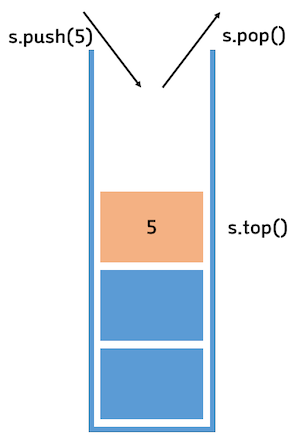
Stack
특징
- 물건을 쌓아 올리듯 자료를 쌓아 올린 형태의 자료구조다.
- 선형 구조
- 후입선출구조(LIFO : Last-In-First-Out) : 마지막에 삽입한 자료를 가장 먼저 꺼낸다.
- 자료가 없을 때 pop하는 오류를 stack underflow, 스택의 크기 이상의 자료를 push 하려고 할 때의 오류를 stack overflow라고 함.
Stack st = new Stack();주요 연산
- push : 삽입, top을 위로 한 칸 올리고, top이 가리키는 위치에 데이터 저장
- pop : 삭제, top이 가리키는 데이터를 반환하고, top을 아래로 한칸 내린다.
- peek : 스택의 top에 있는 item을 반환한다. pop과 달리 stack에서 객체를 꺼내지 않는다.
스택 용도
- 연산자 후위표기법
- 함수의 콜스택 : 가장 마지막에 호출된 함수가 가장 먼저 실행을 완료하고 복귀하는 LIFO구조이다. 함수 호출이 발생하면 함수 수행에 필요한 정보를 스택 프레임에 저장하여 시스템 스택에 삽입한다.
- 브라우저 뒤로가기
- 문자열 역순 출력
- DFS
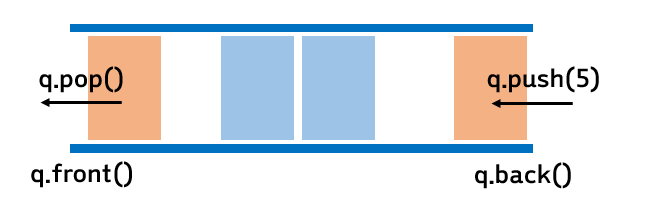
Queue(선형 큐)
설명
- 큐의 뒤(rear)에서만 삽입 하고, 큐의 앞(front)에서는 삭제만 이루어진다.
선형구조
선입선출구조(FIFO : First-In-First-Out) : 가장 먼저 삽입된 원소가 가장 먼저 삭제된다. - 자바에서는 스택을 Stack클래스로 구현하여 제공하지만 큐는 Queue 인터페이스만 있고 별도의 클래스가 없다. 그래서 Queue 인터페이스를 구현한 클래스들을 사용해야 한다.
Queue q = new LinkedList();단점
- 선형 큐에서 삽입 및 삭제를 반복하다 보면, rear가 맨 마지막 인덱스를 가리키고, 앞에는 비어 있을 수 있지만 이를 꽉 찼다고 인식한다. 데이터를 삭제할 때마다 한칸 앞으로 이동시키는 것이 아니라 인덱스 단위로 큐의 연산을 진행했기 때문에 이러한 문제점이 생겨난다. 이러한 단점을 보완하기 위해 Circular Queue(원형 큐)가 생겨났다.
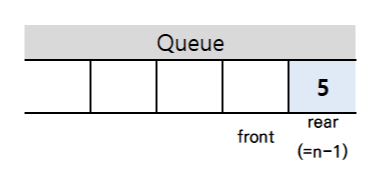
주요 연산
- enQueue : 삽입, 메소드 in Java : offer()
- deQueue : 삭제, 메소드 in Java : poll()
큐 용도
- 버퍼 : 데이터를 한 곳에서 다른 한 곳으로 전송하는 동안 일시적으로 그 데이터를 보관하는 메모리의 영역 (입출력 및 네트워크에서 사용)
- BFS
- 작업 스케쥴링
Circular Queue
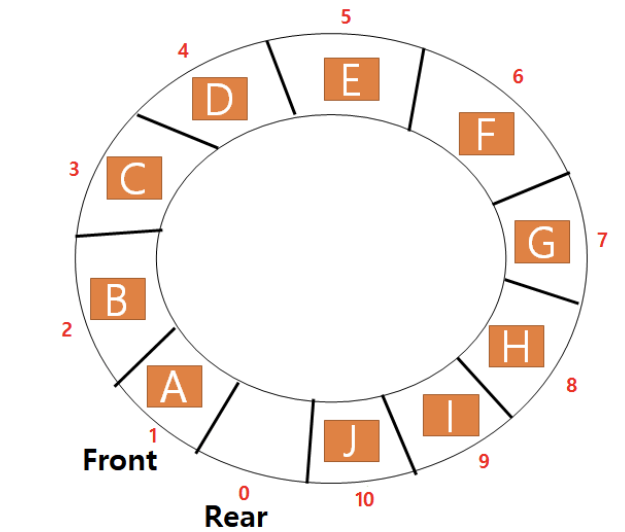
설명
- 일차원 배열을 사용하여 구현한다.
- 초기 front와 rear는 맨 처음 인덱스에 위치한다.
