[Paper Review] Specializing Smaller Language Models towards Multi-step Reasoning
NLP-Paper-review

Main Idea
Large Language Model(LLM)의 퍼포먼스가 높아지면서 Small Language Model(SLM)가 할 수 없는 Task들이 점차 생겨나고 있다. 특히 Multi-step reasoning(복잡 논리 추론) in math problem by Chain-of-Thought(CoT) prompting에 대해서 SLM은 전혀 학습을 하지 못한다.
Model Specializing 을 통해 본 논문에선 다음과 같은 가설을 증명한다.
H0 : LLM은 엄청난 모델 파워가 있지만 수행능력이 너무 퍼졌다. 그에 반에 SLM은 제한적인 모델 파워(Capacity)가 있지만, 이 모델 파워를 Task수행능력에 집중시킬 수 있다.
(Capacity란 전반적인 Task들을 수행할 수 있는 능력을 말하며, 이를 줄이고 특정 Task에만 집중하면 그 Task만은 좋은 성능을 보일 수 있다는 가설이다. 즉, Capacity와 Target task performace의 trade-off가 생길 것)
Method
Instruction 기학습된 FlanT5모델을 GPT3.5(Large Teacher Model)에서 배출하는 CoT prompt를 distilling하여 파인튜닝을 하도록 방법론을 설계한다. 또한, GSM8K를 활용하여 CoT를 파인튜닝 했기 때문에 다른 데이터에서의 퍼포먼스 체크를 위해 3가지 다른 Math reasoning data로 증명(OOD: out-of-distribution).
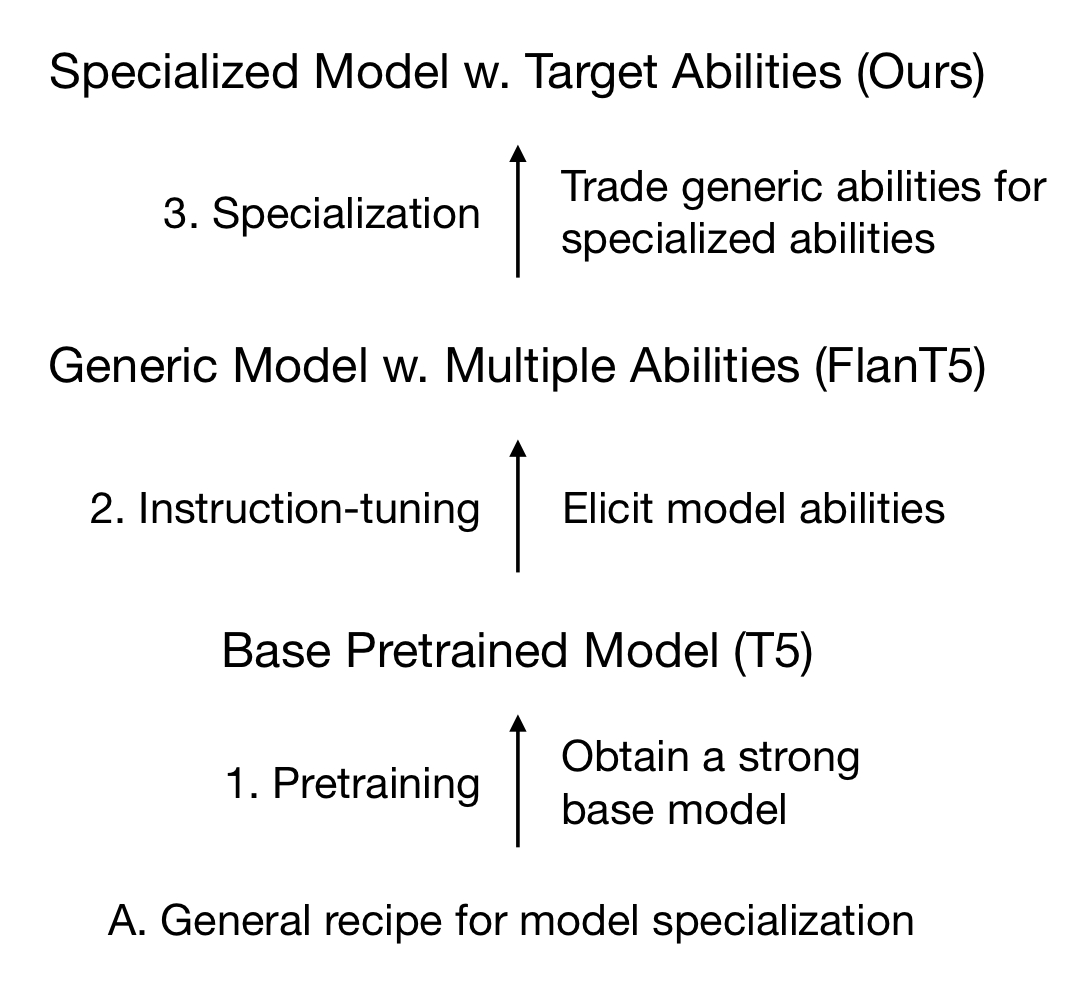
다만, 실험설계의 약간의 미스를 조정하기 위한 4가지 단계가 있다.
