논문 읽기 전 알아둬야 할 개념
🔍대조학습
주어진 데이터에서 서로 유사한 샘플(positive pair)은 임베딩 공간상에서 가깝게, 서로 다른 샘플(negative pair)은 멀어지도록 학습하는 방법
| 용어 | 설명 |
|---|---|
| Anchor | 기준이 되는 샘플 |
| Positive | Anchor와 의미적으로 유사한 샘플 |
| Negative | Anchor와 의미적으로 다른 샘플 |
| Embedding | 입력 데이터를 고차원 공간에 매핑한 벡터 표현 |
| Contrastive Loss | Positive는 가깝게, Negative는 멀게 만드는 손실함수 |
🔍제로샷 전이
모델이 한 번도 훈련받지 않은 새로운 작업이나 클래스에 대해 정답 레이블 없이도 바로 예측을 수행하는 능력
ex)
모델이 ‘기린’이라는 단어를 본 적은 있지만 '기린 사진'을 학습하지는 않았을때도 “기린이 있는 사진을 골라봐” 하면, 기린을 찾아낼 수 있다.
-> why? 이미 기린이라는 단어가 포함된 설명(텍스트)과 수많은 다른 이미지 간의 연결을 학습했기 때문에, 새로운 카테고리도 텍스트 기반 설명만으로 바로 대응할 수 있다.
0. Abstract
최신 컴퓨터 비전 시스템들은 미리 정해진 고정된 객체 범주를 예측하도록 학습된다.
-> “고양이”, “자동차”처럼 사람이 미리 라벨링한 데이터만 인식 가능하다는 뜻
이러한 제한된 형태의 지도 학습은 일반성과 활용성을 제한하며, 다른 시각적 개념을 지정하려면 추가적인 라벨링된 데이터가 필요하다는 단점이 있다.
이에 대한 유망한 대안은 이미지에 대한 텍스트로부터 직접 학습하는 것이다.
“어떤 캡션이 어떤 이미지에 해당하는지" 예측하는 단순한 사전 학습 과제는 효율적이고 확장 가능한 방식으로 최신 이미지 표현을 처음부터 학습하는 데 효과적이다.
학습 데이터: 인터넷에서 수집한 4억 쌍의 이미지-텍스트 데이터
복잡한 라벨링 X, 사람이 손으로 분류한 것 X
👉 인터넷에 자연스럽게 존재하는 이미지와 캡션만으로 학습
사전 학습이 끝난 모델은 텍스트로 시각 개념을 불러오거나 새로운 개념을 설명해서 그걸 기반으로 예측하게 할 수 있다.
즉, 자연어만으로도 다양한 작업에 제로샷 전이가 가능하다.
OCR,행동 인식, 위치 추정, 정밀한 객체 분류 같은 30개 이상의 컴퓨터 비전 문제에 적용해봤을때 대부분의 문제에서 별도의 학습 없이도 꽤 잘 작동했고, 라벨 붙여서 정성껏 학습한 모델이랑 비슷하거나 좋은 성능을 보였다.
이미 OCR을 위해 따로 만든 ‘정답 데이터로 열심히 학습한 모델’이 그냥 텍스트-이미지 학습만 해둔 모델이 비슷한 수준의 정확도를 낸다
ImageNet 제로샷 분류에서, 기존 ResNet-50이 1,280,000개의 라벨 데이터를 보고 학습한 성능과 본 모델이 단 0개의 데이터만 보고 달성한 성능이 거의 같음
1.Introduction and Motivating Work
CLIP 등장 배경
최근 몇 년간 NLP분야는 엄청난 변화를 겪었다. GPT, BERT 같은 모델들이 웹에서 수집한 '원시 텍스트'만으로 언어를 이해하고,
심지어 학습하지 않은 작업에도 제로샷으로 대응할 수 있게 된 것이다.
학습:
"A photo of a cat", "A photo of a dog" 이런 텍스트랑 이미지 쌍을 수백만 개 학습
테스트:
펭귄 사진을 넣고,후보 텍스트로 "A photo of a cat", "A photo of a penguin", "A photo of a bear"를 같이 넣으면
→ CLIP은 펭귄 사진과 "A photo of a penguin"이 제일 잘 어울린다고 판단함
한 번도 "펭귄"이라는 정답 라벨로 훈련받은 적 없지만,텍스트와 이미지의 의미를 모두 이해하니까 논리적으로 고르는 것
💡보통 이미지 분류에선 “고양이”, “개”, “자동차” 같은 카테고리 라벨을 사용하지만 CLIP은 “A photo of a dog” 같은 문장(자연어)을 정답처럼 사용
사전학습 방식(pre-training)
- 다음 단어를 예측하는 autoregressive 방식
- 문장 중 일부 단어를 가리고 맞히는 마스킹 방식
이처럼 특정 태스크에 종속되지 않는 학습 방식으로, 한 번 훈련만 잘 해두면 다양한 작업에 두루 사용할 수 있다.실제로 GPT-3 같은 모델은 별도 데이터 없이도 고성능을 보여주며, 사람이 라벨링한 소량의 데이터로 만든 모델들을 넘어서고 있다.
