Cluster Maintenance
Operating System Upgrade
클러스터의 일부로 노드를 제거해야 하는 시나리오에 관해 논의
유지보수 목적
소프트웨어 기반 업그레이드나 패치 적용, 보안 패치 등을 클러스터에 적용
Master Node, Worker Node1, Worker Node2, Worker Node3
가 있다고 가정하자
이 중 w1이 다운되면?
- 포드는 접근 불가능
- 포드를 어떻게 배치하느냐에 따라 사용자가 영향을 받을 수 있음
예를들어 w1에 있는 pod-1이 w2에도 복제본이 있다고 가정하자.
그러면 pod-1에 액세스하는 사용자는 영향을 받지 않는다.
하지만 pod-2는 w1에만 있다면 사용자가 영향을 받는다.
이때 쿠버네티스는 뭘 했을까?
w1이 즉시 온라인으로 돌아오면 kubelet 절차가 시작되고 포드가 온라인으로 돌아온다.
하지만 노드가 5분 이상 다운되면 해당 노드에서 파드가 종료된다.
포드가 레플리카 셋의 일부라면(복제본이 있다면) 다른 노드에 재현 될 것이다.
포드가 복구되길 기다리는 시간은 관리자에게 5분이라는 값을 설정한다.
kube-controller-manager --pod-eviction-timeout=5m0s노드가 오프라인이 될 때마다 마스터 노드는 최대 5분까지 기다린다.
예를 들어 w1이 5분 동안 죽어있으면 다시 온라인이 될 때 안에 파드는 모두 없어져있다.
복제본이 w2에 있었다면 w2, w3에 파드가 존재할 것이고
복제본이 없다면 그대로 죽은 것이다.
이럴 때 해결책
w1에 파드를 모두 다른 노드로 drain 하는 것이다.
엄밀히 말하면 옮긴게 아니라 정상 종료 후 다른 노드에 재현이 되는 것이다.
kubectl drain node-1그리고 노드가 종료 되었다가 다시 온라인 상태가 되면
kubectl uncordon node-01명령어를 입력한다. 하지만 이때 옮긴 포드가 다시 돌아가진 않는다.
포드가 삭제되거나 클러스터 내에서 생성 된다면 그때 이 이 노드에서 생성될 것이다.
Cluster Upgrade Process
kubeadm upgrade plan
kubeadm upgrade applym1, w1, w2, w3이 있다고 가정하자
- 마스터 노드 업그레이드
- 작업자 노드 업그레이드
Master Node Upgrade
마스터 노드가 업그레이드 되는 동안 컨트롤 플레인의 구성 요소는 API 서버
, 스케줄러, 컨트롤러 관리자와 같은 건 잠시 다운
마스터 노드가 다운된다고 클러스터 상의 작업자 노드와 앱이 영향을 받진 않는다.
마스터노드가 다운되면 관리 기능도 다운
-> kubectl이나 다른 쿠버네티느 API를 이용해 클러스터에 액세스할 수 없음
-> 새 앱을 배포하거나 기존 앱을 삭제, 수정할 수 없음
-> 포드가 종료되면 자동으로 생성되지 않음
-> 노드와 포드가 작동하는 한 앱은 작동해야하고 사용자는 영향을 받지 않음
Worker Node Upgrade
전략
1. 한꺼번에 모두 업그레이드
-> 포드가 다운되면 사용자는 앱에 접속할 수 없음
-> 업그레이드가 완려되면 노드가 백업되고 새 포드가 예약되어 다시 접속할 수 있음
--> 가동 중지 시간이 필요한 전략
- 한번에 노드 하나씩 업그레이드
-> 첫번째 노드를 업그레이드 하면 포드가 다른 노드로 이동
-> 첫번째 노드가 업그레이드되고 백업이 되면
-> 두번째 노드를 업그레이드, 포드가 다른 노드로 이동
kubeadm upgrade
kubeadm upgrade plan- 현재 클러스터 버전
- kubeadm 도구 버전
- 쿠버네티스 최신 버전
apt-get upgrade -y kubeadm=1.12.0-00
kubeadm upgrade apply v1.12.0\
kubectl get nodes
apt-get upgrade -y kubelet=1.12.0-00
systemctl restart kubelet
kubectl get nodesBackup and Restore
Backup Candidates
- Resource Configuration
- deploy, pod, service - ETCD Cluster
- cluster와 관련된 모든 정보가 저장 - Persistent Volumes
- 영구 저장소
Imperactive
- 클러스터에 생성한 리소스와 관련해 때때로 명령을 실행해 명령적 방법으로 개체를 생성
- 네임스페이스나 시크릿 구성 맵을 생성하는 동안 또는 응용 프로그램을 공개하기 위함
kubectl create namespace new-namespace
kubectl create secret
kubectl create configmap명령적 접근
pod.yaml 파일을 생성 후
kubectl apply -f pod.yamlBackup - Resource Configs
kubectl을 이용해 kube API 서버를 쿼리하거나 API 서버에 직접 액세스함으로써 클러스터에 생성된 모든 개체에 대한 리소스 구성을 복사해 저장할 수 있음
예를들어 백업 스크립트에서 사용되는 명령어 예시
kubectl get all --all-namespaces -o yaml > all-deploy-services.yamlBackup - ETCD
etcd는 우리 클러스터에 관한 정보 저장
클러스터 자체에 관한 정보와 노드 및 클러스터 내부에서 생성된 모든 리소스가 여기 저장
아까처럼 리소스를 백업하는 대신 기타 서버 자체를 백업
ETCD는 마스터 노드에 호스트 되어 있음
