
1일차
가상화 (Virtualization)
가상화는 소프트웨어를 사용하여 프로세서, 메모리, 스토리지 등과 같은 단일 컴퓨터의 하드웨어 요소를 일반적으로 가상 머신(VM)이라고 하는 다수의 가상 컴퓨터로 분할할 수 있도록 해주는 컴퓨터 하드웨어 상의 추상화 계층을 구축한다. 실제 기반 컴퓨터 하드웨어의 단지 일부에서만 실행됨에도 불구하고, 각각의 VM은 자체 운영체제(OS)를 실행하며 마치 독립적인 컴퓨터인 것처럼 작동한다. 가상화를 관리하는 소프트웨어(주로 Hypervisor)를 사용하여 하나의 물리적 머신에서 가상 머신(VM)을 만드는 프로세스이다.
📌 호스트 OS형
호스트 OS형은 물리적인 하드웨어 자원 위에 OS를 설치해서 그 위에서 가상화 소프트웨어와 Virtual Machine을 움직이는 방식을 말한다. 따라서 이 같은 경우엔 호스트 Machine과 Virtual Machine 간의 OS가 서로 다를 수 있다.
예를들어 VMware, VirtualBox같은 하이퍼바이저를 이용하여 사용하는 윈도우 서버 위에 Guest OS로 리눅스 서버를 올린다. 이러한 하이퍼바이저 위에는 OS를 여러 개 생성할 수 있고, 각 OS마다 메모리나 하드디스크를 마음대로 분배할 수 있다. 여기서 생성한 OS 중 하나에 문제가 생겨도 다른 OS에 전혀 영향을 미치지 않는다. 즉 하이퍼바이저는 하드웨어 자원을 각각의 게스트OS에게 분할하여 위에서 서버 가상화를 완벽하게 구현한다는 것이다.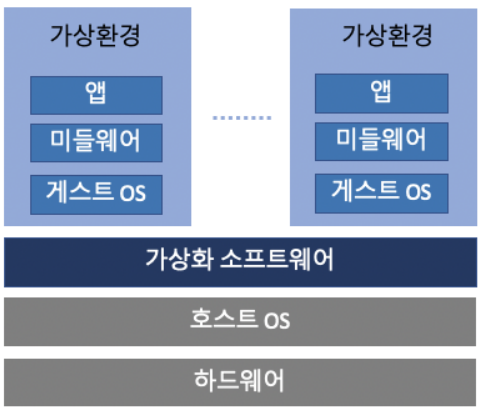
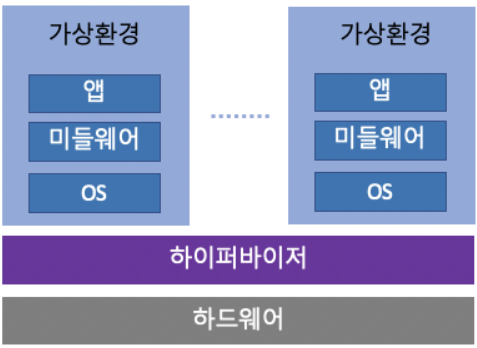
📌 하이퍼바이저형(Hypervisor)
하이퍼바이저형은 호스트 OS를 없이 하드웨어에 하이퍼바이저를 설치하여 사용하는 가상화 방식을 일컫는다. 즉, 하이퍼바이저라는 소프트웨어를 물리적인 하드웨어 자원 위에 직접 동작하게 함으로써 하이퍼바이저 소프트웨어 위에서 개별로 가상머신을 동작하게 만든다.
가상 머신(Virtual Machine, VM)을 생성하고 구동하는 소프트웨어이다. 가상 머신 모니터(Virtual Machine Monitor, VMM)라고도 불리는 하이퍼바이저는 하이퍼바이저 운영 체제와 가상 머신의 리소스를 분리해 VM의 생성과 관리를 지원한다.
📌 컨테이너 (Container)
컨테이너 방식은 호스트 OS 상에서 컨테이너라는 것을 사용해 가상화하여 마치 별도의 서버처럼 사용한다. 컨테이너는 리소스가 각각 분리된 프로세스다. 게스트 OS들이 각각의 커널 공간을 가지던 VM 방식과 달리 호스트 OS의 커널 공간을 공유하며 독립된 파일 시스템, CPU/메모리, 프로세스 공간 등을 사용할 수 있다는 차이점이 있다. VM은 단순히 OS 안에 독립적인 다른 OS를 계속 증가시키는 방식이라 자원을 비효율적으로 사용하고, 컨테이너는 OS 위에 소프트웨어처럼 실행되어 비교적 자원을 덜 잡아먹고 속도도 빠르다.
논리적인 공간(컨테이너)을 만들어 다양한 어플리케이션을 설치해 하나의 서버처럼 사용할 수 있는 패키지이다. 컨테이너를 사용하면 애플리케이션과 종속 항목을 버전 관리가 쉬운 하나의 패키지로 묶어 팀 내의 여러 개발자가 쉽게 복제하고 클러스터 내의 머신으로도 간편하게 복제되도록 만들 수 있다. 즉, 개발자 입장에서는 시스템 소프트웨어 등 여러 종속성 문제에 구애받지 않고 여러 OS에 애플리케이션을 배포하며 시스템 소프트웨어에 대해서 구애받지 않고 버전관리를 할 수 있다.
