1 프로세스
• 프로세스 개요
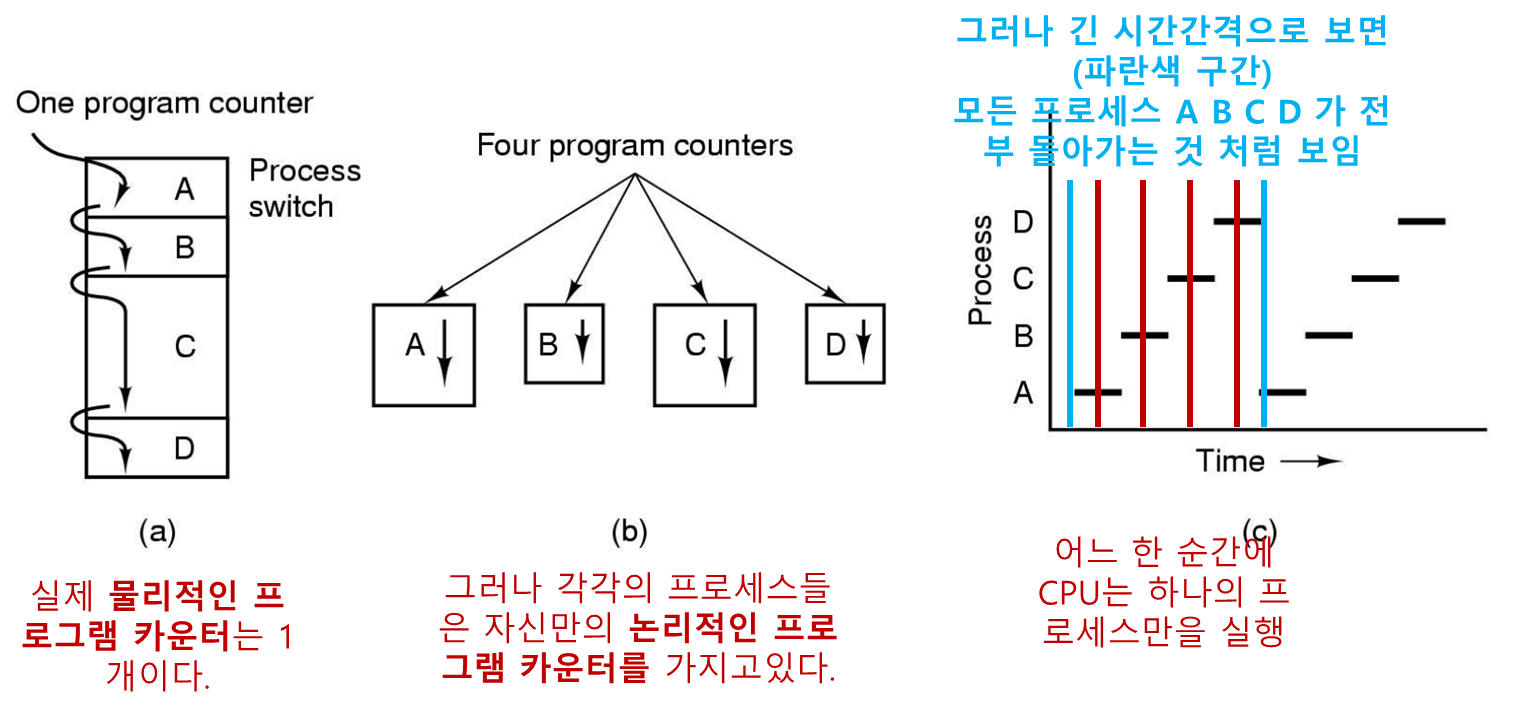
현대 컴퓨터는 여러가지 일을 하고, 이러한 다중 작업을 지원하기 위해 여러 프로세스를 지원하는 다중프로그래밍 시스템이 사용된다.
모든 다중 프로그래밍 시스템에서 CPU는 한 프로세스에서 다른 프로세스로 빠르게 전환하며 각 프로세스를 수십에서 수백 밀리
초동안 실행한다.
어느 한 순간에 CPU는 오직 하나의 프로세스만을 실행하지만 1초 시간간격(혹은 더 긴 시간간격) 으로 보면 CPU는 여러개의 프로세스들을 서비스하여 수행하는 것 처럼 보인다(병렬 수행의 환상: 의사병렬성)
프로세스와 프로그램의 차이?
-
프로그램 : 적당한 표기법으로 표현된 알고리즘(수행 파일 .exe)
-
프로세스 : 프로그램에 명시된 알고리즘을 실제로 수행하는
행위
예를 들어
- 요리책 (프로그램)
- 요리 재료 (입력 데이터)
- 요리하는 사람 (CPU)
- 요리책을 읽고 재료를 가져와서 요리를 하는 행위 (프로세스)
프로세스 구성
-
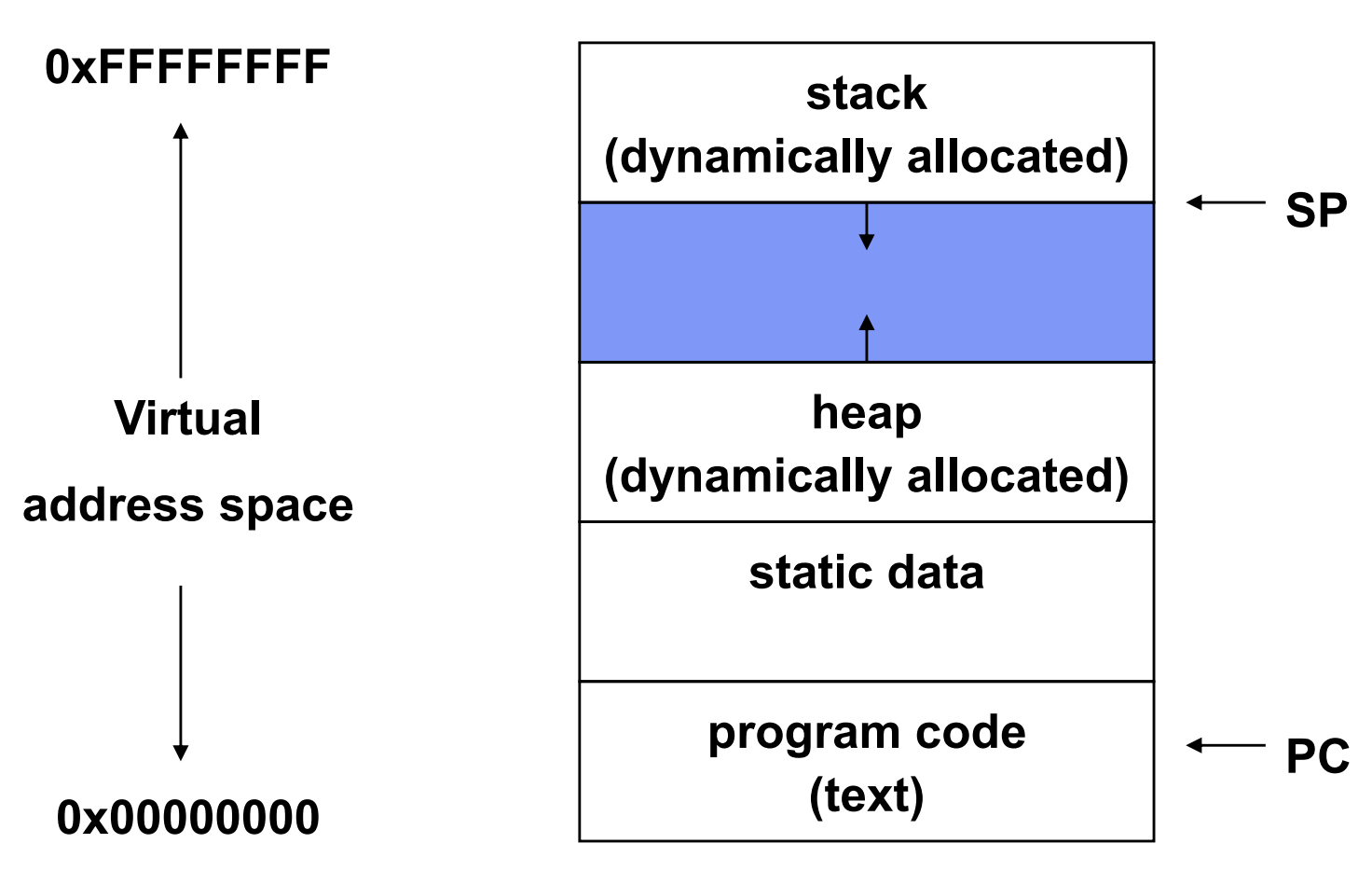
메모리에 매핑된 보호되있고 가상의 주소 공간
-
수행 프로그램의 코드와 데이터
-
실행 스택과 스택 포인터(SP), heap
-
Program Counter
-
프로세서 레지스터 집합
-
시스템 리소스 집합
프로세스 주소 공간
OS 에서의 프로세스 표시
프로세스는 생성시 PID 라는 프로세스만의 고유한 아이디를 할당받는다.
OS에서 프로세스들은 프로세스 테이블(PT) 라는 엔트리로 표시가 된다.
- 이때
PID는PT 엔트리의 인덱스 혹은 포인터이다. PT 엔트리=Process Control Block(PCB)- PCB는 프로세스에 대한 모든 정보를 포함하거나 가리키는(포인터) 큰 데이터 구조이다.
모든 프로세스들의 정보가 담겨 있으며 커널 메모리 영역에 만들어진다.
• 프로세스 생성
운영체제는 프로세스를 생성하는 방법을 가지고 있어야 한다.
다음은 프로세스의 생성을 유발하는 네가지 주요 이벤트들이다.
-
시스템 초기화
-
실행중인 프로세스가 프로세스 생성
시스템호출(sys call)을 부르는경우 -
사용자가 새로운 프로세스를 생성하도록 요청하는 경우
-
배치(batch)작업의 시작
OS 가 부팅할 때 프로세스 생성
참고로 OS 는 프로세스가 아니다
-
전위(foreground) 프로세스 : 사용자와 대화하고 이들을 위해 어떤 작업을 수행하는 프로세스
-
후위(backgruond) 프로세스 : 미리 정해진 어떤 기능을 수행하는 프로세스
- 데몬(daemon) : 백그라운드에 머물면서 전자 우편, 웹 페이지, 뉴스, 인쇄 등등의 작업을 담당하는 프로세스
하나의 프로세스가 다른 프로세스를 생성
실행중인 프로세스는 시스템 호출(sys call) 을 통하여 자신의 작업을 도와주는 하나 또는 다수의 프로세스들을 생성할 수 있다.
프로세스를 생성한 프로세스를 부모, 생성된 프로세스를 자식이라고 부른다.
• UNIX 에서의 프로세스 생성
UNIX 에서 새로운 프로세스를 생성하는 시스템 호출은 fork() 시스템 호출 단 하나만 존재한다.
fork()
fork()호출 이후
- fork()는 호출하는 부모 프로세스와 완전히 동일한 클론 프로세스를 생성한다.
- 새 PCB(Process Control Block)를 생성 및 초기화하고 새 주소 공간을 생성한다.
- 상위 주소 공간의 전체 내용 복사본으로 새 주소 공간을 초기화한다.
- 새 프로세스의 커널 리소스를 상위 리소스(예: 열린 파일) 로 초기화한다(부모와 자식 프로세스가 동일한 열린 파일을 갖는다).
- 새 PCB를 준비 대기열(ready Queue)에 배치한다.
부모와 자식, 두개의 프로세스가 동일한 메모리 내용, 같은 문자열, 동일한 열린 파일들을 가진다
fork() 시스템 호출은 부모와 자식에게 각각 한번씩 두번 return 한다.
자식의 PID를 부모에게 return 한다.자식프로세스에게는0을 리턴한다.
fork()를 사용한 프로세스 생성

