AWS 데이터베이스 세미나 내용 정리
최근 온라인으로 참여한 AWS 데이터베이스 알아보기 세미나 내용을 정리하여 포스팅한다
세미나명 : AWS 데이터베이스 알아보기 세미나
주관 : 아마존웹서비스코리아
장소 : 온라인 참여
날짜 : 2021년 8월 31일 pm 2:00 ~ pm 4:30
참석자수 : 대략 40명
현재 모던 어플리케이션은 전통적인 3티어 방식을 벗어나 MSA(micro service architecture) 구조 및 클라우드 서비스로의 전환을 한데에는 이유가 있다. 그 이유에는 먼저, 1억 유저, 백만명 이상의 동접자로부터 나오는 대규모의 트래픽이 있고, 또 다른 이유에는 이러한 규모의 하드웨어 및 소프트웨어 유지 비용이 너무 크다는 것이다. 물론 이러한 서비스가 되기 전까지는 MSA구조나 클라우드 서비스 도입이 고려사항이 아닐 수 있다. 시장으로부터의 반응이 기반되어야 한다는 전제가 있기 때문이다. 하지만, 이러한 움직임이 트렌드임은 부인할 수 없다.
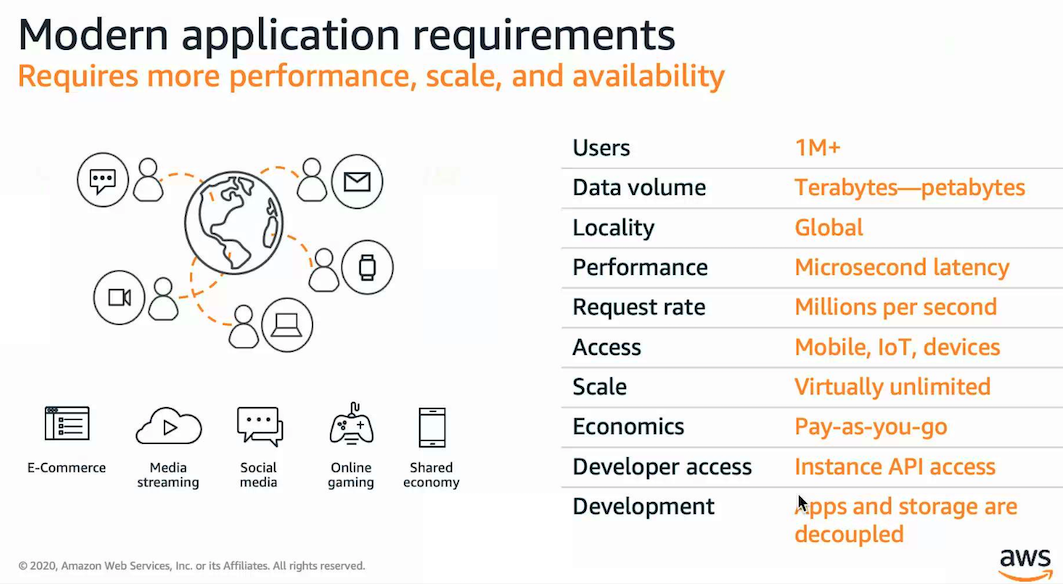
모던 어플리케이션의 요구사항들
이러한 관점에서, 실시간으로 처리되어야하는 방대한 양의 데이터를 어떻게 처리할 것인지에 대한 부분 역시 관심의 대상이 아닐 수 없다. 현재 전통적인 3티어 방식의 어플리케이션에서는 RDBMS의 적극적인 차용을 통한 구현을 하고 있고, 하였다. 하지만, 자료구조적 관점에서 RDBMS는 상당히 규격화되어있고 유연하지 못하다. 또한 상기한 대규모의 트래픽이 발생될때에는 RDBMS의 색인(Index)을 통한 CRUD 역시 퍼포먼스적 측면 및 비용적 측면에서도 비효율적임이 필드에서 확인되었다. 예시로, 아마존은 과거 7500개의 오라클 테이블을 통해 데이터를 관리하였지만, 2004년 몇 시간동안 운영이 중단되는 대형사고를 겪었다. 그 이유에는 특정 시즌에 유입된 대량의 트래픽이 문제였으며, 문제 분석 결과 특정 상품을 조회하는 형태의 워크로드가 70% 이상임을 확인하고, 해당 서비스를 마이크로서비스화 하여 관리하고, 기존의 Index 스캔으로 처리하였던 방식을 탈피하고자 하였고 현재 아마존은 이러한 데이터 처리로 인한 비용 발생을 서비스에 맞는 데이터베이스의 선택과 클라우드로의 전환으로 90%의 비용 절감을 이루었다. 이것이 아래 후술할 AWS DynamoDB가 나온 배경이다.
