0. Abstract
🔴 기존 ALM 문제
ALM이란?
: LLM이 외부 도구를 자율적으로 호출하고 그 결과를 바탕으로 반복적으로 의사결정을 수행하는 모델
- 추론 ↔ 도구 호출을 번갈아 수행
- 매번 전체 토큰 히스토리를 다시 참고
-> 토큰 낭비 + 계산 비용 폭증
🟢 ReWOO 핵심 아이디어
- Reasoning과 Observation을 완전히 분리
- 먼저 생각만 다 하고 나중에 필요한 도구 결과를 한 번에 처리
성능 결과
- HotpotQA 기준 토큰 사용량 5배 절감
- 정확도 +4%
- 도구 실패 상황에서도 성능 안정적
- 추론을 큰 모델에서 작은 모델로 이전 가능
-> ALM을 가볍고 싸고 빠르게 만들 수 있음
1 Introduction
최근 LLM을 외부 플러그인이나 도구와 결합하여,LLM이 환경과 상호작용하고 최신 지식을 검색할 수 있도록 하는 패러다임이 주목받고 있다. -> ALM
기존 ALM의 한계
언어적 추론과 도구 호출을 번갈아 수행
- LLM의 빈번한 실행과 중단
- LLM은 이전 컨텍스트에 조건부로 토큰을 생성하기 때문에 외부 도구와 상호작용할 경우, LLM은 도구의 응답을 기다리기 위해 실행이 중단
- 막대한 토큰 소비 비용
- 블랙박스 LLM API는 상태를 저장하지 않는 구조이므로,
토큰 생성을 다시 시작하려면 컨텍스트 프롬프트,예시,이전의 모든 추론 과정,관측 결과를 전부 다시 입력
[Context + Exemplars + Question]
→ Thought₁ → Action₁ → Observation₁
→ (전부 다시 입력)
→ Thought₂ → Action₂ → Observation₂
→ (전부 다시 입력)
→ ...
이런 한계를 해결하기 위해 등장한게 ReWOO

ReWOO는 ALM의 핵심 구성 요소인 단계적 추론, 도구 호출,요약
을 세 개의 독립된 모듈로 분리한다
Planner: 하나의 작업을 여러 단계로 분해하고, 서로 의존적인 계획들로 구성된 청사진을 만든다. 각 계획은 Worker에게 할당된다.
Worker: 외부 도구를 사용해 해당 계획에 필요한 외부 지식과 증거를 수집한다.
Solver: 모든 계획과 증거를 종합하여초기 질문에 대한 최종 답변을 생성한다.
1. Planner:
[Context + Exemplars + Question]
→ Plan₁, Plan₂, … Planₖ
2. Worker:
도구 호출해서 E₁, E₂, … Eₖ 채움
3. Solver:
[Context + Question + (Plan₁+E₁)+…+(Planₖ+Eₖ)]
→ Answer
기존 ALM은 “보고 → 생각 → 또 보고 → 또 생각” ReWOO는 “생각 다 하고 → 보고 → 정리”
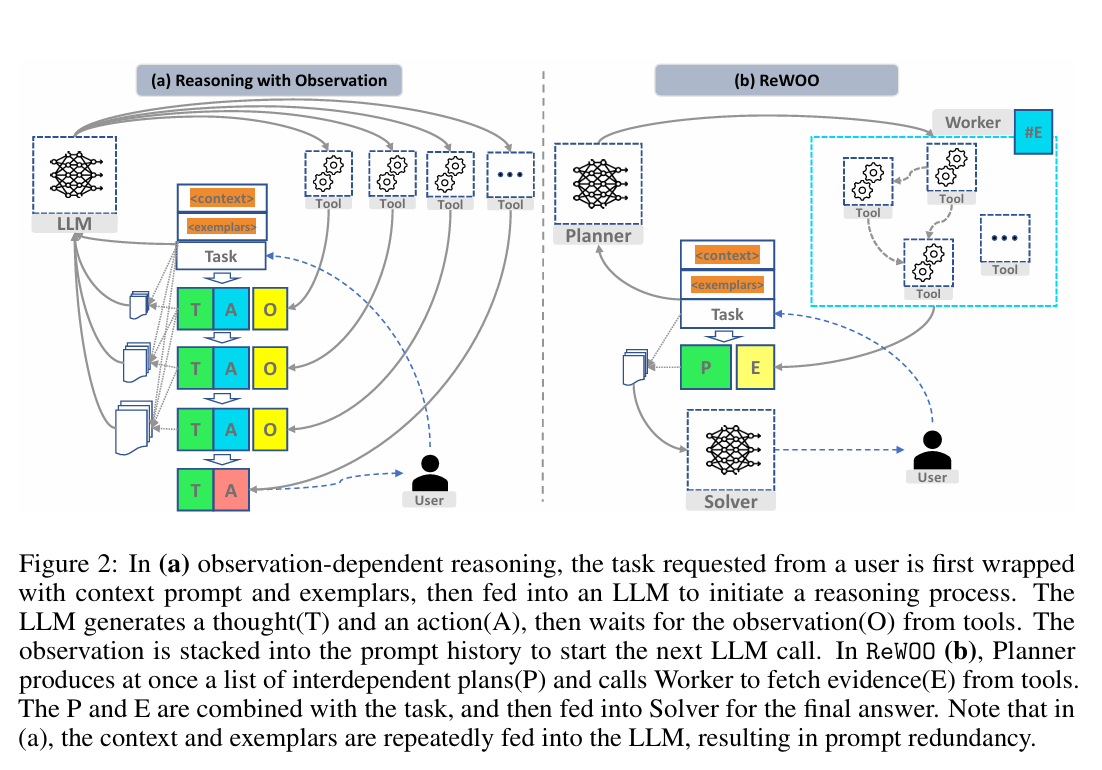
ReWOO는 LLM의 추론 과정과 외부 도구 사용을 분리
-> 관측에 의존하는 추론 방식에서 발생하는 프롬프트의 반복적 중복을 피할 수 있으며, 그 결과 토큰 사용량을 크게 줄이고 프롬프팅 효율을 향상
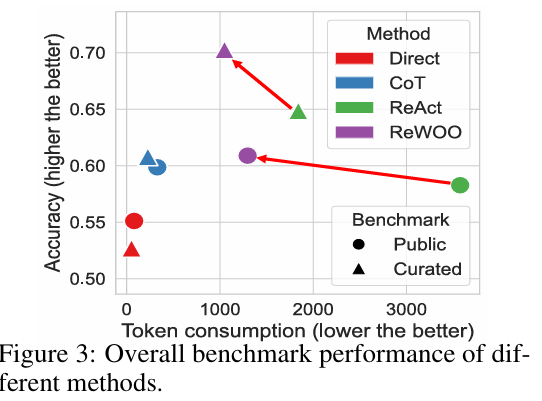