반면, 컴퓨터 비전 분야는 여전히 ImageNet처럼 사람이 직접 라벨링한 데이터셋에 의존하고 있다. 하지만 이런 데이터는 비용도 크고, 유연하지 않다. 그래서 이 논문에서는 아래와 같은 의문을 품는다.
"굳이 사람이 라벨 안 달고, 이미지 옆에 있는 텍스트만 가지고 학습하면 안 될까?"
이미 20년 전부터 이미지와 텍스트를 함께 활용하려는 시도는 있었다.
- Mori et al. (1999): 이미지와 짝지어진 문서에서 명사와 형용사를 예측
- Quattoni et al. (2007): 이미지 캡션 예측을 통해 효율적인 이미지 표현 학습
- Joulin et al. (2016): 이미지의 해시태그·제목·설명을 단어로 예측시키는 CNN을 훈련해,ImageNet 사전학습에 버금가는 전이 학습 성능 확보
그리고 최근에는 더 강력한 모델들이 등장했다.
- VirTex: 텍스트 예측 기반 이미지 표현 학습
- ICMLM: 마스크 언어 모델링 방식
- ConVIRT: 대조 학습을 활용해 텍스트-이미지 간 표현 정렬
이처럼 텍스트와 이미지를 함께 학습하는 방식은 점점 발전하고 있으며,
자연어 기반의 감독 신호만으로도 강력한 비전 모델을 만들 수 있다는 가능성을 보여주고 있다.
(이제는 사람이 라벨 달지 않아도, 텍스트 설명만으로도 모델이
사진을 잘 알아봄)
모델의 학습 목표:
- 주어진 이미지에 가장 잘 어울리는 텍스트를 맞히는 것
- 복잡한 라벨 없이도, 이미지와 텍스트 사이의 의미적 연결을 학습
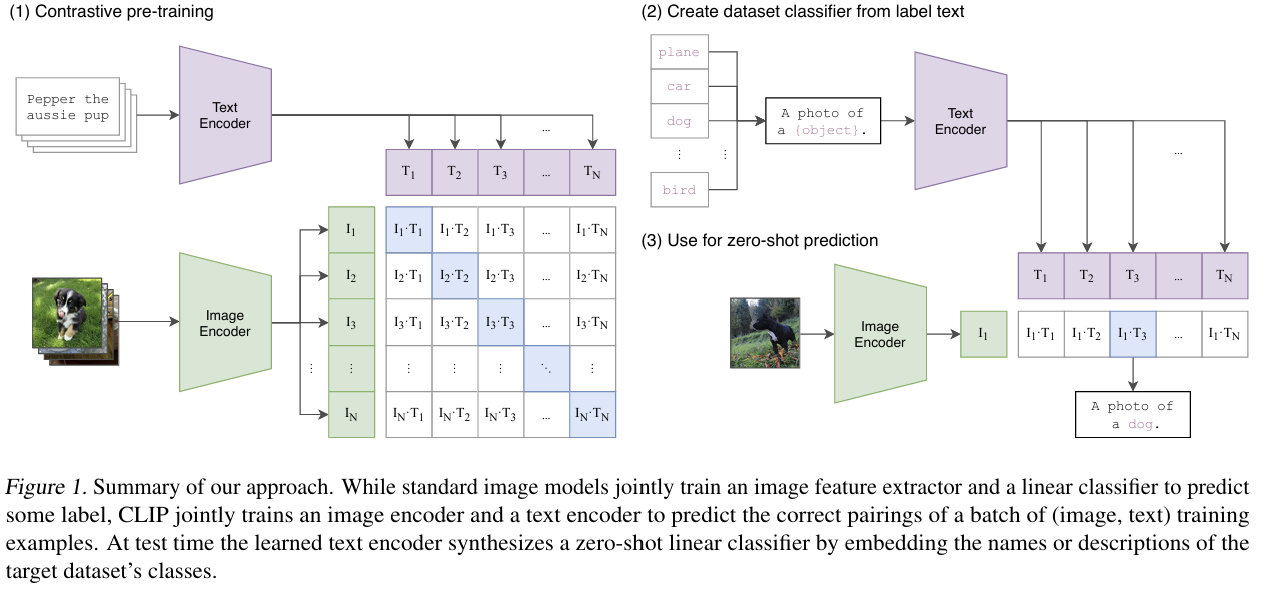
CLIP 모델의 전체 작동 원리
(1) Contrastive Pre-training: 이미지와 텍스트 쌍 맞추기
대조학습: 입력 데이터 간의 유사성과 비유사성을 학습하는 자기지도학습 기법
CLIP에서는 이미지와 텍스트를 각각 인코더에 통과시켜 얻은 벡터 간의 코사인 유사도를 기반으로, 실제 짝인 이미지-텍스트 쌍의 유사도는 높이고 다른 쌍과의 유사도는 낮추도록 학습한다.
