The Dialogue Dodecathlon: Open-Domain Knowledge and Image Grounded Conversational Agents
chatbot
요약
- 2020 ACL, Facebook ai
- 오픈도매인 챗봇에 이미지, 추론 능력도 포함시키는 멀티태스킹 러닝
- 본 논문에서는 대화 에이젼트가 personality와 empathy를 가지고 아래와 같은 능력이 있는지 평가하는 12가지 태스크를 포함하고 있는 데이터셋 소개, 학습, 평가
Think point
- 향후 챗봇 능력을 종합적으로 평가할 수 있는 데이터셋의 기준을 세움
- 챗봇이 가지고 있어야하는 능력들과 활용가능한 대표적인 데이터셋들을 정리해준 논문
- 향후 대화모델 학습할 때 참고할만한 테스트 결과들
Introduction
- 대화에이젼트가 이런 능력들을 한꺼번에 갖게하는 테스크는 없으나 별개의 테스크로는 존재함
- 여러 테스크들을 합쳐서 single challenge로 다양한 능력들을 갖게함
- 기존에는 일반 텍스트들로 미리 학습시키는 접근법들을 사용했지만, 12개의 테스크로 학습시키는 방법이 더 효과적임을 보임
The dodecaDialogue Task
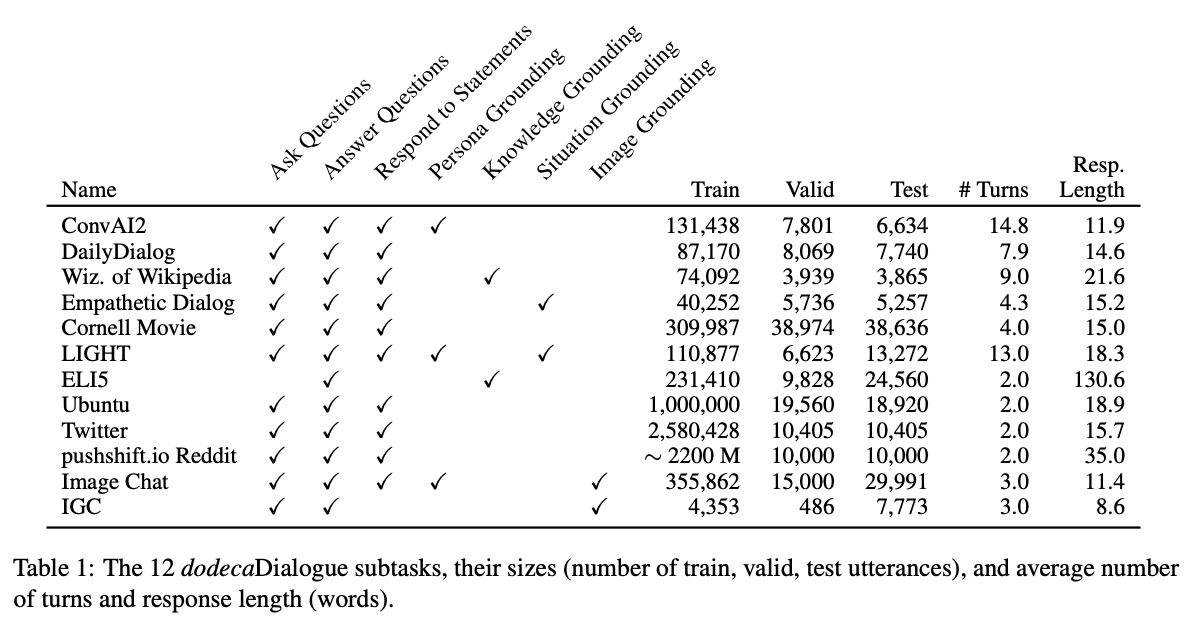
논문에서 대화 모델이 가져야하는 능력들을 아래와 같이 정의하고 이런 능력을 갖고있는 12개의 데이터셋을 채택함
- 페르소나 - get to know about you (ConvAI2)
- 토픽에 대한 토의 - discuss everyday topics (DailyDialog, Reddit, Twitter, Cornell Movie)
- 외부지식활용 - speak knowledgeably at depth (Wizard of Wikipedia, Ubuntu)
- 질의응답 - answer questions on topics (ELI5)
- 상황 기반 대화 - handle various situation and demonstrate empathy (Empathetic Dialog, LIGHT)
- 이미지활용 대화 - discuss images (Image Chat, IGC)
데이터셋이 목표하는 기능 외에도 매력적인 챗봇을 만들기 위해 고려되어야할 특징들, 1) 실제 크롤링 데이터 2) 크라우드소서들이 매력적이도록 유도되어 만들어졌는가를 기준으로 선택되었음.
