논문리뷰
1.[논문리뷰] Learning Transferable Visual Models From Natural Language Supervision

논문 읽기 전 알아둬야 할 개념 🔍대조학습 > 주어진 데이터에서 서로 유사한 샘플(positive pair)은 임베딩 공간상에서 가깝게, 서로 다른 샘플(negative pair)은 멀어지도록 학습하는 방법 | 용어 | 설명
2.RNN 개념
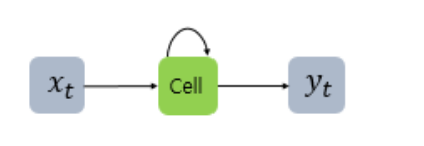
과거 정보를 기억하면서 순서 있는 데이터를 처리하는 신경망 모델이다시계열 데이터를 처리하기에 좋은 뉴럴 네트워크 구조RNN은 내부적으로 메모리 기능을 갖추고 있어 과거 데이터를 저장하고 필요에 따라 활용할 수 있다. 또한 이를 통해 시퀀스 내에 패턴을 인식하고 미래를
3.RNN 코드(데이콘)

파이토치 통한 RNNcell 구현 RNN 클래스구현과 Sequence 데이터 처리 1. MyRNNcell 클래스 구현하기 2.MyRNNcell 인스턴스를 통한 새로운 은닉 상태 계산 3.시퀀스 데이터 처리를 위한 MyRNN 클래스 구현 | 기능 | MyRNNcell | MyRNN | | ...
4.[논문리뷰] BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models
0. Abstract BLIP-2는 비전-언어 사전학습의 높은 비용 문제를 해결하기 위해 제안된 효율적인 전략으로, 사전학습된 이미지 인코더와 대형 언어 모델을 얼려둔 상태로 활용하고, 이 둘을 연결하는 가벼운 쿼리 트랜스포머만 학습한다. 이 트랜스포머는 두 단계로
5.[논문리뷰] BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