(2) Create dataset classifier from label text: 텍스트로 분류 기준 만들기
- 우리가 쓰고 싶은 데이터셋의 라벨들 (예: dog, cat, bird...)
→ "A photo of a {object}" 형태로 템플릿 완성
(3) Use for zero-shot prediction
기존 자연어 기반 학습은 정확도가 매우 낮았다.
ex) Li et al. (2017)은 ImageNet 제로샷 설정에서 11.5%**의 정확도만을 기록
이에 반해 weak supervision 방식 (인스타그램 해시태그, 노이즈 섞인 대규모 라벨 데이터를 활용)은 성능을 눈에 띄게 끌어올린 바 있다.
하지만 이 방식들은 각각 1,000개와 18,291개 클래스처럼 감독 범위가 제한적이며,이들 모델은 전부 고정된 소프트맥스 분류기만을 사용해 동적인 출력이 불가능했고, 그로 인해 제로샷 성능과 유연성이 제한되었다.
여기서 CLIP의 결정적 차이점은 ‘규모’이다.
기존의 weak supervision방식도 꽤 성능이 좋긴 했지만,그 대부분은 수백만~수십억 장의 이미지만을 이용하거나, 클래스 수가 제한된 상태에서 학습되었다.
하지만 CLIP은 무려 4억 쌍의 이미지와 텍스트 데이터를 인터넷에서 수집해, 이미지와 자연어를 함께 학습할 수 있도록 모델 구조 자체를 새롭게 설계했다.
CLIP 특징
제로샷 능력
-> 훈련하지 않은 작업에서도 30개 이상의 데이터셋에서 기존 모델급 성능 달성
강력한 임베딩 표현력
-> 선형 분류기 하나만 붙여도 ImageNet SOTA 모델보다 더 높은 성능
강건함
-> 새로운 환경에서도 성능이 잘 무너지지 않음 → 실전 적용성 👍

💡 CLIP은 기존 방식 대비:
- BoW Prediction보다 3배 더 효율적
- Transformer 기반보다 4배 더 효율적
-> 같은 성능을 내려면 CLIP은 1/3~1/4만큼의 이미지 수만 필요하다.
2. Approach
2.1. Natural Language Supervision
기존 이미지 모델은 “강아지”, “고양이”처럼 사람이 직접 붙인 정답 라벨을 기반으로 학습했다.
하지만 CLIP은 라벨 대신 “A photo of a dog” 같은 자연어 문장을 그대로 학습 신호로 사용한다.
이 방식의 핵심은 별도의 라벨링 없이도 인터넷에 존재하는 이미지-텍스트 데이터를 그대로 활용할 수 있다는 점이다. 그래서 데이터 규모를 훨씬 쉽게 확장할 수 있고, 기존의 비지도·자기지도 학습 방식들을 하나의 “자연어 감독”이라는 개념으로 정리할 수 있다.
2.2. Creating a Sufficiently Large Dataset
CLIP이 기존 모델들과 차별화되는 가장 큰 이유 중 하나는 바로 데이터 규모다. 이전까지 자주 쓰이던 MS-COCO, Visual Genome 같은 고품질 이미지-텍스트 데이터셋은 각각 10만 장 수준으로, 요즘 딥러닝 모델을 훈련시키기엔 너무 작았다.
YFCC100M 같은 대규모 데이터셋도 있긴 하지만,텍스트 품질이 낮다는 한계가 있다.
따라서 “자연어 설명이 달린 이미지”만 추리면 실제 사용가능한 데이터는
고작 1,500만 장 수준으로 줄어든다 → ImageNet 수준임.
그래서 CLIP 팀은 아예 새로 만들었다. CLIP 연구진은 인터넷에서 공개된 다양한 소스로부터 4억 개의 이미지-텍스트 쌍을 직접 수집해서
WIT(WebImageText)라는 자체 데이터셋을 구축했다.
텍스트가 500,000개의 주요 단어 또는 바이그램 중 하나 이상을 포함
각 단어당 최대 2만 개의 샘플까지만 수집해 쏠림 현상 방지
-> 어떤 단어에 너무 많은 데이터가 몰리지 않도록 데이터 수집을 균형 있게 하려는 장치
이로써 다양한 시각 개념을 고르게 포함한 초대형 멀티모달 데이터셋을 완성했다.
2.3. Selecting an Efficient Pre-Training Method
기존 컴퓨터 비전 모델은 엄청난 연산을 쓰면서도, 겨우 1,000개의 ImageNet 클래스만 예측하도록 학습된다.