Models
BERT baseline
BERT에 standard auto-regressive loss를 적용해 generative baseline으로 삼았음
(Image feature는 다루지 못함)
Image + Seq2Seq
- 추가적으로 pretrained ResNet model로 image features 더함
- ResNeXt-IG-3.5B model, a ResNeXt 32x 48d architecture
- 이를 Transformer encoder output 마지막(linear projection이후)에 더해 디코더에 넘겨줌
- 학습중에는 Transformer만 학습됨
- The text transformer is fine-tuned with a standard auto-regressive negative log-likelihood (NLL) loss
Experiements
Task Training
선택한 테스크들이 모두 올라와있는 Parlai 프레임워크 활용해서 학습
Pre-training
Image+Seq2Seq 모듈중 Seq2Seq모듈만 Reddit, Twitter 데이터셋으로 pre-training시킴.
- 레딧
- full-thread 를 읽고 마지막 comment를 생성해내는 작업
- URL포함하거나 5 characters 아래는 제거
- Comments는 1024 BPE 넘는 경우 truncated됨
- batch size of 3072
- 약 3M updates using a learning rate of 5e-4, and an inverse square root scheduler
- 64 * NVIDIA V100s 2주 학습
Preliminary Study
12개 다해보기 전에 작게 테스트 먼저 진행하기 위해 Reddit, ConvAI2, Wizard of Wikipedia and Empathetic Dialogues 먼저 우선 파인튜닝함.
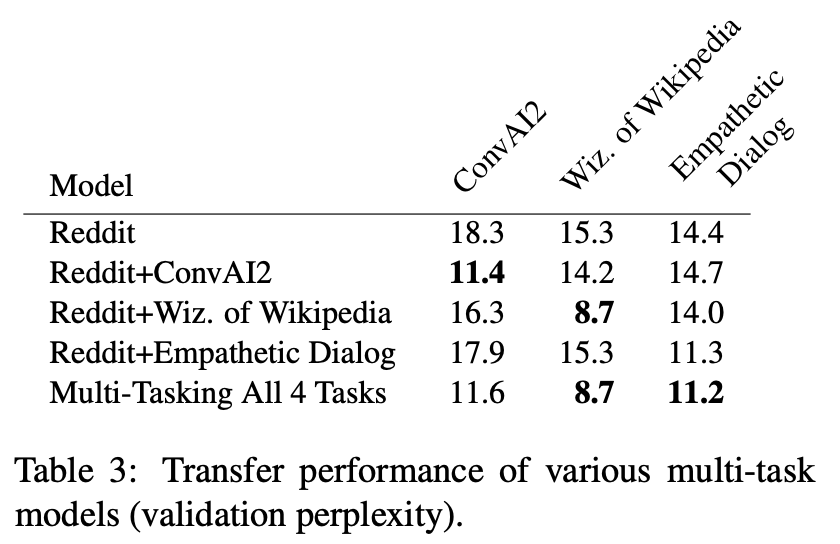
- Reddit 혼자 학습시킨 것도 효과적임
- 그러나 Reddit pre-training + 테스크별 파인튜닝이 각 테스크에서 보이는 성능보다는 아님