UNIX 커널에 의해 새로운 프로세스가 생성되는 유일한 방법
- 자식 프로세스: fork()에 의해 생성된 새 프로세스
fork()는 한 번 호출되었지만 두 번 반환된다!자식프로세스에는0반환부모 프로세스에는자식의 PID반환
- 자식은 부모의 데이터, 힙, 스택을 복사하고 메모리의 이러한 부분 (다른 주소 공간)을 공유하지 않는다.

fork() 와 exec()
이전 프로그램을 fork() 하는 대신 새로운 프로그램을 시작하려면 어떻게 해야 할까?
- exec() 시스템 호출을 사용한다.
int exec(char *prog, char ** argv) ```
exec()
- 현재 프로세스를 중지한다.
- 프로그램 'prog'를 주소 공간에 로드한다.
- 하드웨어 컨텍스트(새로운 프로그램에 대한 args)를 초기화한다.
- PCB를 준비 대기열(ready queue)에 배치한다
- 새 프로세스를 생성하지 않는다
exec() 자세히 알아보기
exec를 호출하는 프로세스는 새 프로그램(텍스트, 데이터, 힙 및 스택)으로 완전히 대체되고 새 프로그램은 main()에서 시작된다.
fork() 호출 이후에 생긴 자식 프로세스는 exec() 시스템 호출을 불러 자신의 메모리 이미지를 변경하고 새로운 프로그램을 수행한다.

fork() exec() 예시
사용자가 shell에게 sort 와 같은 명령어를 입력했다고 가정하면
- shell은 자식 프로세스를 생성(fork)한다.
- 자식은 sort 를 수행한다.
이렇게 2단계를 거치는 이유는 fork 호출 이후에 자식 프로세스가 exec()를 부르기 전에 자신(자식)의 파일 디스크럽터를 조작하여 표준 입력,출력, 오류의 I/O 방향을 변경할 수 있도록 하기 위함이다.
파일 디스크럽터란?
컴퓨터 프로그래밍에서 파일이나 입출력 자원을 식별하는 데 사용되는 추상적인 지표
주로 운영 체제에서 파일, 소켓, 파이프 등의 자원을 관리하고 접근할 때 사용

• 프로세스 종료
프로세스 종료의 조건들은 다음과 같다.
-
정상적인 종료 (자발적)
-
오류 종료 (자발적)
-
치명적인 오류 (비 자발적)
-
다른 프로세스에 의해 종료 (비 자발적)
정상적인 프로세스 종료
대부분의 프로세스는 자신의 작업을 완료했기 때문에 종료한다.
컴파일러가 지정된 프로그램을 컴파일하면 컴파일러는 시스템 호출을 실행하여 OS 에게 자신의 작업이 끝났음을 알린다.
UNIX 에서는 exit() 시스템 호출을 사용한다.
오류 종료
프로세스가 치명적인 오류를 발견하면 종료된다.
예를 들어 프로그램 파일을 컴파일하려 했는데 파일이 존재하지 않는다면 컴파일러는 바로 종료한다.
치명적인 오류(버그) 종료
잘못된 명령어 실행
존재하지 않는 메모리 접근
0으로 나누기
등 치명적인 버그 발생 시 프로세스가 종료된다.
UNIX 에서 프로세스는 OS 에게 자신이 특정한 오류를 직접 처리할 것임을 알릴 수 있으며 이 경우 프로세스는 오류발생 시 종료하지 않고 인터럽트를 받는다.
다른 프로세스에 의해 종료
어떤 프로세스가 시스템 호출을 실행하여 OS 에게 다른 프로세스를 종료시켜줄 것을 요청하는 경우이다.
UNIX 에서 이러한 시스템 호출을 kill 이다.
윈도우 에서는 작업관리자 - 작업 끝내기(Terminate process)이다.
• 프로세스 계층구조
UNIX 에서의 계층구조
UNIX 에서 프로세스와 그 자식들 그리고 그들의 후손들은 모두 프로세스 그룹 을 형성한다.
여기서 프로세스는 단 한명의 부모만 가질 수 있다.
Windows 에서의 계층 구조?
윈도우에서는 계층구조를 가지고 있지 않다.
모든 프로세스들을 동등하다
프로세스가 생성될 때 토큰(또는 핸들) 이 부모 프로세스에 주어지는데 이를 통해서 자식 프로세스를 제어할 수 있다.
그러나 이러한 토큰은 프로세스 간에 자유롭게 전달할 수 있어서 계층 구조를 무력화 시킬 수 있다.
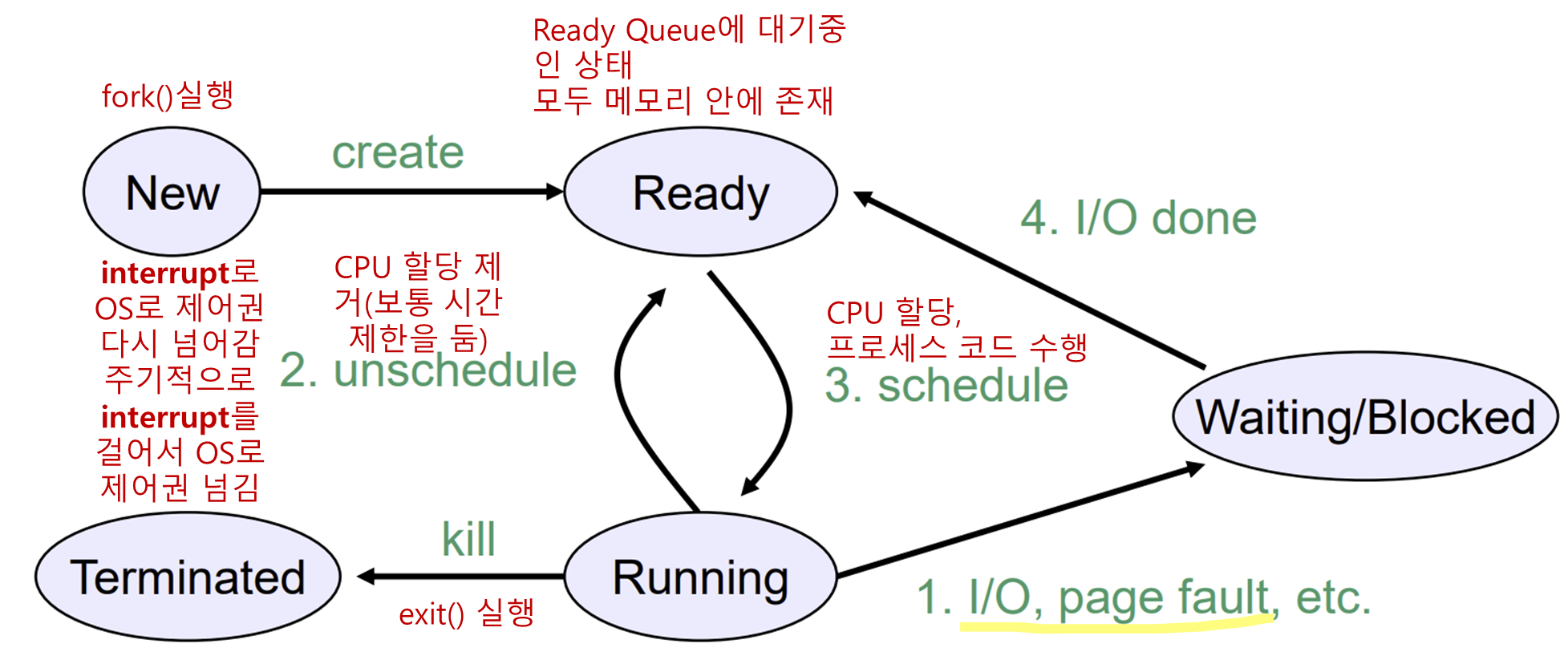
• 프로세스 상태
프로세스에는 3가지 상태가 있다.
-
실행(running) 상태 : 이 순간 CPU를 실제로 사용하고 있다.
-
준비(ready) 상태 : 실행가능하지만 다른 프로세스가 실행중(CPU를 사용중)이므로 일시적으로 정지하는 상태.
-
대기(blocked) 상태 : 외부 이벤트가 발생할 때 까지 실행할 수 없는 상태.
보통 입력을 기다리는 경우처럼 논리적으로 프로세스가 게속 수행을 할 수 없는 상태를 뜻함.
프로세스 상태 전이 그림
• 프로세스 구현
프로세스 모델을 구현하기 위해 OS 는 프로세스 테이블(PCB Process Control Block) 이라 불리는 각 프로세스마다 하나의 엔트리가 존재하는 테이블을 유지한다.
PCB 에는 프로세스 상태에 대한 다음과 같은 정보를 저장한다.
-
프로그램 카운터
-
스택 포인터
-
메모리 할당
-
열린 파일들의 상태
-
과금 및 스케줄링 정보
-
기타 프로세스 상태가 전환될 때 저장되어야 할 모든 정보들

