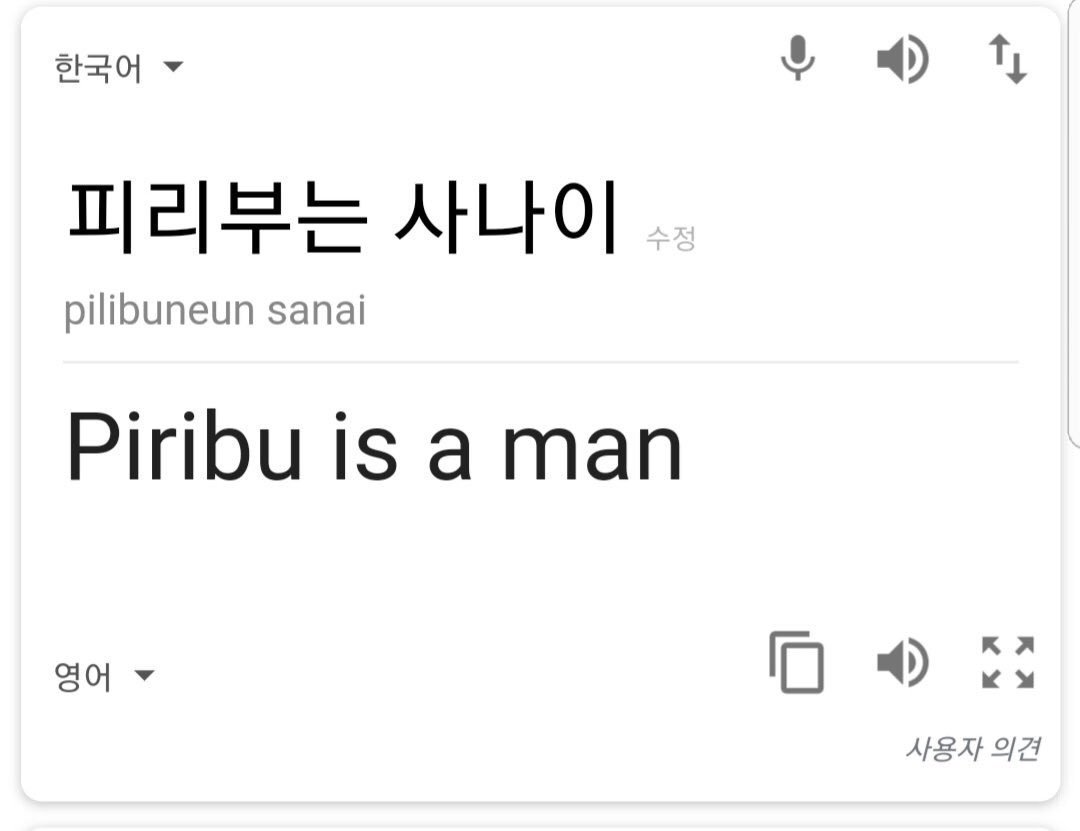
어디선가 한번은 봤던 것 같은 사진입니다. 몇 년 전, 피리부는 사나이의 구글 번역 결과입니다. 현재는 the piped man으로 수정되어 번역되고 있습니다. 피리부 씨는 왜 사나이가 되었을까요. 또, 어떻게 지금은 우리가 원하는 뜻으로 수정되어 번역되고 있을까요.
인공지능이 발전함에 따라 자연어 처리 기술과 성능 또한 자연스럽게 발전하고 있습니다. 많은 기업이 상담원 대신 24시간 대응 가능한 상담 챗봇 서비스를 제공하고 있고, Papago, Google 번역과 같은 번역기의 성능은 나날이 좋아지고 있습니다. 본 게시글에서는 나날이 발전하고 있고 앞으로도 계속 발전해나갈 자연어처리 Task를 살펴보겠습니다.
자연어 처리란 무엇인가
자연어 처리에 대해서 알기 전에 자연어가 무엇인지 알아보도록 하겠습니다.
자연어 (Natural Language)란 프로그래밍 언어와 같이 사람이 인공적으로 만든 언어가 아닌, 우리가 일상 생활에서 사용하는 언어입니다. 이를테면 한국어, 영어, 프랑스어와 같이 일상 생활과 의사 소통을 위해 사용하는 언어라고 할 수 있지요.
