모델 정확도 평가 척도
코로나 환자의 예를 살펴보자, 음성환자에게 양성이라 오진을 냈을 경우보다 양성인 환자에게 음성이라 오진을 낸 경우 환자에게 더 심각한 결과를 가져올 수 있다.
같은 오진이라도 양성을 잡아내는 데 실패하는 오진과 음성 잡아내는 데 실패하는 오진은 그 중요도가 다를 수 있다.
이렇게 정답과 오답을 구분하여 표현하는 방법을 오차 행렬(confusion matrix)이라고 한다.
https://manisha-sirsat.blogspot.com/2019/04/confusion-matrix.html
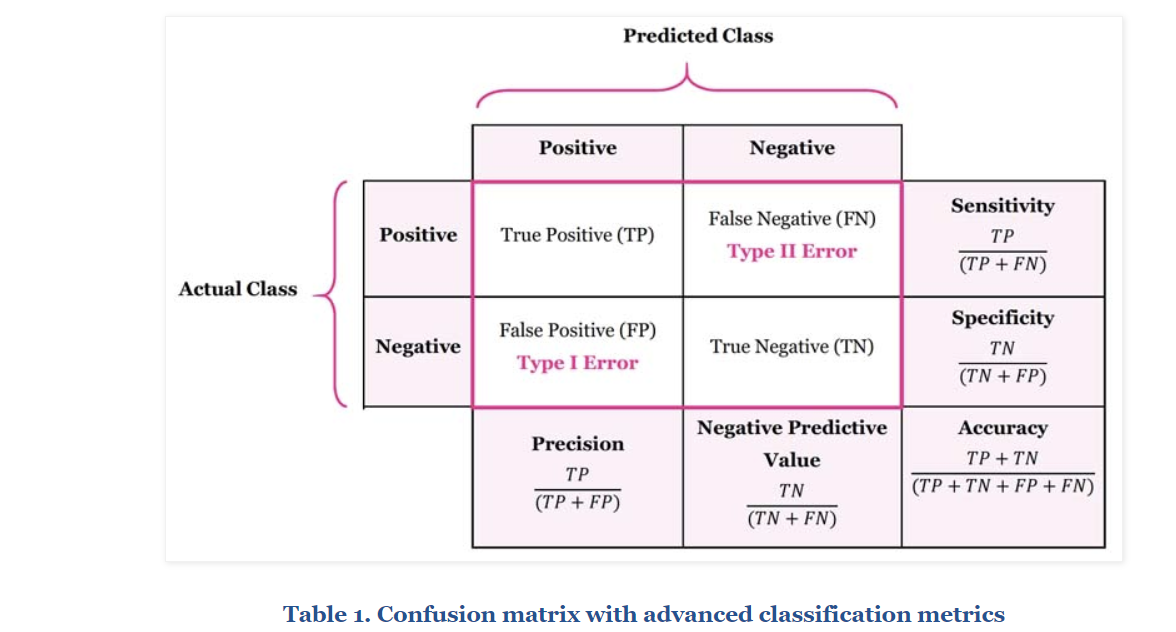
Confusion Matrix란?
Classifier(분류하는 모델)의 성능을 평가하는 도구라고 할 수 있다. 실제 정답(y)과 예측 정답(x)들에 대한 정보를 담고 있다.
x축 / (column-열): "yes" 또는 "no" 라고 한 예측 들 (예. 이건 스팸이야~, 이건 스팸이 아니야~)
y축 / (row- 행): 실제로 존재하는 yes or no (예. 환자 or not 환자, spam or not spam)
스팸 e-mail을 예측하는 사례를 보자.