< 컨테이너와 가상머신(VM)의 차이 >

DevOps Pipeline
서비스나 소프트웨어를 만들어서 론칭하는 게 개발, 론칭한 후에 문제가 생기지 않도록 하는 게 운영이라면 데브옵스란 소프트웨어의 개발(Development)과 운영(Operations)의 합성어로서 소프트웨어 개발자와 정보기술 전문가 간의 소통, 협업 및 통합을 강조하는 개발 환경이나 문화를 말한다. 데브옵스는 소프트웨어 개발조직과 운영조직간의 상호 의존적 대응이며 조직이 소프트웨어 제품과 서비스를 빠른 시간에 개발 및 배포하는 것을 목적으로 한다. 마치 ‘뫼비우스의 띠’처럼 기획하고 만들고 피드백하고 그에 따라 다시 만드는 활동들이 끊임없이 이어지는 것이다.
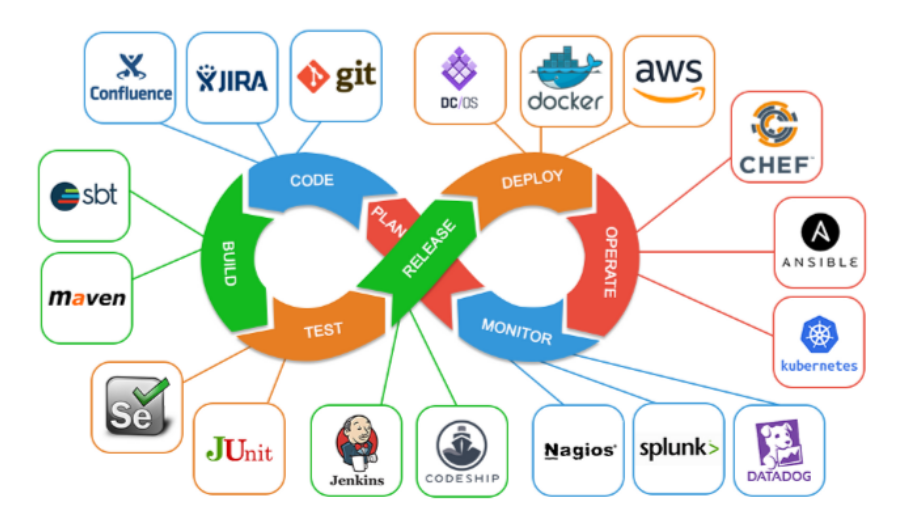
계획: 이 단계에서는 프로젝트 계획을 위한 로드맵을 만들고 기술, 환경, 아키텍처, 도구 및 소프트웨어를 결정합니다. 또한 변경 사항의 의미를 이해하고 시스템의 원활한 실행을 보장합니다.
코드: 개발자는 개발 환경에서 여러 도구를 사용하여 일관성, 코딩 표준 및 모범 사례를 통합할 수 있습니다.
빌드: 여기에서 DevOps 파이프라인이 완전히 시작되고 개발자가 공유 리포지토리에 코드를 커밋하여 코드 변경 사항을 병합하기 위한 풀 요청을 제기합니다. 모든 문제에 대해 알리기 위해 일련의 자동화된 통합 및 단위 테스트를 여기에서 끌어올 수 있습니다.
테스트: 빌드가 승인되면 프로덕션과 밀접하게 미러링되는 환경에 배포됩니다. 수동 및 자동으로 일련의 테스트 실행이 수행됩니다. 모든 조직에는 테스트 도구 모음이 있지만 기본 아이디어는 개발 워크플로우를 방해하지 않고 테스트를 수행하는 것입니다.
릴리스: 이 단계에서는 DevOps의 운영 부분이 시작됩니다. 조직은 새 빌드를 배포할 준비가 되었음을 알게 되고 발견되지 않은 결함이나 버그가 발생하지 않을 것이라는 확신을 갖게 됩니다.
배포: 빌드가 릴리스되면 프로덕션에 배포할 준비가 된 것입니다. 이 단계에서 조직은 블루-그린 배포 전략을 조율할 수 있습니다. 즉, 한 환경은 새로운 변경 사항을 호스팅하고 다른 환경은 이전 코드베이스를 호스팅하는 두 개의 동일한 프로덕션 환경을 보유할 수 있습니다.
작동: 애플리케이션의 원활한 작동을 보장하기 위해 이 단계가 있습니다. 운영 팀은 자동화된 구성 설정을 통해 애플리케이션을 관리하고 개선합니다.
모니터링: 잠재적인 병목 현상, 애플리케이션 버그 및 사용자 행동을 식별하기 위해 자동화된 모니터링 도구를 설정합니다. 여기에서 데이터 로그, 분석 및 사용자 피드백 수집이 이루어지고 실행 가능한 항목이 계획 및 반복을 위해 제품 팀에 다시 전달되고 DevOps 파이프라인을 통해 피드백됩니다.
📌CI / CD (지속적 통합, 지속적 전달)
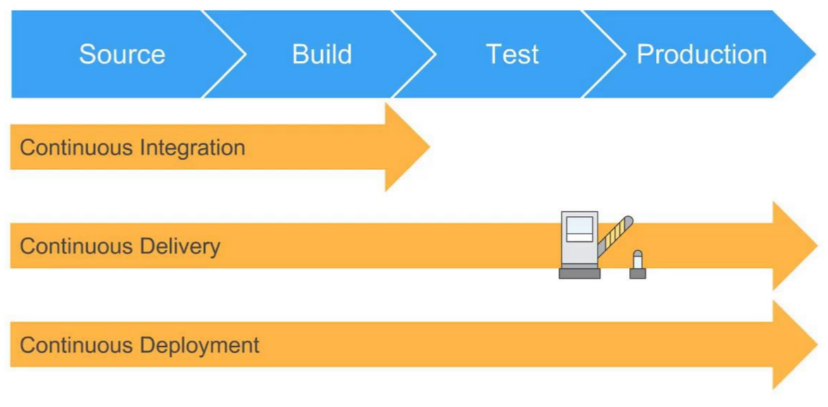 CI(Continuous Integration)란 지속적인 통합이라는 의미이다. 어플리케이션의 새로운 코드 변경 사항이 정기적으로 빌드 및 테스트 되어 공유 레포지토리에 통합히는 것을 의미한다. CI는 자동화된 빌드&테스트로 원천 소스코드의 충돌 등을 방어하는 이점이 있다. SVN, Git 등의 서비스를 통해 진행되지만 현재 붐처럼 떠오르는 MSA(Micro Service Archietecture) 환경에서 CI는 기능 충돌 방지를 제공하며, 신속히 버그를 찾아 품질을 개선하고 검증과 배포의 시간을 최소화하는데 도움을 줄수 있기에 중요하다.