반면 CLIP은 자연어를 통해 훨씬 더 많은 개념을 배워야 하기 때문에, 학습 효율이 핵심 문제가 된다.
처음에는 VirTex처럼 이미지(CNN)와 텍스트(Transformer)를 함께 학습해, 이미지를 보고 설명 문장을 생성하는 방식이 시도됐다.
하지만 같은 이미지도 “a cute cat”, “sleepy pet”처럼 표현이 너무 다양해서,정확한 단어를 맞히는 방식은 확장성이 떨어졌다.
그래서 CLIP은 어떻게 바꿨나?
CLIP 연구진은
“텍스트의 정확한 단어를 맞히는” 대신, “어떤 텍스트가 어떤 이미지와 짝인지 전체적으로 맞히는” 더 간단한 대조 학습 과제로 방향을 전환했다.
→ "문장 맞히지 말고, 그냥 이미지랑 문장이 어울리는지만 학습하자!"
즉, 같은 Bag-of-Words 인코딩을 쓰되,
예측 목적(predictive objective) 대신 대조 목적(contrastive objective)으로 바꾸었다.
→ 그 결과?
ImageNet 제로샷 전이 성능이 4배 더 빨리 향상됨을 관찰했다.
🧩 CLIP의 대조 학습 방식 작동 방법
1. 학습 배치 구성
매 배치마다 N개의 이미지-텍스트 쌍이 들어감
가능한 쌍 조합은 N²개
진짜 정답 쌍은 단 N개뿐.
2. 학습 목표
이미지를 이미지 인코더에 넣고 → vᵢ라는 벡터로 바꾸고
텍스트는 텍스트 인코더에 넣어서 → tᵢ라는 벡터로 바꿈
이제 vᵢ, tᵢ 사이의 코사인 유사도(cosine similarity)를 계산해서
정답쌍(v₁, t₁)은 유사도 높게!
오답쌍(v₁, t₂)은 유사도 낮게!
되도록 인코더 파라미터를 학습시킴.
즉, 같은 의미를 가진 이미지와 텍스트는 가까운 벡터로
의미가 다른 쌍은 서로 멀리 떨어지게 인코더를 훈련시킴.
3. 손실 함수 (Loss)
대칭적인 Cross-Entropy Loss 사용
-> 정답 쌍의 유사도는 높이고, 나머지는 낮추도록 Cross-Entropy Loss가 훈련 유도
두 방향 모두 학습:
이미지 → 텍스트: 주어진 이미지가 어떤 텍스트와 가장 잘 어울리는지
텍스트 → 이미지: 주어진 텍스트가 어떤 이미지와 가장 잘 어울리는지
CLIP이 대칭적인 손실 함수를 사용하는 이유는 이미지와 텍스트 간의 양방향 의미 정렬을 동시에 학습하기 위해서이다. 이미지로부터 텍스트를 맞추는 것뿐 아니라, 텍스트로부터 이미지를 맞추는 과정도 함께 학습함으로써 두 인코더가 균형 있게 훈련되고, 멀티모달 임베딩 공간의 정합성과 일반화 성능이 향상된다
CLIP은 대규모 데이터셋을 사용하므로 과적합 문제가 크지 않으므로 구현 자체는 이전 연구들보다 오히려 간단하게 구성되었다:
🧩 CLIP의 구현 방식
- 사전학습 X: 이미지 인코더와 텍스트 인코더 모두 처음부터 학습
- 데이터가 워낙 많아서 처음부터 학습해도 충분히 좋은 성능을 낼 수 있음 → 특정 태스크에 종속되지 않는 범용성 유지!
-
선형 프로젝션만 사용: 비선형 projection head 제거
→ 단순하게 이미지나 문장을 선형 변환(linear transform)만 해도 충분히 표현력이 나온다는 걸 실험으로 확인함
→ 구조를 단순화시켜서 훈련 속도, 해석 가능성, 확장성까지 챙김 -
문장 샘플링 생략: 대부분 데이터가 한 문장으로 구성되어 있어 변형 함수 제거
-
간단한 이미지 증강: 무작위 크롭 하나만 사용
→ 학습 데이터 자체가 다양하기 때문에,
→ 과도한 증강 없이도 일반화 성능 확보 가능 -
온도 파라미터도 학습함: softmax 스케일 조절용 파라미터를 직접 최적화
-
값이 작을수록 예측이 더 확신에 차게(sharp) 나오고
-
값이 크면 더 부드럽게(soft) 나옴
→ 데이터의 다양성과 난이도에 맞게
→ 자동으로 최적의 softmax 분포 스케일링을 하게끔 만들어줌
2.4. Choosing and Scaling a Model(모델 구조)
CLIP은 이중 인코더구조로 구성된다. 이미지와 텍스트를 각각 독립적인 인코더를 통해 처리하지만,
결과 임베딩은 같은 차원의 공통 공간에 매핑된다.
