고 있던 기억이 아직도 생생하다. (gunicorn을 uwsgi 로 바꿨더니 그나마 좀 버티는 듯하긴 했음)
당시에 너무 이상해서 혼란이 왔던 건, CPU, 메모리, 캐시, DB 커넥션 등 모니터링할 수 있는 모든 수치가 정상이었단 것.
(참고로 배포 시스템 전환기는 블로그로는 마무리를 못 했는데, 파이웹 심포지움 2024에서 발표는 해버렸다. 자체적으로 녹화는 했으니 보실 분은 여기로.)
조치는 허무하리만큼 단순
장애 분석 및 재발 방지를 위해 Locust 로 장애 재연 > 분석 > 조치 순으로 작업을 했었다.
사실 부하테스트를 통해 gunicorn worker, thread, class 최적화를 진행했었는데, 그 때 서버를 늘려서 부하가 해소되는지에 대한 테스트는 안 했던 게 지나고보니 너무 아쉬웠다. 그리고 장애가 오는(느려지는) 시점의 CPU 최대치가 너무 낮았던 것도 단서 중 하나였을텐데 그걸 놓친 것도 아쉬웠고, 캐쉬 걸린 요청 아닌 요청 등을 구분하면서 부하테스트를 하진 않았기에 생각해보면 제대로 된 테스트가 아니었다.
아무튼,
결론적으로 django settings 에 CONN_MAX_AGE, CONN_HEALTH_CHECK 를 설정함으로써 재발 방지 조치는 할 수 있었는데, DB 커넥션 풀이 해결책이란 걸 쉽게 밝혀내지 못한 이유가 여럿 있었다.
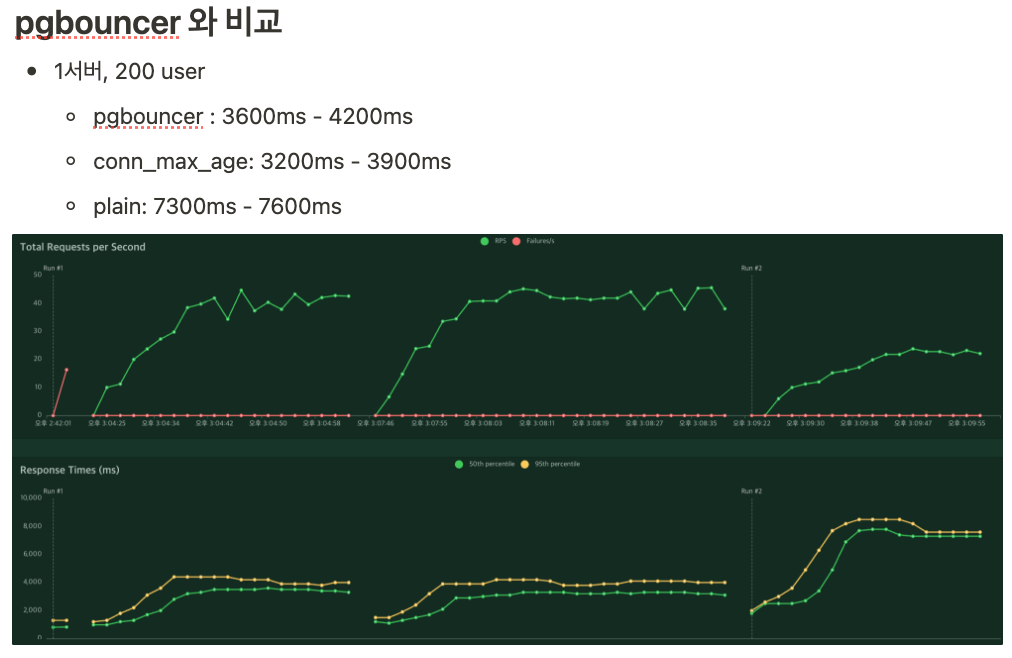
(그 와중에 pgbouncer와 비교하니 미묘하게 성능도 좋아서, 세팅이 쉬운 CONN_MAX_AGE 로 낙점)
장애 분석
DB 커넥션 풀?
DB 커넥션 풀을 의심하지 않았던 대표적인 이유는 RDS max connections는 5000으로 설정이 되어있는데, 장애 상황에서 db 커넥션 자체는 5000에 한참 못 미치는 수준에서 안정적으로 모니터링이 되었다는 것.
그리고 장애 당시에 알아낸 것 중 하나는 인스턴스 내부에서 shell_plus 로 쿼리를 해보면 전혀 문제가 없었고, 캐쉬된 요청도 느려졌기 때문에 DB 나 redis 캐쉬의 병목을 아닐 것 같다는 주장에 힘을 실어주었다. (사실 장애 당시에 시니어 한 분이 DB 커넥션 풀이 문제는 아닐까 의문을 제기했었다.)