CI(Continuous Integration)란 지속적인 통합이라는 의미이다. 어플리케이션의 새로운 코드 변경 사항이 정기적으로 빌드 및 테스트 되어 공유 레포지토리에 통합히는 것을 의미한다. CI는 자동화된 빌드&테스트로 원천 소스코드의 충돌 등을 방어하는 이점이 있다. SVN, Git 등의 서비스를 통해 진행되지만 현재 붐처럼 떠오르는 MSA(Micro Service Archietecture) 환경에서 CI는 기능 충돌 방지를 제공하며, 신속히 버그를 찾아 품질을 개선하고 검증과 배포의 시간을 최소화하는데 도움을 줄수 있기에 중요하다. 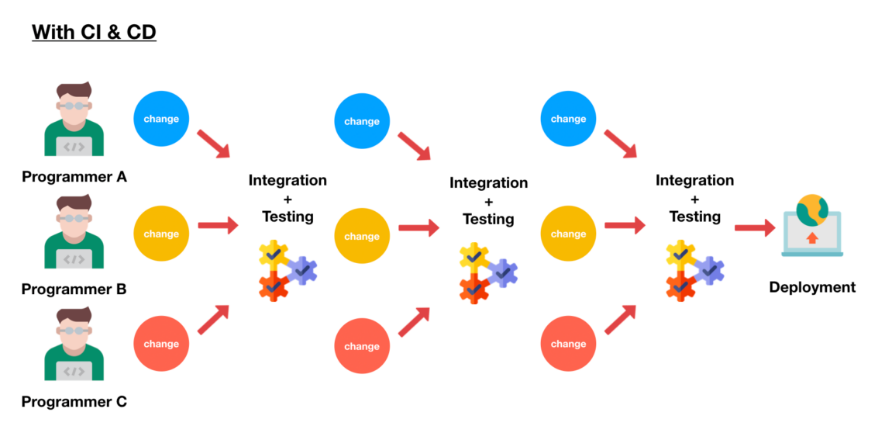
💡 CI/CD 예시
[Delfood] CI/CD 서버 구축과 첫 배포
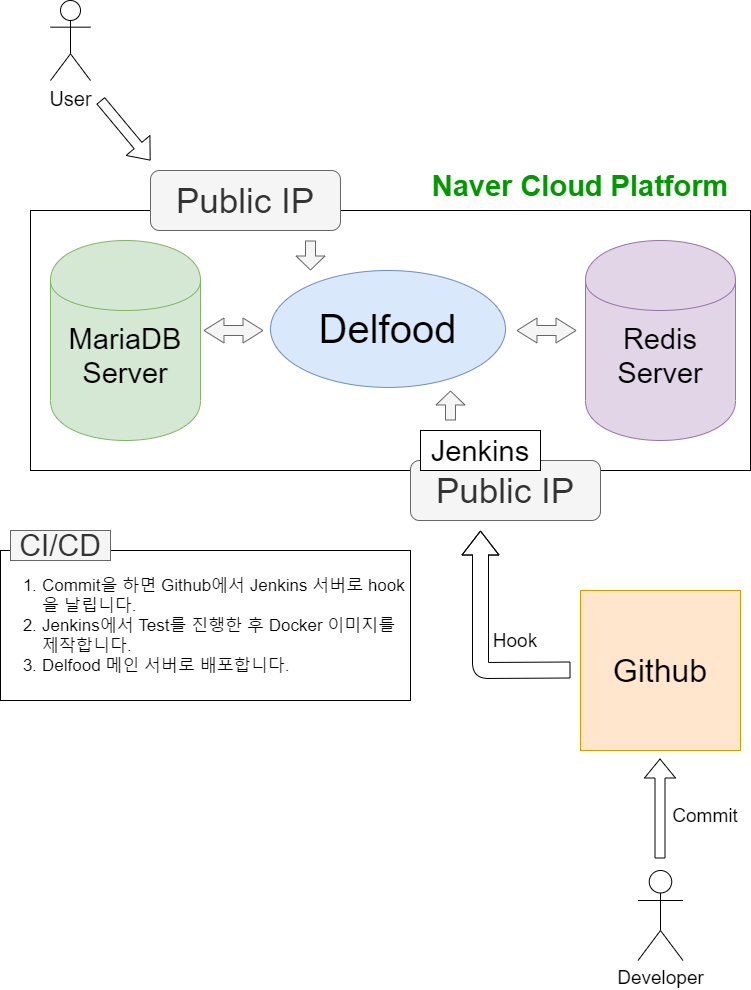
CD는 Continuous Delivery & Continuous Deployment의 의미로 지속적인 서비스 제공, 배포를 의미한다. Continuous Delivery는 공유 레포지토리로 자동으로 Release 하는 것, Continuous Deployment는 Production 레벨까지 자동으로 deploy 하는 것을 의미한다. 정리하자면 CI가 새로운 소스코드의 빌드, 테스트, 병합까지를 의미하였는데 CD는 개발자의 변경 사항이 레포지토리를 넘어 고객의 프로덕션(Production)환경까지 릴리즈 되는 것을 의미한다.