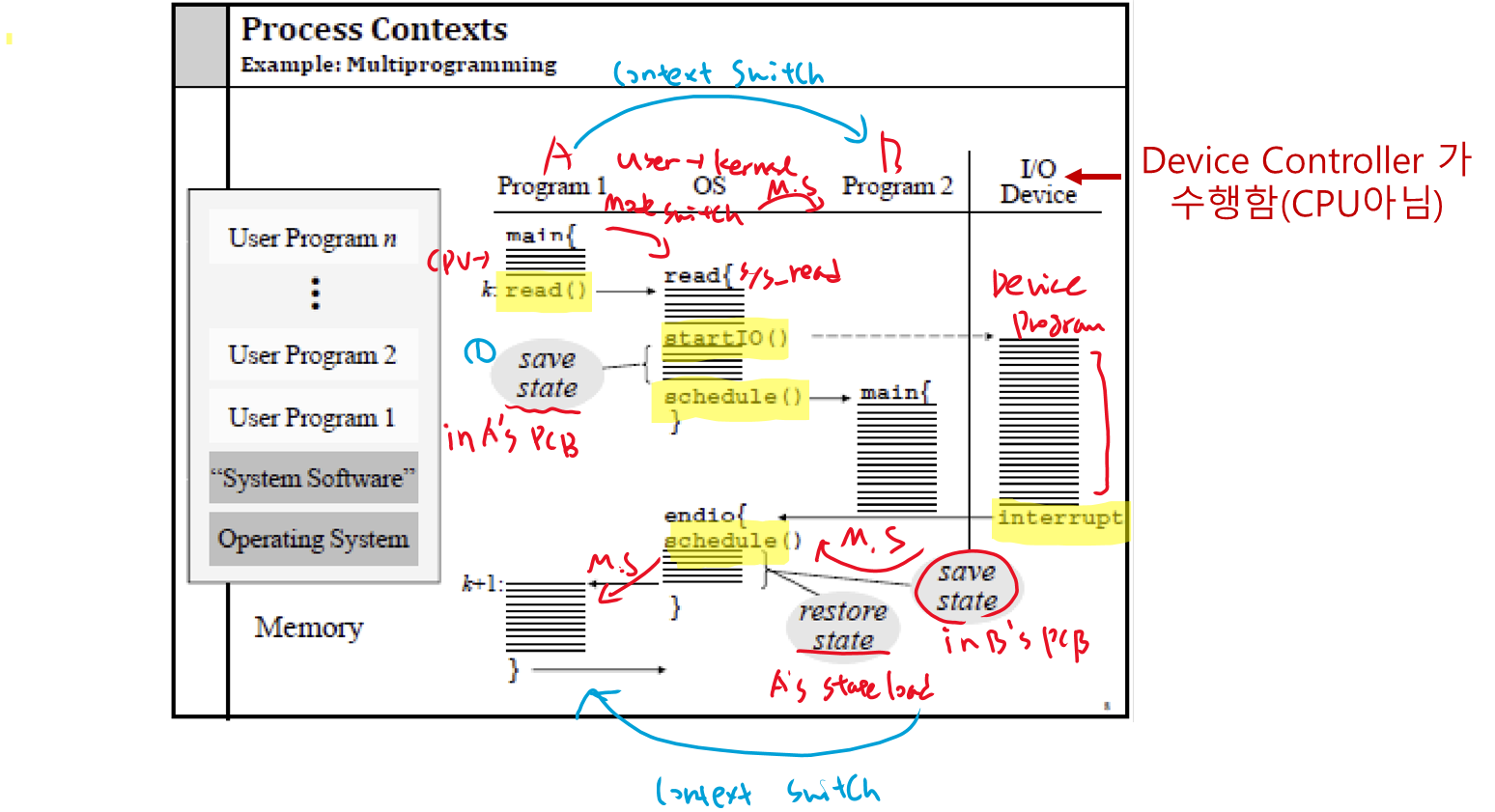
컨텍스트 전환(Context Switch) 이 발생하는 방법의 예
CPU사용을 한 프로세스에서 다른 프로세스로 전환하는 행위를 컨텍스트 스위치라고 한다.

-
하드웨어가프로그램 카운터등을스택에 쌓는다. -
하드웨어가인터럽트 벡터에서새로운 프로그램 카운터를 로드한다. -
어셈블리 언어 프로시저가
레지스터를 저장한다. -
어셈블리 언어 프로시저가
새로운 스택을 설정(스택 포인터 설정)한다. -
C 인터럽트 서비스가 실행된다 (일반적으로 입력을 읽고 버퍼링합니다).
-
스케줄러가 다음에 실행할 프로세스를 결정한다. -
프로시저가 이전에 중단된 코드로 돌아간다.
-
어셈블리 언어 프로시저가 새로운 현재 프로세스를 시작한다.
Context Switch 자세히
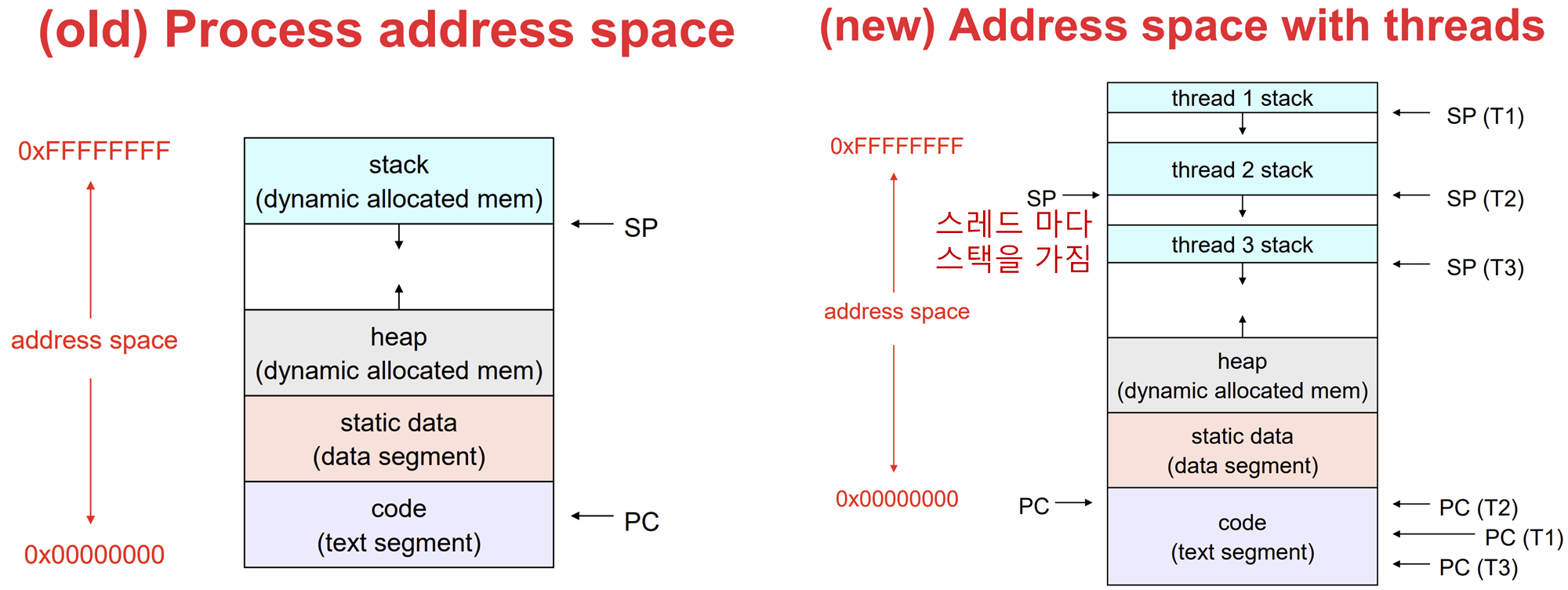
2 스레드 (Thread)
전통적인 OS 에서 각 프로세스는 주소공간 과 하나의 제어 흐름 을 가진다.
그러나 하나의 주소 공간 내에서 마치 별도의 프로세스인것 처럼 준 병렬적으로 수행하는 다수의 제어 흐름을 가지는 것이 좋은 상황이 종종 있다.(하나의 프로그램이 여러 동작을 수행?? 좋은데)
• 스레드의 사용
왜 스레드를 사용할까?
-
다수의 동작이 동시에 진행되어 프로그래밍 모델이 훨씬 단순해진다.
-
프로세스보다 스레드가 용량이 적어서 생성과 제거가 쉽고 동작이 빠르다
-
많은 연산과 I/O 가 동시에 존재하는 경우 스레드를 사용하면 이러한 동작들을 겹치도록 수행할 수 있어 응용의 속도를 향상시킬 수 있다.
결국 스레드는 어떤 작업을 수행하기 위해 밀접하게 연관된 다수의'실행의 흐름 (스레드)'이 자원의 집합을 공유하는 능력이다.
쉽게 말해 어떤 한 작업을 더 효율적으로 처리하기 위해 생긴 것
• 고전적인 스레드 모델
스레드는 다음을 가진다
-
다음에 실행할 명령을 추적하는
프로그램 카운터 -
현재 작업 변수를 저장하는
레지스터 -
호출하였으나 아직 복귀하지 않은 Procedure 마다 한 프레임씩 실행 히스토리를 담고 있는
스택