아마존 이외에도, 아마존 AWS를 통해 많은 기업들이 퍼포먼스, 비용 두마리 토끼를 잡고 있다. Airbnb(에어비엔비)는 AWS DynamoDB를 통해 유저의 검색 이력을 관리하고 AWS ElastiCache를 사용해 렌더링되는 정보들을 관리하며, 전통적 방식의 AWS RDS를 통해 로직을 처리한다. duolingo(듀오링고) 역시 AWS DynamoDB, AWS ElastiCache를 사용중이며 AWS RDS 보다 기술적 혁신이 들어간 AWS Aurora를 사용중이다. 이 이외에도 여러 기업들이 기존 3티어 방식을 벗어나 MSA로 구조적인 개편을 하고, 각 서비스에 맞는 데이터베이스를 선택함으로써 효율을 극대화하고 있다.
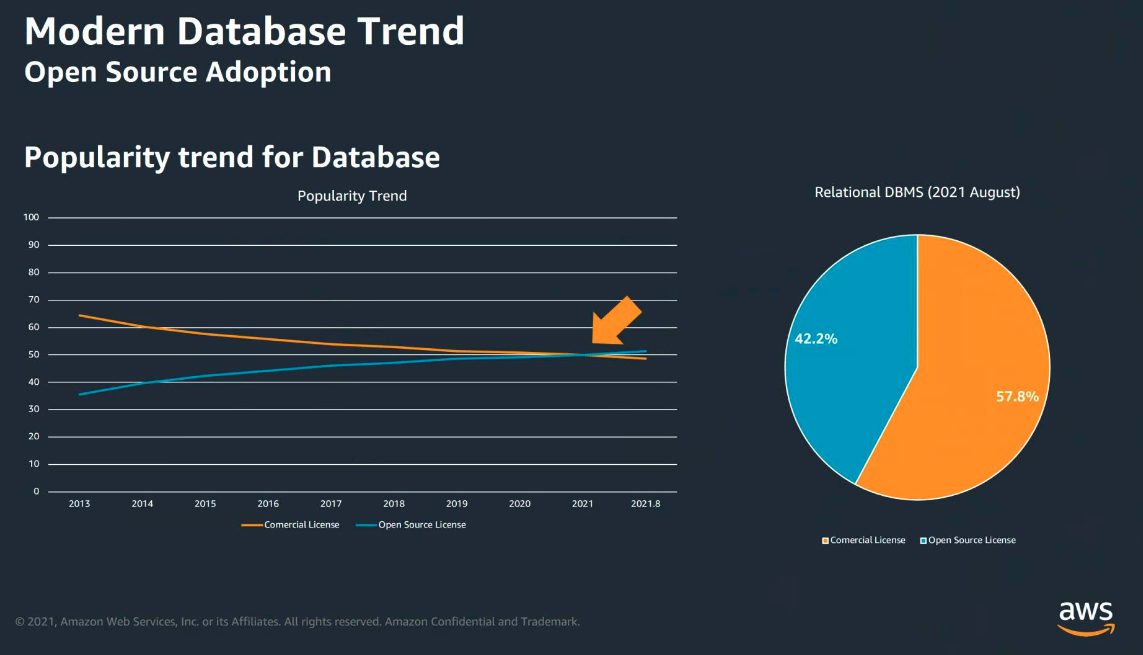
오픈소스 데이터베이스(MySQL, Postgresql 등)를 선택하는 일이 늘어남(https://db-engines.com)
기업의 전통적인 RDBMS에서 클라우드화, 오픈소스의 차용이 단번에 디루어진 것은 아니다. 기업의 기밀을 관리하는 데이터베이스를 linux 베이스, 오픈소스 데이터베이스를 골자로 하는 AWS 데이터베이스 시스템의 초기 반응은 미진하였다고 한다. 하지만 현재는 많은 기업에서 차용하고 있다.

클라우드화 되고 있는 데이터베이스, 관리로 인한 비용 발생을 줄인다

AWS 데이터베이스 서비스들
그렇다면 AWS 데이터베이스는 어떤 서비스들을 제공할까. 위 사진처럼 총 8가지 종류의 서비스들이 있다.