📌 IaC (Infrastructure as Code)
인프라 운영을 코드로 개발하여 관리하는 도구로 "프로그래밍형 인프라"라고도 한다. 기존의 수동으로 시스템마다 인프라를 구현하던 시대가 지고 코드로 개발된 인프라 구성이 활성화되고 있다. 이를 통해 인프라구성의 시간과 비용이 절감되고 일관성 보장, 오류감소, 구성변동 제거 등의 강점을 가지게 되었다.
개발자가 하던 프로비저닝(인프라 구축) 작업을 대부분 IaC로 처리하고 개발자는 스크립트를 실행하여 인프라를 준비할 수 있다. 따라서 인프라 준비를 기다리는 동안 애플리케이션 배포를 보류할 필요가 없으며 시스템 관리자는 시간이 많이 소요되는 수동 프로세스를 관리하지 않아도 된다.
📌 MSA(Micro Service Archietecture) 환경
기존의 어플리케이션이 모든 기능을 포함하는 하나의 거대한 서비스이었다면 MSA는 작은 기능별로 서비스를 잘게 쪼개어 개발하는 형태를 의미한다. MSA 환경에서는 대부분 Agile(소규모 기능 단위로 빠르게 개발 & 적용을 반복하는 개발방법론) 방법론이 적용되기 때문에 기능 추가가 매우 빈번하게 발생한다. 각각의 서비스는 독립적으로 실행되기 때문에 각 서비스 별로 업데이트, 배포 및 확장 할 수 있다. 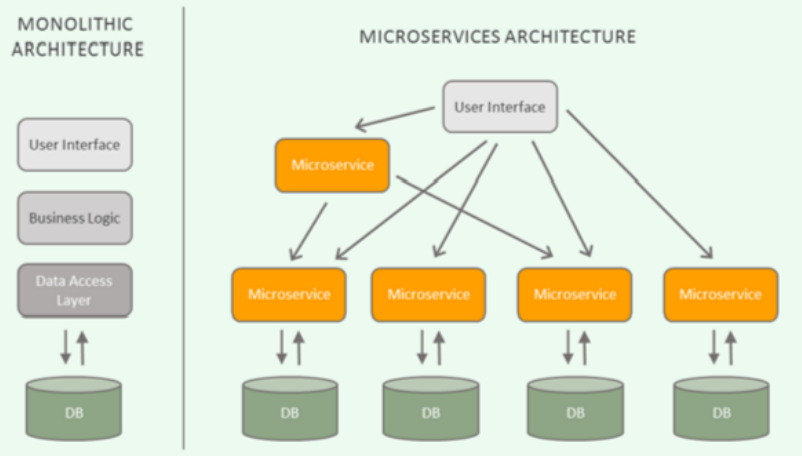
📌 모니터링 & 로깅(Monitoring & Logging)
서비스는 24시간 사용할 수 있어야 하고 애플리케이션 및 인프라 업데이트 빈도가 증가함에 따라 적극적인 모니터링이 더 중요해지고 있다. 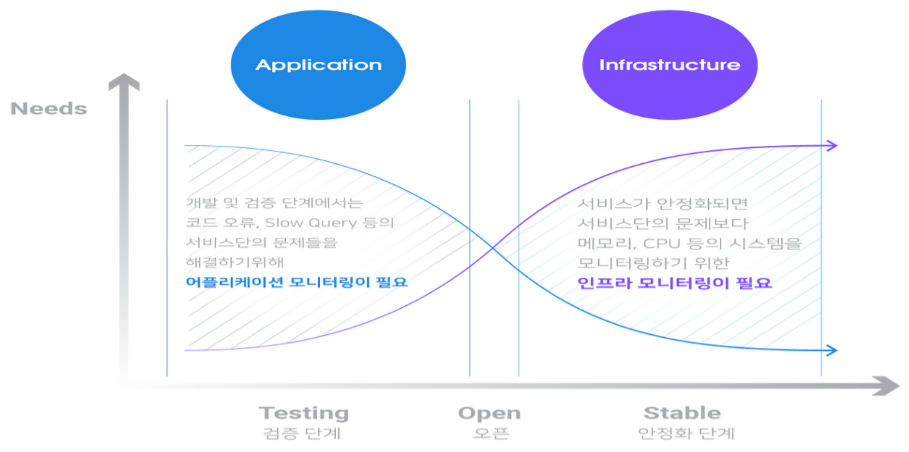
2일차
Port
일반적으로 포트 번호는 잘 알려진 포트(well-known port), 등록된 포트(registered port), 동적 포트(dynamic port) 세 가지로 나눌 수 있다. 잘 알려진 포트(well-known port)는 특정한 쓰임새를 위해서 IANA(Internet Assigned Numbers Authority)에서 할당한 TCP 및 UDP 포트 번호의 일부이다.
-
잘 알려진 포트(well-known port) : 0번 ~ 1023번 /UNIX/LINUX에서 루트(root) 권한으로만 port를 열 수 있음
-
등록된 포트(registered port) : 1024번 ~ 49151번 / 서버 소켓으로 사용함
-
동적 포트(dynamic port) : 49152번 ~ 65535번 /
일반적으로 서버는 well-known port와 registered port를 이용해서 사용한다. 서버 쪽과는 달리 클라이언트 쪽에서는 포트번호에 신경쓰지 않고 해당 호스트 내에서 유일한가 여부에만 신경쓰며 이를 Ephemeral(잠시살아있는) 또는 임시 포트번호라고 표현 한다. 통상 1024 ~ 5000 번이 포트 번호로 할당 된다.