함수를 동시에 실행하면 서로의 스택을 침범할 수 있으므로 스레드당 스택을 주어야 한다.
• 스레드 패키지 구현 방법
스레드들을 생성/관리하는데 누가 책임을 가지냐에 따라 커널레벨 스레드와 유저레벨 스레드로 나뉜다.
둘의 차이는 간단히 말해 OS 가 스레드를 인식하냐 못하냐의 차이이다.
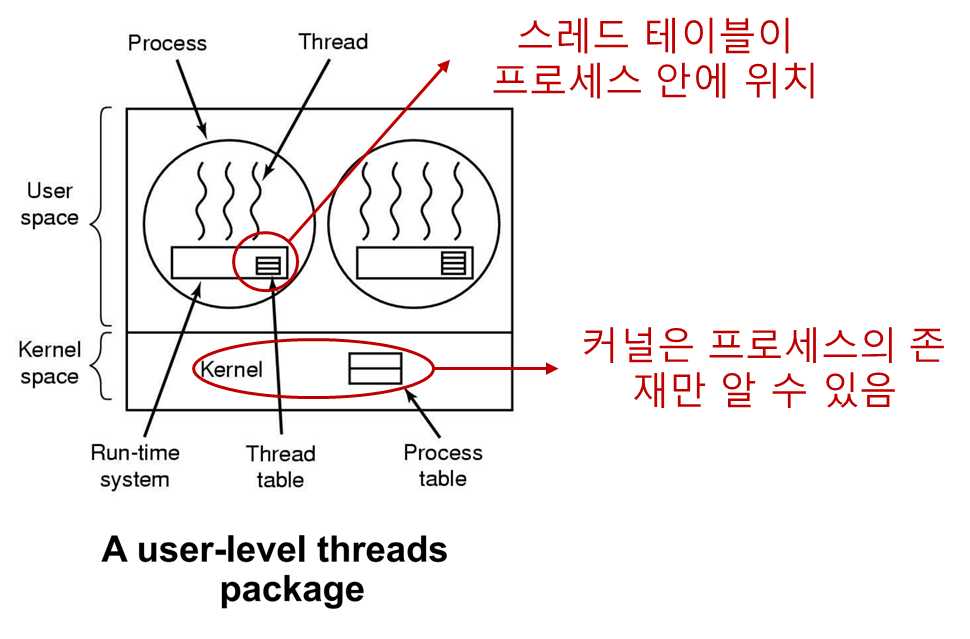
유저레벨 스레드
프로그램에 연결된 라이브러리가 스레드 생성/관리에 책임을 가진다.
스레드 패키지 전체를 유저공간 에 위치시키는 것이다.
커널은 이들에 대해 전혀 알지 못한다.
그저 하나의 프로세스가 돌아간다는 것만 알 수 있다.
장점
-
스레드 패키지 전체를 유저공간에 위치시킴으로서 스레드를 전혀 지원하지 않은 OS 에서도 구현될 수 있다.
-
각 프로세스마다 자신에게 특화된 스케줄링 알고리즘을 가질 수 있도록 한다.
-
유저레벨 스레드는 용량이 작고 빠르다
- 스레드 생성, 스레드 간 전환, 스레드 동기화는
프로시저 호출을 통해 이루어진다. 커널의 개입이 필요하지 않다 - 트랩/컨텍스트(프로세스) 스위치/캐시 flush 가 없다.
- 커널레벨 스레드보다
확장성이 뛰어나다.
- 가비지 컬렉터 스레드가 실행 도중에 멈추지 않는다.
단점
유저레벨 스레드는 이러한 중대한 단점때문에 잘 쓰이지 않는다.
핵심은 OS 가 스레드를 인지할 수 없기 때문에 일어난다.
블록킹 시스템 호출을 구현할 수 없다.
- OS 입장에서 프로세스가 블록킹 시스템 호출을 불려서 해당 프로세스를 블록시키게 되며 결과적으로 프로세스내 모든 스레드가 블록하게 된다.
- OS 는 프로세스 내의 스레드의 존재를 알지 못하므로 프로세스가 시스템 호출을 하면 일단 프로세스를 블록 상태로 바꾼다. 따라서 안에 존재하는 다른 스레드를 실행할 수 없다.
페이지 폴트
- 스레드가 페이지 폴트를 유발하면 비록 다른 스레드가 실행 가능할지라도 스레드의 존재를 알지 못하는 커널은 디스크 I/O 가 완료될 때 까지 프로세스 전체를 블록시킨다.
즉, 프로세스가 멈춰버린다.
페이지 폴트란?
보통 프로그램의 모든 데이터는 동시에 메모리에 존재하지 않고 일부만 메모리로 올라오고 나머지는 보조기억장치(디스크)에 저장되어 있다.
만약 프로그램이 메모리에 존재하지 않는 명령을 호출하거나, 그 명령으로 점프한다면 페이지 폴트가 발생하여 OS 는 해당 명령어와 그 이웃들을 디스크에서 가져올 것이다. 이것이 페이지 폴트이다.
- 만약 한 스레드가 무한루프를 돌고 있으면 이 스레드가 자발적으로 CPU를 양보할 때 까지 다른 스레드는 실행하지 못할 수도 있다.
- 하나의 프로세스 내에는
클록 인터럽트(일정한 주기로 인터럽트 거는 것)와 같은 것이 없기 때문에 스레드들을 순번대로 스케줄 하는 것이 불가능하다.
- 다중 프로세서(CPU)가 있어도 사용할 수 없다.
- 커널은 스레드에 대해 알지 못하기 때문에 실행중인 스레드에만 CPU를 할당할 수 있다.
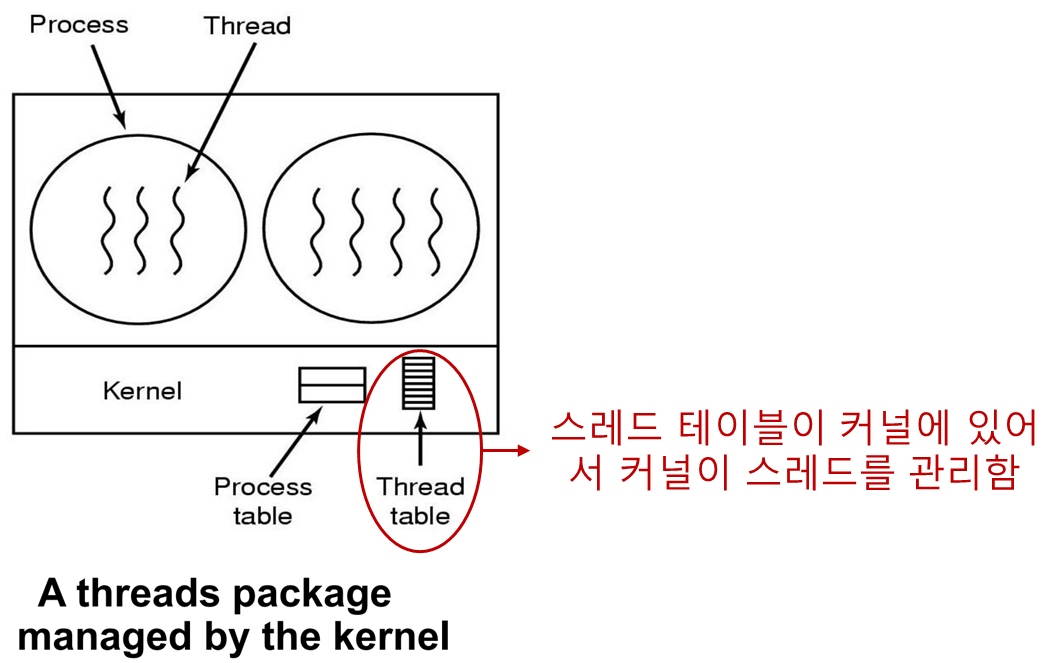
커널레벨 스레드
OS 가 스레드 생성/관리에 책임을 가진다.
스레드 생성과 관리에 시스템 호출 이 필요하다.
스레드를 블록시킬 수 있는 모든 호출은 시스템 호출 형태로 구현되어 런타임 시스템 프로시저를 호출하는 것 보다 훨씬 비용이 크다.
유저 레벨 스레드와 비교해서 보면
- 프로세스가 블록킹 시스템 호출을 불려서 해당 프로세스를 블록시키게 되어도 같은 프로세스의 다른 스레드를 수행하거나 다른 프로세스의 스레드를 수행할 수 있다.
- 왜? 커널(OS) 가 스레드 생성/관리를 하니까
페이지 폴트가 발생해도 커널이 스레드를 생성/관리 하므로 요청한 페이지의 디스크 I/O 를 기다리는 동안 실행할 수 있는 다른 스레드를 실행한다.
커널 레벨 스레드의 단점으로는
시스템 호출 비용이 크다. 따라서 스레드 연산(생성, 종료 등) 이 빈번하다면 많은 오버헤드가 발생한다.
왜 커널레벨에서 시스템 호출 비용이 클까?
'컨텍스트 스위칭' 때문
시스템 호출을 할 때, 프로그램은 사용자 모드에서 커널 모드로 전환된다.
이 과정에서 현재 실행 중인 작업의 상태를 저장하고, 커널 모드로 전환한 후 필요한 작업을 수행한 다음, 다시 사용자 모드로 돌아와야 한다.
그리고 시스템 호출 동안 다른 프로그램을 돌리고 호출 종료 시 원래 프로그램으로 돌아오는데도 상태를 저장해야한다.
이 전환 과정에서 많은 시간이 소요되며, 이는 시스템 자원을 많이 사용하게 된다.
3 프로세스 간 통신(Synchronization)
프로세스는 종종 다른 프로세스와 통신을 해야 한다.
프로세스 간 통신에 대해 3가지의 쟁점이 있다.
- 어떻게 프로세스가 다른 프로세스에게 정보를 전달하는가?
- 스레드끼리는 서로 주소 공간을 공유하므로 이를 이용하면 해결할 수 있다.
-
어떻게 둘 또는 그 이상의 프로세스가 서로 상대방을 방해하지 않도록 설정 하는가?
-
프로세스 간에 종속성이 존재할 때 어떻게 적절한 순서를 정하는가?
2,3 번이 좀 까다롭다
• 경쟁 조건 (Race Condition)
경쟁 조건 이란
둘 또는 그 이상의 프로세스가 공유 데이터를 읽거나 쓰는데 최종 결과는 누가 언제 수행되는가에 따라 달라지는 상황을 말한다.
몇몇 OS 에서 협력하는 프로세스들은 각 프로세스가 읽고 쓸 수 있는 저장 공간을 공유한다.
다음 예시를 보면서 경쟁조건에 대해 이해해보자
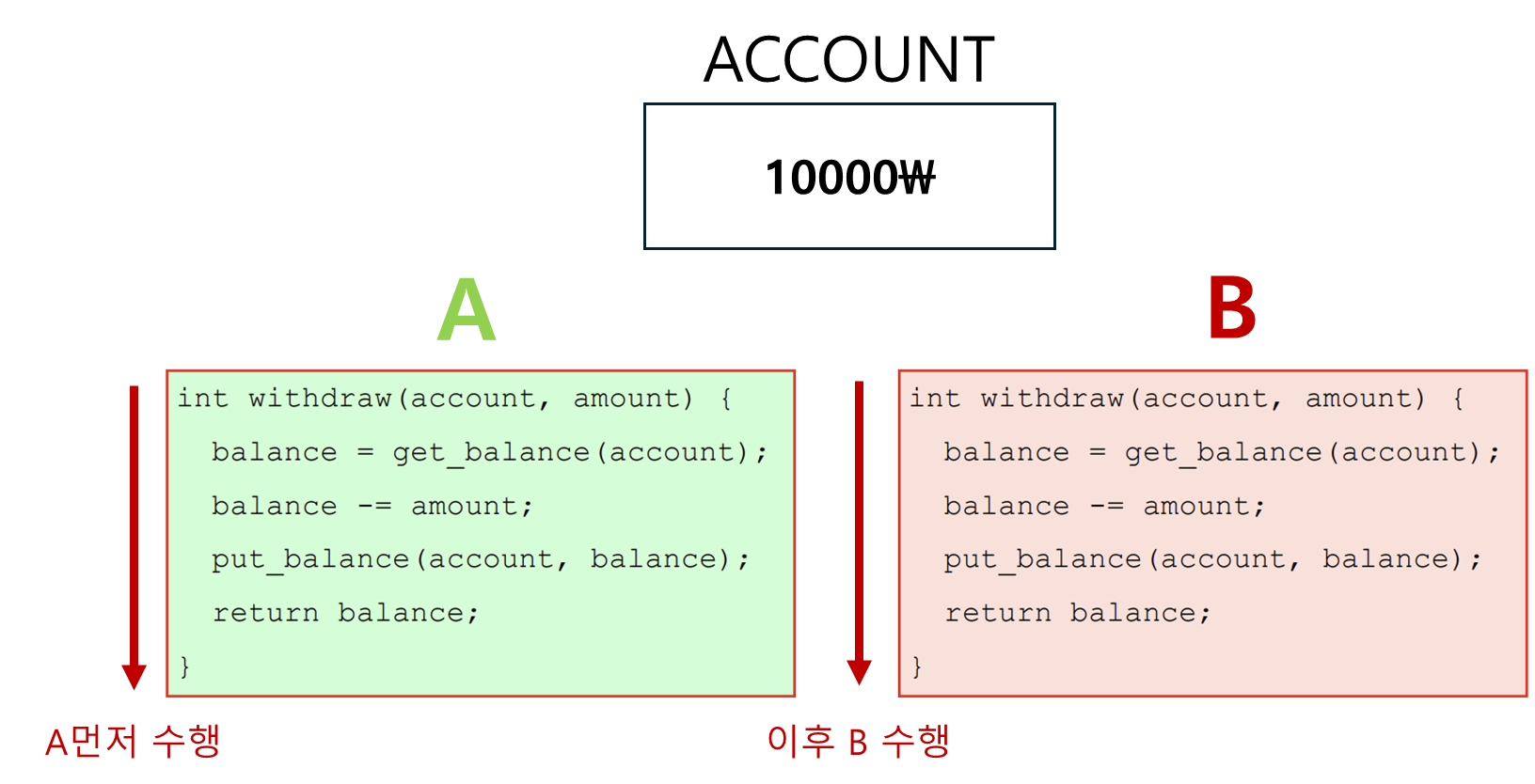
공용 계좌에 10000\이 있고 A 와 B 가 인출을 한다고 생각해보자
여기서
공용계좌 = 전역변수
A, B = 각각 스레드 혹은 프로세스
라고 생각하면 된다.
둘이 따로따로 인출과 인출 후 차액 입금을 한다면 아무런 문제가 발생하지 않는다.
그러나 B가 인출 도중에 A가 끼어들어 인출후 입금을 완료한다면
공용계좌의 총액이 이상해진다...

