전편 Dialogue Response Ranking Training with Large-Scale Human Feedback Data 논문요약 (1) 에 이어서 계속 포스팅합니다 :)
The DialogRPT: Dialog Ranking Pretrained Transformers
각 샘플에 feedback 예측 점수를 매기는 대신 샘플쌍에 대해 더 적절한 응답을 분류하는 테스크(A Contrastive Learning approach)로 아래 규칙을 따른다.
The model is trained to predict a higher score for the positive sample r+ (i.e. the response with more feedback) compared to the negative sample r−.
1) only comparing replies of the same context
2) the sequence of two replies, r+ and r− must have been created within a brief time window (no more than one hour)
3) the feedback score of r+ must exceed that of r − by a specified threshold in order to make the label less noisy.
4) if a reply has more downvotes than upvotes, it will not be considered as a positive sample, but can be used as a negative sample
Training objective
DialogRPT의 결과값을 Sigmoid 태워 positive sample의 값을 maximize하고 negative sample의 값을 minimize하는 것이 목표

humain-like, preferred human 동시 평가
한 샘플에 대해 두가지를 동시에 평가하기 위해 위의 preferred human 값과 human-like 예측 분류 모델을 함께 사용함.

실험결과
DialogRPT 성능
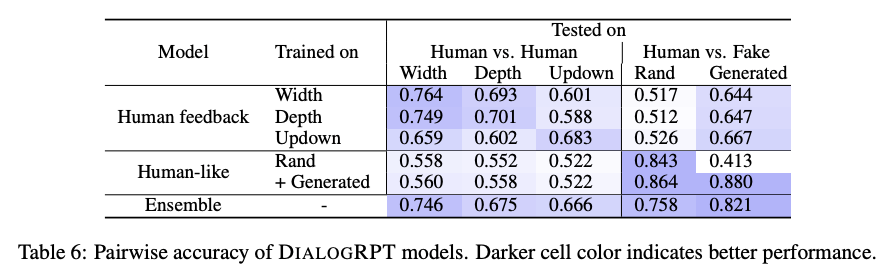
단어 분석

- 표 4에서 볼 수 있듯이 응답 또는 찬성 응답이 적은 응답은 덜 만족하는 경향이 있음 (예 : lol, awesome, wow, nice).
- 반대로 더 많은 피드백을 유도하는 댓글은 일반적으로 성격이 다른데, 예를 들어 질문 (?, 왜, 어떻게, 무엇을, 누가 표시)은 종종 더 긴 대화 (더 깊은 깊이)로 이어짐. 광범위한 청중을 대상으로하는 댓글은 특정 사람들을 대상으로 한 댓글보다 더 직접적인 응답 (더 큰 폭)을받는 경향이 있음.
예제 I love NLP! 로 테스트했을 때 결과 분석

- 상대적으로 단조로운 응답(Me too!)은 세 가지 피드백 측정 모두에서 가장 낮은 점수를 얻으며
- 합의에 대한 타당성이 제공되는 응답 B에 대해 더 높은 점수를 얻는다.
- 응답 C는 NLP가 작동하는 방식에 대한 토론을 유발하기 때문에 가장 높은 Depth 점수를 얻는다.
- 반대로, 응답 D는 더 적은 턴으로 응답 할 수 있지만 잠재적으로 많은 유효한 응답으로 응답 할 수 있으며 이는 높은 Width 점수를 받은 것을 설명한다.
- 마지막으로 응답 E는 가장 높은 Updown 점수를받는데, 아마도 모델이 제공하는 유용한 리소스 포인터 (교과서)에 대한 감사를 표현하기 위해 많은 사람들이이를 찬성 할 것이라고 예측했기 때문일 것임.
응답 E에서 단어 (URL)를 제거하면 점수가 약간 낮아져 모델이 웹 링크가 포함 된 게시물에 민감하지 않음을 나타낸다.
humain-like()는 깊이, 넓이보다 중요
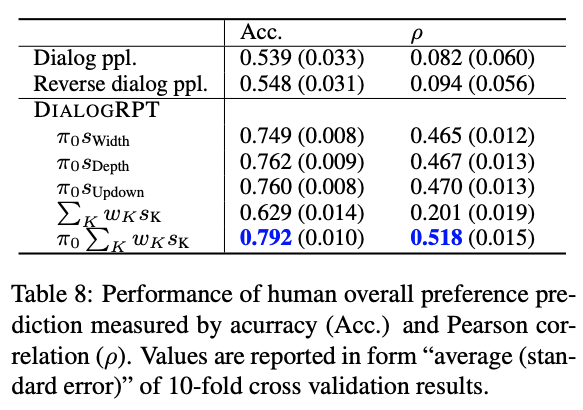
- 세 가지 피드백 모드 중에서 인간의 선호도는 Updown과 가장 잘 연관되어 있는데, 이는 아마도 Upvotes (또는 "좋아요")는 너비나 깊이보다 인간의 선호도와 더 직접적으로 연관되어 있다는 의미로 해석할 수 있다.
Conclustion
결과적으로 기존의 perplex-based된 DialogGPT보다 ranking하는 성능이 향상됐는데, 이는 Generative dialogue model의 ranking 과정에서 사람의 피드백정보를 통합하면, 단어간의 관련성에만 의존하는 방법보다 자연스러운 대화모델을 개발할 수 있음을 나타냄