💡 기억 해둘만한 port
1521 - Oracle
3306 - MySQL, mariaDB < TCP >
1433 - MS sqlserver
20 - FTP(data) < TCP >
21 - FTP(File transfer protocol 제어) < TCP >
22 - SSH, SFTP(ssh 기반 ftp), SCP < TCP >
23 - Telnet < TCP >
25 - SMTP < TCP >
53 - DNS(Domain name service) < TCP, UDP >
69 - active mode, TFTP(Trivial FTP) < UDP >
80 - HTTP < TCP, UDP >
110 - POP3 < TCP >
443 - HTTPS < TCP >
990 - FTPS(ssl/tls 기반 ftp)
Session 확인
netstat: NETwork STATistics 의 약자로 전송 제어 프로토콜, 라우팅 테이블, 수많은 네트워크 인터페이스, 네트워크 프로토콜 통계를 위한 네트워크 연결을 보여주는 명령 도구이다.
<사용 가능한 명령어 목록>

PID 확인
리눅스에서 프로세스 PID는 너무나 기본적이면서 중요하다. 왜냐하면 해당 프로세스가 문제가 생겼을 때나 현재 실행상태 등을 체크할 때, 그리고 소켓을 여는 프로세스라면 몇개의 소켓이 열려있는지 등을 파악하기 위함이다.
ps: Process Status의 약자로 이름 그대로 명령어를 실행하면 현재 실행되고 있는 프로세스들의 정보를 화면에 출력한다. 또한 ps -aux | grep python 실행 명령에 python이 있었던 프로세스를 모두 찾을 수 있다. 찾은 PID를 가지고 ls -al /proc/pid 명령을 입력하면 해당 프로세스 실행 위치를 알 수 있다.
netstat -ano: 현재 열려있는 주소와 PID의 화면을 볼 수 있다. 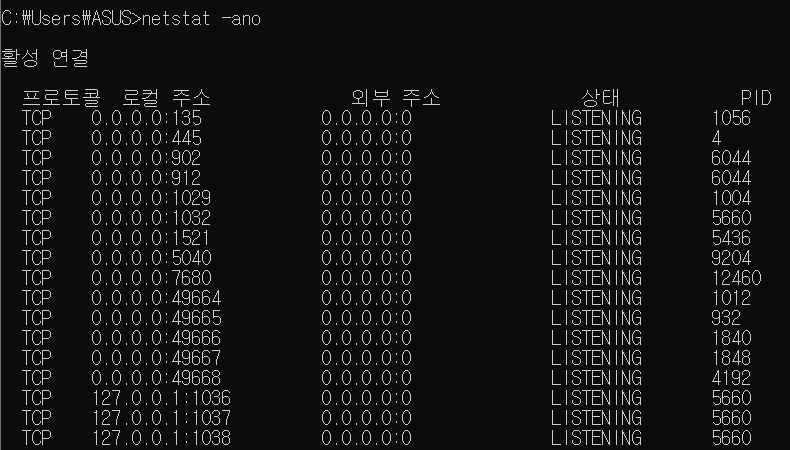
실행중인 프로세스 찾기: 작업관리자의 세부 정보를 통해 현재 사용하고 있는 PID를 확인할 수 있다.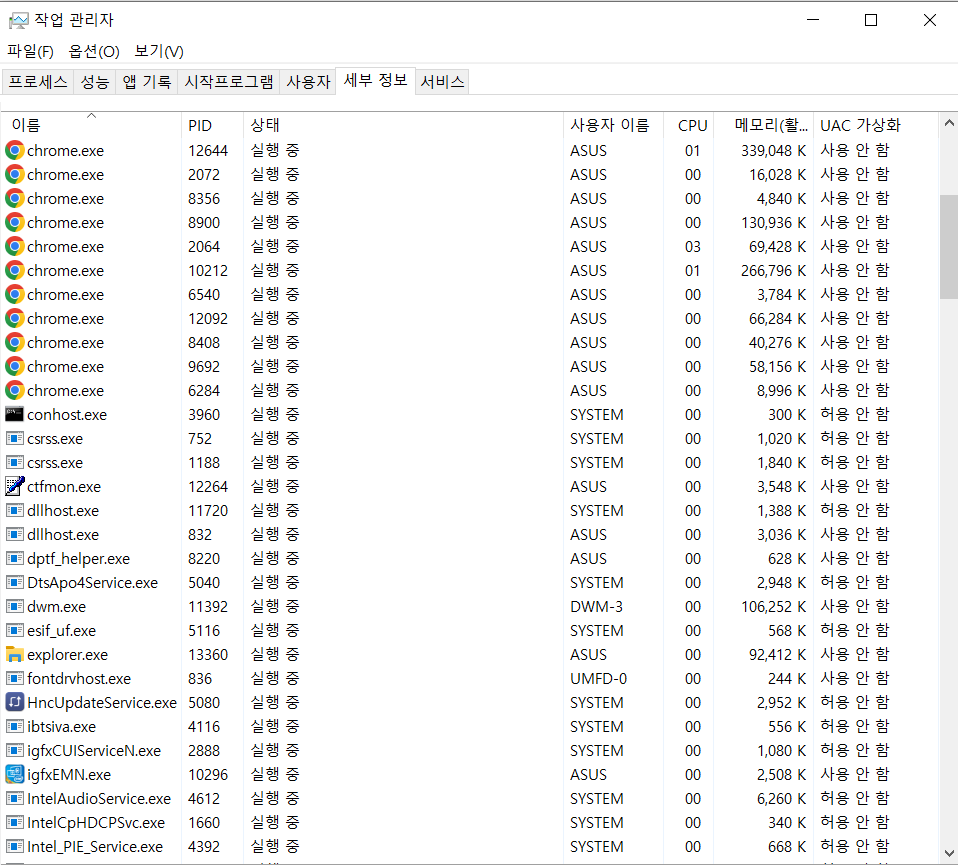
3일차
구글 검색 팁
- Filetype: pdf 검색명
확장자가 pdf인 파일을 찾아준다.
