Contributions
- 소셜미디어의 피드백 데이터를 사용해 large-scale의 feedback 예측 학습 데이터셋 구축
- comment의 engagingness를 평가하기 위해 ranking problem을 response pair를 비교하는 방식으로 변경
- 133M pair of human data(reddit data)로 GPT-2 기반의 DialogRPT 모델을 학습
Introduction
- End-to-end open domain dialog 성능은 인간이 구별하기 힘들정도로 높아졌다.
- SOTA 모델들의 목표는 minimizing the perplexity of reference response for a given context 와 같은 컨셉으로 정리된다.
- 주어진 레퍼런스 응답의 perplexity를 최소화
- 그러나, 그보다 context에 관련성이 있는지와 사람같이 말하는가에 집중되어야한다.
- 이 논문에서는 응답의 relevance보다 사람이 좋아할만한 응답을 증대시키는 방법에 집중한다. we move beyond simple prediction of response relevance, augmenting this with a prediction of how likely a response is to elicit a positive reaction from an interlocutor.
- 소셜 미디어에 방대한 피드백 데이터들이 많아 large-scale 학습데이터를 구축하는 것이 가능하다. 그러나 피드백과 퀄리티가 항상 비례하지만은 않다. (인플루언스의 댓글과 그렇지 않은 것들의 차이 등등..)
- 따라서 절대적으로 피드백 수치를 비교하는 것이 아닌 댓글들을 비교해 분류하는 테스크를 수행한다.
Human feedback
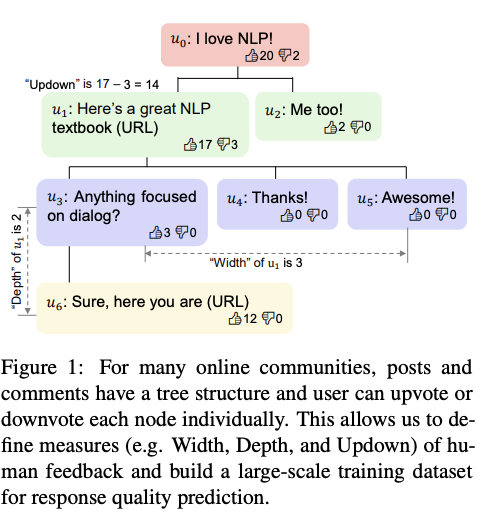
- 스레드 root로부터 해당 댓글의 parent node까지 Context로 정하고 해당 댓글을 reply로 정의한다. We consider the path from the root to the parent node of a comment to be its context c, and the comment as a reply r
- 소셜 미디어 스레드에서 해당 댓글의 feedback 을 평가하는 메트릭스는 아래와 같이 정의한다.
-
Width, the number of direct replies to r.
-
Depth, the maximum length of the dialog after this turn.
-
Updown, the number of upvotes minus the number of downvotes.
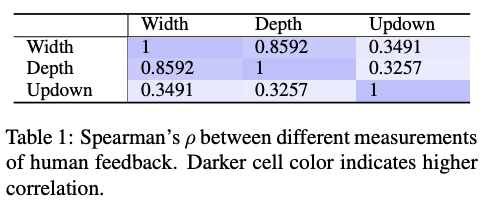
-
깊이, 넓이에 updown은 상관이 없었는데 좋은글에 댓글 쓰는대신 updown으로 피드백을 대체한다고 볼 수 있다.
-
- 일반적으로는 실제 댓글의 퀄리티와 피드백 점수는 높은 유사도를 갖지만 높은 피드백을 받은 댓글과 유사한 댓글의 게시물은 매우 다른 피드백을 받기도한다. (precision은 높은데 recall은 낮다)
- 매우 인기있는 스레드의 흥미롭지 않은 댓글은 인기없는 서브레딧의 흥미있는 댓글 피드백보다 높은 점수 받으며 댓글 타이밍에 피드백점수가 크게 영향을 받는다.
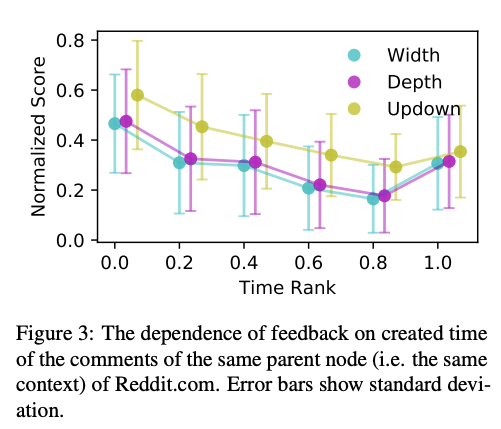
- 3가지 메트릭스를 활용하는 것과 더불어, 응답 생성에 활용하기 위해 [사람 VS Fake] 테스크도 추가해 사람같은 응답을 측정하도록 한다.
- Fake example로는 random human response와 machine generated responses를 사용

Striving to build valuable services