- 4가지 Task를 전체 학습시킨 모델이 평균적으로 가장 좋은 성능을 보임
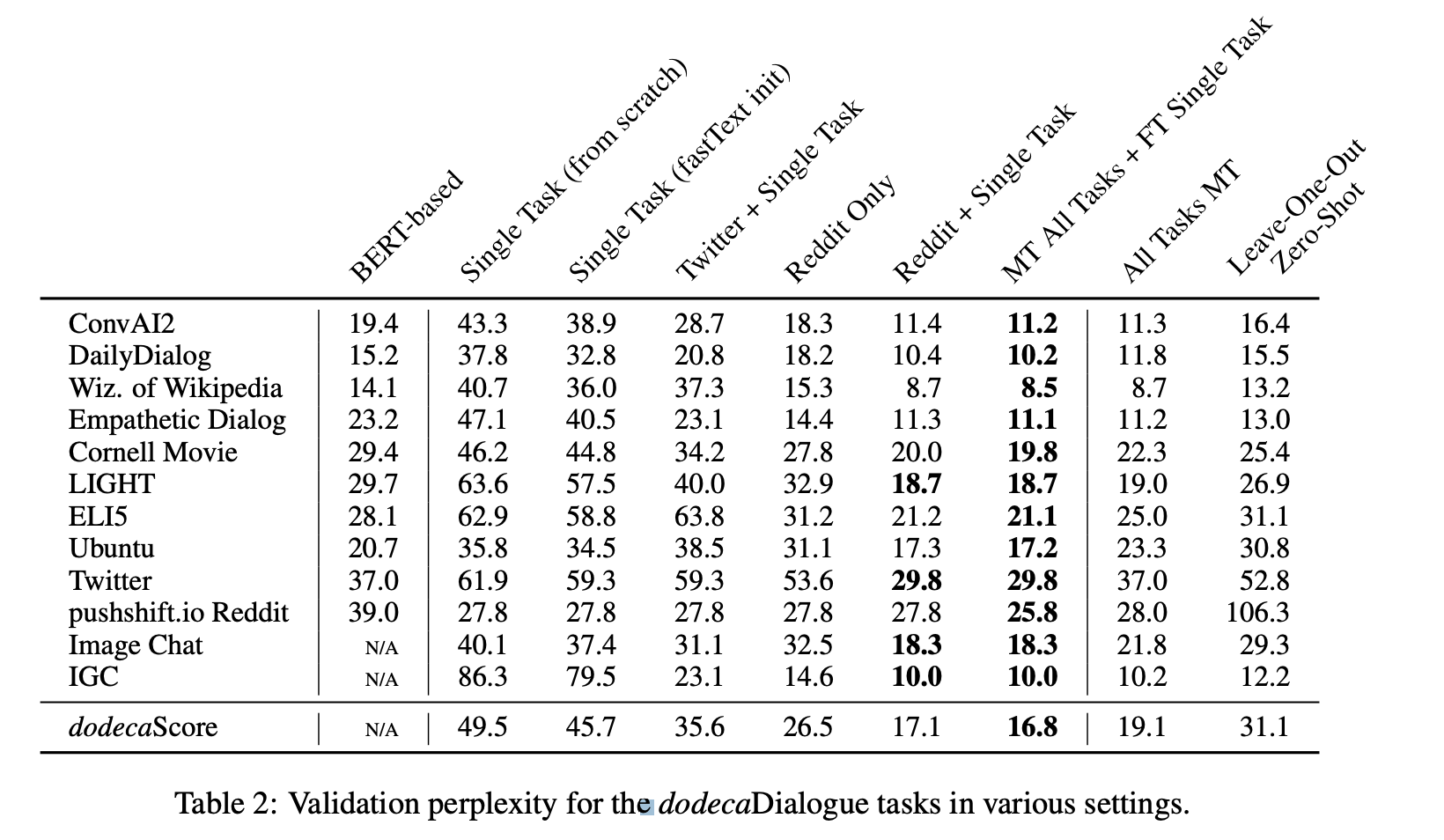
*dodecaScore (last row) that is the mean perplexity over all 12 tasks
Comparison of Pre-training + Fine-tuning
strategies
Reddit pre-training에 각 single task 파인튜닝 시켜 성능 테스트함.
- 레딧으로 pre-training한 모델이 다른 pre-training 모델보다 좋음 dodecaScore가 BERT-based, Single Task, Twitter + Single Task들보다 좋음
- "대화"를 미리 학습하기에 Reddit만한게 없다라고 생각할 수 있음
- 특히, Reddit Only 모델이 Single Task (from scratch)들보다 좋은걸 알 수 있는데 양이 적은 IGC, Wiz. of Wikipedia and Empathetic Dialog 테스크에서 두드러짐
Multi-Task Results (All Tasks MT)
- 12개 테스크에 평균적으로 가장 높은 성능보이는 모델을 베스트모델로 취급함.
- Reddit Only로 학습시키는 것보다 성능이 좋음 (당연함)
- 특별한 향상은 찾아볼 수 없었음
Multi-Task followed by FineTuning (MT All Tasks + FT Single Task)
- multi-task 방법으로 pre-training하고 각 single task에 fine-tuning함
- 모든 실험 방식중에 가장 성능이 높았지만 Reddit + FT single Task에 비교해보면 큰 차이는 없음
Task Up-Weighting
멀티테스크 트레이닝할 때 task up-weighting 기법 적용하면 특정 single-task 성능 높이는데 도움됨.
Zero-Shot Performance
- target task 제회하고 학습시킨 모델을 target task에 적용했을 때 성능
- dodecaScore is 31.1 ... Reddit에 적용햇을 때 PPL이 106나와서 점수가 매우 낮음. (아무래도 굉장히 큰 데이터라...)