이처럼 두개 이상의 프로세스(스레드) 가 동시에 공유 데이터에 접근하는것을 막아야 한다...
• 임계 구역 (Critical Region)
위에서 문제가 발생한 이유는 B가 공유 변수(공동계좌) 를 사용하는 도중 A가 공유 변수를 사용했기 때문이다.
이를 해결하기 위해서 상호 배제(Mutual Exclusion) 즉, 한 프로세스가 공유 변수나 파일을 사용중이면 다름 프로세스들은 건들지 못하도록 하는 것이 필요하다.
공유 메모리를 접근하는 프로그램 부분을
임계 구역 (Critical Region)이라고 한다.
두 프로세스가 동시에 임계구역에 존재하지 않도록 조절한다면 경쟁조건을 피할 수 있다.

위에 예시에서 공동계좌에 접근하는 부분이 임계구역이다.

경쟁조건 해결을 위한 좋은 해결책은 다음 4가지 조건을 모두 만족하는 것이다.
-
두 개 프로세스가 동시에 자기의 임계구역 내에 존재하는 경우는 없어야 한다.
-
CPU 의 개수나 속도에 대해 어떤 가정도 하지 않는다.
-
임계구역 외부에서 실행하고 있는 프로세스는 다른 프로세스들을 블록시켜서는 안된다.
-
임계구역에 진입하기 위해 무한히 기다리는 프로세스는 없어야 한다.
• 바쁜 대기를 이용한 상호 배제
바쁜 대기
변수가 특정 값이 될 때까지 계속해서 검사하는 것
상호 배제를 구현하는 여러가지 방법들에 대해 알아보자
1. 인터럽트 끄기
가장 간단한 해결책으로서 각 프로세스가 임계구역에 진입하자마자 인터럽트를 끄고 임계구역에서 나가기 직전에 인터럽트를 키도록 하는 것이다.
근데 이건 좋은 방법이 아닌데 만약 프로세스 중 하나가 인터럽트를 끄고 다시 켜지 않는다면 시스템은 더이상 동작하지 않는다.
게다가 다중 CPU를 가진 시스템의 경우 인터럽트를 끄는 disabled 명령은 명령을 수행한 CPU 에만 영향을 끼친다.
나머지 CPU는 멀쩡히 돌아가면서 임계구역을 넘나들 것이다.
인터럽트 끄기는 OS 내부(커널) 에서는 유용하지만, 유저레벨에서는 적절하지 않다.
2. 락 변수
0으로 초기화된 락 변수가 있다고 가정하면
프로세스가 임계구역에 진입할 때 락을 테스트 하는데
-
락이 0 이면 프로세스가 락을 1로 설정하고 임계구역에 진입한다.
이후 임계구역에서 나올 때 락을 다시 0으로 설정하고 나온다. -
락이 1이면 다른 프로세스는 락이 0으로 바뀔 때 까지 기다려야 한다.
근데 앞에서 공동계좌 예시에서 발생한 문제와 같은 일이 일어날 수 있다.
락을 1로 바꾸기 까지 시간이 꽤 걸릴텐데(변수를 읽고 쓰는 작업이므로) 이때 다른 프로세스가 실행된다면 결국 임계구역에 2개의 프로세스가 들어갈 수 있다.