(하지만 직접적인 원인은 아니지만 해결책은 될 수 있다는 게 이 일의 어렵고도 재밌는 부분인 것 같다.)
TCP 병목?
추상화는 표현을 매우 간결하게 만들어준다...
하지만 모든 추상화는 눈물을 흘리며 양파 껍질을 벗겨서 무엇이 어떻게 돌아가는지 확인해야 하는 때가 온다. 보통은 뭔가가 잘못되었을 때다.
<release의 모든 것 p.78>
때문에 외부 네트워크 대역폭보다는 내부 TCP 통신의 병목이 문제일 것 같다는 가설을 세우고 장애 재연을 하며 ESTABLISHED 상태인 커넥션이 많다(1000 내외)는 것까지는 밝혀냈다. 이 블로그 등을 참조하여, 커널 파라미터들을 바꿔가며 정확한 원인을 찾아보려 했지만 실패했다.
그 와중에 널널한 개발자 님의 이해하면 인생이 바뀌는 TCP 송/수신 원리를 봤던 게 생각나, 패킷을 까봐야하겠다는 마음을 먹고 tshark 를 인스턴스에 설치 후 장애 재연 뒤 로그를 다운로드 받아서 wireshark 로 패킷을 하나하나 분석해봤다.
- request <-> 임시 포트 <-> Next js
- Next.js <-> 임시 포트 <-> gunicorn
- gunicorn <-> db
분석을 해야할 지점을 위의 세 가지로 정리했는데, 3번은 이미 curl 로 내부에서 db와의 통신은 빠르다는 걸 확인했기 때문에, 1,2번에 집중했다.
TCP 3-way Handshake:
시작: 21814 - 7.855262401초
종료: 21816 - 7.855276112초
걸린 시간: 7.855276112초 - 7.855262401초 = 0.000013711초
HTTP 요청 전송:
시작: 22737 - 7.963234828초
걸린 시간: 7.963234828초 - 7.855276112초 = 0.107958716초 (이전 단계 종료부터 해당 단계 시작까지)
HTTP 응답 수신:
시작: 24030 - 8.171421237초
종료: 24032 - 8.171448965초
걸린 시간: 8.171448965초 - 7.963234828초 = 0.208214137초 (HTTP 요청 전송부터 HTTP 응답 수신까지)
TCP 연결 종료:
시작: 24034 - 8.171755075초
종료: 25543 - 8.998216582초
걸린 시간: 8.998216582초 - 8.171755075초 = 0.826461507초눈이 침침해질 때 쯤 Next.js 와 gunicorn 사이의 TCP 통신에서 연결 종료에 비정상적으로 시간이 오래 걸린다는 걸 발견했다.
드디어 병목 지점을 특정하는 데 성공!
분석
종합하면 (그래서 더 복잡한데)
- Next.js 은 SSR 로 인한 API 요청이 많음 (SSR의 비효율)
- 요청이 많을 때 Next.js 서버와 gunicorn 사이의 커넥션이 늦게 종료되는 문제가 있음. (TCP 병목)
- 캐시가 있으면 CPU를 적게 써서, CPU 병목에 도달하기 전에 TCP 병목을 만나는 것으로 보임.
- 따라서 오토 스케일링 기준을 CPU만 보는 건 위험할 수도 있음. (응답 시간도 봐야.)
- 다만, DB 커넥션 풀링이 되어 있으면 TCP 병목을 완화해줌.
- 이로 인해 TCP 병목을 만나기 전에 CPU 병목이 나타날 것임.
- 따라서 DB 커넥션이 문제의 직접적인 원인은 아니지만 해결책이 될 수 있음.
추가적으로 다음과 같은 사항을 발견했다.
- DB 커넥션 풀링이 안 되어 있고, TCP 병목이 일어난 시점에는 서버를 늘리면 상황을 더 악화시킴.
- DB 커넥션 풀링이 된 상태에서 CPU 병목은 서버를 늘리는 것으로 상황을 완화시킬 수 있음.
- 하지만 병목 상황에서 서버를 늘리면 로드 밸런싱이 고르게 되질 않음.
- 때문에 미리 서버를 늘려놓는 게 최선
후기
이렇게 큰 장애를 겪고, 재연 및 분석을 하기 위해 집요하게 매달리고 나니 단기간에 많이 배우고 성장했다는 느낌이 들었다.
최근에 시니어 한 분이 개발자로 밥 벌어 먹고 살면서 패킷 분석할 일은 없을 줄 알았다 고 하셨는데 그 당시엔 단순히 답을 알고 싶어 파고 들다보니 누가 가르쳐 준 것도 아닌데 패킷 까볼 생각이 들었고 방법을 찾아 실천에 옮겼더랬다.
장애로 인한 손실을 자양분으로 삼았다는 사실에 회사에 미안한 마음이 있지만 소 잃은 뒤엔 꼭 외양간을 고치고야 마는 게 개발자의 중요한 덕목이니까.