- front와 rear를 회전시키기 위해서 모듈러(%)연산을 사용한다.
주요 연산
- enQueue : (rear+1) % (배열의 크기), 만약 rear+1이 front와 같으면 해당 큐는 꽉 찼다.
- 배열의 크기가 11인 배열의 index 10까지 모두 채우면, 다음 rear은 11이 아니라 0이 된다.
- deQueue : (front+1) % (배열의 크기)
- size : (배열의 크기 + rear - front) % (배열의 크기)
- 주의할 점 : rear == front(가득 찼을 때)도 마찬가지로 0이 된다.
- full : (rear + 1) % (배열의 크기) == front
- 왜 위처럼 복잡하게?
- 큐를 한칸 빼주기 때문에 위의 그림은 가득찬 상태로 본다.
- empty : rear == front
Priority Queue
설명
- Queue 인터페이스를 구현하였다.
- 저장한 순서에 상관없이 우선순위(priority)가 높은 것부터 꺼낸다.
- null을 저장하면 NullPointerException이 발생한다.
- 배열을 사용하며, 각 요소를 힙이라는 자료구조의 형태로 저장한다. ( JVM의 힙과 자료구조의 힙은 다르다!)
- Priority Queue API
Queue pq = new PriorityQueue();
pq.offer(9);
pq.offer(3);
pq.offer(5);답 : 3,5,9
- 위의 pq를 출력하면 3,5,9가 나온다. 저장순서와 출력순사가 다르다. 우선순위는 숫자가 작을수록 높아져서 3이 가장 먼저 출력된다.
구현방법은 3가지가 있다.
- 배열을 기반으로 구현하는 방법
- 연결 리스트를 기반으로 구현하는 방법
- 힙(heap)을 이용하는 방법
배열이나 연결리스트로 구현할 경우 간단하게 구현이 가능하지만, 데이터 삽입과 삭제 과정에서 데이터를 한 칸씩 당기거나 밀어야 하는 연산을 계속 하여야 함.
또 삽입의 위치를 찾기 위해 배열에 저장된 모든 데이터와 우선순위를 비교해야 한다.
연결리스트의 경우, 삽입의 위치를 찾기 위해 첫번째 노드부터 시작해 마지막 노드에 저장된 데이터와 우선순위 비교를 진행해야 할 수도 있다. -> 성능 저하
그래서 일반적으로 힙을 이용해 구현한다.
Deque
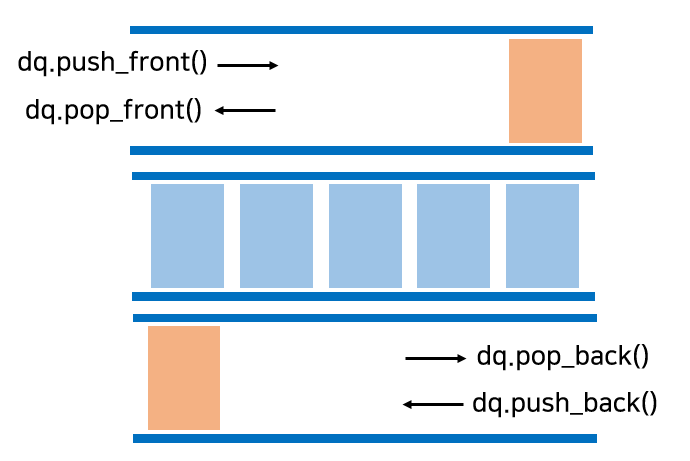
설명
- 자료의 추가와 삭제를 양쪽 끝에서 가능하게 하는 자료구조, 큐와 스택을 합친 형태로 생각할 수 있다.
- 연속적인 메모리를 기반으로 하는 '시퀀스 컨테이너'이다. 따라서, 임의 접근 반복자 제공.
- Deque API
유형
- scroll : 입력 제한 덱, 입력이 한쪽에서만 일어나도록 제한
- self : 출력 제한 덱, 출력이 한쪽에서만 일어나도록 제한
덱의 응용
- 스케줄링 : 스케줄링이 복잡해질 수록 스택과 덱보다 효율이 잘 나오는 경우가 있다.
- 우선순위 조절 : 한방향으로만 삽입/삭제가 가능한 스택과 큐와 달리 양방향으로 삽입 삭제가 자유롭기 때문에.
출처
- https://www.geeksforgeeks.org/circular-queue-set-1-introduction-array-implementation/
https://velog.io/@choiiis/%EC%9E%90%EB%A3%8C%EA%B5%AC%EC%A1%B0-%EC%8A%A4%ED%83%9DStack%EA%B3%BC-%ED%81%90Queue
https://chanhuiseok.github.io/posts/algo-26/
https://gusdnd852.tistory.com/241
https://gusdnd852.tistory.com/242?category=748315
https://velog.io/@holicme7/%EC%9A%B0%EC%84%A0%EC%88%9C%EC%9C%84-%ED%81%90Prioirity-Queue-mbk48cz764
https://velog.io/@holicme7/%EC%9A%B0%EC%84%A0%EC%88%9C%EC%9C%84-%ED%81%90Prioirity-Queue-mbk48cz764
https://moonong.tistory.com/34
http://itnovice1.blogspot.com/2019/01/blog-post.html

지우의 블로그