
📖 dplyr
- SQL 문법과 비슷함
📌 filter
> emp %>% filter(dept_no == 10 & gender == "M" & bonus >= 400)
id ename dept_no job_level join_date gender base bonus
1 6477 skim2 10 1 2020/06/01 M 3900 400
2 6163 jlee 10 3 2022/09/03 M 4500 500
3 6681 slee 10 4 2021/09/24 M 5000 500
> emp %>% filter(base >= 5000 | bonus >= 500 | dept_no == 40)
id ename dept_no job_level join_date gender base bonus
1 6163 jlee 10 3 2022/09/03 M 4500 500
2 6409 msa 10 3 2020/03/18 F 4000 500
3 6681 slee 10 4 2021/09/24 M 5000 500
4 6335 jlee2 20 3 2023/01/05 F 4700 500
5 6700 mkwon 20 4 2023/03/18 M 7000 600
6 6252 hpark 20 5 2020/06/01 M 5600 400
7 6224 yma 30 5 2021/10/10 F 5200 500
8 6081 hryu 40 2 2022/05/05 F 3200 300
9 6484 jchae 40 3 2022/12/01 M 3400 500
10 6195 mkwon 40 3 2022/05/09 M 3300 400
11 6228 noh 40 4 2020/06/01 F 5000 500
12 6670 bjin 40 5 2021/04/08 M 6000 600
> emp %>% filter(dept_no %in% c(20, 30))
id ename dept_no job_level join_date gender base bonus
1 6162 ylee 20 1 2020/01/02 M 4400 400
2 6018 jlee 20 3 2022/06/20 F 3800 300
3 6335 jlee2 20 3 2023/01/05 F 4700 500
4 6700 mkwon 20 4 2023/03/18 M 7000 600
5 6252 hpark 20 5 2020/06/01 M 5600 400
6 6003 dkoh 30 2 2021/11/11 F 3600 400
7 6224 yma 30 5 2021/10/10 F 5200 500📌 select
> emp %>% select(gender)
gender
1 F
2 M
3 M
4 M
5 F
6 M
7 M
8 F
9 M
10 F
11 F
12 M
13 M
14 F
15 F
16 F
17 M
18 M
19 F
20 M
> emp %>% select(ename, gender)
ename gender
1 skim F
2 skim2 M
3 jpark M
4 jlee M
5 msa F
6 rnoh M
7 slee M
8 jpark F
9 ylee M
10 jlee F
11 jlee2 F
12 mkwon M
13 hpark M
14 dkoh F
15 yma F
16 hryu F
17 jchae M
18 mkwon M
19 noh F
20 bjin M
> emp %>% select(-base)
id ename dept_no job_level join_date gender bonus
1 6353 skim 10 1 2022/07/06 F 400
2 6477 skim2 10 1 2020/06/01 M 400
3 6302 jpark 10 2 2021/05/01 M 300
4 6163 jlee 10 3 2022/09/03 M 500
5 6409 msa 10 3 2020/03/18 F 500
6 6018 rnoh 10 3 2021/11/20 M 300
7 6681 slee 10 4 2021/09/24 M 500
8 6531 jpark 10 5 2020/09/22 F 400
9 6162 ylee 20 1 2020/01/02 M 400
10 6018 jlee 20 3 2022/06/20 F 300
11 6335 jlee2 20 3 2023/01/05 F 500
12 6700 mkwon 20 4 2023/03/18 M 600
13 6252 hpark 20 5 2020/06/01 M 400
14 6003 dkoh 30 2 2021/11/11 F 400
15 6224 yma 30 5 2021/10/10 F 500
16 6081 hryu 40 2 2022/05/05 F 300
17 6484 jchae 40 3 2022/12/01 M 500
18 6195 mkwon 40 3 2022/05/09 M 400
19 6228 noh 40 4 2020/06/01 F 500
20 6670 bjin 40 5 2021/04/08 M 600
> emp %>% select(-base, -bonus)
id ename dept_no job_level join_date gender