전통적인 RDBMS 방식 데이터베이스를 제공하는 RDS, Aurora
key-value를 통한 NoSQL 방식으로, 기존 인덱스 스캔 방식의 RDBMS보다 성능, 비용 절감을 보이는 DynamoDB
Json 처리 등 depth가 깊은 데이터 및 유연한 data type을 제공하는 DocumentDB
어플리케이션, 데이터베이스 사이의 cache 부분을 관리하는 Redis와 같은 서비스를 위한 ElastiCache
GraphDB와 같은 데이터간의 노드를 중심으로 하는 서비스를 위한 Neptune
IoT 센싱 정보처럼 넣은 시간을 x축으로 하고, y축에 정보가 필요한 서비스(time-series DB)를 위한 Timestream
금융정보와 같이 무결성이 최우선적인 DB를 위한 QLDB
400kb, 32 depth의 제약이 있는 DocumentDB와 달리 제약이 없는 Keyspaces

AWS Aurora의 특징
먼저 AWS Aurora(오로라)는 Mysql의 5배, Postgresql의 3배의 처리량을 보이며, 15개의 read replicas(복제본)까지 늘리도록 설정할 수 있다. 또한 기존 RDBMS의 구조 중 저장소 부분의 구조적인 부분을 변경하여 가용성 및 안정성 둘 다 보장하고 있으며 높은 보안 및 Fully-managed를 보장하고 있다. Fully-managed란 완전관리형으로, 사용자가 RDS, DynamoDB, ElastiCache 같은 DB 서비스를 이용하면 내부적으로 서버/OS가 있지만 사용자에게는 드러나지 않으며, DB 솔루션 설치또한 필요 없이 바로 DB를 사용할 수 있다. 사용자는 설정만으로 또는 설정하지 않아도 쉽게 백업, 가용성에 대한 부분을 보장 받을 수 있다.
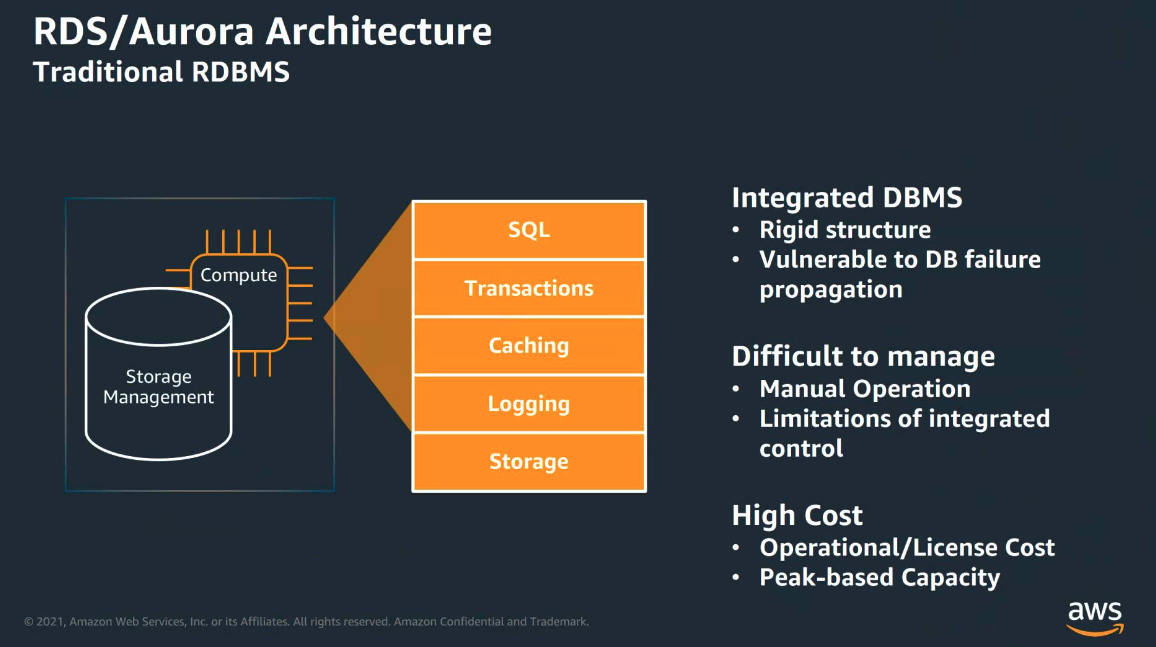
전통적인 RDBMS의 구조
전통적인 RDBMS의 구조는 크게 computing 영역과 storage 영역으로 나눌 수 있으며, logical instance가 computing 영역에 생성되어 sql, transaction, caching등의 일을 처리하고, physical I/O가 발생되면 storage 영역으로 넘어간다. logging에 대한 처리는 storage 영역의 데이터를 다시 computing 영역으로 가져온 후 logging에 대한 처리를 한다. 이러한 구조에서 결국 인스턴스의 생성이 가장 성능에 영향을 미치는 부분이며, 전통적인 3계층 구조의 어플리케이션에서는 통합된 데이터베이스와 더불어 하나의 인스턴스, 하나의 컴퓨터상에서 동작하는 경우가 많아 장애에 취약하였으며 한 시스템의 장애가 다른 시스템의 장애로 이어졌다. 또한 서비스 규모가 커짐에 따라 고비용의 장비로 대체하고는 하였다.