True Positive(TP): 스팸을 알맞게 스팸이라고 예측한 경우
True Negative(TN): 정상 이메일을 알맞게 정상 이메일로 예측한 경우
False Positive(FP) / Type 1 Error: 스팸인 아닌 이메일을 스팸이라고 잘못 예측한 경우
False Negative(FN) / Type 2 Error: 정상 이메일을 스팸이라 잘못 예측한 경우
쉽게 이해하기 위해 positive, negative을 예측으로 이해하면 될 것 같다. Positive이라고 하면 "너 이거 맞지!?" 예시로 "너 환자지!?"라고 긍정예측한 경우다. 여기서 포인트는 예측이란 것, 즉 끝에 '?'가 들어간다. 반대로 Negative이라는 것은 "너 환자 아니지!?", 혹은 "너는 ~가 아니야" 라고 부정예측한 것이다. 여기서 환자냐~, 스팸이냐~가 아닌 긍정 예측이냐, 부정예측이냐에 포커스를 두는 것이 핵심이고 앞에 True가 붙으면 뒤에 예측이 맞은 것이고, False가 붙으면 뒤에 예측이 틀린것이다.
Sensitivity, Specificity, Precision, Accuracy
- Sensitivity - True Positive Rate - Recall(민감도)
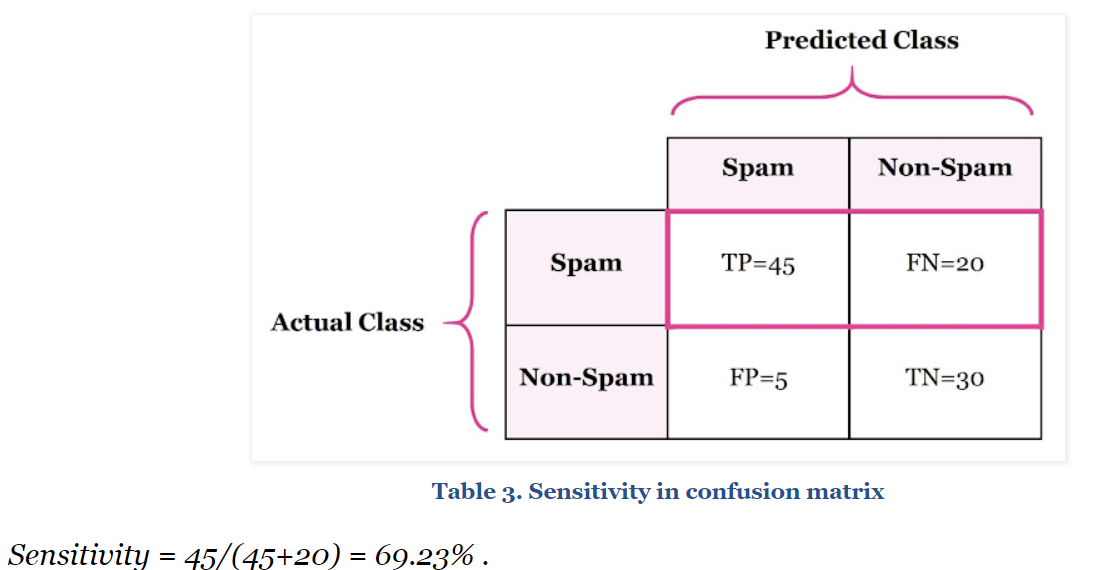
TP / TP + FN
실제 Positive를 얼마나 잘 예측했는지를 나타내는 지표이다
실제 스팸 이메일에 대한 예측의 정확도를 측정하는 척도라 이해하면 될 것 같다.
스팸 이메일을 "스팸이다~"라고 알맞게 예측한 경우와 "스팸이 아니다"라고 예측했는데 틀린 경우를 합해서 맞춘 개수, 확률을 True Positive Rate 또는 Recall로 이해하면 될 것 같다.
위 같은 경우 스팸메일 총 65개중 45를 알맞게 분류하였고 recall은 69.23%가 나왔다.
- Specificity or True Negative Rate

TN / FP + TN
실제 negative을 얼마나 잘 예측했는지를 나타내는 지표이다. 스팸이 아닌 정상 이메일을 중 정상이메일을 얼마나 잘 예측했는지를 측정하는 척도이다.