ReWOO를 종합적으로 평가하기 위해, 6개의 다단계·지식 집약적 NLP 벤치마크, 그리고 하나의 자체 구축 데이터셋에서 실험을 수행
ReWOO의 비교 기준:
- Direct Prompting (비-ALM 방식)
- Chain-of-Thought(CoT) 프롬프팅 (비-ALM 방식)
- ReAct (관측 기반 추론을 사용하는 대표적인 ALM 방식)
ReWOO가 관측 기반 추론 방식 대비 일관된 효율성 향상을 달성했음을 보여준다.
또한 instruction tuning과 specialization을 통해 ReWOO가 시스템 파라미터 효율성 측면에서도 큰 잠재력을 가짐을 입증했다.
실험 결과,소수의 에폭만 fine-tuning한 LLaMA 7B 모델이 zero-shot 설정에서 GPT-3.5와 대등한 성능을 보였으며, 이는 ReWOO가 가볍고 확장 가능한 ALM 배포를 가능하게 함을 보여준다.
ReWOO의 핵심 기여
① Foreseeable Reasoning 규명
- LLM은 도구의 관측 없이도 필요한 정보와 해결 단계를 미리 계획하는 추론 능력을 가짐 이를 foreseeable reasoning이라 정의
② ReWOO 모듈형 ALM 프레임워크 제안
- Planner / Worker / Solver 구조로 추론과 도구 호출을 완전히 분리
③ 추론 능력의 소형 모델 Offloading
- 대형 LLM의 foreseeable reasoning 능력을 소형 언어 모델로 이전-> LLaMA 7B가 GPT-3.5 수준의 성능 달성 (zero-shot), 소형 모델도 보지 못한 도구를 zero-shot으로 활용 가능
2 Methodology
2.1 ReWOOwithPlan-Work-Solve Paradigm
Planner
- LLM의 foreseeable reasoning (명시적인 관측 없이도
문제 해결에 필요한 중간 단계와 정보 요구를 사전에 추론) 활용 - (Plan, #E) 구조의 전체 해결 청사진 생성
- Plan: 현재 단계에서 수행해야 할 작업을 설명하는 문장이고,
- #E: 단계 번호 s가 붙은 특수 토큰으로, 해당 단계에서 지정된 Worker가 수집할 것으로 예상되는 evidence를 저장하기 위한 공간 (아직 비어 있는 증거 슬롯)
Planner가 Worker에게 지시를 내릴 때 이전 단계에서 수집된 #E들을 참조할 수 있기 때문에 다음 단계가 이전 결과에 의존하는 문제도 처리 가능
Worker
- Planner의 지시를 받아 외부 도구 호출
- 실제 관측/증거를 수집해서 #E 채움
- 추론 없음, 판단 없음 → 정보 수집 전용
Solver
- Plan + Evidence 전부 종합
- 최종 답변 / 상태 결과 생성
- 질의응답(QA) 작업에서는 답변을 생성
- 행동 요청 작업에서는 작업 수행 상태를 반환
- Planner·Worker 실수가 있어도 자체 추론으로 일부 보정 가능
- “계획과 증거를 맹신하지 말라”는 프롬프트가 성능 ↑
2.2 Prompt Redundancy Reduction
추론과 관측을 번갈아 수행하는 방식의 ALM 시스템은 프롬프트 중복 문제를 겪는다.