1. Different Tokenizers. Dynamic Programming을 통해 해결(하지만, 필자는 이부분을 이해하지 못하여 5번째 읽는 중입니다...! / 의견 주세요!!! 제발!!!!)
2. checkpoint마다 distill퍼포먼스가 다르다 (언제나 FlanT5가 더 좋았으며, T5도 specialize이후 성능이 더 좋긴 했다.)
3. 내부 데이터의 성능과 외부 데이터의 성능의 영향이 일정하지가 않다. 따라서 tuning data에 대해서 모델 선택을 하지 않는다 (이 부분 해석이 잘 안되었습니다 ㅜㅜ)
4. Trade-off가 양방향으로 일어난다. distill하여 trade-off가 일어난 후 성능 체크를 위해 BigBench Hard 데이터에 대해 튜닝을 하니, CoT Prompting파워를 잃어버렸다.(굉장히 신기했던 부분 어쩌면 trade-off가 아닌 adaptation이 빠른게 아닐까 싶은 생각이 있다.)
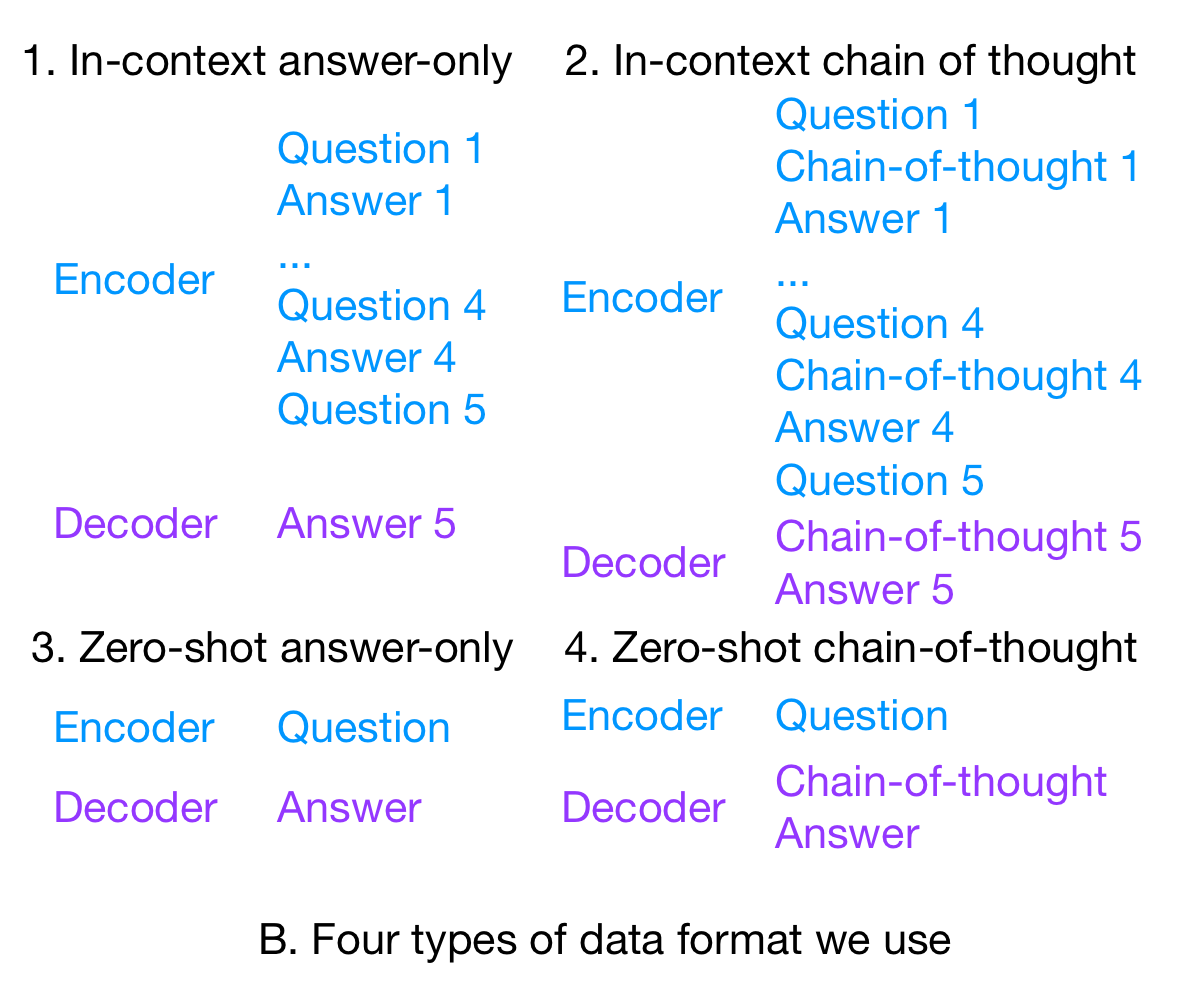