ETCD는 빌트인 스냅샷 솔루션도 갖고 옴
ETCD 컨트롤 유틸리티의 스냅샷을 이용해 데이터베이스 스냅샷을 찍을 수 있음
ETCDCTL_API=3 etcdctl \
snapshot save snapshot.db이 백업에서 클러스터를 복원하려면 먼저 kube API 서버 서비스 중단
service kube-apisercer stop복원 프로세스는 기타 클러스터를 다시 시작해야 하는데 kube API 서버가 거기 달려있음
그 후 ETCD 컨트롤 스냅샷 복원 명령 실행
ETCDCTL_API=3 etcdctl \
snapshot restore snapshot.db \
--data-dir /var/lib/etcd-from-backupETCD가 백업에서 복구할 때 새 클러스터 구성을 초기화하고 ETCD의 멤버를 새 클러스터에 새 멤버로 구성
새 멤버가 실수로 기존의 클러스터에 합류하는 걸 막음
문제 풀이
We need to take node01 out for maintenance. Empty the node of all applications and mark it unschedulable.
node를 비우고 unschedulable 해야하므로 drain 사용
controlplane ~ ✖ kubectl drain node01 --ignore-daemonsets
node/node01 already cordoned
Warning: ignoring DaemonSet-managed Pods: kube-flannel/kube-flannel-ds-k7pl2, kube-system/kube-proxy-bxjd6
evicting pod default/blue-6b478c8dbf-5nwcl
evicting pod default/blue-6b478c8dbf-2hmvn
pod/blue-6b478c8dbf-5nwcl evicted
pod/blue-6b478c8dbf-2hmvn evicted
node/node01 drainedWhat nodes are the apps on now?
node를 물어봐서
kuebctl get nodes인 줄 알았는데
현재 사용 중인 앱에서 어떤 node를 쓰고 있냐는 질문이었기 때문에
controlplane ~ ➜ kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
blue-6b478c8dbf-cmdtk 1/1 Running 0 23m 10.244.0.4 controlplane <none> <none>
blue-6b478c8dbf-r8xx6 1/1 Running 0 11m 10.244.0.5 controlplane <none> <none>
blue-6b478c8dbf-zj6s7 1/1 Running 0 11m 10.244.0.6 controlplane <none> <none>The maintenance tasks have been completed. Configure the node node01 to be schedulable again.
아까 node를 drain 했으니 다시 schedulable 하게 만드려면 uncordon을 사용하면 된다.
controlplane ~ ➜ kubectl uncordon node01
node/node01 uncordonedHow many nodes can host workloads in this cluster?Inspect the applications and taints set on the nodes.
controlplane ~ ➜ kubectl describe nodes controlplane | grep -i taint
Taints: <none>
controlplane ~ ➜ kubectl describe nodes node01 | grep -i taint
Taints: <none>(3) The master node in our cluster is planned for a regular maintenance reboot tonight. While we do not anticipate anything to go wrong, we are required to take the necessary backups. Take a snapshot of the ETCD database using the built-in snapshot functionality. Store the backup file at location /opt/snapshot-pre-boot.db
(3) Luckily we took a backup. Restore the original state of the cluster using the backup file.
How is ETCD configured for cluster1?
stacked ETCD
student-node ~ ➜ kubectl config use-context cluster1
Switched to context "cluster1".
student-node ~ ➜ kubectl get pods -n kube-system | grep etcd
etcd-cluster1-controlplane 1/1 Running 0 59mHow is ETCD configured for cluster2?
external ETCD
student-node ~ ➜ kubectl config use-context cluster2
Switched to context "cluster2".