관측 기반 ALM이 질문 Q를 해결하기 위해 총 k개의 추론 단계를 거쳐
최종 응답 R을 도출한다고 가정해보자.
- 질문: Q
- 컨텍스트 프롬프트: C
- 예시들: S
- 추론 단계 수: k
- 매 단계마다 생성:
- Thought: T
- Action: A
- Observation: O
기존 ALM
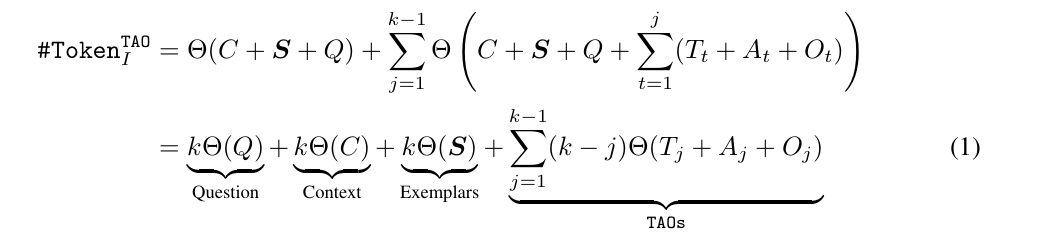
질문 Q, 컨텍스트 C, 예제 S 매 단계마다 다시 입력됨
질문 Q → k번
컨텍스트 C → k번
예제 S → k번
-> 중복
1단계에서 만든 (T₁, A₁, O₁)
→ 이후 모든 단계에서 다시 포함
2단계 TAO
→ 그 다음 단계들에서 계속 포함
…
즉, 초반에 만든 생각일수록 나중에 수십 번 재사용됨
그래서 토큰 수가 k에 대해 거의 제곱(k²)으로 증가
k 조금만 커져도:
토큰 제한 초과
비용 폭탄
시간 폭탄
ReWOO
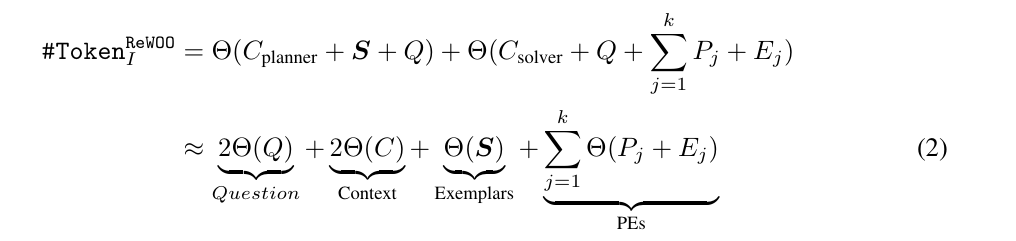
-
Θ(x) : 텍스트 x의 토큰 개수
-
C_planner : Planner에게 주는 컨텍스트(규칙/지시문/시스템 프롬프트 등)
-
C_solver : Solver에게 주는 컨텍스트
-
Pⱼ : j번째 단계의 계획 문장(Plan text)
→ “이번 단계에서 뭘 해야 하는지” 설명 -
Eⱼ : j번째 단계에서 Worker가 가져온 증거(Evidence)
→ 검색 결과/도구 결과/문서 일부 등ReWOO에서 LLM에 넣는 입력은 딱 두 번 발생한다
1). Planner 호출 1번
입력으로 (Planner 컨텍스트 + 예시 + 질문) 을 넣는다
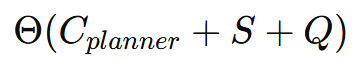
2). Solver 호출 1번
입력으로 (Solver 컨텍스트 + 질문 + 모든 단계의 (계획+증거)) 를 넣는다
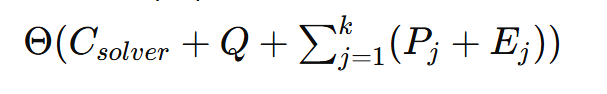
두 개를 더한 게 총 입력 토큰.