1 6353 skim 10 1 2022/07/06 F
2 6477 skim2 10 1 2020/06/01 M
3 6302 jpark 10 2 2021/05/01 M
4 6163 jlee 10 3 2022/09/03 M
5 6409 msa 10 3 2020/03/18 F
6 6018 rnoh 10 3 2021/11/20 M
7 6681 slee 10 4 2021/09/24 M
8 6531 jpark 10 5 2020/09/22 F
9 6162 ylee 20 1 2020/01/02 M
10 6018 jlee 20 3 2022/06/20 F
11 6335 jlee2 20 3 2023/01/05 F
12 6700 mkwon 20 4 2023/03/18 M
13 6252 hpark 20 5 2020/06/01 M
14 6003 dkoh 30 2 2021/11/11 F
15 6224 yma 30 5 2021/10/10 F
16 6081 hryu 40 2 2022/05/05 F
17 6484 jchae 40 3 2022/12/01 M
18 6195 mkwon 40 3 2022/05/09 M
19 6228 noh 40 4 2020/06/01 F
20 6670 bjin 40 5 2021/04/08 M📌 arrange
> emp %>%
+ arrange(id)
id ename dept_no job_level join_date gender base bonus
1 6003 dkoh 30 2 2021/11/11 F 3600 400
2 6018 rnoh 10 3 2021/11/20 M 3500 300
3 6018 jlee 20 3 2022/06/20 F 3800 300
4 6081 hryu 40 2 2022/05/05 F 3200 300
5 6162 ylee 20 1 2020/01/02 M 4400 400
6 6163 jlee 10 3 2022/09/03 M 4500 500
7 6195 mkwon 40 3 2022/05/09 M 3300 400
8 6224 yma 30 5 2021/10/10 F 5200 500
9 6228 noh 40 4 2020/06/01 F 5000 500
10 6252 hpark 20 5 2020/06/01 M 5600 400
11 6302 jpark 10 2 2021/05/01 M 3700 300
12 6335 jlee2 20 3 2023/01/05 F 4700 500
13 6353 skim 10 1 2022/07/06 F 4000 400
14 6409 msa 10 3 2020/03/18 F 4000 500
15 6477 skim2 10 1 2020/06/01 M 3900 400
16 6484 jchae 40 3 2022/12/01 M 3400 500
17 6531 jpark 10 5 2020/09/22 F 4000 400
18 6670 bjin 40 5 2021/04/08 M 6000 600
19 6681 slee 10 4 2021/09/24 M 5000 500
20 6700 mkwon 20 4 2023/03/18 M 7000 600
> emp %>%
+ arrange(desc(base))
id ename dept_no job_level join_date gender base bonus
1 6700 mkwon 20 4 2023/03/18 M 7000 600
2 6670 bjin 40 5 2021/04/08 M 6000 600
3 6252 hpark 20 5 2020/06/01 M 5600 400
4 6224 yma 30 5 2021/10/10 F 5200 500
5 6681 slee 10 4 2021/09/24 M 5000 500
6 6228 noh 40 4 2020/06/01 F 5000 500
7 6335 jlee2 20 3 2023/01/05 F 4700 500
8 6163 jlee 10 3 2022/09/03 M 4500 500
9 6162 ylee 20 1 2020/01/02 M 4400 400
10 6353 skim 10 1 2022/07/06 F 4000 400
11 6409 msa 10 3 2020/03/18 F 4000 500
12 6531 jpark 10 5 2020/09/22 F 4000 400
13 6477 skim2 10 1 2020/06/01 M 3900 400
14 6018 jlee 20 3 2022/06/20 F 3800 300
15 6302 jpark 10 2 2021/05/01 M 3700 300
16 6003 dkoh 30 2 2021/11/11 F 3600 400
17 6018 rnoh 10 3 2021/11/20 M 3500 300
18 6484 jchae 40 3 2022/12/01 M 3400 500
19 6195 mkwon 40 3 2022/05/09 M 3300 400
20 6081 hryu 40 2 2022/05/05 F 3200 300
> emp %>%
+ arrange(dept_no, join_date)