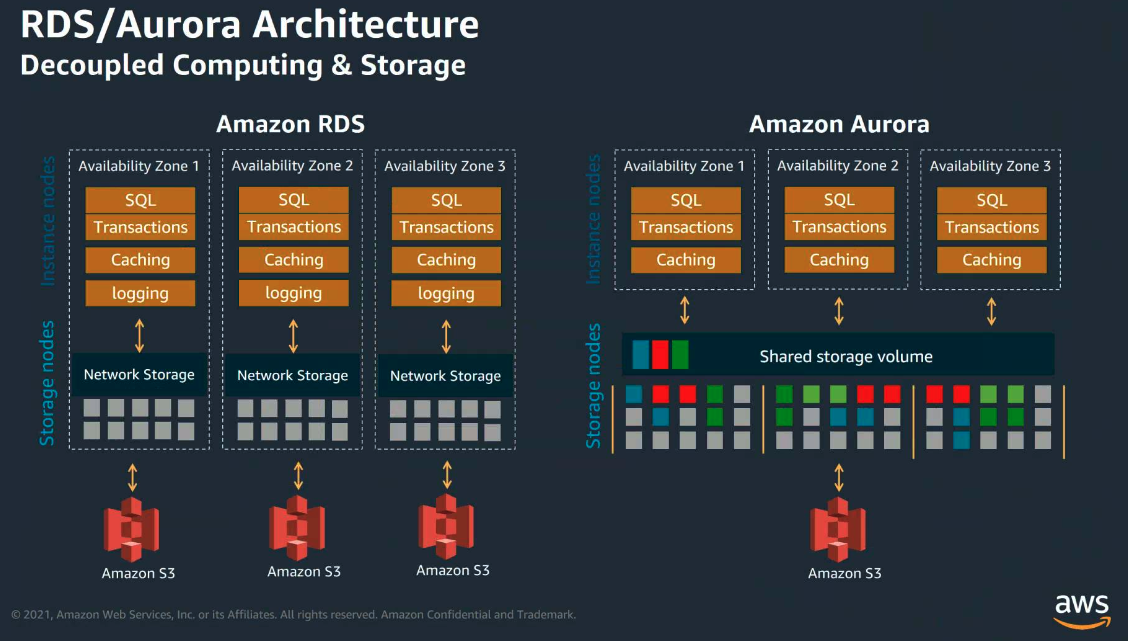
AWS RDS와 AWS Aurora
이러한 단점을 피하고자 AWS RDS와 AWS Aurora는 컴퓨팅 영역과 스토리지 영역을 분리하였다. 다만, Aurora의 경우, logging 영역을 스토리지 영역으로 이전하고, 스토리지 영역이 공유 스토리지 형태로 구조적 변경을 하였다는 것이 가장 큰 차이점이다.

Zone의 개념과 Quorum(쿼럼) 방식
공유 스토리지 이전에 Aurora는 네트워크적으로 구분된 3개의 존에 각각 2개씩 인스턴스가 복제되어 있다. 총 6개의 복제본을 가지고 있는 셈이다. 이 Zone들을 protection group이라고 부르며, 총 10 Gb가 할당된다. 이러한 복제본들을 통해 어떠한 순간에도 데이터 안정성을 보장한다. 또한 공유 스토리지에 읽기/쓰기 작업을 결정할때에는 쿼럼 방식, 일종의 과반수 투표 방식을 통해 진행된다. 읽기 작업의 경우 6개의 복제본 중 3개 이상, 쓰기 작업의 경우 6개의 복제본 중 4개 이상의 무결성을 가져야 작업이 진행된다. 따라서, 데이터 무결성이 공유 스토리지에 보장된다.