기존 ReAct는 단계마다 LLM을 다시 부르니까 입력이 k번 이상 반복되는데, ReWOO는 Planner 1번 + Solver 1번 = 총 2번만 LLM 호출
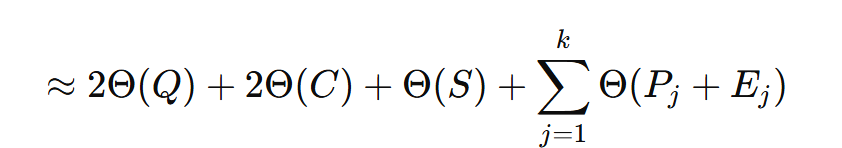
(1) 질문 Q가 2번 들어감 → 2Θ(Q)
- Planner 입력에 Q 1번
- Solver 입력에 Q 1번
- 합치면 2번
(2) 컨텍스트 C가 2번 들어감 → 2Θ(C)
- Planner 컨텍스트: C_planner
- Solver 컨텍스트: C_solver
둘 다 "컨텍스트" 계열이라 대충 C로 묶음
※ 정확히는 Θ(C_planner) + Θ(C_solver)인데,
보기 쉽게 "둘 다 비슷한 규모의 컨텍스트"라고 보고 2C처럼 적은 것.
(3) 예시 S는 1번만 → Θ(S)
- 예시는 Planner가 계획 세울 때만 필요하다고 봄 -> 1번
(4) 단계별로 추가되는 건 (P + E)뿐 → ΣΘ(P_j + E_j)
- k단계면 (P₁ + E₁), …, (P_k + E_k)가 Solver 입력에 한 번에 붙음
- 따라서 단계가 늘면 늘수록 이 부분만 늘어남
기존 방식
매 단계마다:
컨텍스트 + 예시 + 질문 + 지금까지의 모든 기록을 다시 입력
그래서 단계가 늘면 이전 기록 재전송이 폭증 → 거의 k² 느낌ReWOO
컨텍스트/질문/예시는 거의 정해진 횟수만
단계가 늘면 Plan+Evidence만 늘어남 → k에 비례
2.3 Parameter Efficiency by Specialization
기존 ALM은 ALM은 파라미터 모델(LLM) 과 비파라미터 요소(도구 호출) 를 함께 다뤄야 해서 end-to-end 학습이 매우 복잡하다는 한계가 있음
기존 접근:
-
Toolformer : 도구가 포함된 코퍼스를 활용하여 self-supervised 방식으로 언어 모델을 미세조정
❌ 도구를 독립적으로만 샘플링 → 다단계 추론에 취약 -
ReAct :thought–action–observation 전체 궤적을 fine-tuning
❌ 보지 못한 작업이나 새로운 도구 집합에 대해 잘 일반화되는지는 입증되지 않음
이런 한계를 해결하기 위해 ReWOO는 추론과 도구 호출을 분리한다.