데이터 전송방식 비교
📌 Broadcast
브로드캐스팅(broadcasting)은 송신 호스트가 전송한 데이터가 네트워크에 연결된 모든 호스트에 전송되는 방식을 의미한다.
📌 Multicast
멀티캐스트(multicast)란 한 번의 송신으로 메시지나 정보를 목표한 여러 컴퓨터에 동시에 전송하는 것을 말한다. 이 때 망 접속 형태가 요구할 경우에 한해, 자동으로 라우터와 같은 다른 네트워크 요소들에 메시지의 복사본이 생성된다.
멀티캐스트 주소를 사용하는 가장 일반적인 전송 계층 프로토콜(transport layer protocol)은 사용자 데이터그램 프로토콜(User Datagram Protocol, UDP)이다.
📌 Unicast
유니캐스트(unicast) 전송이란 고유 주소로 식별된 하나의 네트워크 목적지에 1:1로 ( one-to-one) 트래픽 또는 메시지를 전송하는 방식을 말한다.
IGMP
서브넷(로컬 네트워크) 상에서, 멀티캐스팅 멤버십 제어를 위한, 그룹 관리용 프로토콜이다. 하나의 라우터와 여러 호스트로 구성되는 서브 네트워크(Sub Network) 상에서 호스트들이 어떤 멀티캐스트 그룹에 속하는가를 라우터에게 알리기 위한 일종의 그룹 관리용 신호 프로토콜이다. (Signaling Protocol)
📌 IGMP 동작과정
-
멀티캐스트 라우터는, 주기적으로 Subnet 호스트 그룹들(224.0.0.1 : 멀티캐스트 주소)에게 멀티 캐스트 그룹 참여 호스트가 있는지 여부를 묻는 IGMP Query 메시지를 전송한다.
-
호스트는 이러한 IGMP Query 메시지에 응답하면서 자신이 가입하려는 그룹 정보(멀티캐스트 주소)를 IGMP Report 메시지를 통해 라우터에게 알려준다.
-
호스트는 자체적으로 IGMP Query 메시지(라우터 -> 호스트) 없이도 먼저 Report 메시지를 라우터에게 전송도 가능하다.
-
질의에 대한 보고가 없거나 또는 특정 멀티 캐스트 그룹에서 탈퇴 메시지 ( IGMP Leave Message ) 를 호스트로부터 받은 경우 멀티 캐스트 라우터는 해당 서브넷 에 대한 모든, 또는 지정된 멀티 캐스트 그룹에게 패킷을 전달 하지 않는다 .
IPsec(IP Security)
IPSec은 IP계층(네트워크)에서의 안전한 연결을 설정하기 위해 IP 패킷 단위로 인증, 암호화, 키관리를 하는 프로토콜이다. IPsec은 IP에 자체적인 보안 기능이 없기 때문에 개발됐다.
IPSec은 암호화와 인증을 추가하여 프로토콜을 더욱 안전하게 만드는데 예를 들면 IPSec은 데이터를 소스에서 암호화한 다음 대상에서 복호화한다. 또한 데이터의 소스를 인증하는 것들을 의미한다.
SSL / TLS
SSL(Secure Scokets Layer)은 전송계층 상에서 클라이언트,서버에 대한 인증 및 데이터 암호화 수행하고 클라이언트와 서버 양단 간 응용계층 및 TCP 전송계층 사이에서 안전한 보안 채널을 형성해 주는 역할을 하는 보안용 프로토콜이다. 전달되는 모든 데이터를 암호화하고 특정한 유형의 사이버 공격도 차단한다.
SSL은 TLS(Transport Layer Security) 암호화의 전신이기도 한다. TLS(Transport Layer Security)는 문자 그대로 전송 계층에서 통신을 암호화하는 프로토콜이다. 응용계층(HTTP)과 전송계층(TCP) 사이에 위치해 있다.
웹 발전과정
http(Port: 80) -> https(Port: 443) -> HSTS ->QUIC(HTTP3)
📌 HSTS(HTTP Strict Transport Security)
HSTS는 HTTPS을 보조하는 정책 중 하나로서, 일정 기간 동안 이용자의 보안(HTTPS) 접속을 강제할 수 있다.
일반적으로 HTTPS를 강제하게 될 때 서버측에서 302 Redirect 를 이용하여 전환시켜 줄 수 있다. 하지만 이것이 취약점 포인트로 작용될 수 있다.따러서 클라이언트 (브라우저)에게 HTTPS를 강제 하도록 하는 것이 권장되는데, 이것이 HSTS (HTTP Strict Transport Security)이다. 클라이언트 (브라우저)에서 강제 하기 때문에 Plain Text (HTTP)를 이용한 연결 자체가 최초부터 시도되지 않으며 클라이언트 측에서 차단된다는 장점이 있다.
📌 QUIC(http3)
QUIC(Quick UDP Internet Connections) 프로토콜은 UDP 기반 응답 속도를 개선하고 TCP 기반 다중화와 신뢰성 있는 전송이 가능한 차세대 HTTP 프로토콜(HTTP/3)이다. Google을 통해 개발이 진행되었고, 지금은 표준 등록을 위해 준비한 프로토콜이라고 한다. 사물인터넷 등의 다양한 인터넷 서비스가 등장함에 따라, OSI 7 Layer 전송 계층 프로토콜의 한계를 극복하고 고품질의 인터넷 서비스 제공 위해 QUIC 프로토콜 개발하였다고 한다. 쉽게 말해서, Quick UDP 인터넷 연결을 의미한다.