정상이메일에 대한 총 예측 나누기 알맞게 예측한 수
다른 예시로 환자가 아닌데 환자라고 예측한 경우를 떠올릴 수 있다
더 나아가서 false positive rate을 구할 수 있는데
False Positive Rate = 1 - Specificity
- Precision 정밀도
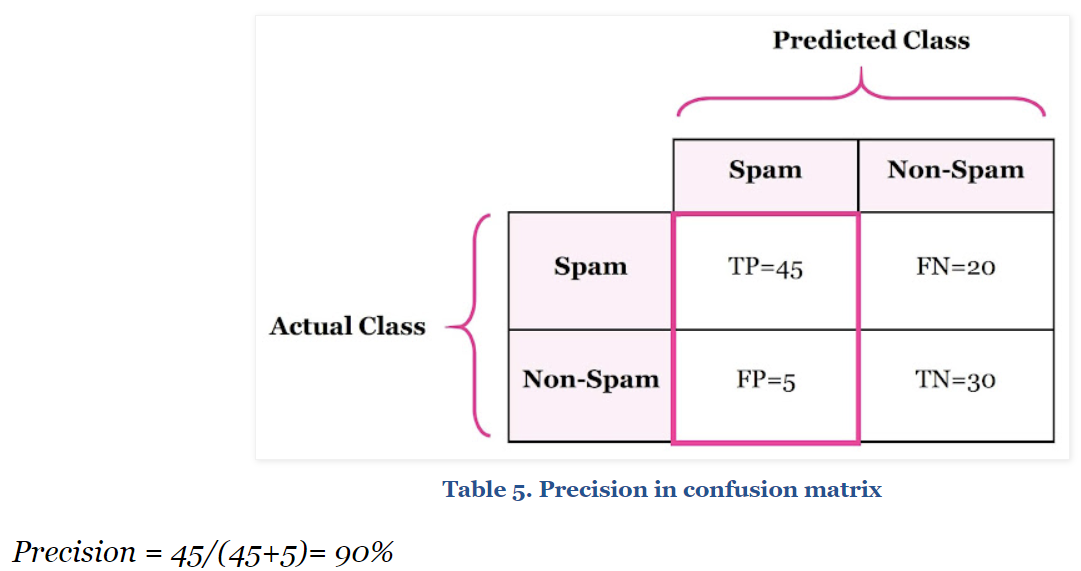
TP / TP + FP
Positive이라고 한 예측들의 정확도 라고 얘기하겠다.
너 스팸이지~, 너 환자 맞지~ 라고 예측 했는데 그 중 실제 스팸 또는 환자였던 경우와 스팸 또는 환자가 아니었던 경우를 측정한다.
다시 말해 너 환자라고 예측했는데 예측이 맞았던 경우와 틀렸던 경우를 구한다.
- Accuracy 정확도
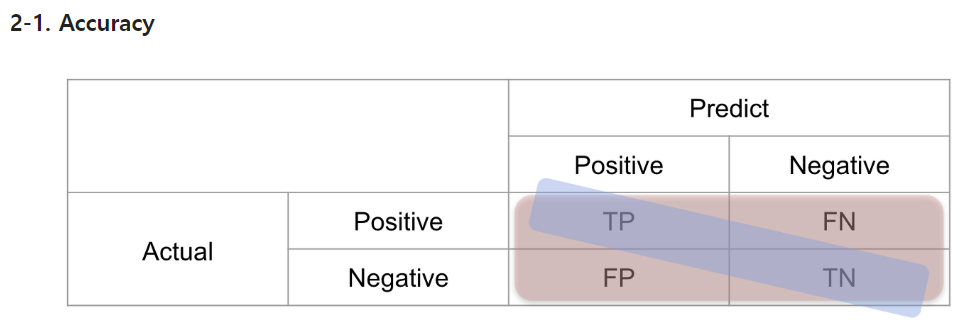
전체 예측한 것 중에 올바른 예측을 얼마나 했는지를 지표로 구하는 것이다
TP + TN / TP + TN + FP + FN
accuracy가 높을수록 에측 정확도가 높다고 할 수 있다
더 나아가 Error Rate을 구할 수 있는데
Error Rate = 1 - Accuracy
Error Rate이란? 잘 예측한 것을 나타내는 정확도와의 반대인 잘 못 예측한 정도다
- Accuracy는 balanced data(균형이 잘 잡힌 데이터)에서만 사용하는 것이 좋다고 한다
- Accuracy의 한계점으로 부정인 것을 예측 잘 못한다고 한다.
F1 Score
- 보통 imbalanced data 평가척도로 자주 사용