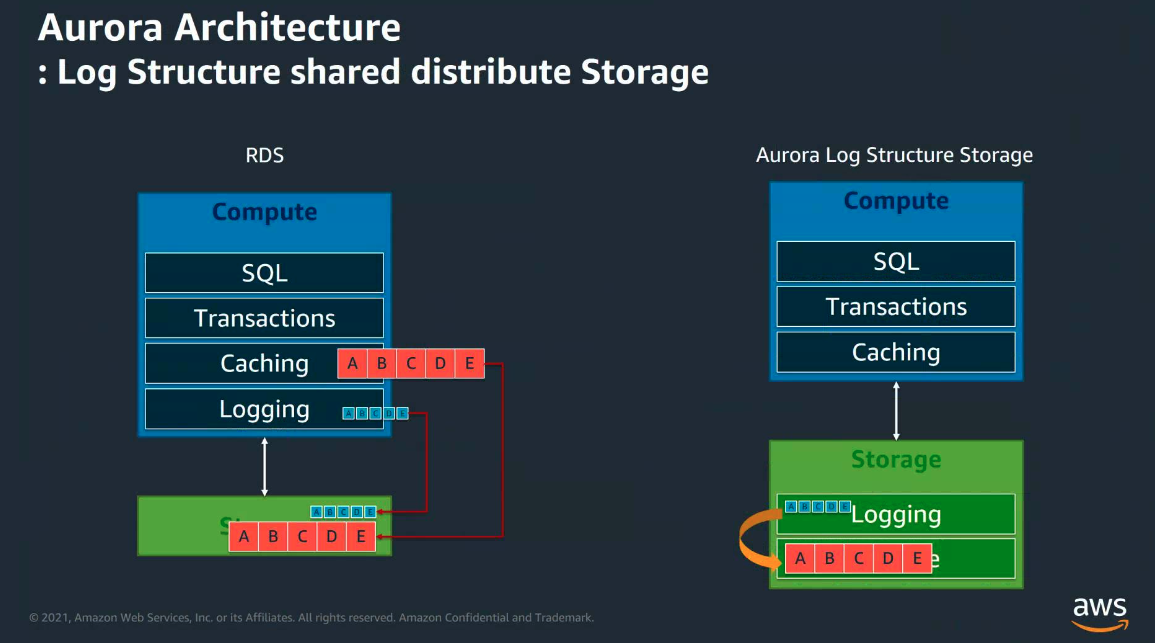
logging 처리의 비교
또한, 기존의 RDS와 달리 이전된 logging은 상기한 무결성한 공유 storage 영역에서 작업이 이루어지므로 log 데이터 역시 무결성함을 보임과 동시에, 기존 방식보다 더 효율적이다.
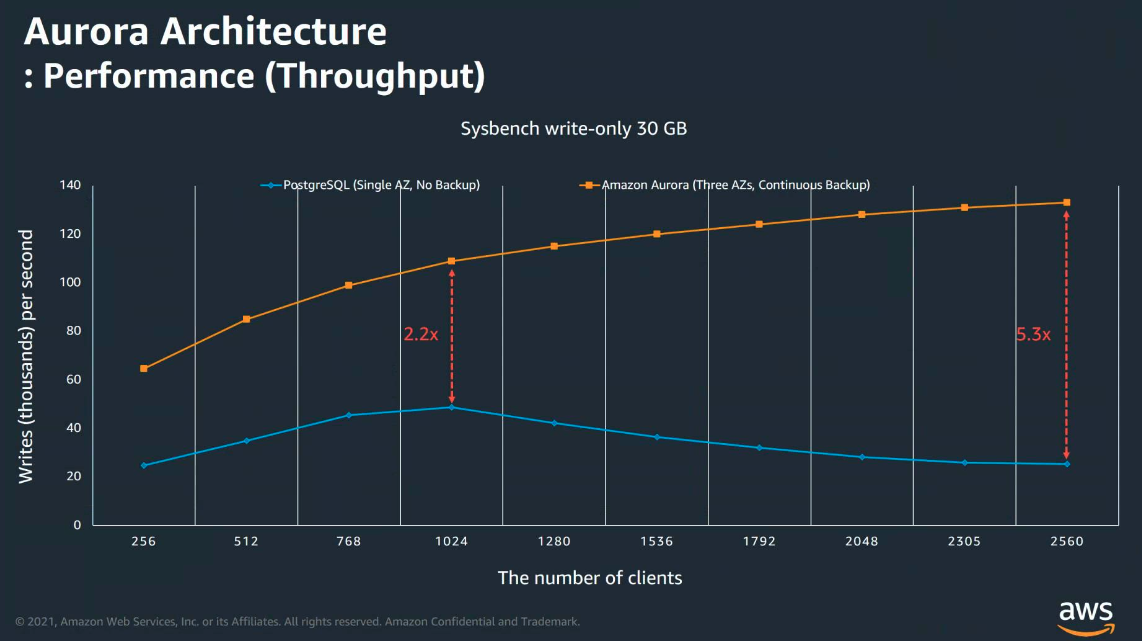
위 구조적 차이로 인한 퍼포먼스 차이
이러한 구조적인 차이에서 기존의 서비스보다 요청이 많은 상황에서도 안정적인 퍼포먼스가 나오는 것을 그래프를 통해 확인할 수 있다.
