2022-05-02 ~ 2022-05-08
멋사 2주차
Peer Group에 가입하고, 첫 모임을 하였다.
1. Peer Group
(1) 규칙
- 매일 유튜브 강의 듣고 디스코드에 채팅으로 인증
- 매주 월요일 21시에 진행되는 내용발표 준비
- 과제있을 때마다 깃헙에 pull requests 올리고 코드리뷰 진행
- TIL(Todays I learned 일기 주 1회 작성)
(2) 학습 자료
- 핸즈온 머신러닝 2

- Andrew Ng 강의
https://www.coursera.org/learn/machine-learning/home/welcome
2. 회귀(Regression)
여러 개의 독립변수와 한 개의 종속변수 간의 상관관계를 모델링 하는 기법
머신러닝 회귀 예측의 핵심은 주어진 피처와 결정 값 데이터 기반에서 학습을 통해
최적의 회귀 계수를 찾아 내는 것
- 일반 선형회귀: 예측값과 실제 값의 RSS(Residual Sum of Squares)를 최소화할 수 있도록 회귀 계수를 최적화하며, Regularization을 적용하지 않은 모델
- Ridge: 선형 회귀에 L2 규제를 추가한 회귀 모델, L2 규제는 상대적으로 큰 회귀 계수 값의 예측 영향도를 감소시키기 위해 회귀 계수값을 더 작게 만드는 모델
- Lasso: 선형 회귀에 L1 규제를 적용한 방식, L1 규제는 예측 영향력이 작은 피처의 회귀 계수를 0으로 만들어 예측 시 피처가 선택되지 않게 하는 모델(L1 규제는 피처 선택 기능으로도 불림)
- ElasticNet: L2, L1 규제를 함께 결합한 모델
- Logistic Regression: 회귀라는 이름이 붙어 있지만, 분류에 사용되는 선형 모델
최적의 회귀 모델을 만든다는 것은 전체 데이터의 잔차(오류 값) 합이 최소가 되는 모델을 만든다는 의미.( 동시에 오류 값 합이 최소가 될 수 있는 최적의 회귀 계수를 찾는다는 의미)
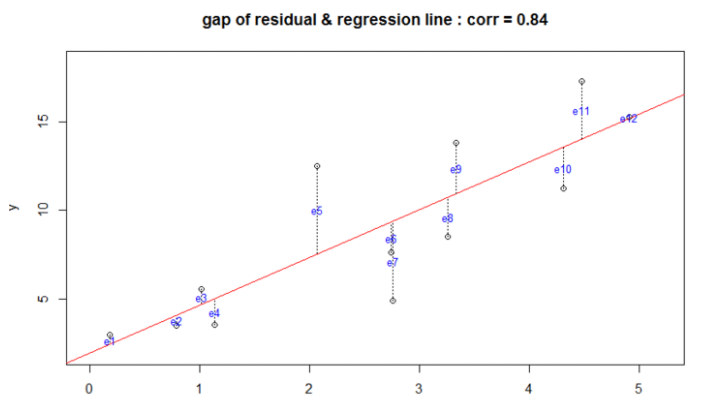
위 도표에서 알 수 있듯이 잔차는 +, - 값이 모두 가능하기 때문에 잔차를 단순히 더하게 되면 0이 되는 경우가 발생할 수 있음
- 절댓값을 취함(MAE, Mean Absolute Error)
- 제곱 합의 평균을 구하여 사용(RSS, Residual Sum of Square)
3. RSS 기반의 회귀 오류 측정
오류 값의 제곱을 구해서 더하는 방식. 미분 등의 계산을 편리하게 하기 위해서 RSS 방식으로 오류 합을 구함
회귀식의 독립변수 X, 종속변수Y가 중심 변수가 아니라 w 변수(회귀 계수)가 중심 변수

4. 경사하강법(Gradient Descent)
최적의 RSS를 도출하기 위해 사용되는 W 파라미터를 구하기 위한 방법
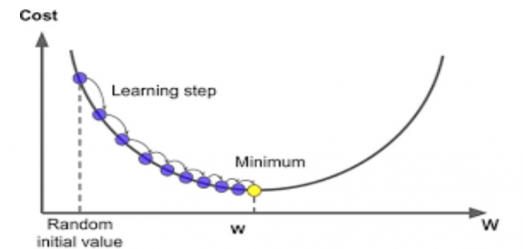
다음의 2차함수 그래프에서 최초 초기 랜덤값을 찍고 점진적인 학습을 통해 계속해서 손실함수가 최소가 되는 Point를 찾는 것
비용 함수가 포물선 형태의 2차 함수라면 경사 하강법은 최초 w에서부터 미분을 적용한 뒤,
이 미분 값이 계속 감소하는 방향으로 순차적으로 w를 업데이트한다.