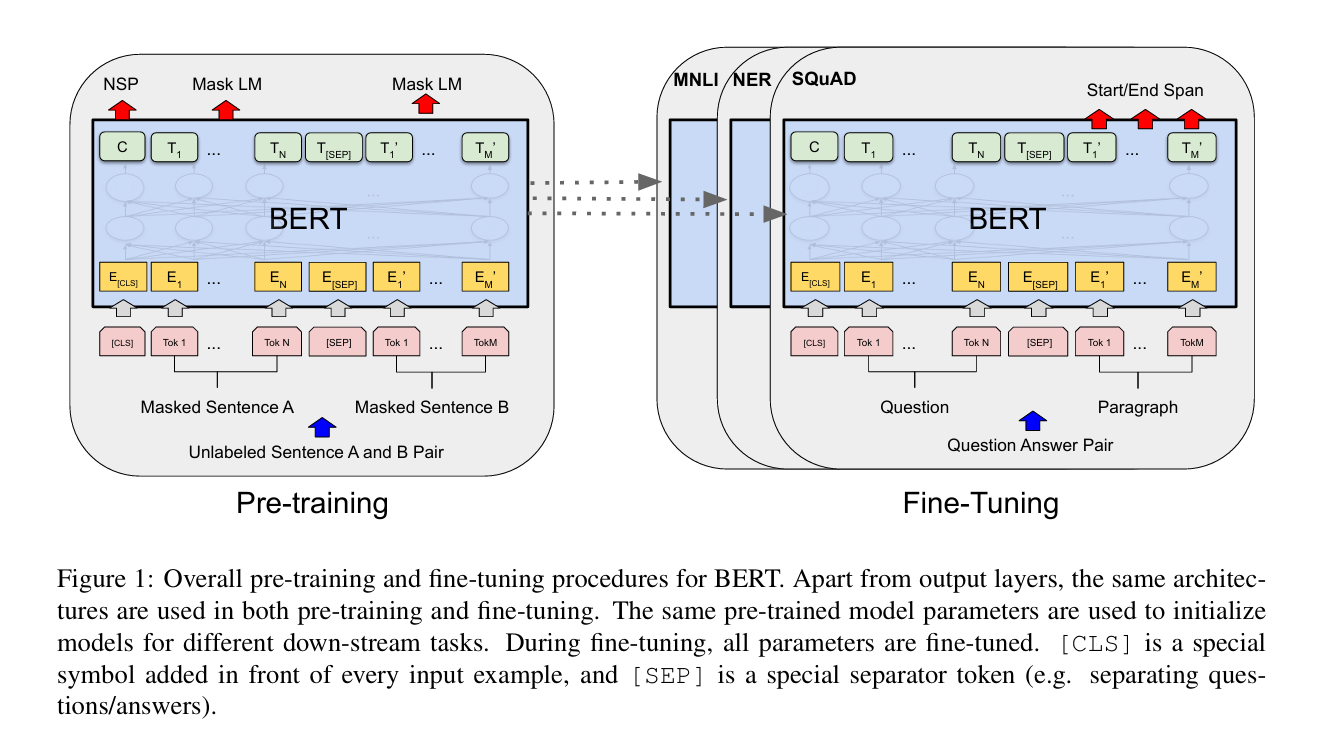
이 논문에서는 BERT라 불리는 새로운 언어 표현 모델을 소개한다. BERT는 모든 층에서 좌우 문맥을 공동으로 조건화함으로써 비지도 학습 기반의 깊은 양방향 표현을 사전 학습하도록 설계되었다.그 결과, 사전 학습된 BERT 모델은 단 하나의 추가 출력 층만으로도 다양
6.[논문리뷰] Alpaca: A Strong, Replicable Instruction-Following Model
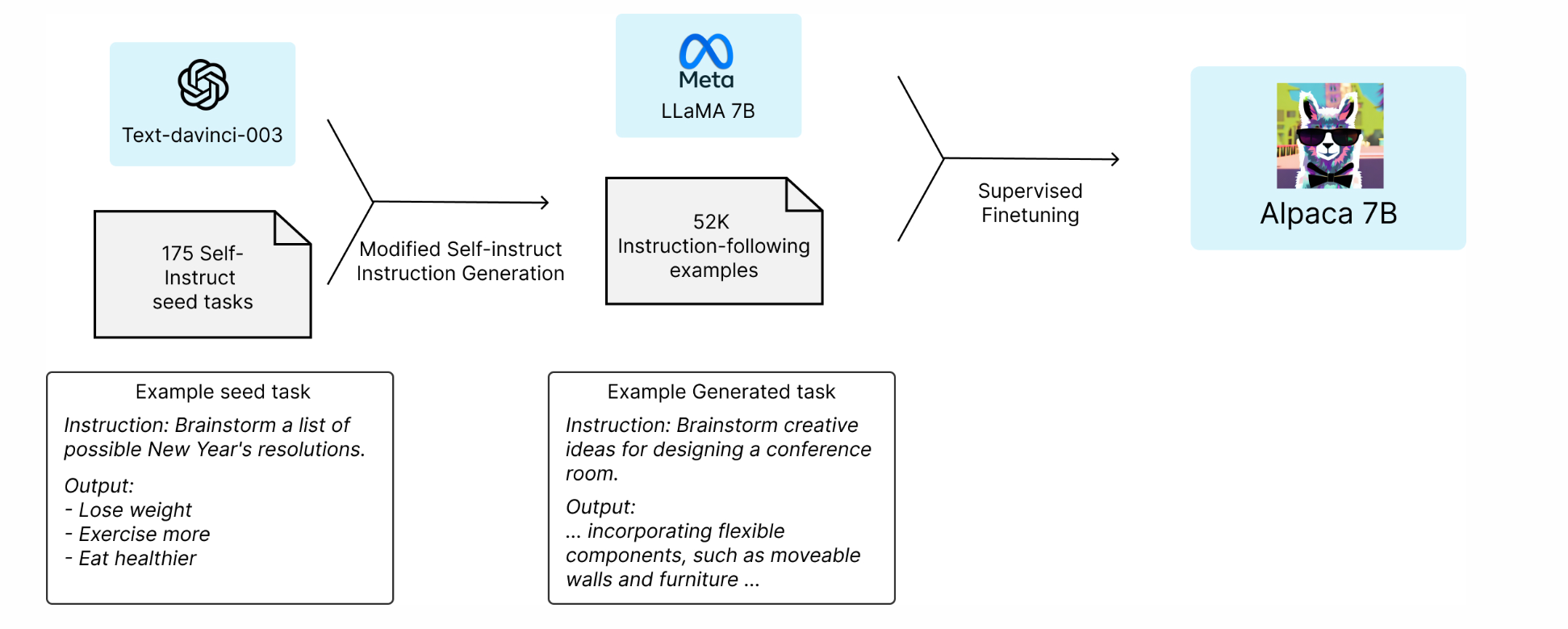
Instruction-following 모델:단순히 다음 단어 예측이 아니라, 사람의 의도를 파악하려고 학습됨.예: “이 문장을 한국어로 번역해줘” → 번역 결과를 출력.즉, 사람의 지시를 task로 이해하고 수행.instruction-following 모델(ex: G
7.[논문리뷰] Finetuned Language Models Are Zero-Shot Learners
0. ABSTRACT 이 논문은 언어 모델의 제로샷 학습 능력을 향상시키는 간단한 방법을 탐구한다. 이 논문은 instruction tuning(지시문 튜닝) — 즉, 여러 데이터셋을지시문을 통해 파인튜닝하는 방식 — 이 보지 못한 과제들에 대한 제로샷 성능을 크게
8.[논문리뷰] SELF-CONSISTENCY IMPROVES CHAIN OF THOUGHT REASONING IN LANGUAGE MODELS
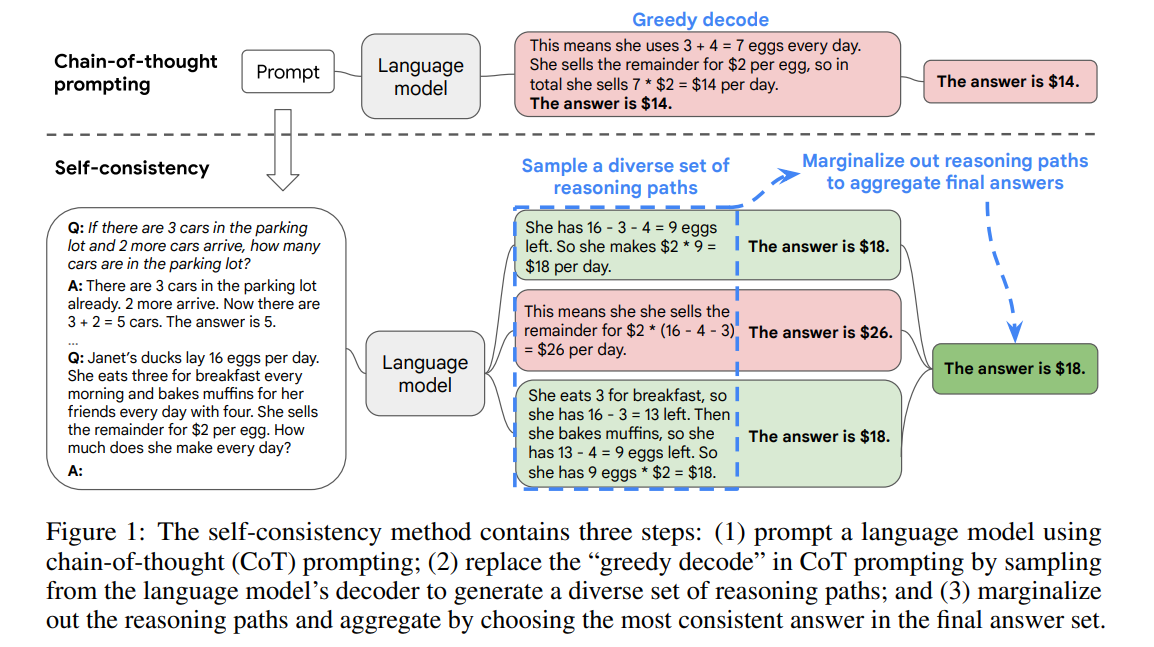