Fine-tuning 단계에서는 도구 응답을 전혀 보여주지 않고,
대신 Planner에 대해 미리 계획하는 추론 능력(foreseeable reasoning)만 학습
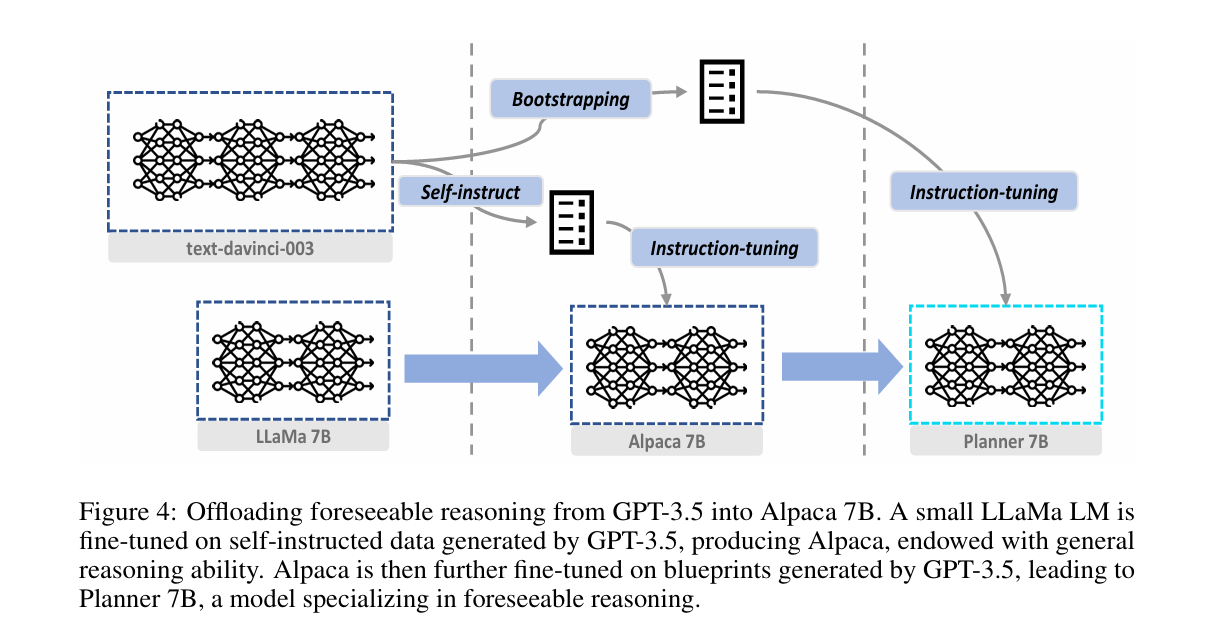
GPT-3.5가 가진 foreseeable reasoning 능력을 LLaMA 7B로 이전(offloading)
GPT-3.5(text-davinci-003)로 HotpotQA + TriviaQA 데이터에서 약 4000개의 (Plan, #E) blueprint 생성
Bootstrapping
정답으로 이어진 경우만 선택
→ 약 2000개 Planner용 instruction 데이터 확보Alpaca 7B 생성
LLaMA 7B를 52k self-instruct 데이터로 fine-tuning
→ GPT-3.5의 일반적 능력을 근사Planner 7B 생성
Alpaca 7B를 다시 Planner instruction 데이터로 fine-tuning
→ foreseeable reasoning에 특화된 모델
3 Experiments
본 논문에서는 다양한 NLP 벤치마크 전반에 걸쳐 ReWOO를 최신 프롬프팅 패러다임들과 비교 평가하였다.
외부 도구 활용의 필요성을 강조하기 위해, 답변을 위해 최신 외부 지식이 반드시 필요한 데이터셋을 새롭게 구축하였다.
주목할 점은, ReWOO가 토큰 사용량을 일관되게 줄이면서도, 모든 과제에서 ReAct와 동등하거나 더 뛰어난 성능을 보였다는 것이다.
3.1 Setups

1. Tasks & Datasets
(a) 상식 + 다단계 추론
- HotpotQA: 여러 문서를 거쳐야 하는 multi-hop QA
- TriviaQA: 독해 기반 QA
- SportsUnderstanding: 스포츠 전문 지식 QA (BigBench)
- StrategyQA: 여러 단계의 추론이 필요한 오픈 도메인 QA
(b) 수리·과학 추론
- GSM8K: 초등 수준 수학 문제
- PhysicsQuestions: 고등학교 물리 문제
(c) Curated (자체 구축)
최신 정보가 필요한 실제 ALM 시나리오
- SOTUQA: 2023년 국정연설 기반 QA
→ 문서 + 웹 검색 + 비교가 동시에 필요
2. Baselines
-
Direct Prompt
- zero-shot
- 추론·도구 없이 바로 답변
- 모델의 기본 성능 기준선
-
Chain-of-Thought (CoT)