3. 엄격한 교대
스핀 락(Spin lock)
바쁜 대기를 사용하는 락을 스핀 락이라 한다.

B는 A가 작업을 끝낼 때 까지 계속 while 루프 뺑뺑이 (spinning lock) 에 걸려있다.
4. TSL 명령 (하드웨어의 도움을 받자)
TSL 명령의 동작
TSL REGISTER, LOCK
메모리 워드 LOCK 의 값을 읽어 레지스터 REGISTER 에 저장하고 메모리 주소 LOCK 에 0이 아닌 값을 기록한다.
중요한 점은 워드를 read 하고 write 하는 연산은 '분할이 불가능' 하여 이 연산이 완료될 때 까지 어떤 CPU도 메모리 워드에 접근할 수 없다.
하드웨어의 도움을 받아 TSL 명령을 수행하는 CPU 는 명령이 끝날 때 까지 메모리 버스를 잠가 어떤 다른 CPU도 메모리에 접근할 수 없도록 한다.
이는 메모리 버스를 잠근 CPU를 제외하고 다른 CPU가 버스를 사용하지 못하도록 버스 잠금을 선언하는 버스 라인(특별한 하드웨어) 를 필요로 한다.
메모리 버스를 잠그는 것은 인터럽트를 끄는 것과는 매우 다르다
인터럽트를 끄고 메모리 워드를 read write 하는 동안에 다른 CPU가 버스를 통해 해당 메모리 워드에 접근하는 것을 막을 수 없다.

• Sleep & Wakeup (No Busy Waiting)
앞서 우리는 바쁜 대기를 활용한 상호 배제(Mutual Exclusion) 에 대해 알아보았다.
근데 바쁜 대기는 CPU 시간을 낭비할 뿐만 아니라 예기치 못한 결과(우선순위 역전 문제: 프로세스가 우선순위대로 실행되지 않는 문제) 를 가져올 수 있다.
Sleep 과 Wakeup 을 활용해서 바쁜 대기를 쓰지 않는 방법에 대해 알아보자
-
Sleep : 호출자를 블록 상태로 만드는 시스템 호출. 다른 프로세스가 호출자를 깨워줄 때 까지 블록 상태에 머물게 된다.
-
Wakeup: Sleep 중인 프로세스 하나를 깨움. 블록 해제
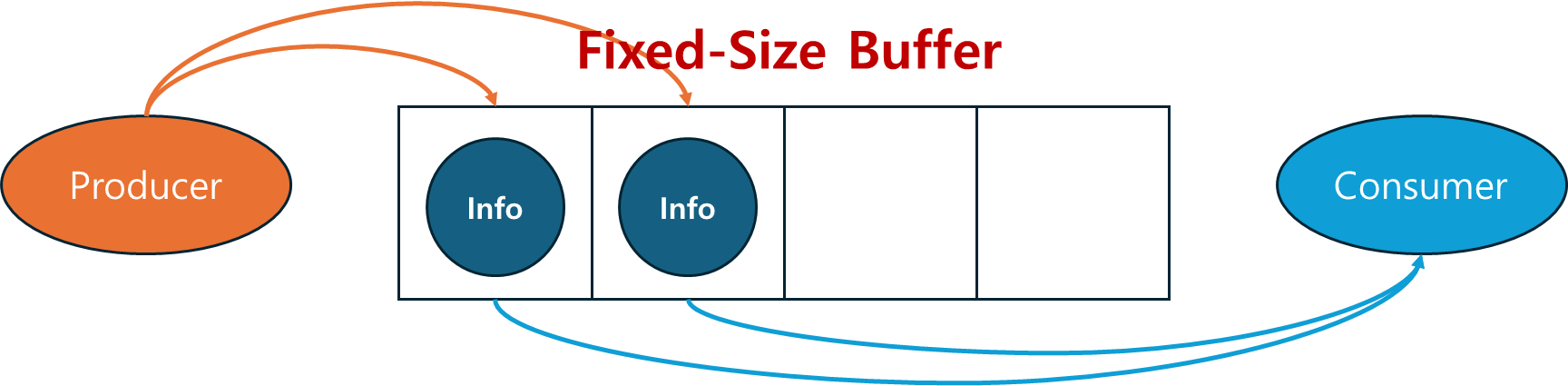
생산자 - 소비자 문제
bounded-buffer 문제라고도 불린다.
두개의 프로세스가 고정된 크기의 공통된 버퍼를 공유한다.
생산자는 정보를 생산해서 버퍼에 넣고
소비자는 버퍼에서 정보를 가져간다.
생산자 - 소비자 문제의 로직은 다음과 같다.
생산자가 새로운 아이템을 버퍼에 넣으려고 하는데 버퍼가 가득 차 있다면?
생산자는 잠들고 소비자가 아이템을 버퍼에서 하나 꺼낼 때 잠든 생산자를 깨워주는 것이다.
반대로 소비자가 버퍼에서 아이템을 꺼내려고 하는데 버퍼가 비어있다면?
소비자는 잠들고 생산자가 아이템을 버퍼에 넣을 때 잠든 소비자를 깨워주는 것이다.
생산자 - 소비자 문제점: 경쟁조건의 발생
다음 코드를 보면서 생산자-소비자 문제의 문제점을 알아보자
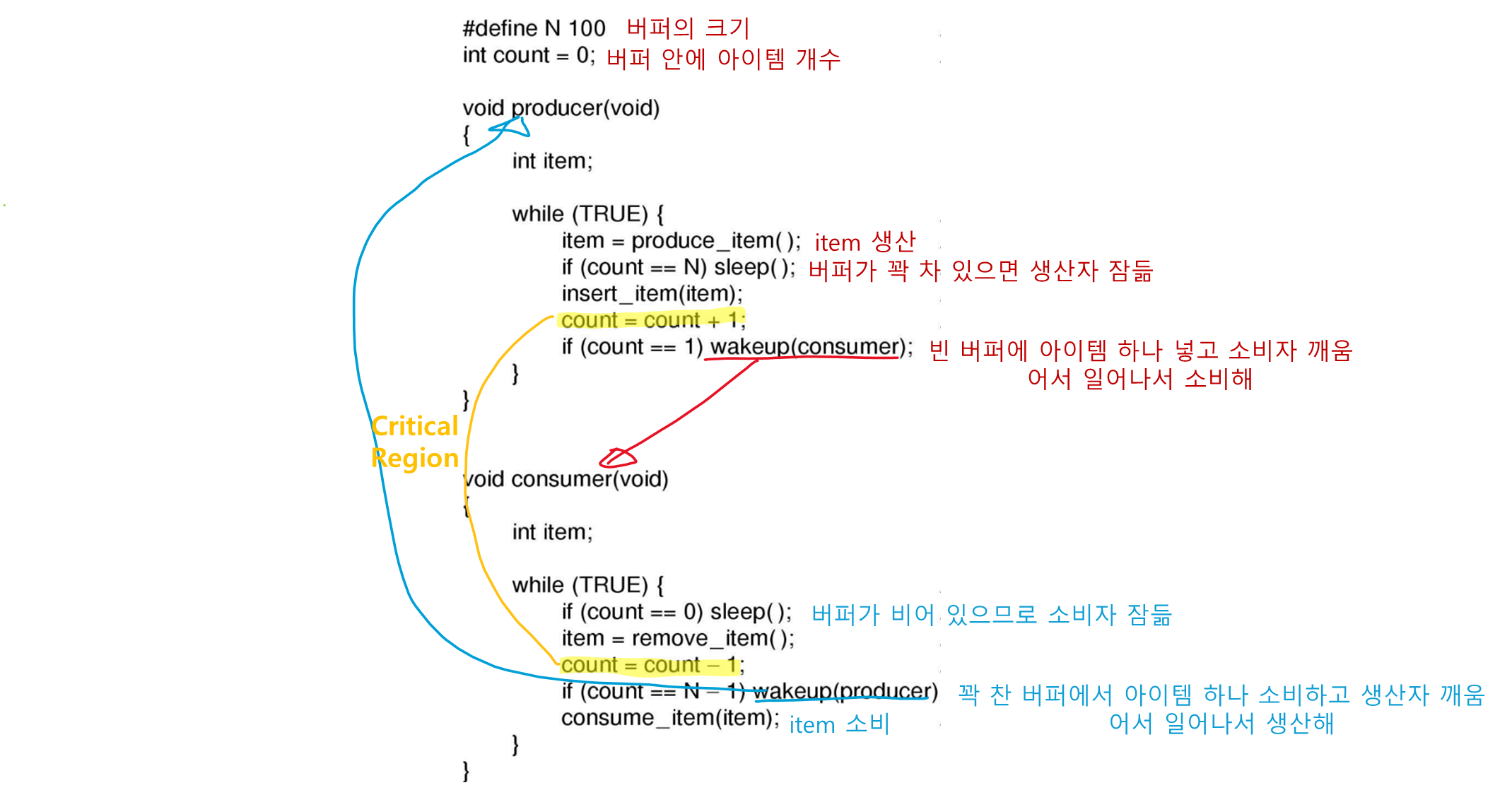
count 라는 공유변수(Shared Resource) 에 대한 접근에 제한이 없기 때문에 경쟁조건이 발생할 수 있다.
-
count = 0으로 버퍼가 비어있을 때, 소비자가 이 버퍼 값을 읽어서 0임을 알았다. -
이 순간에 스케줄러는 소비자 프로세스 의 수행을 중지시키고 생산자를 수행하기 시작한다.
- 소비자는 count = 0 인 사실만 알고 아직 sleep() 함수를 호출하지 않음
-
생산자는 아이템을 버퍼에 추가하고 카운트를 증가시키고 이전에 카운트 = 0 이었으므로 소비자를 wakeup 시킨다.