이 자연어를 기계가 이해할 수 있게, 즉 컴퓨터가 인간의 언어를 알아들을 수 있게 만드는 것을 자연어 처리 (Natural Language Processing)라고 합니다. 이렇게만 보면 자연어 처리가 대체 어떤 것을 연구하는 학문인지 감이 잘 오지 않습니다. 다양한 자연어 처리 Task를 살펴보며 자연어 처리에 대해 이해해보는 시간을 갖도록 하겠습니다.
간단한 소개만 진행하고 자세한 내용은 추후 다른 게시글에서 다루도록 하겠습니다.
NLP Task
편의상 자연어 처리를 NLP라 작성하겠습니다.
NLP는 현재 다양한 분야에서 연구 및 사용되고 있는데, 가장 보편적인 NLP Task에 대해 알아보도록 하겠습니다.
텍스트 분류 (Text Classification)
정리정돈을 잘하자!
어렸을 때 어른들로부터 줄곧 들어온 소리입니다. 정리정돈의 중요성은 누구보다 잘 알고 있지만 잘 실천하지는 못하죠. 하지만 정리정돈을 잘하면 다양한 상황에서 편리하며 소모되는 시간이 줄어드는 것은 자명합니다.
쉴 새 없이 축적되는 데이터를 잘 분류하는 것은 두 말하면 입 아플 정도로 중요합니다. 잘 분류된 데이터를 이용한다면 처리 속도는 당연히 증가할 것이며, 소모되는 시간과 비용은 현저히 감소할 것입니다. 기계가 데이터 분류, 그 중에서도 텍스트를 잘 분류할 수 있도록 하는 것이 텍스트 분류 (Text Classification)의 목적입니다.
텍스트 분류는 텍스트가 가진 정보를 이용해 분류하는 문제로, 두 가지로 나뉩니다. 분류해야 할 범주가 두 가지라면 이진 분류(Binary Classification)라고 하며, 세 가지 이상이라면 다중 분류(MultiClass Classification)라고 합니다.
이진 분류에 대해 먼저 살펴보자면 말 그대로 두 가지 중 한 가지로 분류되는 문제를 다룹니다.
다음과 같은 항목이 이진 분류에 해당하는 항목입니다.
- 스팸 메일인지 일반 메일인지
- 긍정적 문장인지 부정적 문장인지
- 식물인지 동물인지
다중 분류는 세 가지 이상의 범주 중 한 가지로 분류되는 문제를 다룹니다.
다음과 같은 항목이 다중 분류에 해당하는 항목입니다.
- 뉴스 기사 분류 (정치, 경제, 스포츠, IT 등)
- 상품 리뷰 분류 (노트북, 스마트폰, 이어폰 등)
- 감성 분석 (기쁨, 슬픔, 우울함 등)
기계 번역 (Machine Translation)
이제 더이상 해외에서의 의사소통을 두려워하지 않아도 됩니다. 네이버 Papago, Google 번역과 같은 번역 서비스는 다양한 언어로 번역이 가능할 뿐만 아니라 음성으로 읽어주기까지 합니다. 번역 서비스는 그동안 참 많은 발전을 이루어 왔고 앞으로도 꾸준히 발전할 것입니다.
기계 번역은 규칙 기반 기계 번역(Rule-Based Machine Translation)부터, 통계 기반 기계 번역(Statistical Machine Translation), 신경망 기계 번역(Neural Machine Translation)까지 발전을 이루어 왔고 뛰어난 성능을 보여주고 있습니다.
번역하고 싶은 문장을 Source Text, 번역된 문장을 Target Text라 하겠습니다.
규칙 기반 기계 번역(Rule-Based Machine Translation)은 Source Text와 Target Text의 문법 규칙을 기반으로 번역하는 방법입니다. Source Text의 형태소 분석, 구문 분석, 의미 분석, 화용 분석을 거쳐 이에 역순으로 Target Text를 생성합니다. 문법 규칙이 유사한 경우 형태소 분석, 구문 분석, 의미 분석, 화용 분석 중 생략되는 단계가 존재할 수 있습니다.
규칙 기반 기계 번역(Rule-Based Machine Translation)은 언어학적 지식이 상당수 필요하다는 것이 가장 큰 단점으로 꼽힙니다.