- “step by step” 추론 유도
- 명시적 추론은 있으나 도구 사용 없음
-
ReAct
- thought–action–observation 기반 ALM
- zero-shot 평가를 위해 도구 설명을 컨텍스트에 추가
3. Exemplars
-
ReWOO Planner용 예시:
- HotpotQA: 6개
- TriviaQA: 1개
- GSM8K: 1개
-
예시 내용:
- 정보 검색
- 비교
- 방정식 풀이
- 계산 등 추론 템플릿 중심
-
PhysicsQA, SportsUnderstanding, StrategyQA:
- 일반화 능력 평가를 위해
- 관련 없는 벤치마크에서 예시 1개만 제공
-
공정성을 위해:
- ReWOO에 사용한 예시는
- ReAct에도 동일하게 제공
4. Action Space (사용 가능한 도구)
기본 제공 도구:
- Wikipedia
- WolframAlpha
- LLM (다른 LLM 호출)
- Calculator
- SearchDoc (개인 문서 검색)
Curated 태스크 추가 도구:
- Location, Stock, Twitter, Yelp
- Email, TradeStock, Draw 등
-> ReWOO와 ReAct에 동일한 도구 세트 제공
(벤치마크별 사용 가능 도구는 Table 1)
5. Evaluation Metrics
(1). 성능
- Exact Match (EM): 모델 답이 정답이랑 100% 똑같으면 1점, 아니면 0점
- Character-level F1: 문자 단위로 얼마나 많이 겹치는지 보는 점수
- GPT-4 기반 채점기로 의미적 정확도 평가
(2). 효율성
- 총 토큰 사용량 (도구 호출 포함)
- 추론 단계 수
- 1,000개 질의당 평균 비용(USD)
6. Fine-tuning 환경
- LLaMA 7B 모델
- RTX 4090 단일 GPU
- LoRA 기반 fine-tuning
3.2 Results and Observations
3.2.1 Comparison between Prompting Paradigms
평균 결과 (6개 공공 벤치마크 기준)
- 토큰 사용량 64% 감소
- 정확도 +4.4%p 상승
🔹 자체 구축 데이터셋(SOTUQA)에서의 성능
SOTUQA가 중요한 이유
- 최신 정보 필요
- 문서 검색 + 비교 + 추론 필수
- 현실 ALM 사용 시나리오랑 가장 비슷
-
ReWOO & ReAct 모두