id ename dept_no job_level join_date gender base bonus
1 6409 msa 10 3 2020/03/18 F 4000 500
2 6477 skim2 10 1 2020/06/01 M 3900 400
3 6531 jpark 10 5 2020/09/22 F 4000 400
4 6302 jpark 10 2 2021/05/01 M 3700 300
5 6681 slee 10 4 2021/09/24 M 5000 500
6 6018 rnoh 10 3 2021/11/20 M 3500 300
7 6353 skim 10 1 2022/07/06 F 4000 400
8 6163 jlee 10 3 2022/09/03 M 4500 500
9 6162 ylee 20 1 2020/01/02 M 4400 400
10 6252 hpark 20 5 2020/06/01 M 5600 400
11 6018 jlee 20 3 2022/06/20 F 3800 300
12 6335 jlee2 20 3 2023/01/05 F 4700 500
13 6700 mkwon 20 4 2023/03/18 M 7000 600
14 6224 yma 30 5 2021/10/10 F 5200 500
15 6003 dkoh 30 2 2021/11/11 F 3600 400
16 6228 noh 40 4 2020/06/01 F 5000 500
17 6670 bjin 40 5 2021/04/08 M 6000 600
18 6081 hryu 40 2 2022/05/05 F 3200 300
19 6195 mkwon 40 3 2022/05/09 M 3300 400
20 6484 jchae 40 3 2022/12/01 M 3400 500
> emp %>%
+ arrange(desc(job_level), desc(base), join_date)
id ename dept_no job_level join_date gender base bonus
1 6670 bjin 40 5 2021/04/08 M 6000 600
2 6252 hpark 20 5 2020/06/01 M 5600 400
3 6224 yma 30 5 2021/10/10 F 5200 500
4 6531 jpark 10 5 2020/09/22 F 4000 400
5 6700 mkwon 20 4 2023/03/18 M 7000 600
6 6228 noh 40 4 2020/06/01 F 5000 500
7 6681 slee 10 4 2021/09/24 M 5000 500
8 6335 jlee2 20 3 2023/01/05 F 4700 500
9 6163 jlee 10 3 2022/09/03 M 4500 500
10 6409 msa 10 3 2020/03/18 F 4000 500
11 6018 jlee 20 3 2022/06/20 F 3800 300
12 6018 rnoh 10 3 2021/11/20 M 3500 300
13 6484 jchae 40 3 2022/12/01 M 3400 500
14 6195 mkwon 40 3 2022/05/09 M 3300 400
15 6302 jpark 10 2 2021/05/01 M 3700 300
16 6003 dkoh 30 2 2021/11/11 F 3600 400
17 6081 hryu 40 2 2022/05/05 F 3200 300
18 6162 ylee 20 1 2020/01/02 M 4400 400
19 6353 skim 10 1 2022/07/06 F 4000 400
20 6477 skim2 10 1 2020/06/01 M 3900 400
> emp %>%
+ filter((dept_no == 10 & job_level <=2) | (dept_no %in% c(20, 30) & job_level >= 4)) %>%
+ select(ename, dept_no, job_level, join_date) %>%
+ arrange(desc(job_level), join_date)
ename dept_no job_level join_date
1 hpark 20 5 2020/06/01
2 yma 30 5 2021/10/10
3 mkwon 20 4 2023/03/18
4 jpark 10 2 2021/05/01
5 skim2 10 1 2020/06/01
6 skim 10 1 2022/07/06📌 mutate
- 열 추가 및 수정
> emp %>%
+ mutate(total = base + bonus) %>%
+ head
id ename dept_no job_level join_date gender base bonus total
1 6353 skim 10 1 2022/07/06 F 4000 400 4400
2 6477 skim2 10 1 2020/06/01 M 3900 400 4300
3 6302 jpark 10 2 2021/05/01 M 3700 300 4000
4 6163 jlee 10 3 2022/09/03 M 4500 500 5000
5 6409 msa 10 3 2020/03/18 F 4000 500 4500