-
근데 이 때 소비자는 아직 논리적으로 잠든 상태가 아니다(아까 위에 sleep() 함수를 아직 호출하지 않았다고 했다). 따라서 wakeup 시그널은 사라진다.
-
생산자는 열심히 버퍼를 채우다 버퍼가 꽉 차면 잠들 것이다.
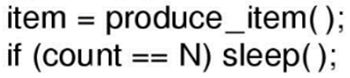
-
소비자도 이제 sleep() 함수를 호출해서 잠들었는데, 아까 생산자가 보낸 wakeup 시그널은 진작에 사라진 상태라 두 프로세스가 모두 영원히 잠들게 된다.

세마포어
다익스트라가 정수 변수를 사용하여 미래를 위해 미리 호출한 wakeup 횟수를 저장할 것을 제안하였고 세마포어 라는 새로운 변수형을 도입하였다.
sleep 과 wakeup이 일반화 된 down 과 up 두 연산을 제시하였다.
임계구역에 들어갈 때
세마포어가 0이면 임계구역 진입이 블록되고 0보다 크면 임계구역에 진입함과 동시에 세마포어의 값을 1 감소시킨다.
임계구역에서 나갈 때
세마포어를 1 증가시켜 다른 프로세스가 임계구역에 들어올 수 있도록 한다.
세마포어 연산이 시작되면 이 연산이 완료되거나 프로세스가 잠들 때 까지 다른 프로세스가 세마포어 변수에 접근할 수 없다.
동기화와 경쟁 조건을 방지하기 위해서 이다.
세마포어: down 연산
P() 함수라고도 불린다.
세마포어에 대한 down 연산은 값이 0보다 큰 지 검사한다.
만약
- 0보다 크다면 세마포어를 1 감소시키고
- 0이라면 프로세스는 down 의 수행을 완료하지 않고 즉시 잠들게 된다.
- 나중에 잠든 프로세스가 깨어나면 down 수행을 완료한다.
세마포어: up 연산
V() 함수라고도 불린다.
세마포어를 1 증가시키며 대기중인 스레드를 깨운다.
대기중인 스레드 중에서 하나 만을 깨운다
세마포어를 활용한 생산자-소비자 문제의 해결
세개의 세마포어 변수를 사용한다.
Full : 아이템으로 채워진 버퍼의 개수를 나타냄
Empty : 빈 버퍼의 개수를 나타냄
Mutex : 동시에 임계구역에 접근하지 못하도록 함.
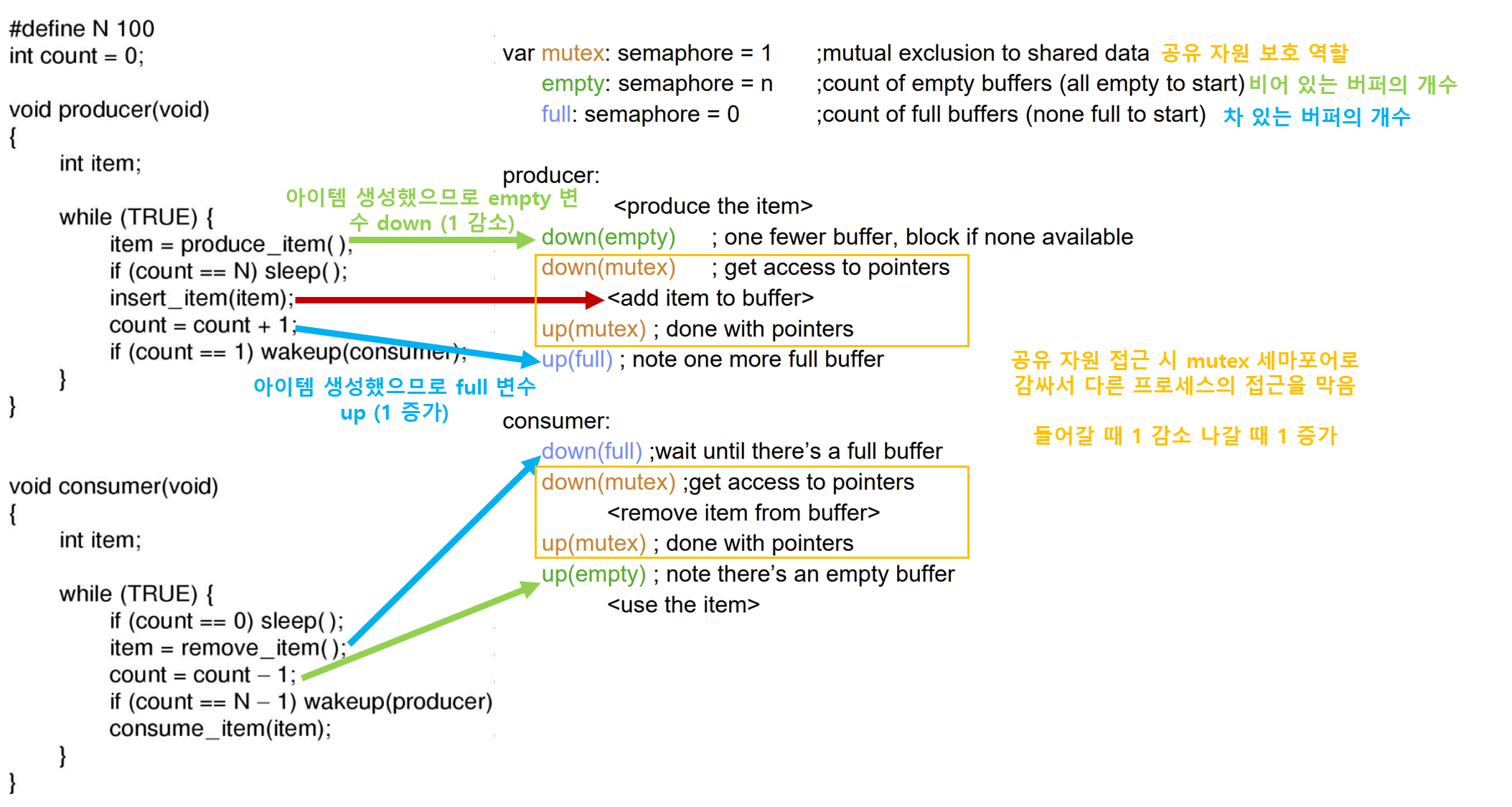
Mutex 세마포어는 상호 배제를 위해 사용되었다.
이는 한번에 단 하나의 프로세스만 공유자원을 읽고 쓰도록 보장하는 용도로 사용된다.
Full 과 Empty 세마포어는 동기화를 위해 사용되었다.
특정 이벤트 순서들이 발생하거나 발생하지 않도록 보장하기 위해 필요하다.
중요한 점은 임계구역 진입할 때 Mutex 가 먼저 실행되면 임계구역 접근이 막히므로 생산자, 소비자 모두 접근을 못하는 DeadLock 현상이 일어날 수 있다.
• 모니터
모니터 란?
특별한 형태의 모듈 또는 패키지에 모아진 프로시져(함수), 변수, 그리고 자료구조의 모음이다.
프로세스는 필요하면 언제든 모니터의 프로시져들을 호출할 수 있지만 모니터 밖의 프로시저에서 모니터의 내부 자료구조를 직접 접근하는 것은 불가능하다.
모니터는 프로그래밍 언어 자체가 지원해주는 개념인데 C는 이를 지원하지 않는다.
모니터는 상호 배재를 달성하는 데 중요한 속성을 가지고 있는데 그건 바로 단 하나의 프로세스만 한 순간에 모니터에서 활동할 수 있다. 이다.
즉 한 프로세스가 모니터에서 떠날 때 까지 다른 프로세스는 접근이 블록 된다.
모니터의 조건 변수와 wait & signal 연산
임계구역을 모두 모니터의 프로시저 형태로 만들면 동시에 두개의 프로세스가 임계구역에서 실행할 수 없다
근데 앞서 생산자-소비자 문제에서 버퍼가 가득 차면 생산자는 어떻게 블록되어야 할까?