student-node ~ ➜ kubectl get pods -n kube-system | grep etcd
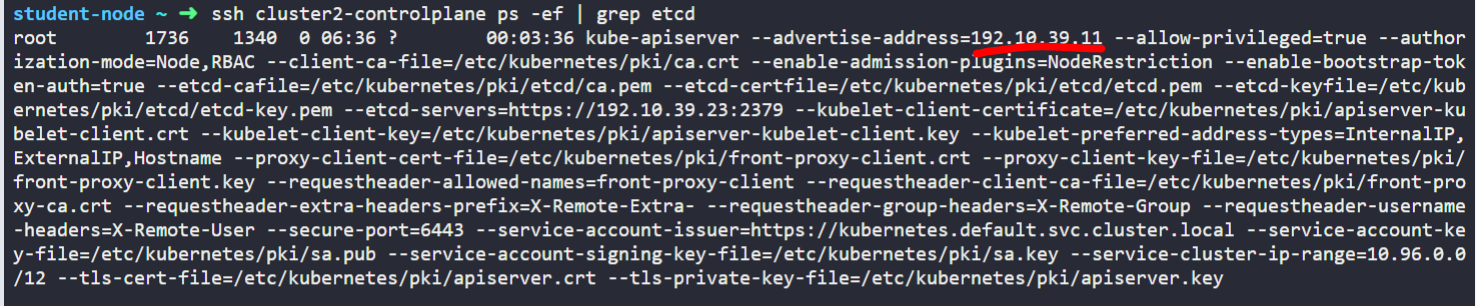
What is the IP address of the External ETCD datastore used in cluster2?
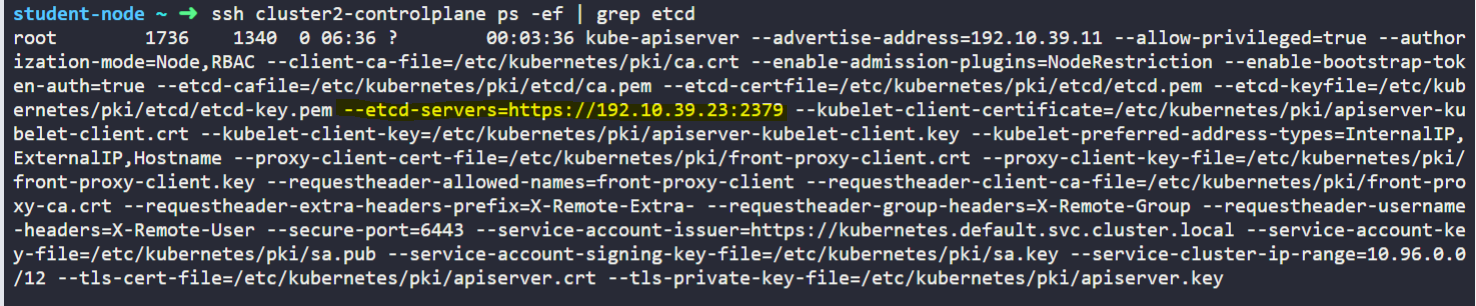
What is the default data directory used the for ETCD datastore used in cluster1? Remember, this cluster uses a Stacked ETCD topology.
data-dir=/var/lib/etcd
student-node ~ ➜ kubectl config use-context cluster1
Switched to context "cluster1".
student-node ~ ➜ kubectl get pods -o wide -n kube-system
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
coredns-6d4b75cb6d-4gc4f 1/1 Running 0 66m 10.50.0.2 cluster1-controlplane <none> <none>
coredns-6d4b75cb6d-6srqs 1/1 Running 0 66m 10.50.0.3 cluster1-controlplane <none> <none>
etcd-cluster1-controlplane 1/1 Running 0 67m 192.10.39.9 cluster1-controlplane <none> <none>
kube-apiserver-cluster1-controlplane 1/1 Running 0 67m 192.10.39.9 cluster1-controlplane <none> <none>
kube-controller-manager-cluster1-controlplane 1/1 Running 0 67m 192.10.39.9 cluster1-controlplane <none> <none>
kube-proxy-42dp6 1/1 Running 0 66m 192.10.39.14 cluster1-node01 <none> <none>
kube-proxy-nmdwg 1/1 Running 0 66m 192.10.39.9 cluster1-controlplane <none> <none>
kube-scheduler-cluster1-controlplane 1/1 Running 0 67m 192.10.39.9 cluster1-controlplane <none> <none>
weave-net-5qx2s 2/2 Running 1 (66m ago) 66m 192.10.39.9 cluster1-controlplane <none> <none>
weave-net-6ddp6 2/2 Running 0 66m 192.10.39.14 cluster1-node01 <none> <none>
student-node ~ ✖ kubectl describe pods etcd-cluster1-controlplane -n kube-system | grep data
--data-dir=/var/lib/etcd
/var/lib/etcd from etcd-data (rw)
etcd-data:(4) What is the default data directory used the for ETCD datastore used in cluster2? Remember, this cluster uses an External ETCD topology.
다시 공부할 거
- taints
taint는 node에 pod가 할당되는 것을 방지한다.
taint가 설정된 노드에는 일반적인 파드는 업로드 될 수 없으며 toleration을 적용해야 업로드 할 수 있다.
- drain
drain은 노드의 유지관리와 자원 해제를 목적으로
노드를 cordon 상태로 만든 후 파드를 다른 노드로 이동시킨다.
- cordon
cordon은 노드의 점검, 업데이트를 목적으로
노드를 점검 상태로 변환하여 새로운 파드의 업데이트를 막음.
기존에 실행 중인 파드는 그대로 실행