통계 기반 기계 번역(Statistical Machine Translation)은 이름에 나타난 것처럼 통계적으로 번역하는 방법입니다. 통계적이라 함은 사전에 데이터가 존재해야 함을 의미합니다. 데이터를 바탕으로 Word Alignment를 진행해 얻을 수 있는 대역어 테이블에서 단어 혹은 구 단위로 묶어 번역 모델을 생성하는 과정을 거쳐 Source Text와 가장 비슷하다고 예측한 Source Text를 생성합니다.
통계 기반 기계 번역(Statistical Machine Translation)은 어순이 다른 언어 간 번역이 이루어질 때 성능이 부족하다는 것이 가장 큰 단점으로 꼽힙니다.
신경망 기계 번역(Neural Machine Translation)은 인공지능이 발전하면서 새로이 등장한 기계 번역 방법입니다. 신경망 기계 번역이 등장하기 전, 번역 서비스는 통계 기반 기계 번역을 기반으로 제공되고 있었습니다. 하지만 신경망 기계 번역이 등장하고 점차 통계 기반 기계 번역을 대체하고 있습니다.
신경망 기계 번역(Neural Machine Translation)은 데이터를 통해 학습된다는 점에서 통계 기반 기계 번역과 유사하다고 볼 수 있으나, 통계 기반 기계 번역이 사용하는 데이터보다 더욱 방대한 데이터를 통해 딥러닝한다는 점이 신경망 기계 번역의 특징입니다.
신경망 기계 번역(Neural Machine Translation)의 가장 큰 단점은 데이터의 질과 양에 따라 언어별 번역 정확도가 다르다는 것입니다. 상대적으로 데이터의 양이 많은 영어와 데이터의 양이 적은 한국어, 태국어 등 단일 국가에서 사용하는 언어에 대한 번역 정확도는 서로 상이한 결과를 보입니다.
텍스트 요약 (Text Summarization)
세 줄 요약 좀
장문의 게시글을 게시하거나, 메세지를 작성하여 전송하면 독자, 상대방이 흔히 보이는 반응입니다. 수능을 준비하던 수험생 시절 우리를 괴롭혔던 언어, 외국어 영역의 요약 문제를 풀 때 빠르고 정확하게 요약할 수 있는 초능력이 발휘되었으면 하는 바람을 항상 가지곤 했었지요.
이렇듯 텍스트 요약(Text Summarization)은 정말 중요한 Task입니다. 다수의 문단, 더 나아가 다수의 문서로 이루어진 텍스트 정보를 한 눈에 파악하기란 아주 어려운 일입니다. 또, 전문 용어가 가득한 텍스트를 마주 하는 날에는 눈 앞이 깜깜해져 버립니다.
텍스트 요약(Text Summarization)은 원문을 잘 반영하면서도 간결하고 이해하기 쉬운 형태의 문장, 혹은 문단으로 요약하는 Task입니다. 원문의 문장을 포함한 요약인 Extractive Method와 원문의 의미를 해석하여 새로운 문장을 생성하는 요약인 Abstractive Method가 존재합니다.
텍스트의 핵심 내용을 빠르고 정확하게 판단할 수 있는 좋은 요약문을 생성하기 위한 연구는 활발히 진행중이며, 더욱 발전되어야 할 연구 분야입니다.
NLP가 풀어야 할 숙제
저를 지도하신 교수님께서는 NLP에 100%는 없다라고 항상 강조하셨습니다. 텍스트 분류, 기계 번역, 텍스트 요약을 포함한 다양한 NLP Task는 100%의 정확도를 보이지 못합니다. 하지만 100%에 근접하는 정확도를 보이기 위한 노력은 계속되어야 하며, 계속될 것입니다.
본 게시글에서 소개한 Task를 제외하고도 많은 NLP Task가 존재합니다. 본 게시글에서는 제가 생각했을 때 가장 보편적이라고 생각하고 관심 있는 NLP Task를 소개하였습니다.
다음 게시글에서는 소개한 NLP Task들을 하나씩 자세하게 살펴보도록 하겠습니다.
피드백은 항상 감사히 받습니다. 게시글에 수정해야 할 내용이 있다면 댓글로 알려주세요!