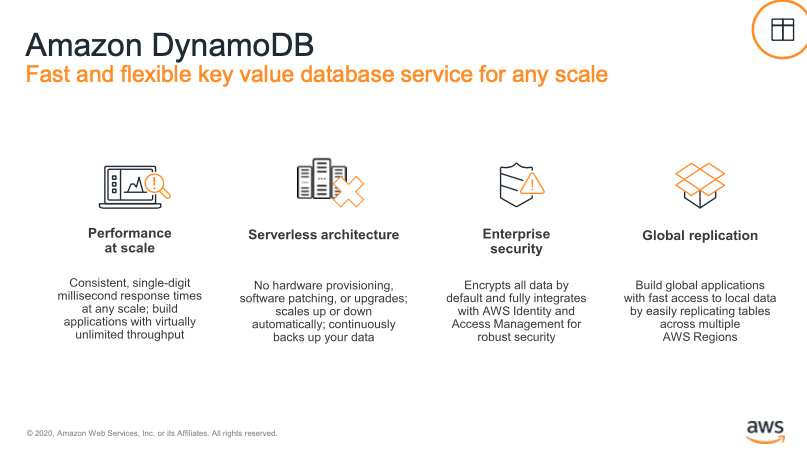
AWS DynamoDB의 특징
AWS DynamoDB는 key-value 구조의 NoSQL로, 빅데이터의 CRUD에서 상당한 강점을 보이며, cloud 서비스의 특징인 serverless 환경을 가진다. 또한, 암호화를 통한 보안 및 in-region을 벗어나 international하게 복제가 가능한 유지보수적 강점 역시 지니고 있다. 데이터가 많아도 항상 일정한 response time이 보장된다는 것이 주목할 만하다. 기존 RDBMS의 색인 검색보다 퍼포먼스적으로 더 우수하다는 것은 필드(국내 사례도 있다)에서 증명된 바 있다.

AWS DocumentDB의 특징
AWS DocumentDB의 경우, 자료형에 비교적 자유로운 점과 JSON과 같은 형태의 데이터 저장에 최적화 되있다는 점이다. MongoDB와 호환되며, MongoDB의 2배의 처리량을 보인다. 그 외에 다른 AWS 서비스와 유사한 특징 역시 보유하고 있다. 다만, MongoDB의 경우 하나의 데이터는 400kb, 32 depth의 제한이 있다.

AWS ElastiCache의 특징