6 6018 rnoh 10 3 2021/11/20 M 3500 300 3800
> emp %>%
+ mutate(special_bonus = base * 0.1) %>%
+ head
id ename dept_no job_level join_date gender base bonus special_bonus
1 6353 skim 10 1 2022/07/06 F 4000 400 400
2 6477 skim2 10 1 2020/06/01 M 3900 400 390
3 6302 jpark 10 2 2021/05/01 M 3700 300 370
4 6163 jlee 10 3 2022/09/03 M 4500 500 450
5 6409 msa 10 3 2020/03/18 F 4000 500 400
6 6018 rnoh 10 3 2021/11/20 M 3500 300 350
> emp %>%
+ mutate(total = base + bonus,
+ special_bonus = total * 0.1)
id ename dept_no job_level join_date gender base bonus total special_bonus
1 6353 skim 10 1 2022/07/06 F 4000 400 4400 440
2 6477 skim2 10 1 2020/06/01 M 3900 400 4300 430
3 6302 jpark 10 2 2021/05/01 M 3700 300 4000 400
4 6163 jlee 10 3 2022/09/03 M 4500 500 5000 500
5 6409 msa 10 3 2020/03/18 F 4000 500 4500 450
6 6018 rnoh 10 3 2021/11/20 M 3500 300 3800 380
7 6681 slee 10 4 2021/09/24 M 5000 500 5500 550
8 6531 jpark 10 5 2020/09/22 F 4000 400 4400 440
9 6162 ylee 20 1 2020/01/02 M 4400 400 4800 480
10 6018 jlee 20 3 2022/06/20 F 3800 300 4100 410
11 6335 jlee2 20 3 2023/01/05 F 4700 500 5200 520
12 6700 mkwon 20 4 2023/03/18 M 7000 600 7600 760
13 6252 hpark 20 5 2020/06/01 M 5600 400 6000 600
14 6003 dkoh 30 2 2021/11/11 F 3600 400 4000 400
15 6224 yma 30 5 2021/10/10 F 5200 500 5700 570
16 6081 hryu 40 2 2022/05/05 F 3200 300 3500 350
17 6484 jchae 40 3 2022/12/01 M 3400 500 3900 390
18 6195 mkwon 40 3 2022/05/09 M 3300 400 3700 370
19 6228 noh 40 4 2020/06/01 F 5000 500 5500 550
20 6670 bjin 40 5 2021/04/08 M 6000 600 6600 660
> emp %>%
+ mutate(is_new = ifelse(join_date > "2022-03-01", "Y", "N")) %>%
+ select(ename, is_new)
ename is_new
1 skim Y
2 skim2 N
3 jpark N
4 jlee Y
5 msa N
6 rnoh N
7 slee N
8 jpark N
9 ylee N
10 jlee Y
11 jlee2 Y
12 mkwon Y
13 hpark N
14 dkoh N
15 yma N
16 hryu Y
17 jchae Y
18 mkwon Y
19 noh N
20 bjin NNULL VS NA
emp$total <- NULL # 열 자체가 사라짐 emp$special_bonus <- NA # 열은 그대로, 값만 알수없다고 표시
✨ dplyr 응용
> emp %>%
+ mutate(job_level_name = ifelse(job_level <= 2, "junior", "senior"),
+ signing_bonus = ifelse(join_date >= " 2023-01-01" & join_date <= "2023-12-31", 200, 0),
+ comission = ifelse(dept_no == 10 & job_level_name == "senior", 400, 0),
+ total = base + bonus + signing_bonus + comission) %>%
+ filter(total > 6000) %>%
+ select(ename, total) %>%
+ arrange(desc(total))
ename total
1 mkwon 7600
2 bjin 6800
3 hpark 6200
4 slee 6100📌 group_by, summarize
> emp %>%
+ group_by(dept_no) %>%