→ Direct Prompt / CoT보다 훨씬 잘함 -
ReWOO vs ReAct
- 정확도: +8%p
- 토큰 사용: –43%
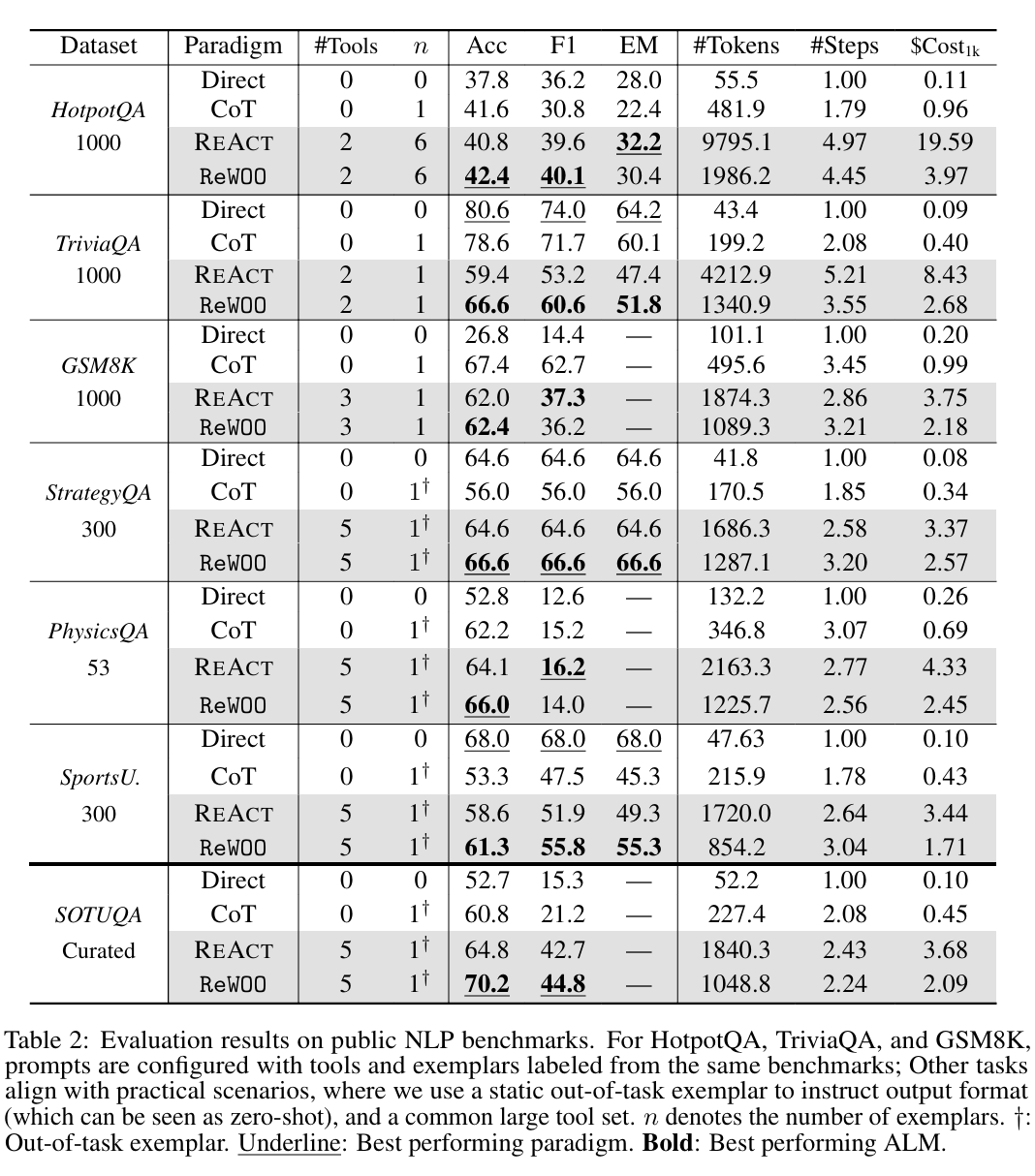
📌 ReAct vs ReWOO 공통 패턴
- Acc / F1 / EM
- ReWOO가 대부분 더 높거나 비슷
- #Tokens / $Cost
- ReWOO가 항상 훨씬 적음
🔹 불필요한 도구는 성능을 해친다
외부 도구를 제공하지 않은 Direct Prompting과 CoT가
ALM 방식보다 더 좋은 성능을 보이는 경우가 존재
이 관찰을 바탕으로, 저자들은 도구 개수를 점진적으로 늘리는 실험을 수행
HotpotQA에서 시작하여 ReWOO와 ReAct에 도구를 하나씩 추가
-
Google 같은 강력한 도구는 일시적으로 성능 향상
그러나 도구 수가 많아질수록 전체 성능은 감소 -
2개 도구에서는 성공하지만 7개 도구에서는 실패한 ReWOO 사례 20개 중 17개가 도구 오용때문
이는 불필요한 도구가 ALM에 잡음을 유입해 성능을 저하시킨다는 것을 의미
🔹 ReWOO는 도구 실패에 더 강건
ALM 시스템에서는 도구 오류 또는 빈 응답이 흔히 발생한다.
이를 평가하기 위해, 모든 도구가 “No evidence found.”를 반환하도록 강제한 실험을 수행
- ReAct는 도구 실패 시 성능이 크게 붕괴
- ReWOO는 성능 저하가 상대적으로 작고 비용도 낮음
즉, ReWOO는 도구 실패 상황에서도 더 강건하다.
🔹 RLHF의 영향
HotpotQA에서 사용한 LLM을 gpt-3.5-turbo → text-davinci-003
으로 교체한 실험도 수행했다.
text-davinci-003은 더 적은 추론 단계,더 적은 토큰,더 높은 성능
을 보였다.
이는 대화형 RLHF가 상식 기반 추론 능력에는 오히려 약간 부정적일 수 있음을 시사한다.
3.3 Fine-tuning and Specialization of LLM
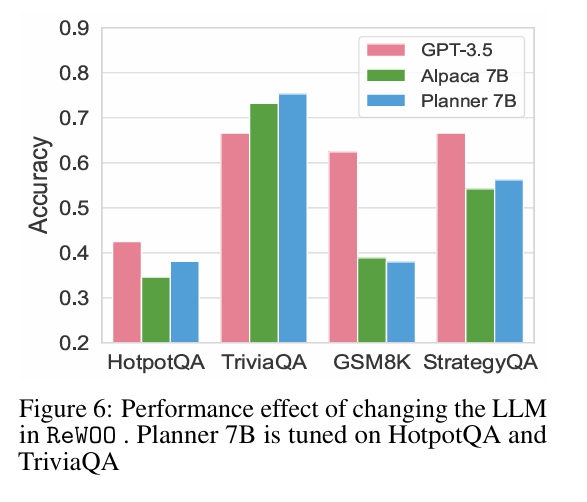
앞서 제시한 Specialization 프레임워크를 따라, GPT-3.5의 능력을 각각 Alpaca 7B와 Planner 7B로 offload하였다.
- Alpaca 7B: GPT-3.5의 일반적인 언어 능력을 근사하도록 학습된 모델
- Planner 7B: GPT-3.5의 foreseeable reasoning에 특화되도록 추가 학습된 모델.