🖼️ 이미지 인코더 (Image Encoder)
(1)ResNet-50 기반 아키텍처
널리 사용되고 성능이 검증된 ResNet-50을 기본 구조로 채택했다.
다음과 같은 몇 가지 개선을 적용함:
-
ResNet-D 개선 + blur pooling 적용
-> ResNet-D 구조로 변경함, 작은 성능 향상과 일반화 개선. blur pooling은 왜곡을 줄여 더 깔끔한 특징 추출 가능. -
Global Average Pooling 레이어를 제거하고, 대신 Attention Pooling 사용
-> 이미지의 중요한 부분을 스스로 집중(attend)하도록 만들어서, 더 정교한 표현이 가능함.
→ 이 Attention Pooling은 transformer 스타일의 multi-head QKV attention 한 층으로 구현되며, 쿼리(query)는 이미지의 전역 평균 풀링 결과를 기반으로 생성됨.
(2) Vision Transformer (ViT)**
최근 도입된 Vision Transformer를 실험적으로 사용함.
-> CNN 외에도 Transformer 구조의 가능성을 비교 평가하기 위함. 최근 비전 분야에서 ViT가 부상 중
원래 구현을 대부분 그대로 따르되, 다음과 같은 약간의 수정 적용:
패치와 위치 임베딩을 합치기 전에 LayerNorm을 추가 -> 학습 안정성
초기화 방식도 약간 다르게 적용
📌 ViT는 CNN처럼 지역 정보를 중심으로 보지 않고,
문맥 전체를 보면서 어떤 패치가 중요한지를 판단할 수 있어.
그래서 더 추상적이고 유연한 표현을 만들 수 있다.
✏️ 텍스트 인코더: Transformer 기반
Transformer 구조를 사용하며, Radford et al. (2019)에서 제안된 구조 변경사항들을 따름.
기본 모델 크기는
🔹 레이어 12개, hidden size 512, 헤드 수 8개 → 총 파라미터 약 6,300만 개
🔹 입력 문장은 소문자 + BPE(Byte Pair Encoding)으로 토크나이즈
→ 희귀한 단어도 subword로 쪼개서 커버 가능
→ 어휘집 크기: 49,152개
🔹 입력 문장에는 [SOS], [EOS] 토큰이 붙음
→ 문장의 시작과 끝 표시
🔹 Transformer의 마지막 층에서 [EOS] 위치 벡터를 문장의 대표 벡터로 사용함
→ 이 벡터가 텍스트 인코더의 최종 출력
-> 문장 전체를 하나의 벡터로 요약할 때, Transformer가 마지막에 뱉는 출력 중 '문장의 끝([EOS])' 위치 벡터를 대표값으로 쓴다는 뜻
Masked Self-Attention을 사용하여,
나중에 사전학습된 언어 모델로 초기화하거나, 언어 모델링을 보조 목표로 추가할 수 있게 구조 설계됨 (하지만 본 논문에서는 이건 실험하지 않음)
이미지 인코더와 텍스트 인코더의 출력은 각각 선형변환을 통해 같은 512차원 공간으로 변환됨
✅ 왜 Transformer 구조?
→ 자연어 처리에서 가장 강력한 구조로 자리잡음. 문맥 이해에 최적.
✅ 왜 BPE 사용?
→ 희귀 단어도 sub-word 단위로 분해해 표현 가능. 단어 수를 줄이면서 커버리지는 유지.
✅ 왜 시퀀스 길이 제한 76?
→ 대부분 이미지 캡션은 한두 문장. 긴 시퀀스가 거의 없으므로 계산 자원 낭비를 줄임.
✅ [EOS] 위치 사용 이유?
→ 문장의 끝을 가장 잘 요약하는 위치로 간주됨. Transformer의 일반적인 표현 방식.
✅ Masked self-attention 유지 이유?
→ 향후 언어모델 초기화나 언어 모델링을 추가할 수 있는 확장성을 확보하기 위함.
모델 확장 방법
기존 컴퓨터 비전 연구에서는 주로 너비 또는 깊이 한 방향만 키우는 방식이 일반적이었다.
하지만 이 모델은 너비, 깊이, 해상도 모두에 균형 있게 연산량을 배분하는 방법을 채택했다.-> 단순하게 3요소를 동일하게 늘리는 기준선 방식을 사용
텍스트 인코더는 이미지 인코더의 너비 증가 비율에 맞춰 너비만 증가시켰고, 깊이는 그대로 유지
→ 실험 결과, 텍스트 인코더는 용량 변화에 성능이 크게 민감하지 않음 : 자원 절약!
2.5. Training
CLIP을 훈련시키기 위해 OpenAI는 5개의 ResNet과 3개의 Vision Transformer(ViT) 모델을 활용했다.