미분된 1차 함수의 기울기가 감소하지 않는 지점을 비용 함수가 최소인 지점으로 간주하고 그때의 w 값을 반환한다.
경사하강법의 핵심은 “어떻게 하면 오류가 작아지는 방향으로 W 값을 보정할 수 있을까?” 이다
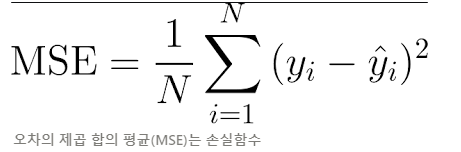
예측값 y^은 wx + b로 계산됨
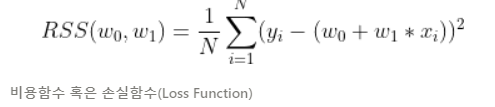
업데이트할 w를 구하기 위해 w에 대한 편미분
- MSE를 미분해 미분 함수의 최솟값을 구해야 하는데, 두개의 w 파라미터인 w0과 w1을 각각 가지고 있기 때문에 일반적 미분 적용 불가
- w0, w1 각 변수에 편미분 적용


- 업데이트 할 w와 b (gdW, gdB)

5. Code
gdW : LR ((y^ - y ) x)MEAN
gdB : LR * ((y^ - y ))MEAN
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline*# 표준정규분포를 따르는 0 ~ 1 사이의 난수 발생
X = np.random.rand(100)
*# 임의의 노이즈를 위해 아래와 같이 y변수 생성*
y = X + np.random.rand(100)*# 위에서 생성한 X, y 시각화
plt.scatter(X, y)
plt.show()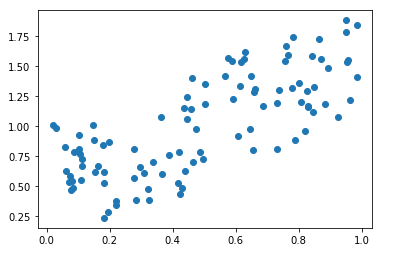
# 실제값과 예측값을 시각화 하는 함수
def plot_prediction(pred, y):
plt.scatter(X, y, label = 'real_value')
plt.scatter(X, pred, label = 'prediction')
plt.legend()
plt.show()# Gradient Desent 구현
# 초기 w, b 값
w = np.random.uniform(-1, 1)
b = np.random.uniform(-1, 1)
LR = 0.5
for epoch in range(100):
y_Pred = w * X + b # 예측값
# error가 0.001 이하이면 early stopping 하도록
error = np.abs(y_Pred - y).mean() # MAE
if error < 0.001:
break
# Gradient Descent 계산
w_grad = LR * ((y_Pred - y) * X).mean()
b_grad = LR * ((y_Pred - y)).mean()
# 새로운 w, b 갱신
w = w - w_grad