이 두 모델은 모두 zero-shot 설정에서 원래의 GPT-3.5와 성능 비교를 수행하였다.
Figure 6에 따르면, Alpaca 7B와 Planner 7B를 ReWOO의 Planner 모듈에 적용했을 때,
- HotpotQA
- TriviaQA
- StrategyQA
와 같은 벤치마크에서 파라미터 수가 약 25배 더 큰 GPT-3.5와 맞먹는 성능을 달성하였다.
또한, Alpaca 7B에서 Planner 7B로 갈수록 전반적인 정확도가 추가로 향상되는 것을 확인할 수 있는데,
이는 Specialization 전략이 효과적으로 작동했음을 의미한다.
Planner 7B를 학습할 때 사용한 instruction 데이터에는
Wikipedia[query]LLM[prompt]
두 가지 도구만 등장했음에도 불구하고,
in-context에서 도구 설명만 제공하면, Planner 7B는
Google[query]Calculator[prompt]
와 같은 보지 못한 도구들에 대해서도 Alpaca 7B보다 더 잘 추론하는 모습을 보였다.
“큰 모델이 잘하는 ‘미리 생각하는 능력’만 뽑아서, 작은 모델에게 가르칠 수 있다.”
4 Limitations and Future Work
환경 정보가 거의 없는 탐색형 과제에서는 ReWOO의 핵심인 foreseeable reasoning이 잘 작동하지 않음

"당신은 방 한가운데에 있다.
주변을 둘러보면 drawer, shelf, cabinet, sofa, safe 등
매우 많은 물체들이 있다.
당신의 목표는: vase을 safe에 넣는 것이다."
→ Planner가 vase의 위치를 전혀 모르기 때문에
→ 가능한 모든 행동 경로를 전부 나열해야 함
이 경우 Planner의 추론 복잡도는 기존 observation-dependent 방식의 최악 복잡도와 동일
즉, ReWOO도 환경 관측이 필수적인 문제에서는 한계가 있음
🟢 시사점
- 강건한 ALM 시스템은 single LLM에 의존하면 안 됨
- LLM, 도구, 서브모델을 DAG(방향 비순환 그래프) 형태로 연결해
각 구성 요소가 역할 분담을 하도록 설계
향후 연구 방향
1. 특화 능력의 소형 모델 오프로딩
foreseeable reasoning을 작은 모델로 이전 (Planner 7B 사례)
Solver 등 다른 모듈도 동일하게 특화 가능2. 도구 표현 학습 (Tool Representation Learning)
기능이 비슷한 도구를 벡터로 표현
ALM 전체를 파라미터화 → end-to-end 학습 가능성3. DAG 실행 최적화
병렬 실행, 그래프 최적화 알고리즘 적용
전체 시스템 효율 및 속도 개선
5. Conclusion
-
기존 ALM은 추론 과정과 도구 호출이 얽혀 있어, 매 단계마다 동일한 컨텍스트와 예시가 반복 입력되며 토큰 사용량과 비용이 급격히 증가하는 한계를 가진다.
-
ReWOO는 이를 Planner–Worker–Solver 구조로 분리하여,
Planner는 도구 응답 없이 전체 해결 과정을 미리 설계하고
Worker는 계획에 따라 외부 도구를 호출해 증거를 수집하며
Solver는 계획과 증거를 종합해 최종 답변을 생성한다. -
이 과정에서 활용되는 foreseeable reasoning은 관찰 없이도 다음 추론 단계를 예측하는 능력으로, ReWOO가 프롬프트 중복을 제거하고 토큰 사용량을 선형 증가(O(k))로 유지할 수 있게 하는 핵심 요소이다.
-
다양한 공개 NLP 벤치마크와 실제 환경을 반영한 큐레이션 데이터셋에서, ReWOO는 ReAct 대비 훨씬 적은 토큰을 사용하면서도 동일하거나 더 높은 성능을 달성하였다.
-
추가 실험을 통해 GPT-3.5의 foreseeable reasoning 능력을 소형 언어 모델로 이전할 수 있음을 확인하였으며, 작은 모델도 제로샷 환경에서 새로운 도구를 활용할 수 있는 가능성을 제시하였다.
본 연구는 ReWOO가 토큰 효율성, 파라미터 효율성, 확장성을 동시에 만족하는 ALM 설계의 기반이 될 수 있음을 보여주며, 향후 모듈별 특화 학습, 도구 표현 학습, 시스템 그래프 최적화로 확장될 수 있는 방향을 제안한다.