다른 신기한 실험 결과는 in-context example에서는 in-context learning와 zero-shot 성능 둘다 향상했지만, zero-shot example에서는 zero-shot이 in-context learning성능을 흡수하는 trade-off현상이 일어났다.
Insight
- 모델의 capacity를 target task 퍼포먼스로 적응시킬 수 있다.
- 그 과정에서 어떤 걸 얻고 소모되는 지 정확한 실험 설명을 통해 확인할 수 있다.
- 단순히 오버피팅이 되지 않았음을 OOD를 통해 증명했다.
Experiment Setup
- Train Data: GSM8K
- Test Data: MultiArith, ASDiv, SVAMP, BigBench Hard
- BaseModel: Flan-T5
- Teacher Model(generate distillation / specialize data): GPT3.5(code-davinchi-002)
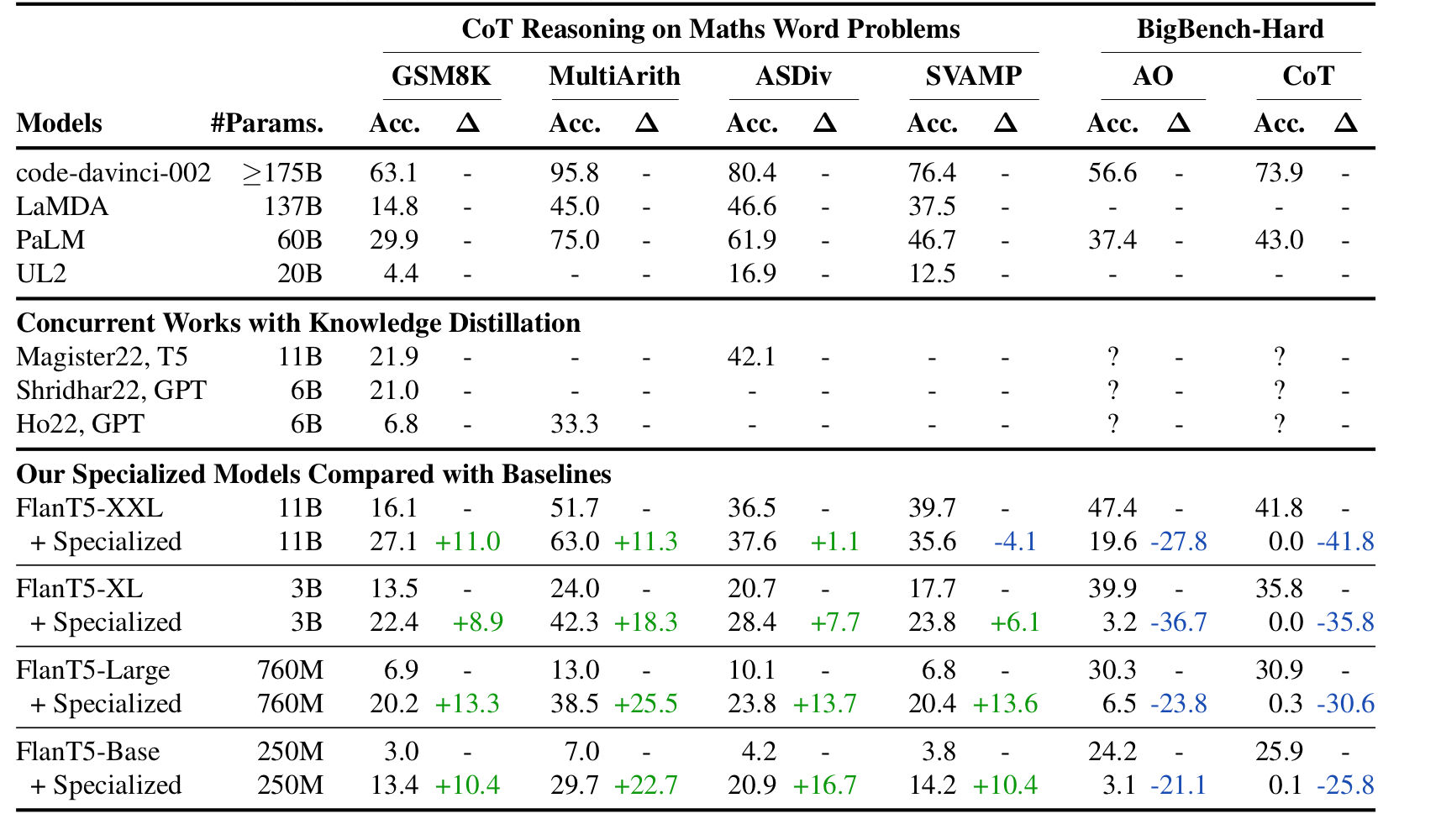
우측의 BigBench-Hard가 원래의 Model Capacity를 측정하는 지표라고 생각하면 된다. 따라서 모델의 전체적인 성능이 정말 떨어지며 Math Problems에 대해서 성능이 확실히 향상된 것을 확인할 수 있다..!!!(놀랍다...!!)
SVAMP에 대해서는 FlanT5-XXL모델이 Specialize가 됬음에도 불구하고 성능이 하락했다. FlanT5중에 가장 파라미터가 높은데 이런 성능을 보이는 것은 어쩌면 이런 distillation은 student모델이 작을수록 새로운 데이터에 대한 학습 수용량이 크다는 걸 뜻하는 것인지 실험을 해볼 필요는 있어보인다.
2.정말 Specialize가 유의미한 결과를 낳았을까?

좌측부터 SLM이 in-context learning을 아예 못한다는 것을 증명하며, 오른쪽으로 갈수록 SLM이 COT에 대해 올바르게 학습이 가능하다는 것을 보여준다.
Reference
- Fu, Y., Peng, H., Ou, L., Sabharwal, A., & Khot, T. (2023). Specializing Smaller Language Models towards Multi-Step Reasoning. arXiv preprint arXiv:2301.12726.