Image and Knowledge Grounding
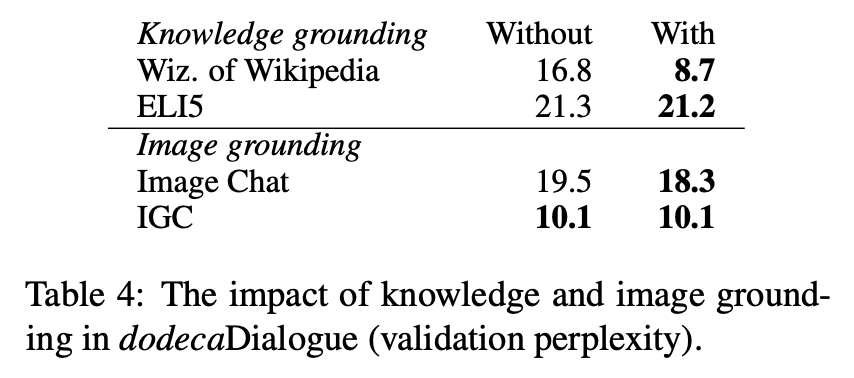
- 외부지식 활용, 이미지 활용이 모델 성능 향상에 얼마나 도움되는지 테스트하기위해 특정 테스크가 있을 때 없을 때 얼마나 차이나는지 비교해봄
- (WOW는 큰 차이 나는거 같음, Image는 거의 효과 없음... 그냥 빼도 괜찮을거 같은데...)
Comparison to Existing Systems
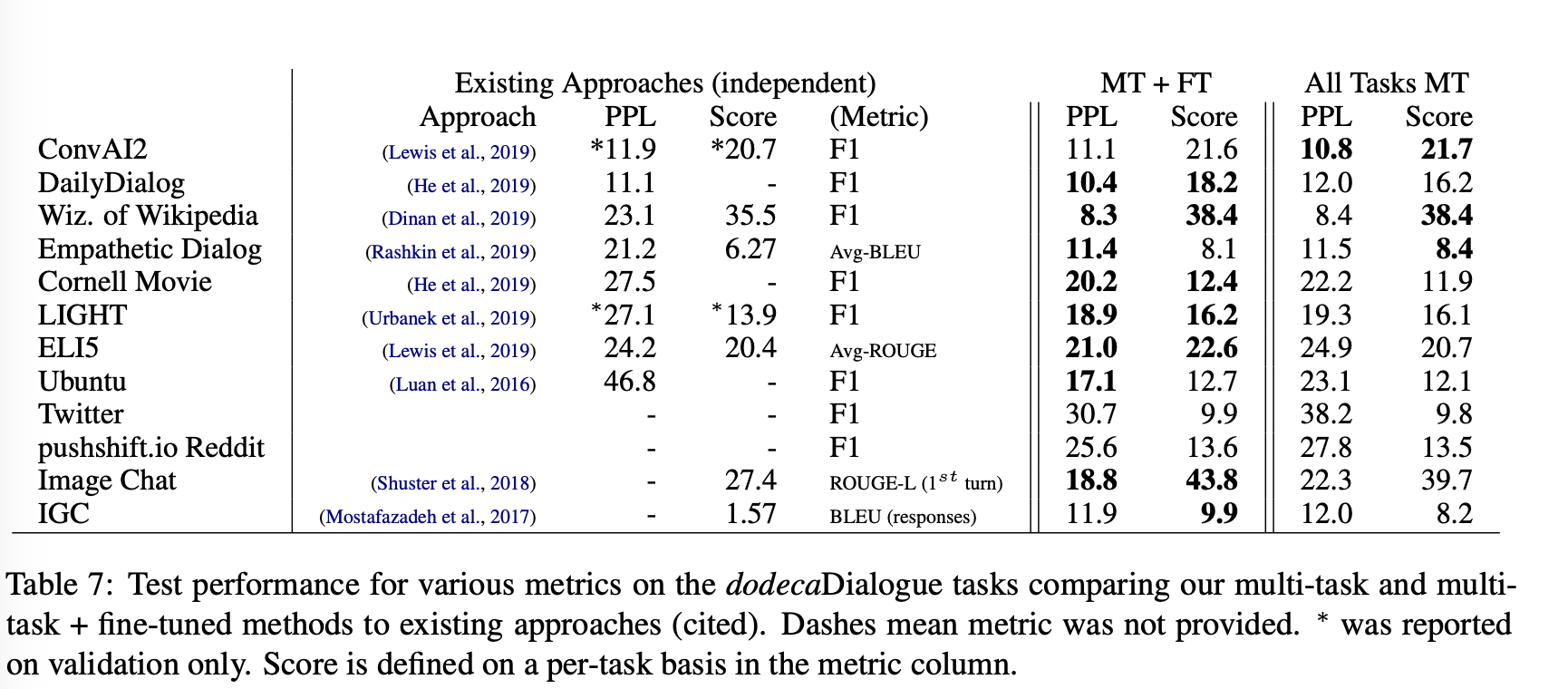
(각 데이터셋의 Score는 perplexity (PPL), BLEU, ROUGE(-1,-2 and -L)
and F1 다양한 메트릭스 중 target task에 맞는 메트릭스 방법이 선택됨)