+ summarize(avg_base = mean(base),
+ med_base = median(base),
+ sum_bonus = sum(bonus),
+ no_ppl = n()) # 특정 변수가 아니라 행 개수를 셈. ()값 필요없음
# A tibble: 4 × 5
dept_no avg_base med_base sum_bonus no_ppl
<int> <dbl> <dbl> <int> <int>
1 10 4075 4000 3300 8
2 20 5100 4700 2200 5
3 30 4400 4400 900 2
4 40 4180 3400 2300 5평균: mean()
중앙값: median()
합: sum()
개수: n()
표준편차: sd()
분산: var()
최소값: min()
최대값: max()
✨ dplyr 응용 2
# 부서 번호 30 제외 filter
# 각 부서별 group_by
# 베이스 + 보너스 mutate
# 평균 summarize
# 연봉이 가장 높은 arrange
# 부서 번호만 출력 select
# 가장 높은 부서 번호 하나만 출력 head(1)
> emp %>%
+ filter(dept_no != 30) %>%
+ group_by(dept_no) %>%
+ mutate(total = base + bonus) %>%
+ summarize(avg_total = mean(total)) %>%
+ arrange(desc(avg_total)) %>%
+ select(dept_no) %>%
+ head(1)
# A tibble: 1 × 1
dept_no
<int>
1 20📌 join
① 가로에 열을 붙이는 방법, 기존 데이터에 변수를 추가
② 세로로 합치는 방법, 기존 데이터에 행을 추가
🔹 rbind(), cbind(), bind_rows(), bind_cols()
> m1 <- data.frame(id = 1:3,
+ kname = c("1월", "2월", "3월"),
+ name = month.name[1:3])
> m2 <- data.frame(id = 4:12,
+ name = month.name[4:12])
> a1 <- data.frame(abb = month.abb[3:1],
+ num = 3:1)
> a2 <- data.frame(abb = month.abb[2:5])
> m1
id kname name
1 1 1월 January
2 2 2월 February
3 3 3월 March
> m2
id name
1 4 April
2 5 May
3 6 June
4 7 July
5 8 August
6 9 September
7 10 October
8 11 November
9 12 December
> a1
abb num
1 Mar 3
2 Feb 2
3 Jan 1
> a2
abb
1 Feb
2 Mar
3 Apr
4 May> rbind(m1,m2)
Error in rbind(deparse.level, ...) :
numbers of columns of arguments do not match
> cbind(m1, a1)
id kname name abb num
1 1 1월 January Mar 3
2 2 2월 February Feb 2
3 3 3월 March Jan 1
> bind_rows(m1, m2) # 행 숫자가 달라도 합칠 수 있음.
id kname name
1 1 1월 January
2 2 2월 February
3 3 3월 March
4 4 <NA> April
5 5 <NA> May
6 6 <NA> June
7 7 <NA> July
8 8 <NA> August
9 9 <NA> September
10 10 <NA> October
11 11 <NA> November
12 12 <NA> December
> cbind(m2, a2) # 데이터 프레임의 길이가 서로 달라서 에러.
Error in data.frame(..., check.names = FALSE) :
arguments imply differing number of rows: 9, 4
> bind_cols(m2, a2)
Error in `bind_cols()`:
! Can't recycle `..1` (size 9) to match `..2` (size 4).
Run `rlang::last_trace()` to see where the error occurred.🔹 left_join()
> left_join(m1, a1, by= c("id" = "num"))
# m1의 id와 a1의 num이 같다.
id kname name abb
1 1 1월 January Jan
2 2 2월 February Feb
3 3 3월 March Mar🔹 inner_join()
> d1 <- data.frame(name = c("Minji", "Sojin", "Hyunwoo", "Kitae"),
+ bday = c("1980-01-02", "1982-05-06", "1988-02-04", "1993-04-07"),