TCP state diagram
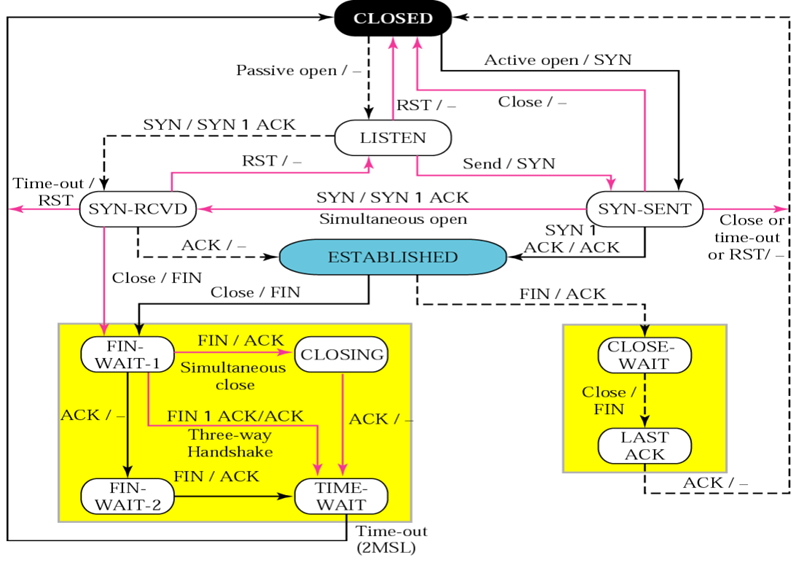
- 실질적인 데이터를 전송할 때는 push flag를 셋팅하고 보냄
- 서버측에서 연결을 종료할때는 서버에서 fin,ack 이후 클라이언트가 ack해서 끝냄
- 클라이언트가 syn를 보냈을 때 반응이 오면 port가 열린 것이고, RST,ack가 오면 port가 닫혀 있다는 것을 알 수 있음
wireshark
📌 패킷에서 계층별 정보를 찾는 방법
1) 패킷이 이동하는 네트워크를 찾는다. (나는 WIFI에서 찾음)
2) 하단에서 계층별 패킷을 확인하여 세부 정보를 찾아본다.
💡 TCP 조회
Frame - 데이터 링크계층(DataLink Layer) 2Layer
Ethernet II Src - 데이터 링크계층(DataLink Layer) 2Layer
Internet Protocol Version 4 Src (IPv4) - 네트워크 계층(Network Layer) 3Layer
Transmission Control Protocol (TCP) - 전송 계층(Transport Layer) 4Layer
📌 wireshark -> statics -> conversation -> display filter를 활용하는 방법


- 이더넷, IPv4, IPv6, TCP, UDP 필요 프로토콜만을 확인하기 위한 방법이다.
- 우클릭하여 다양한 필터를 적용할 수 있다. (A↔B 양방향 통신 등)
4일차
DNS(Domain Name System)
숫자로 이루어진 IP Address를 사람이 인식하기 쉬운 문자열로 변환, 역변환하는데 도움을 주는 서비스이다.DNS 정보를 저장하는 단위를 '레코드'라고 하는데 추상적으로 도메인(문자열), 도메인에 해당하는 아이피로 이루어 진다.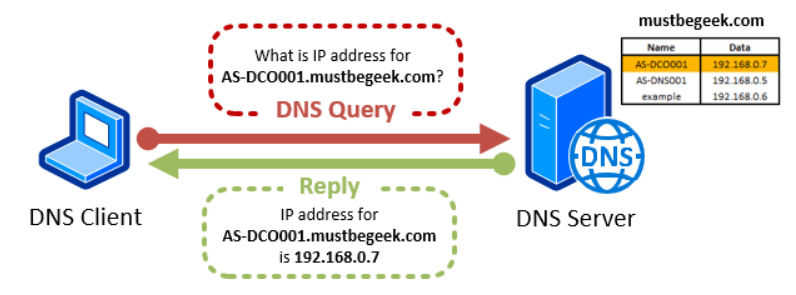 문자열을 조회해서 아이피를 찾는 것을 '정방향', 아이피를 조회해서 문자열을 찾는 것을 '역방향'이라고 한다.
문자열을 조회해서 아이피를 찾는 것을 '정방향', 아이피를 조회해서 문자열을 찾는 것을 '역방향'이라고 한다.
