전 직장동료이자 사수였던 분이 계시다
그 분이 퇴사하고 한 달 정도 지난 후 수원에서 만났다
개발 관련 이야기를 하기 좋아하고 열정이 남아 있는 우리이기에, 매주 스터디를 진행해보기로 하였다
주말마다 공부를 해야한다고 생각은 하면서 행동을 하지 않는 나에게는 나쁘지 않은 제안이였다
스터디 모임의 이름은 죽은 개발자의 사회로 하기로 하였다
죽은 시인들의 사회와 마찬가지로, 아직 개발자라고 부르기에는 미숙하기에 죽은 이후에야 정회원이 될 수 있다 (....) 웃프다
개발을 좋아하는 나의 사수 답게, 103초가 걸리던 모듈을 0.7초로 줄였다는 소식과 어떻게 가능하였는지는 그 분에게 매우 궁금한 소식이였나보다
이번 스터디에서는 내가 어떤 과정을 거쳐 이것이 가능하였는지 설명하였고 첫 스터디인 만큼 약간 날로 먹는(..?) 주제로 선정하였다
상황설명
현재 회사에서 베타 테스트 목적으로 배포된 기기 관제 솔루션 웹페이지가 있다
해당 웹페이지는 기기들이 알려준 정보를 일괄하여 관제하는 웹페이지로, IoT 회사다운 멋진 솔루션이다
다만 문제는, 기기가 초단위로 날려준 데이터가 올 1월부터 쌓여 현재 1억개의 row가 생겼다는 것이 문제였다
기기가 많은 정보를 적재한다는 것은 이미 알고 있었고, 기존 솔루션에 이미 시간 단위로 평균을 내는 스케줄러 작업이 돌아가고 있다
따라서, 시간 단위로 통계 데이터를 보면 빠르다
문제는 사용자가 임의로 시간을 설정하여 정보를 보려고 하면 발생한다 해당 요청이 들어온 순간 1억개의 row를 모두 검색한다 시간복잡도 O(N)의 일이 벌어지는 것이다
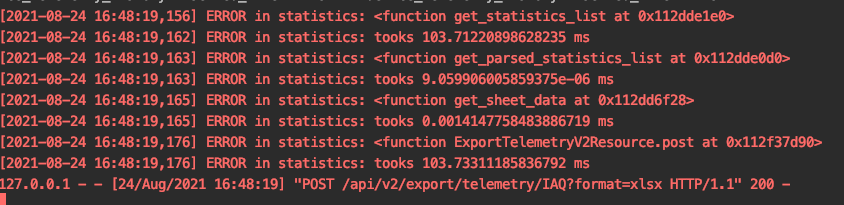
실서버에 시간 측정 모듈을 붙이고 api를 요청하니 데이터를 엑셀로 출력되기까지 103초가 나왔다 (...)
절망..
그리고 대부분의 시간은 쿼리를 날리고 데이터를 받아오는 것에서 사용하였다 (100초 이상....)
이것을 최적화 하는것이 이슈로 나에게 할당되었다
해결과정(이라고 적고 삽질기라고 읽는다)
현재 회사에서는 flask, flask-sqlalchemy (ORM)를 사용한다
로직 자체는 query문을 제작하고 query.all()로 데이터를 받아오는 방식으로 구현되어 있었다
db.session.query(Model.a, Model.b) 식으로 session을 활용하고 가져올 데이터를 명시하면 더 빨라진다는 것을 stackoverflow에서 확인하였다 (이걸 알아내는 것도 많은 시간이 걸렸다...)
빨라지긴 하였다 103초에서 93초로 (....)
그 다음 해본 것은 ORM을 포기하고 native query로 작성하는 것이였다
이 역시 빨라지긴 하였다 103초에서 85초로 (....)
해당 쿼리는 join을 3개의 테이블과 엮어서 하였으므로 join을 빼보았지만 오히려 시간이 늘어났다 (ㅜㅜ...)
결국 해당 이슈를 그 날 처리하지 못하고 이틀만 더 시간을 달라고 팀장님께 말씀드렸다
그리고 index를 도입하겠다고도 말씀드렸다
index는 이전부터 알고는 있었지만 한번도 실무에서 쓸 일이 없었다
index에 대한 개념의 상세한 정보는 아래의 유튜브를 추천한다
결국 나에게 가장 중요한 정보는, Primary key (auto-increment로 설정되있는)가 할당되어 있으면, 그것이 자동적으로 clustered index로 설정되고, sql의 default 데이터 자료구조인 binary tree구조로 된다는 것이였다
또한 만약 secondary index를 할당하면 기존 clutered index에 포인터를 할당하여 참조한다는 것이였고, unique가 아니여도 가능하다는 것이였다!
상식상 binary tree라면 정렬되있는 상황에서 O(logN)의 시간복잡도를 가지기 때문에 빠를 수 밖에 없을 것이다
바로 실험을 해보았다
select * from table where inserted_time > "2021-08-30 00:00:00";
위와 같은 쿼리를 실서버에 날리니 80초 정도가 소요되었다
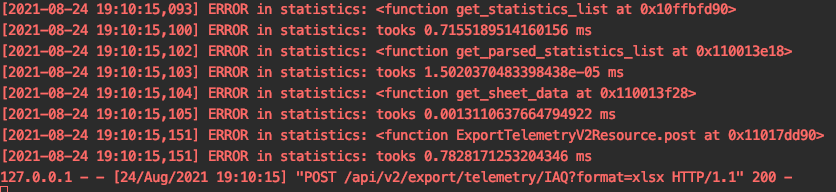
return받은 데이터 중 index가 가장 낮은 primary key id를 넣어보았다
select * from table where id > 153241331
놀랍게도 0.7초가 걸렸다 (.....)
-- 인덱스 추가
alter table table_name add index index_name(column_name);
-- 인덱스 확인
show index from table_name;
secondary index를 추가하고 인덱스를 확인하였다
데이터가 많아서 그런지 index 추가하는 것에 체감상 3분 이상 걸린 것 같다
-- 실행계획을 확인 (index를 어떤 걸 사용할지 확인 가능)
explain select * from table_name;
-- 실행계획을 바꾸기 위한 쿼리, select절에 hint를 준다
select * from table_name use index(index_name);
굳이 실행계획을 바꾸기위해 hint를 주지 않아도 optimizer가 알아서 바꿔주긴 하였다
sqlalchemy에서는 아래와 같이 코드를 작성하면 index 사용이 가능하였다
query.with_hint(table, 'use index(index_name), 'mysql').all()
또한, 이미 모델이 만들어지고 데이터가 있는 상황에서는 아래와 같이 sqlalchemy에 index를 알려줘야 index이름이 확인되어 동작하였다
from sqlalchemy import Index
class Table(db.Model)
id = db.Column(db.Integer(), primary_key=True)
inserted_time = db.Column(db.DateTime(), default=datetime.now, index=True)index_setting = Index('index_name', Table.inserted_time)
index_setting.create(bind=db.engine)
나의 경우 mysql에 이미 index를 선언하여서 위와 같이 index_setting.create(bind=db.engine)를 하면 500에러가 발생하였지만, 어찌됬든 index를 사용 가능하게 되었다
ㅎㅎ
기본적인 index 개념을 이용하여 문제를 해결하였고, 특별한 내용은 아니지만 해당 내용을 공유한다
다음 스터디는 날로 먹기는 힘들겠군 (...)