이들은 단순한 백본이 아니라, 효율성과 성능을 극대화하기 위해 여러 스케일 조정이 들어간 모델들
ResNet-50
- RN50x4, RN50x16, RN50x64
ViT 계열
-ViT-B/32, ViT-B/16, ViT-L/14
모든 모델은 32 에폭 학습
학습 세팅 요약:
최적화 알고리즘: Adam Optimizer 사용
가중치 감쇠(정규화): 편향 및 scale 계수 이외의 모든 파라미터에 decoupled weight decay 적용
러닝레이트 스케줄러: Cosine Annealing 스케줄 사용 (
초기 하이퍼파라미터 설정:
ResNet-50 기준으로 grid search, random search, 수동 튜닝을 통해 1 epoch 기준 세팅
이후 더 큰 모델에는 계산 제약을 고려해 휴리스틱하게 조정
학습 가능한 온도(temperature) 파라미터:
초기값은 0.07, logit이 과하게 커지지 않도록 최대 100으로 클리핑
효율적인 학습을 위한 기법들:
배치 크기: 32,768이라는 초대형 미니배치 사용
메모리 최적화:
Mixed-precision 학습 사용
Gradient checkpointing 적용
Half-precision Adam 통계 및 half-precision으로 확률적으로 반올림된 텍스트 인코더 가중치 사용
임베딩 유사도 계산: 각 GPU가 자기 배치에 필요한 부분만 계산하는 식으로 분산(Sharding) 처리
⏱️학습 시간:
가장 큰 ResNet (RN50x64) 모델은 592개의 V100 GPU로 18일간 학습
가장 큰 ViT (ViT-L/14) 모델은 256개의 V100 GPU로 12일간 학습
ViT-L/14는 336 픽셀 고해상도로 추가 1 epoch 학습해 성능 향상을 꾀했으며
이 모델은 ViT-L/14@336px로 명명됨
3. Experiments
3.1. Zero-Shot Transfer
3.1.1. MOTIVATION
컴퓨터 비전 분야에서 제로샷 러닝(Zero-Shot Learning)은 일반적으로 이미지 분류에서 보지 못한 클래스(객체 범주)에 일반화하는 것을 의미한다. 하지만 우리는 이 용어를 더 넓은 의미로 사용해서, 보지 못한 데이터셋에 대한 일반화로 정의한다.
우리는 이걸 "보지 못한 작업"을 수행하는 간접 지표로 간주한다.
많은 비지도 학습 연구들이 모델의 표현 학습 능력에 집중하고 있지만, 우리는 제로샷 전이(transfer)를 통해 모델의 작업 학습(task learning) 능력을 평가하고자 한다.
이런 관점에서 보면, 하나의 데이터셋은 특정 분포에서 특정 작업에 대한 성능을 평가하는 수단이 된다.
기존의 이미지 분류 벤치마크들(CIFAR-10, ImageNet 등)은 대부분
"실제 작업을 측정하려는 목적"보다는 "알고리즘 성능을 비교하려고 만든 실험용 데이터셋"이 많다.
- SVHN
→ "Google Street View 사진에서 집 주소 숫자 읽기"
-> 명확- CIFAR-10
→ 분포는 TinyImage지만, 실용성은 애매.
그래서 CLIP 연구진은
CLIP이 진짜 강한 모델이라면, 다양한 데이터셋에서도 적응을 잘 해야 한다!
즉, 분포 변화(distribution shift)나 도메인 변화(domain generalization)에 얼마나 강한지가 중요하다!
라고 말한다.
과거의 유사 시도: Visual N-Grams
CLIP 이전에도 사전학습 기반 제로샷 분류 시도는 존재했다. 대표적으로 Visual N-Grams은 14만 개 이상의 시각적 n-gram을 기반으로 이미지와 텍스트 간 확률을 계산하여 분류를 수행했다. 다만, 적용 가능성 및 범용성 측면에서는 한계가 있었다.
자연어처리(NLP) 분야에서는 이러한 방식이 이미 익숙한 개념
Liu et al.은 위키백과로 사전학습한 모델이 이름의 음역을 자연스럽게 수행하는 현상을 관찰했다.
GPT-1, GPT-2는 이러한 현상을 정식으로 연구하며, 사전학습 기반의 제로샷 추론 능력이 사전지식만으로도 나타날 수 있음을 보여주었습니다.
CLIP은 이러한 NLP 기반 제로샷 학습 전략을 비전 분야에 도입하여,
"이미지-텍스트 대조학습을 통해 제로샷 능력을 효과적으로 획득할 수 있는가?를 핵심 질문으로 실험을 설계한 것이다.
3.1.2. USING CLIP FOR ZERO-SHOT TRANSFER
CLIP은 이미지와 텍스트 조각이 서로 짝이 맞는지 예측하도록 사전학습되어 있다.
이러한 능력을 제로샷 분류에도 그대로 활용한다.
즉, 각 데이터셋에서 클래스들의 이름을 가능한 텍스트 조합으로 간주하고, (이미지, 텍스트) 쌍 중에서 가장 가능성이 높은 조합을 CLIP이 예측하도록 한다.