+ job = c("Accountant", "Analyst", "Developer", "CEO"))
> d2 <- data.frame(name = c("Minji", "Sojin", "Hyunwoo", "Kitae"),
+ bday = c("2001-03-30", "1982-05-06", "2003-09-22", "1993-04-07"),
+ city = c("Seoul", "Daegu", "Gwangju", "Jeju"))
> d1
name bday job
1 Minji 1980-01-02 Accountant
2 Sojin 1982-05-06 Analyst
3 Hyunwoo 1988-02-04 Developer
4 Kitae 1993-04-07 CEO
> d2
name bday city
1 Minji 2001-03-30 Seoul
2 Sojin 1982-05-06 Daegu
3 Hyunwoo 2003-09-22 Gwangju
4 Kitae 1993-04-07 Jeju
> inner_join(d1, d2, by = c("name", "bday"))
name bday job city
1 Sojin 1982-05-06 Analyst Daegu
2 Kitae 1993-04-07 CEO Jeju🔹 full_join()
> dept <- data.frame(dept_no = c(10, 30, 40, 50),
+ dept_name = c("Solas", "Operations", "HR", "Research"))
> loc <- data.frame(dept_no = c(10, 30, 40, 50, 60),
+ location = c("Seoul", "Incheon", "Busan", "Jeonju", "Daejeon"))
> extra_info <- full_join(dept, loc, by = "dept_no")
> extra_info
dept_no dept_name location
1 10 Solas Seoul
2 30 Operations Incheon
3 40 HR Busan
4 50 Research Jeonju
5 60 <NA> Daejeon🔹 union(), intersect(), setdiff()
> m1 = data.frame(id = 1:4,
+ name = month.name[1:4])
> m2 = data.frame(id = 3:7,
+ name = month.name[3:7])
> m3 = data.frame(id = 3:7,
+ name = month.name[3:7],
+ kname = c("3월", "4월", "5월", "6월", "7월"))
> m1
id name
1 1 January
2 2 February
3 3 March
4 4 April
> m2
id name
1 3 March
2 4 April
3 5 May
4 6 June
5 7 July
> m3
id name kname
1 3 March 3월
2 4 April 4월
3 5 May 5월
4 6 June 6월
5 7 July 7월> rbind(m1, m2)
id name
1 1 January
2 2 February
3 3 March
4 4 April
5 3 March
6 4 April
7 5 May
8 6 June
9 7 July
> bind_rows(m1, m3)
id name kname
1 1 January <NA>
2 2 February <NA>
3 3 March <NA>
4 4 April <NA>
5 3 March 3월
6 4 April 4월
7 5 May 5월
8 6 June 6월
9 7 July 7월
> union(m1, m2) # 중복값 없이 결합
id name
1 1 January
2 2 February
3 3 March
4 4 April
5 5 May
6 6 June
7 7 July
> intersect(m1, m2) # inner join의 행 버전
id name
1 3 March
2 4 April
> setdiff(m1, m2) # m1에는 있고, m2에는 없음
id name
1 1 January
2 2 February
> setdiff(m2, m1) # m2에는 있고, m1에는 없음
id name
1 5 May
2 6 June
3 7 July📌 기타 유용한 함수
✨ data.frame 씌우기 전에 tibble이면 색깔 차이로 정보를 더 표시
emp %>% + group_by(dept_no, job_level) %>% + summarize(avg = mean(base)) %>% + mutate(prev_avg = lag(avg), + diff = prev_avg - avg) `summarise()` has grouped output by 'dept_no'. You can override using the `.groups` argument. # A tibble: 15 × 5 # Groups: dept_no [4]
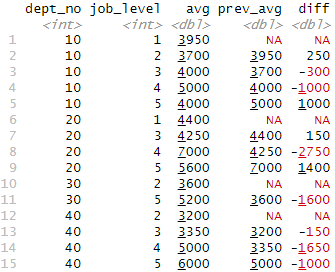
✨ 그룹을 고려하지 않고 lag가 밀고 차를 계산함.