📌 DNS 작동방식
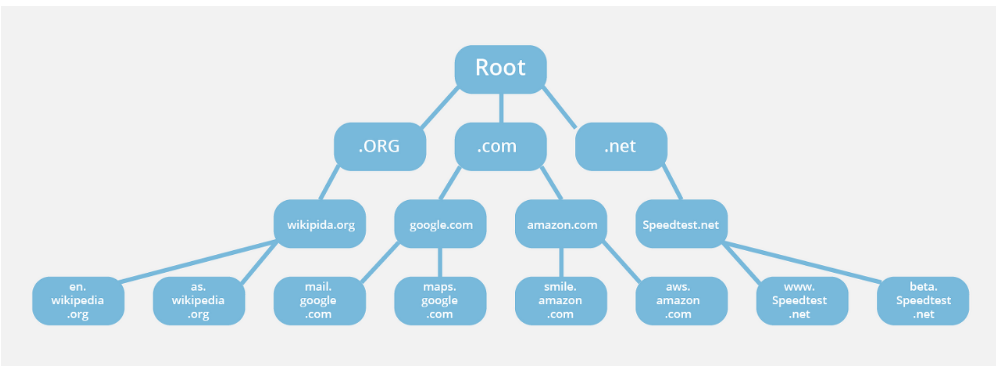
DNS 구성을 보면 상위 도메인(.org, .com, .net, 등) 밑에 하위 도메인이 있는 구조로 되어있다.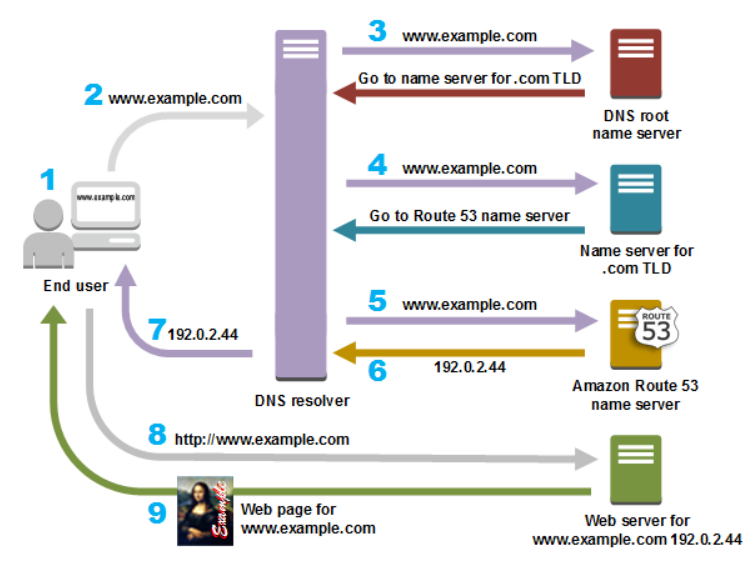 최상위 DNS를 통해 하위 DNS의 주소를 받은 뒤 하위 DNS에 질의를 반복하여 주소를 받아오는 것을 알 수 있다.
최상위 DNS를 통해 하위 DNS의 주소를 받은 뒤 하위 DNS에 질의를 반복하여 주소를 받아오는 것을 알 수 있다.
💡 www.naver.com을 입력해서 웹 페이지를 보기위한 과정
-
웹 브라우저에게 'www.naver.com' 웹 페이지 접속을 요청한다.
-
내 컴퓨터는 도메인을 해석하기 위해(도메인의 아이피를 알아내기 위해) 최상위 루트 DNS 서버에 'www.naver.com'의 아이피 주소를 요청한다.
-
루트 DNS 서버는 com의 DNS 서버 주소를 알려준다.
-
내 컴퓨터는 알아낸 com의 DNS 서버로 naver의 DNS 서버 주소를 알려준다.
-
내 컴퓨터는 알아낸 naver의 DNS 서버에 가서 www의 아이피 주소를 달라고 한다.
-
naver의 DNS 서버 주소가 가르쳐준 x.x.x.x로 접속해서 웹페이지를 받아온다.
여기서 주소는 마지막 최종 종착지 서버, 호스트를 의미하는 www 부분과 도메인 부분인 naver.com으로 이루어지는데 이렇게 호스트 부분과 도메인 부분이 합쳐진 전체 주소를 FQDN(Fully Qualified Domain Name)이라고 한다.
DNS 서버는 사실 도메인을 해석하기 위해서 두 가지 방식을 사용하는데 Recursive Query, 재귀적 질의 방식과 Iterative Query, 반복 질의 방식이 있다. 재귀적 방식은 클라이언트에서 DNS 쿼리를 요청하였을 때 서버가 직접 다른 DNS 서버에 질의해서 그 결과를 반환하는 방식이다. 반복 질의 방식은 클라이언트가 질의한 정보가 특정 DNS 서버 정보에 없을 경우 다른 연관된 DNS 서버 정보를 주고 클라이언트는 전달받은 새로운 DNS 서버 정보로 직접 조회하는 방식이다.
DNS 동작과정 다이어그램을 보여주는 사이트: https://www.zonecut.net/dns/
📌 DNS Caching
DNS 서버의 과부하를 막기 위해 최종 끝단 클라이언트와 각각의 계층을 담당하는 DNS 서버들은 굳이 자신의 윗 계층으로 질의하지 않아도 자기가 대답할 수 있게 이전에 사용했던(질의 당했던) 정보를 설정, 조건에 따라 저장하고 있다가 쿼리가 들어올 경우 다른 DNS 서버로 패스하는 것이 아니라 직접 응답을 해준다.
이렇게 저장하는 행위를 'Caching'이라고 하고 저장하는 공간을 'Cache'라고 한다. 이 캐시는 최종 끝단의 클라이언트, 즉 내 컴퓨터에도 있고 중간 DNS서비스들도 저장하고 있는데 일반 사용자의 경우 아래의 공간에 저장된다.
5일차
PC가 통신이 되는지 확인하기 위한 방법
- ping 127.0.0.1 네트워크 드라이브가 문제 없음을 체크
- ping 내 IP 자신에게 할당한 IP 주소 확인
- ping gateway gateway까지 도달하는 통신과정 확인
- ping 8.8.8.8 외부까지 전달되는 통신 과정 확인
- ping yahoo.co.kr 도메인 관련 정보 전달에 문제 없는지 체크
클러스터 역할
디스크(raid, lvm), CPU(HPC), 랜카드(bonding, teaming, ether channel, 네트워크를 묶는 클러스터(이중화를 통해서 네트워크 HA를 구현하고 통신의 LB를 뀌함)
