Will I Sound Like Me? Improving Persona Consistency in Dialogues through Pragmatic Self-Consciousness 논문요약
chatbot
논문링크: https://arxiv.org/abs/2004.05816
Generative 방식에서 Persona Consistency를 높이는 방식에 대해 제안한 논문
기존 SOTA 방법은 페르소나 Contradictory 에 insensitive 하다는 것을 강조하며 이를 보안하는 방법을 제안함
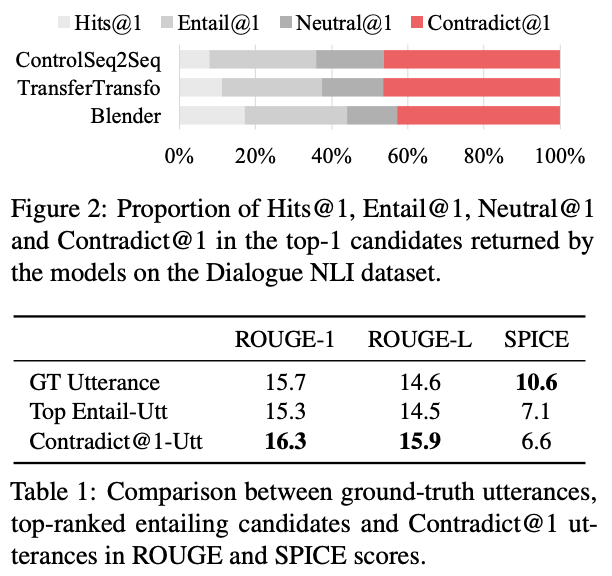
왜 insensitive한가 분석해보니 Contradict @ 1 결과를 낳은 발화들은 SPICE metrics에는 낮은 점수를 갖지만 ROUGE에서는 높은 점수를 받았음.
 또한, contradict@1-utter는 GT(Ground Truths)방식에 비해 Perpelxity도 낮았다.
또한, contradict@1-utter는 GT(Ground Truths)방식에 비해 Perpelxity도 낮았다.
이 실험 결과를 통해 챗봇모델은 페르소나 컨디션 모델보다 LM모델에 가깝게 행동하는 것을 알 수 있었다. word generation step에 일관성을 보장해줄 수 있는 persona-based dialogue agent가 필요하다.
Aproach
가상의 listener's distribution을 반영하도록해 consistency를 돕도록 하는 방법 제안
word generation step에서 생성된 token distribution에 self-concscious speacker가 개입해서 persona i에 조금 더 일치하는 단어가 선택될 수 있도록 각 token에 추가 persona distribution 점수를 부여하는 것.
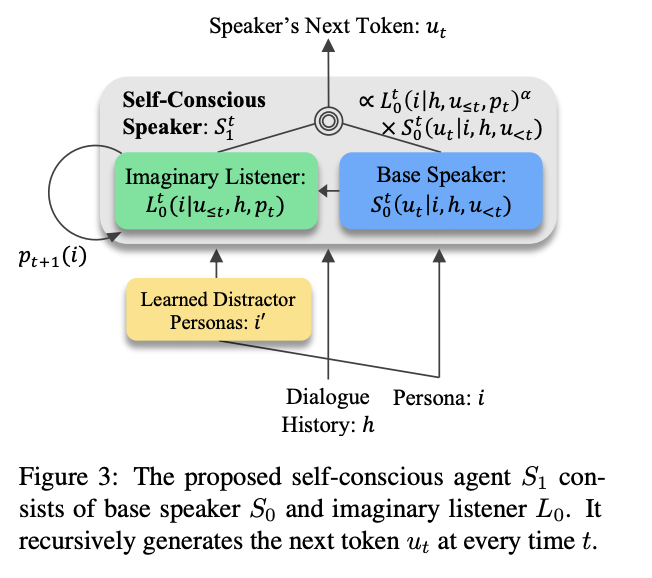
Distractor: 주어진 타겟과 다른 샘플들을 제공해 모델의 성능을 높이는 방법으로 여러 실험을 통해 Distractor를 선택하는 방법이 모델 성능에 중요한 영향을 미친다는 것을 강조하며 long-term memory network를 활용해여 Distactor selector를 학습시키는 방법 제공
실험 결과
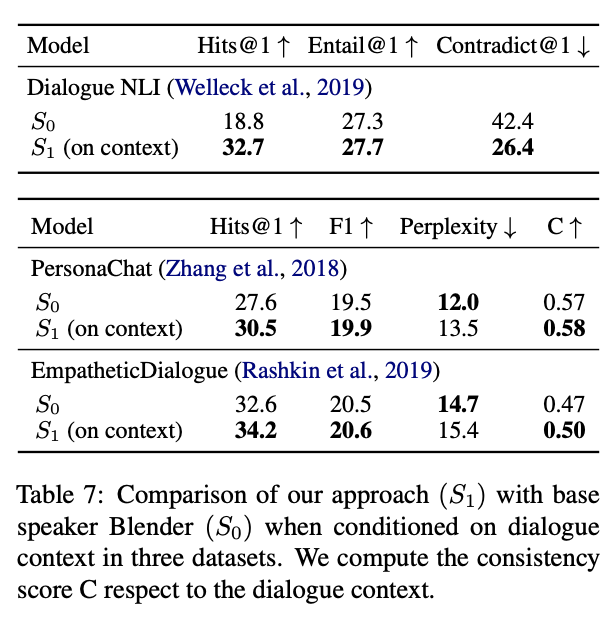
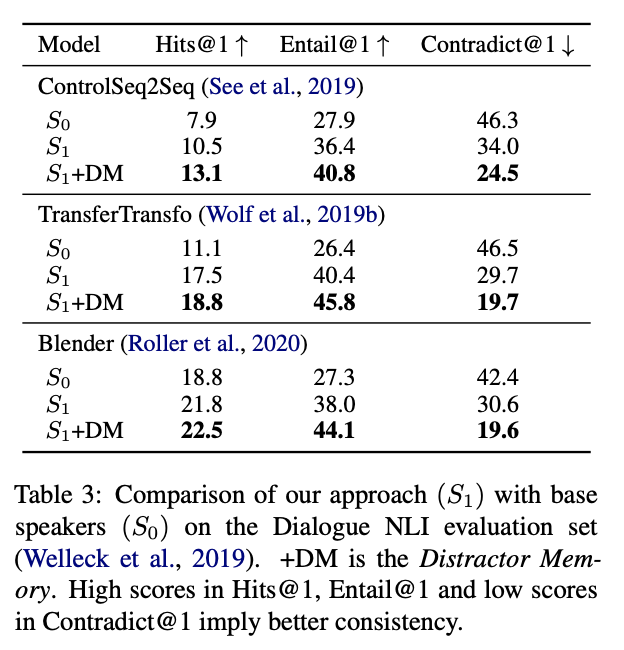
각 SOTA모델에 Dialogue NLI 평가데이터셋에서 평가결과.. 모순결과가 매우 낮아짐
Blender 이용했을 때 다양한 데이터셋 평가결과