어플리케이션 서버와 데이터베이스 사이에는 cache가 있으며, 웹서버에서 먼저 cache를 통한 조회 후 데이터베이스로 가는 특징이 있는데, 이러한 서비스들 (Redis 등)을 위한 서비스이다. redis와 같은 서비스가 사용되는 서비스가 있다면 접목할만하다.
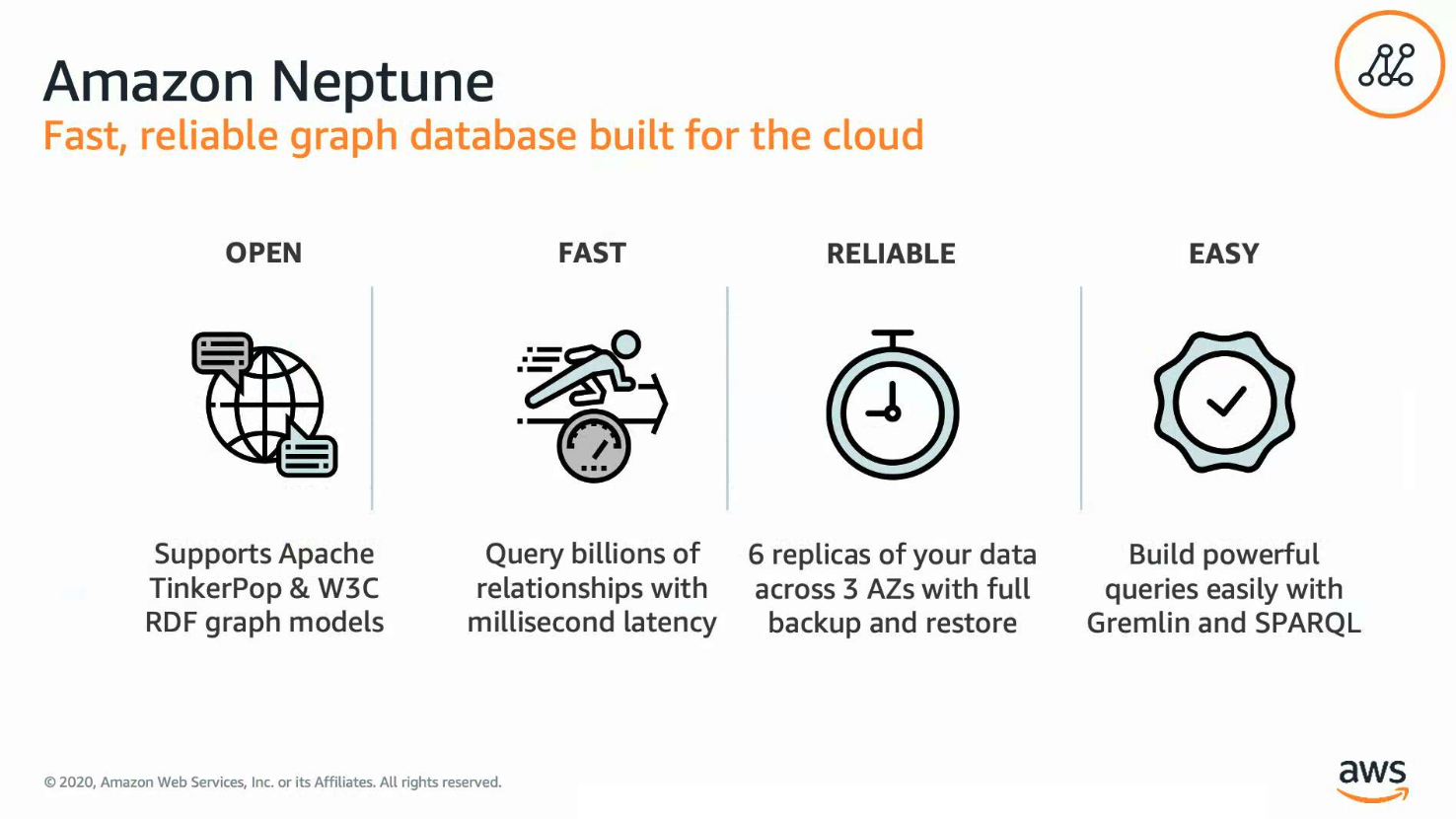
AWS Neptune의 특징
SNS 서비스 중, 내 친구의 친구들을 추천하는 기능이 있는데 이를 구현하려면 어떨까. 기존 RDBMS로 처리한다면 복잡한 조인 및 Index를 이용한 쿼리 최적화가 필요하고, 서비스가 커짐에 따라 유연하지 못할 것이다. 이러한 단점을 해결하기 위해 등장한 것이 GraphQL이며, 이 GraphQL을 클라우드화 서비스한 것이 Amazon Neptune이다.
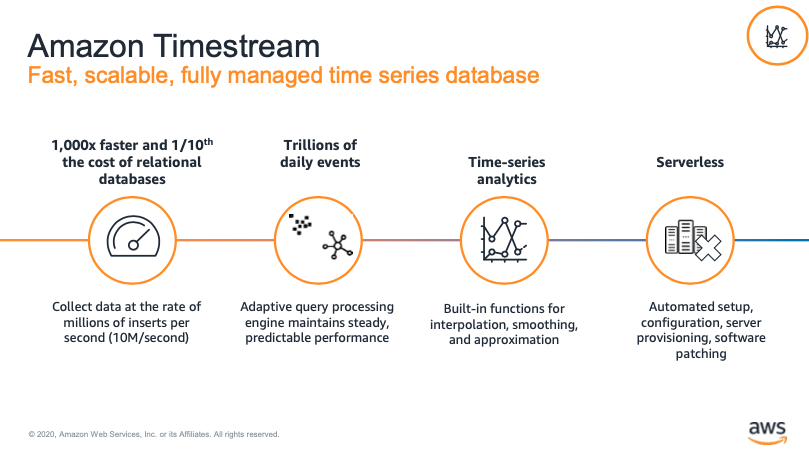
AWS Timestream의 특징
기기로부터 센싱된 정보를 DB에 적재할때는 시간에 따라 정렬된다는 특징이 있다. 또한 이러한 데이터는 상당히 방대한 양임과 동시에, 기기의 대수만큼 증가한다는 특징이 있다. 이러한 시간에 따른 정보를 처리하기 위해 나온 데이터베이스가 time-series DB이며, 이러한 데이터베이스를 클라우드화 한 서비스가 바로 AWS Timestream이다. 이런 류의 데이터에 대한 조회에 최적화되어있다.