df_emp <- data.frame(emp %>% + group_by(dept_no, job_level) %>% + summarize(avg = mean(base), .groups = 'drop') %>% + select(dept_no, job_level, avg)) df_emp %>% + mutate(prev_avg = lag(avg), + diff = prev_avg - avg) dept_no job_level avg prev_avg diff 1 10 1 3950 NA NA 2 10 2 3700 3950 250 3 10 3 4000 3700 -300 4 10 4 5000 4000 -1000 5 10 5 4000 5000 1000 6 20 1 4400 4000 -400 7 20 3 4250 4400 150 8 20 4 7000 4250 -2750 9 20 5 5600 7000 1400 10 30 2 3600 5600 2000 11 30 5 5200 3600 -1600 12 40 2 3200 5200 2000 13 40 3 3350 3200 -150 14 40 4 5000 3350 -1650 15 40 5 6000 5000 -1000
🔹 순서 함수 세가지
- row_number(): 그냥 순서대로 순위를 매김
- min_rank(): 중복값은 동순위로 하고 건너뛰고 그 다음 순위 카운팅
- dense_rank(): 중복 되어도 건너뛰지 않고 바로 다음 숫자로 순위 매김
> emp %>%
+ arrange(desc(base), desc(bonus)) %>%
+ mutate(rank1 = row_number(desc(base)),
+ rank2 = min_rank(desc(base)),
+ rank3 = dense_rank(desc(base)))
id ename dept_no job_level join_date gender base bonus rank1 rank2 rank3
1 6700 mkwon 20 4 2023/03/18 M 7000 600 1 1 1
2 6670 bjin 40 5 2021/04/08 M 6000 600 2 2 2
3 6252 hpark 20 5 2020/06/01 M 5600 400 3 3 3
4 6224 yma 30 5 2021/10/10 F 5200 500 4 4 4
5 6681 slee 10 4 2021/09/24 M 5000 500 5 5 5
6 6228 noh 40 4 2020/06/01 F 5000 500 6 5 5
7 6335 jlee2 20 3 2023/01/05 F 4700 500 7 7 6
8 6163 jlee 10 3 2022/09/03 M 4500 500 8 8 7
9 6162 ylee 20 1 2020/01/02 M 4400 400 9 9 8
10 6409 msa 10 3 2020/03/18 F 4000 500 10 10 9
11 6353 skim 10 1 2022/07/06 F 4000 400 11 10 9
12 6531 jpark 10 5 2020/09/22 F 4000 400 12 10 9
13 6477 skim2 10 1 2020/06/01 M 3900 400 13 13 10
14 6018 jlee 20 3 2022/06/20 F 3800 300 14 14 11
15 6302 jpark 10 2 2021/05/01 M 3700 300 15 15 12
16 6003 dkoh 30 2 2021/11/11 F 3600 400 16 16 13
17 6018 rnoh 10 3 2021/11/20 M 3500 300 17 17 14
18 6484 jchae 40 3 2022/12/01 M 3400 500 18 18 15
19 6195 mkwon 40 3 2022/05/09 M 3300 400 19 19 16
20 6081 hryu 40 2 2022/05/05 F 3200 300 20 20 17🔹 누적 평균
> emp %>%
+ arrange(join_date) %>%
+ group_by(gender) %>%
+ arrange(gender) %>%
+ mutate(cum_base = cummean(base))
# A tibble: 20 × 9
# Groups: gender [2]
id ename dept_no job_level join_date gender base bonus cum_base
<int> <chr> <int> <int> <chr> <chr> <int> <int> <dbl>
1 6409 msa 10 3 2020/03/18 F 4000 500 4000
2 6228 noh 40 4 2020/06/01 F 5000 500 4500
3 6531 jpark 10 5 2020/09/22 F 4000 400 4333.
4 6224 yma 30 5 2021/10/10 F 5200 500 4550
5 6003 dkoh 30 2 2021/11/11 F 3600 400 4360
6 6081 hryu 40 2 2022/05/05 F 3200 300 4167.
7 6018 jlee 20 3 2022/06/20 F 3800 300 4114.
8 6353 skim 10 1 2022/07/06 F 4000 400 4100
9 6335 jlee2 20 3 2023/01/05 F 4700 500 4167.
10 6162 ylee 20 1 2020/01/02 M 4400 400 4400
11 6477 skim2 10 1 2020/06/01 M 3900 400 4150
12 6252 hpark 20 5 2020/06/01 M 5600 400 4633.
13 6670 bjin 40 5 2021/04/08 M 6000 600 4975
14 6302 jpark 10 2 2021/05/01 M 3700 300 4720
15 6681 slee 10 4 2021/09/24 M 5000 500 4767.
16 6018 rnoh 10 3 2021/11/20 M 3500 300 4586.
17 6195 mkwon 40 3 2022/05/09 M 3300 400 4425
18 6163 jlee 10 3 2022/09/03 M 4500 500 4433.
19 6484 jchae 40 3 2022/12/01 M 3400 500 4330
20 6700 mkwon 20 4 2023/03/18 M 7000 600 4573.이 글은 패스트캠퍼스 데이터 분석 Master Class의 강의자료 일부를 발췌하여 작성되었습니다.

데이터 꿈나물