Chain-of-Thought 프롬프트는 복잡한 추론 문제에서 LLM의 성능을 높이지만, 일반적으로 greedy 디코딩만 사용해 하나의 추론 경로만 생성한다는 한계가 있음.이를 해결하기 위해 본 논문에서는 Self-Consistency 디코딩 전략을 제안함.이는 아래와
9.[논문리뷰] Attention Is All You Need
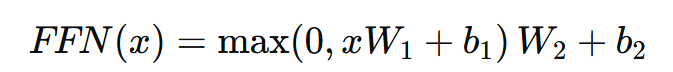
0. ABSTRACT 기존의 시퀀스 변환 모델들은 RNN/CNN 기반이며 인코더–디코더 구조를 가짐. 이러한 구조는 계산이 느리고 병렬화가 어렵다는 한계가 있다. 따라서 본 논문에서는 이를 해결하기 위해 RNN·CNN 제거하고 오직 Attention만 사용하는 Tran
10.[논문리뷰] LORA: LOW-RANK ADAPTATION OF LARGE LAN GUAGE MODELS
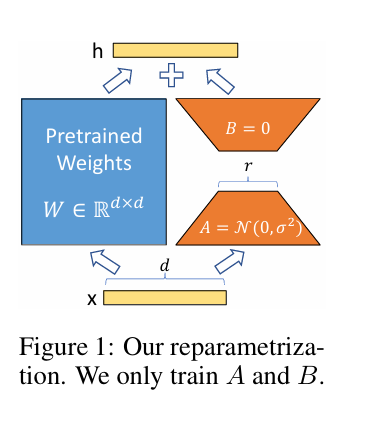
대규모 일반 도메인 데이터로 사전학습을 하고, 특정 작업이나 도메인에 맞게 적응시키는 것은 자연어 처리의 중요한 패러다임이다. 그러나 더 큰 모델을 사전학습할수록, 모든 모델 파라미터를 다시 학습시키는 전체 파인튜닝 방식은 점점 실용성이 떨어진다. 이를 해결하기 위해
11.[논문리뷰] ReWOO:Decoupling Reasoning from Observations for Efficient Augmented Language Models

🔴 기존 ALM 문제ALM이란?: LLM이 외부 도구를 자율적으로 호출하고 그 결과를 바탕으로 반복적으로 의사결정을 수행하는 모델추론 ↔ 도구 호출을 번갈아 수행매번 전체 토큰 히스토리를 다시 참고\-> 토큰 낭비 + 계산 비용 폭증🟢 ReWOO 핵심 아이디어Re