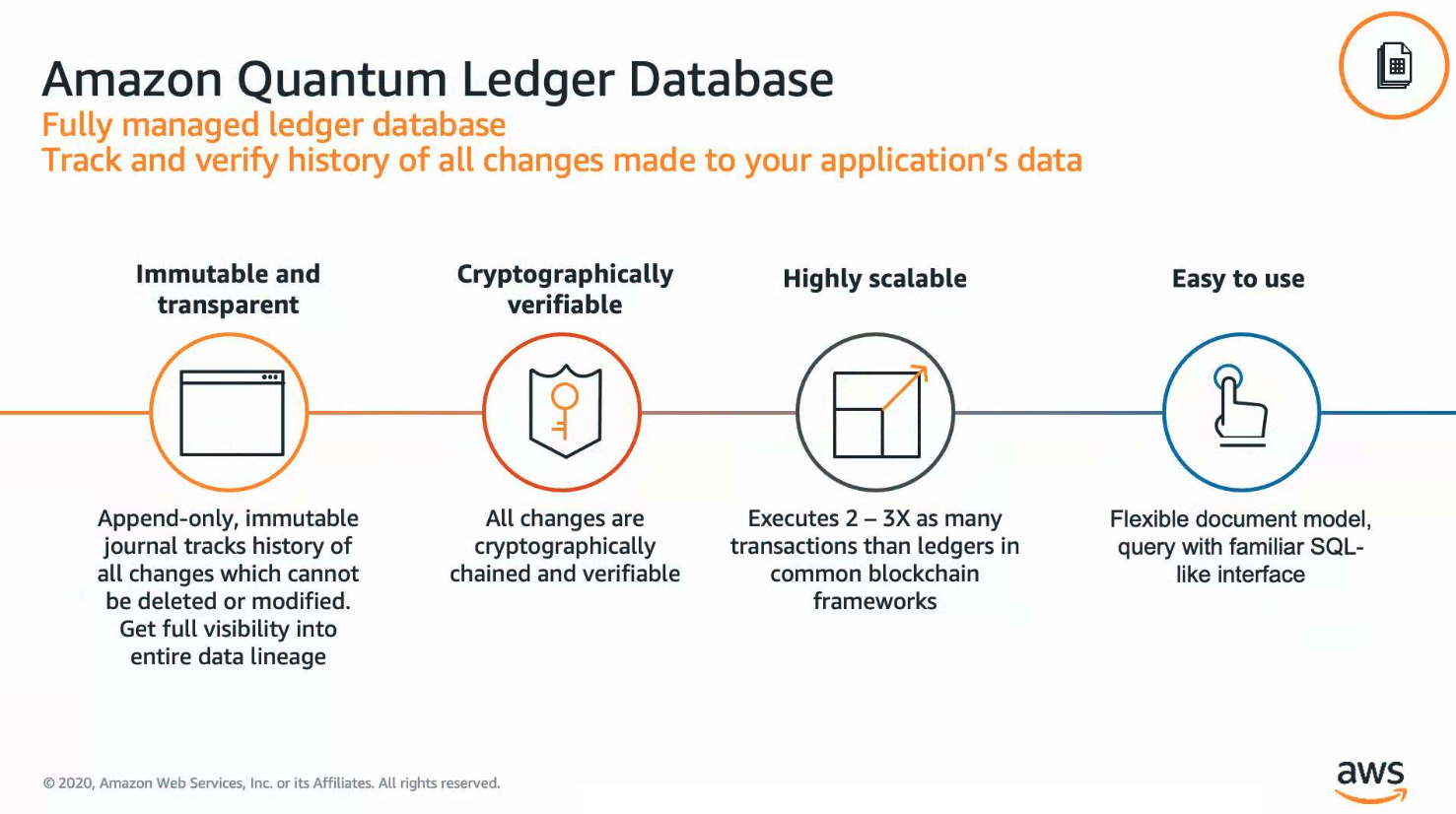
AWS QLDB의 특징
데이터의 위변조를 방지하는 것이 매우 중요한 서비스, 가령 금융 정보같은 서비스를 위한 데이터베이스로, 무결성을 보장한다. 블록체인과 같은 데이터 산출물에 대한 클라우드 서비스로도 생각해볼 수 있다.

AWS keyspaces의 특징
상기 MongoDB와 유사한 특징을 가지지만, 하나의 데이터에 대한 제약조건이 없다. 아파치 카산드라와 같은 서비스를 위한 AWS의 서비스이다.
규모가 적은 서비스, 혹은 대규모의 구조를 수용하려고자 준비하는 서비스가 있다면 이러한 MSA구조의 차용과 더불어 클라우드화하는 것을 적용해볼만하며, 이미 하나의 트렌드로 자리매김하고 있다. 따라서 이러한 서비스들에 대한 이해가 서비스의 구현 뿐 아니라 앞으로의 성능, 비용적 측면을 줄일 수 있는 핵심 요소가 될 것이다.