좀 더 구체적으로 설명하면 다음과 같다:
먼저 이미지 인코더와 텍스트 인코더를 이용해
각각 이미지와 클래스 이름 텍스트들의 임베딩(embedding)을 구한다.
이후 이 임베딩들 사이의 코사인 유사도(cosine similarity)를 계산한다.
이 유사도 값은 온도 파라미터(temperature)로 스케일링되고,
소프트맥스(softmax)를 통해 확률 분포로 변환된다.
💡 참고로 이 과정을 수학적으로 보면,
입력과 가중치를 L2 정규화하고, 바이어스 없이, 온도 조절만 들어간
→ 멀티클래스 로지스틱 회귀 분류기(multinomial logistic regression)로 볼 수 있다.
예측 확률 = softmax(입력 벡터 × 클래스 가중치 벡터 + bias)
예측 확률 = softmax( (이미지 벡터 • 텍스트 벡터) / T )
이 관점에서 보면,
이미지 인코더는 비전 백본 역할을 하며, 이미지의 피처를 계산하고
텍스트 인코더는 일종의 하이퍼네트워크처럼 작동해서,
주어진 텍스트(클래스 이름)에 따라 분류기의 가중치를 생성해주는 역할을 한다.
이 해석을 바탕으로 보면,
CLIP의 사전학습 과정은 마치 가상의 비전 데이터셋(클래스 32,768개, 각 클래스당 예시 1개, 자연어로 정의됨)을
무작위로 만들어서 여기에 대해 성능을 최적화하는 것과 유사하다.
👉 제로샷 평가를 할 때는,
이렇게 생성된 제로샷 분류기(텍스트 인코더로 만든)를 한 번 계산해두고,이후에는 이걸 캐시해서 전체 예측에 재사용한다.
→ 덕분에 계산 비용을 데이터셋 전체로 나눌 수 있어서 효율적이다.
3.1.3. INITIAL COMPARISON TO VISUAL N-GRAMS
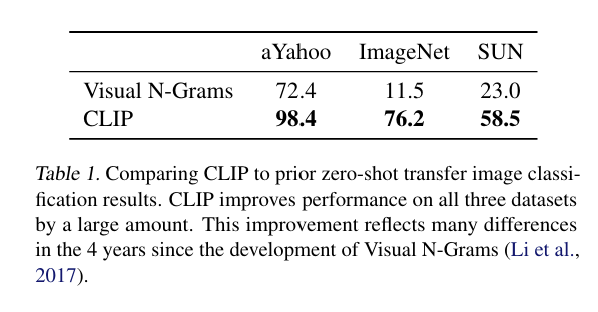
표 1에서는 Visual N-Grams와 CLIP의 성능을 비교한다.
CLIP의 최고 성능 모델은 ImageNet 정확도를 11.5% → 76.2%까지 올렸다.
이는 CLIP이 ImageNet에서 레이블 없이도 ResNet-50의 성능을 따라잡았다는 의미다.
💡 이런 결과는 CLIP이 제로샷(Zero-shot) 상황에서도 강력한 성능을 발휘하며, 유연하고 실용적인 비전 분류기로서 유의미한 진보임을 시사한다.
CLIP과 Visual N-Grams를 비교하는 건 맥락을 설명하기 위한 것이지,두 모델을 완전히 동일 조건으로 비교한 건 아니다
CLIP은 10배 더 큰 데이터셋에서 학습했고,
예측당 연산량도 100배,
전체 학습 연산량은 1000배 이상이며,
Transformer 기반 모델을 사용함 (Visual N-Grams가 나왔을 땐 이 기술 없음)
그래서 공정한 비교를 위해, Visual N-Grams가 사용한 YFCC100M 데이터셋에서 CLIP ResNet-50을 동일하게 학습시켜봤다.
결과적으로, 하루도 안 되는 시간 안에 Visual N-Grams의 ImageNet 성능을 달성했다.
심지어 이 CLIP 모델은 ImageNet 사전학습 없이 처음부터 학습된 것이다.(반면, Visual N-Grams는 ImageNet으로 사전학습된 모델을 사용함)
CLIP은 Visual N-Grams가 보고한 나머지 두 개의 데이터셋에서도 성능이 훨씬 좋다:
- aYahoo: CLIP이 에러 수를 95% 줄임
- SUN: CLIP 정확도는 Visual N-Grams보다 2배 이상 높음
3.1.4. PROMPT ENGINEERING AND ENSEMBLING
일반적인 이미지 분류 데이터셋은 클래스 이름이나 설명과 같은 자연어 기반 제로샷 전이에 필요한 정보를 부차적인 요소로 다루는 경우가 많다.
대부분의 데이터셋은 단지 클래스의 숫자 ID만 부여하고, 이 숫자를 영어 이름으로 매핑한 별도의 파일만 제공한다.