b = b - b_grad
if epoch % 20 == 0:
y_Pred = w * X + b
plot_prediction(y_Pred, y)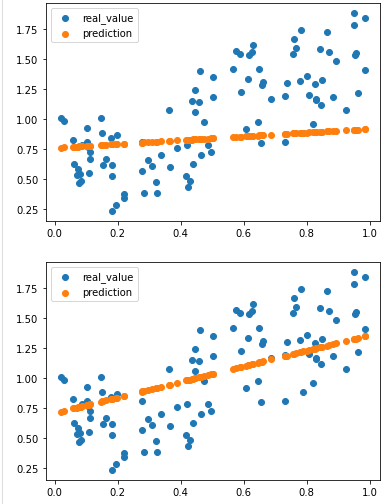
6. Supervised Learning
멀캠 프로젝트 4주차
1. TLCC (Time Lagged Cross Correlation)
터빈의 경우 대부분 주기적으로(e.g. 10초, 1분 마다) 값이 추출되는 시계열 데이터가 분석 대상
다양한 전처리 방법들이 있지만, 데이터들 간의 연관성이 높은 터빈 데이터에서는 시간에 따른 상관관계의 변화를 파악하는 것이 중요
갑작스러운 상관관계의 변화가 고장에 대한 신호가 되기도 하고, 상관관계를 이용하여 진단 및 예측 모델을 개선할 수도 있기 때문
2. Time-series Correlation
Correlation이란 2개의 변수가 가지는 선형 상관관계를 의미합니다. Collinearity는 Regression Model을 생성할 때 독립변수 중 2개 이상이 강한 선형 상관관계를 가지는 상황
3. Time-series 데이터간 correlation을 찾는 방법
(1) Pearson Correlation Coefficient(피어슨 상관 계수)
Pearson 상관 계수는 +1과 -1 사이의 값을 가지며, +1은 완벽한 양의 선형 상관 관계, 0은 선형 상관 관계없음, -1은 완벽한 음의 선형 상관 관계를 의미
한 변수가 증가할 때 다른 변수가 증가 또는 감소하는지에 대한 정보는 얻을 수 있어도, 두 변수 중 어느 변수가 다른 변수에 영향을 주는지에 대한 정보는 얻을 수 없습니다. 또한 Pearson Correlation은 데이터가 등분산성을 가진다고 가정하므로 변수 데이터가 정규 분포를 가지지 않거나 outlier가 발생할 경우 잘못된 분석 결과가 도출
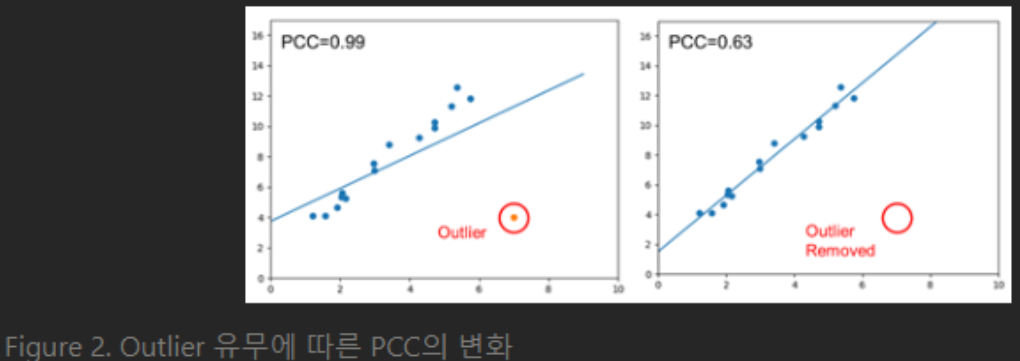
(2) Kendall Tau Rank Correlation Coefficient (켄달 상관 계수)
Kendall Tau Correlation Coefficient은 순위 상관 계수(Rank Correlation Coefficient)의 한 종류이며 두 변수들 간의 순위를 비교하여 연관성을 계산
Pearson과 같이 두 데이터의 연관성을 +1과 -1 사이의 값으로 나타내고, 전체 구간에 대한 결과
