오늘의 에러
대용량의 json 파일을 vscode에서 열어보려고 했다. 뭔가 처리되는가 싶더니 연결이 끊겼다..!
대용량 데이터 다루기
내 손에 데이터가 주어졌다. 근데 용량이 엄청 크단다. 일단은 기분이 좋아진다. 왜냐하면 데이터가 많으니까! (일단 품질이 좋든 나쁘든 데이터는 다다익선이 맞다. 버릴때 버리고 쳐낼 때 쳐내더라도 마음이 든든해진다.)
그런데 문제는 그 다음부터다. 내 컴퓨터의 메모리(RAM)가 그만큼의 데이터를 처리할 수 있다면 모르겠지만, 메모리가 처리해내기 버거울만큼의 데이터가 주어질 수도 있다. (극단적으로 내 메모리가 처리할 수 있는 한계는 200MB인데, 1GB짜리 처리해야한다던가..)
물론, 메모리를 그만큼 늘리면 해결할 수 있다. (=돈)
똑똑하게도, 컴퓨터를 만든 사람들은 임시파일이라는 형태로 나눈 다음 정렬하는 방법을 채택했다. (이미지 소스)
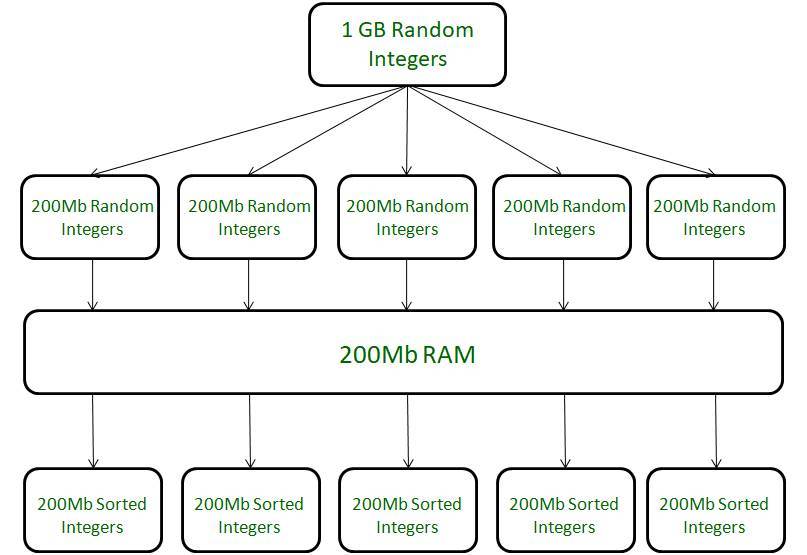
내용을 명확히 이해한 건 아니지만, 큰 덩어리를 잘라서 활용한다는 것 같다.
파이썬에서 동일한 역할을 하는 게 readline()이라는 함수같다. 이전까지는 readlines()로 한꺼번에 읽어왔었는데, 그건 사실 실습 중에 몇 줄 안되는 파일을 읽어오는 거라 가능했던 것 같다.
너무 크면 vscode가 멈춥니다.
클릭해서 여는 것도, 아래의 코드를 실행하는 것도 vscode와 내 뇌가 정지되는 현상이 발생하므로, 웬만하면 읽을 땐 쓰지 말자. 덕분에 좋은 걸 배웠다.
# 대용량의 파일을 이런식으로 읽어오면 프로그램이 멈추고, 메뉴바에 있는 런캣이 미친듯이 달려간다.
import json
with open('./ko_wiki_v1_squad.json', 'r') as f:
squad_dataset = f.readlines()
print(squad_dataset)앞으로는
메모리도 생각해가면서 코드를 적어야겠다. 아래와 같이!
import json
with open('./ko_wiki_v1_squad.json', 'r') as f:
squad_dataset = f.readlines()
for line in squad_dataset:
print(line) # 이 부분을 process()라는 함수를 사용하는 것 같은데, 나중에 찾아봐야겠다.
print(squad_dataset)혹은
import json
N = 30
with open('./ko_wiki_v1_squad.json', 'r') as f:
head = [next(f) for _ in range(N)] # next() 함수를 사용하는데, 나중으로 미뤄둔다.
print(len(head))
for l in head:
print(l)또는 이렇게 써볼 수도 있고,
import json
with open('./ko_wiki_v1_squad.json', 'r') as f:
lines = f.readlines()
for l in lines[10:21]: # 이렇게 하면 원하는 부분만 읽어올 수 있다.
print(l, end ='')readline()을 활용해볼 수도 있다.
참고 사이트
나중에 찾아볼 것들
next()process()

꿈꾸는 몽상가