일부 데이터셋(예: Flowers102, GTSRB)은 이 매핑 파일조차 제공하지 않아 제로샷 전이 자체가 불가능한 경우도 있다.
또한, 클래스 이름 자체가 임의로 정해진 경우도 있어서,
‘작업(task) 설명’에 의존하는 제로샷 전이에서는 혼란이 생길 수 있다.
📌 문제 1: 동음이의어(polysemy)
클래스 이름만 CLIP의 텍스트 인코더에 넣으면 어떤 의미의 단어인지 구분하기 어렵다.
예시:
ImageNet에선 "crane"이 건설기계(크레인)와 새(두루미) 두 클래스 모두 존재
Oxford-IIIT Pet에서는 "boxer"가 개 품종이지만, 사람일 수도 있음 (복싱 선수)
📌 문제 2: 단어 vs 문장
CLIP의 학습 데이터에서는 이미지와 짝지어진 텍스트 대부분이 '문장'이었다.
그런데 테스트할 땐 단일 단어(예: “cat”, “apple”)만 입력하면 학습-테스트 분포 차이가 발생한다.
그래서 "A photo of a [label]."처럼 프롬프트 템플릿을 써주면
텍스트가 이미지 내용 설명임을 명확히 해줘서 성능이 개선됨.
-> ImageNet에서 이 프롬프트 하나만 추가해도 정확도 1.3% 향상
GPT-3에서 그랬듯이, CLIP도 프롬프트 문장을 데이터셋에 맞게 맞춰주면 성능이 꽤 좋아진다!
예시:
Oxford-IIIT Pets: "A photo of a [label], a type of pet."
Food101: "A photo of a [label], a type of food."
FGVC Aircraft: "A photo of a [label], a type of aircraft."
OCR 데이터셋: "‘[label]’" ← 인식할 단어나 숫자를 따옴표로 감싸기
위성 이미지: "A satellite photo of a [label]."
🔁 앙상블
성능 향상을 위해 여러 프롬프트 버전을 이용한 제로샷 분류기 앙상블도 시도했다.
"A photo of a big [label]."
"A photo of a small [label]."
등 다양한 문장으로 텍스트 임베딩을 여러 개 만들고 평균
🔑 포인트는 확률이 아닌 임베딩 공간에서 앙상블했다는 점!
→ 이렇게 하면 텍스트 임베딩을 미리 캐시해두고, 여러 예측에 재활용 가능함
→ 성능은 향상되지만 연산량은 그대로 유지!
확률에서 앙상블
→ 여러 모델의 출력 확률을 평균 내거나 합쳐서 예측하는 방식
→ 예: 모델 A: 고양이 60%, 개 40% / 모델 B: 고양이 70%, 개 30%
→ 평균: 고양이 65%, 개 35%임베딩 공간에서 앙상블
→ 확률 계산 전에, 각 이미지나 텍스트의 벡터(임베딩)를 평균해서 하나의 벡터를 만들고,
그걸로 예측을 함.
→ 즉, softmax 전에 벡터 수준에서 앙상블하는 것
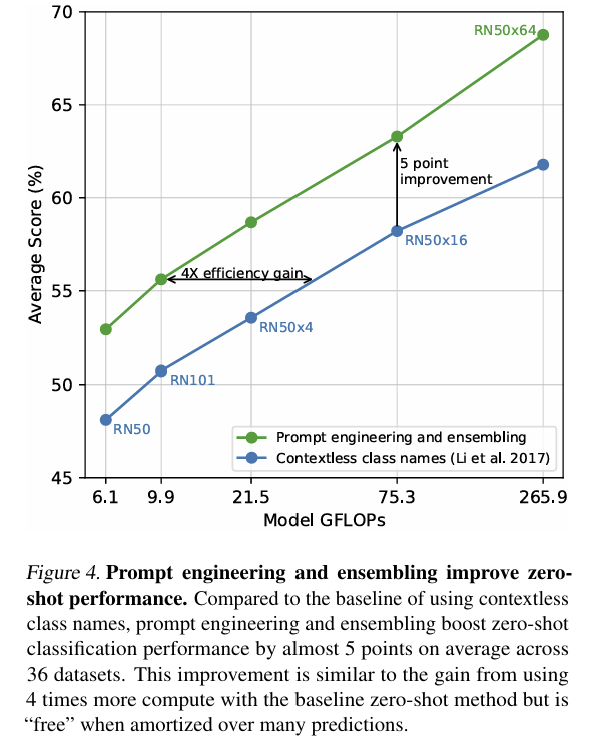
ImageNet 기준으로는 80개의 프롬프트를 앙상블해서
기본 프롬프트보다 정확도 3.5% 추가 향상됨.
종합적으로 보면, 프롬프트 엔지니어링 + 앙상블을 함께 사용하면
ImageNet 정확도가 거의 5% 향상됨!
\