두 변수간 데이터 그 자체가 아닌 순위를 비교하는 것이기에, 변수 데이터가 정규 분포를 가지지 않으면 잘못된 결과를 얻을 수 있는 Pearson 상관 계수의 단점이 보완
(3) Time Lagged Cross Correlation (TLCC)
하나의 time-series를 조금씩 shifting 시키면서 데이터 전체 범위에 대하여 Pearson 상관 계수를 계산하여 나타냅니다. TLCC는 Pearson, Kendall Correlation과는 다르게 두 데이터 사이에서의 인과관계를 파악
인과관계의 대표적인 것 : leader-follower relationship
예시로 Figure 3에서 터빈 데이터 A1과 A2의 TLCC 결과를 나타냈습니다. A2의 shift범위를 -500~+500까지의 값을 계산하여 shift에 따라 상관 계수 값의 변화를 관찰
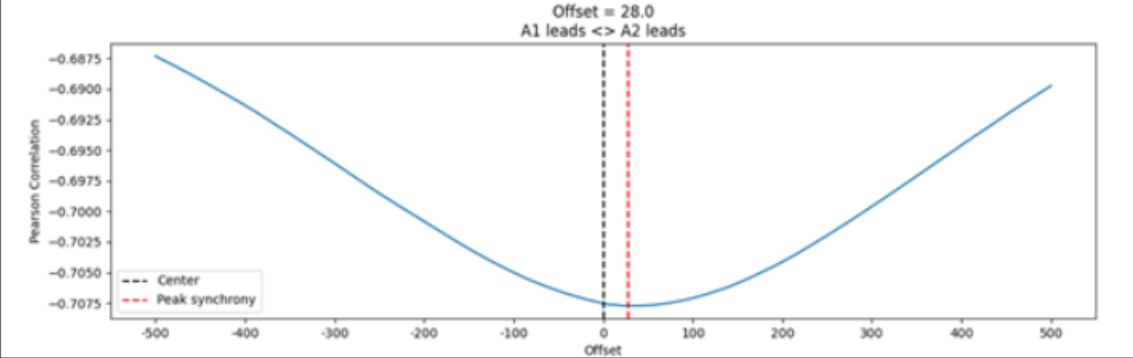
결과를 보면 A2가 앞으로 28만큼 shift 되었을 때 상관관계의 절댓값이 가장 높게 측정되었습니다. Offset이 양의 값이므로 A2가 이 상관관계를 주도
TLCC는 전체 구간에 대한 결과이므로, 추가적으로 시간에 따라 상세하게 분석을 하고자 한다면 Windowed Time Lagged Cross Correlation (WTLCC)
을 사용
- 데이터를 여러 개의 window로 나누고 위와 같은 TLCC분석을 각 window마다 하는 것이 WTLCC
(4) Dynamic Time Warping (DTW)
DTW는 Figure 4와 같이, 두 time-series 데이터 간의 최소거리를 가지는 직선 경로를 찾는 방식
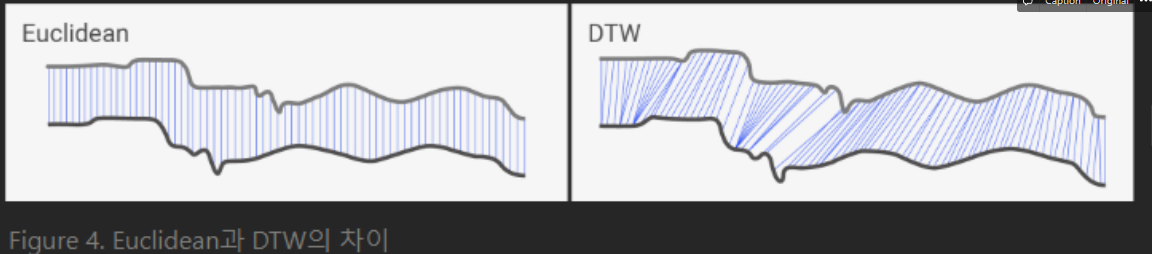
- 데이터 각 시간 지점에서 길이를 구하는 것이 Euclidean 방식
- 데이터 각 지점에서 시간지점과 상관없이 최단 직선 경로를 찾는 것이 DTW
Signal의 길이가 서로 다르더라도 DTW를 적용할 수 있다는 장점이 있습니다. 이러한 장점이 있어 Speech analysis에 사용하기 위해 처음 개발
(5) Summary
- 정해진 구간 안에서 두 시계열 데이터의 상관 관계를 수치로 나태내는 방식 : 피어슨 상관 계수와 켄달 상관계수
- 두 시계열 데이터의 인과관계를 파악하기 위한 방식 : TLCC
- 다른 길이를 가지는 시계열의 유사성을 판단하기 위한 방식 : DTW
출처 : https://tech.onepredict.ai/7b5cb659-687d-48a4-ac80-827d30e49fb3