이 문제는 조건 변수와 이들에 대한 두개의 연산 wait 와 signal을 도입하여 해결할 수 있다.
wait 연산
모니터 프로시져가 더이상 진행할 수 없음을 인식하면 (위에서 버퍼가 가득 찼다는 것을 생산자가 알게 된 경우) 어떤 조건변수 (위에 그림에서 full에 대해) wait 을 수행한다.
이 동작은 wait 을 호출한 프로세스를 대기하게(블록) 만들고, 현재 모니터 진입을 블록당하고 있는 다른 프로세스가 모니터에 진입할 수 있도록 하게 한다.
-
모니터 잠금을 해제하여 다른 프로세스가 들어갈 수 있도록 한다.
-
다른 프로세스가 '조건에 대한 신호'
signal(c)를 보낼 때까지 기다린다. -
따라서 조건 변수에는 대기 큐가 있다.
signal 연산
대기중(블록) 인 조건 변수에 대해 signal을 수행하여 대기중인 프로세스 하나를 깨울 수 있다.
-
조건 변수는 카운터가 아니다. 나중에 사용하기 위해 signal을 누적시킬 수 없다.
-
signal을 불러야 한다면 그 전에wait가 수행되었어야 한다.
모니터 예시

wait 과 signal 이 경쟁 조건 을 발생시키는 sleep, wakeup 와 유사하지만 경쟁조건 을 일으키지 않는다
왜냐하면 공유 자원이 모니터 안에 있어서 모니터 안에 프로세스가 들어와서 수행중인 경우 다른 프로세스는 접근을 할 수 없기 때문이다.
모니터 종류 3가지
생산자 - 소비자와 같은 프로세스는 파트너 프로세스가 대기중인 조건 변수에 대해 signal(c) 를 수행하여 대기중인 파트너를 깨울 수 있다.
이때, 두개의 프로세스가 모니터에서 동시에 활동하는 것을 막기 위해 signal 이후에 어떻게 될 것인지에 대한 규칙이 필요하다.
Hoare 모니터
signal(c) 이후에 기존에 수행중인 프로세스는 중단시키고 새로 깨어난 프로세스가 즉시 실행되어야 함.
Hansen 모니터
signal(c) 이후에 signal을 수행한 프로세스는 즉시 모니터를 나가야 한다.
다른 말로 signal 문장은 모니터 프로시저의 맨 마지막 문장에서만 실행되어야 한다. 그래야 바로 나갈 수 있기 때문
Mesa 모니터
여러 프로세스가 wait 중인 어떤 조건 변수 c 에 대해 signal(c) 가 수행되면 대기중인 프로세스 중 스케줄러에 의해 선택된 프로세스 하나가 깨어나 수행된다.
4 스케줄링 (Scheduling)
컴퓨터가 다중 프로그래밍 형태로 동작할 때 종종 다수의 프로세스 또는 스레드가 동시에 CPU를 사용하기 위해 경쟁한다.
이때 누구에게 CPU를 할당할 것인가 를 정하는 OS의 일부분을 스케줄러 라고 하고 스케줄러의 알고리즘을 스케줄링 알고리즘 이라 부른다
스케줄러 자세히
스케줄러는 작업을 대기열에서 대기열로 이동하는 모듈로스케줄링 알고리즘은 다음에 실행할 작업과 대기할 대기열을 결정하고스케줄러는 일반적으로 언제 실행되는지 결정한다.
스케줄러는starvation(특정 프로세스만 CPU 할당을 못받아 처리를 받지 못하는(굶고 있는) 상황)을 방지하려고 노력해야 한다.
스케줄러는 보통 다음의 상황에 실행된다.
- 작업이 실행에서 대기(블록) 상태로 전환되는 경우 (그다음에 어떤 프로세스를 실행할까?)
인터럽트발생 시 (특히 타이머 인터럽트 발생 시)- 작업 생성 또는 종료 시
여기서는 다양한 스케줄링 알고리즘에 대해 알아볼 것이다.
이 알고리즘들은 프로세스와 스레드 모두에 적용되는 알고리즘들이다.
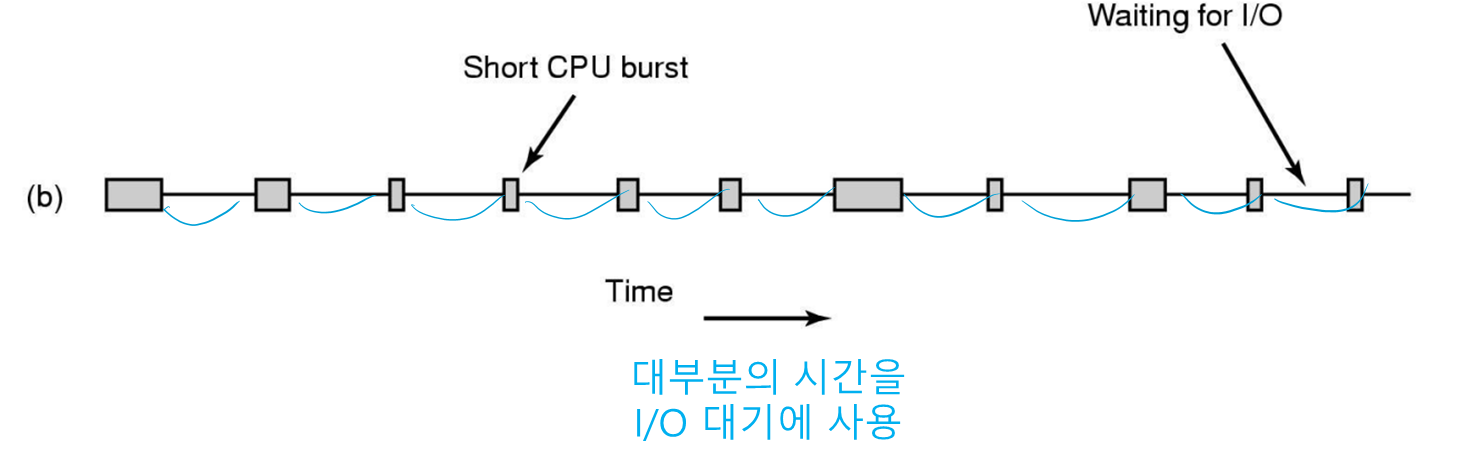
• 프로세스의 행동
여기서 burst 는 일정 시간 동안 CPU 계산이나 I/O 를 수행하는 행위를 뜻한다.
CPU-bound
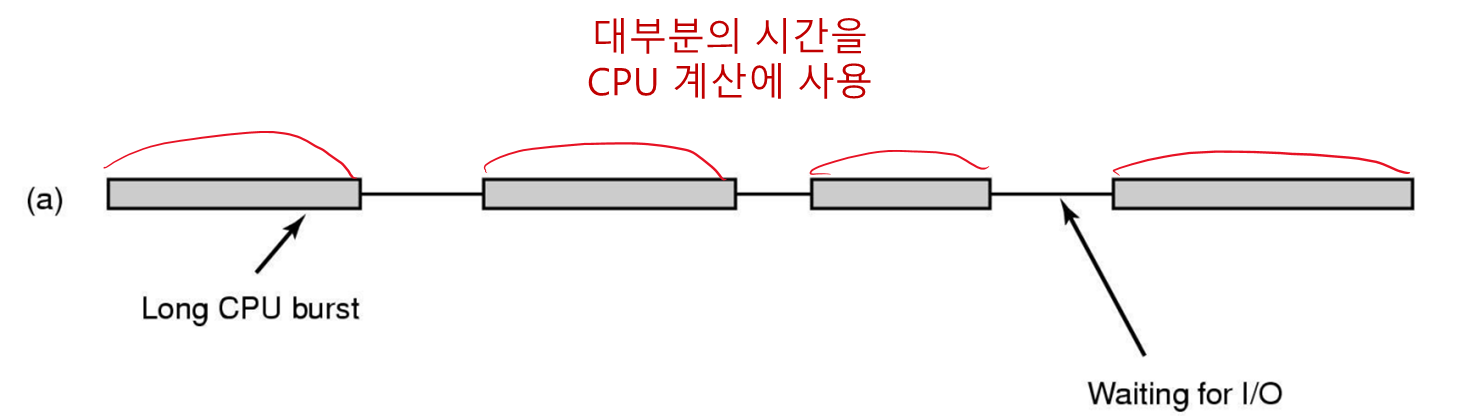
I/O-bound
• 언제 스케줄링을 해야 하는가?
새로운 프로세스를 만들 때자식 프로세스를 먼저 실행할 지 부모 프로세스를 먼저 실행할지
- 자식/부모 프로세스는 모두 준비 상태이므로 스케줄러는 다음에 실행할 프로세스를 선택할 수 있다.
프로세스를 종료할 때 스케줄링이 필요
- 프로세스가 종료되면 CPU점유가 해제되므로 스케줄러는 다음 ready queue 에 있는 프로세스 중 누굴 실행할 지 선택할 수 있다.
-
프로세스가 I/O, 세마포어, 기타 이유 때문에
블록된 경우 -
I/O
인터럽트가 발생할 경우
- I/O 인터럽트가 발생했다는 것은 I/O 를 기다리며 블록된 어느 프로세스가 실행할 준비가 됬다는 것을 의미한다.
스케줄러는 다음에 I/O 대기중인 프로세스를 실행할 지 , 아니면 다른 대기 상태의 프로세스를 실행할 지 선택할 수 있다.
클록 인터럽트가 발생한 경우
• 스케줄링 알고리즘의 분류: 선점형 비 선점형
클록 인터럽트를 어떻게 다루는가에 따라비-선점형,선점형으로 나뉜다.
비 선점형(nonpreemptive) 알고리즘
어떤 프로세스가 수행 프로세스로 선정되면
이 프로세스가 I/O 나 다른 프로세스를 기다리기 위해 대기하거나 또는 자발적으로 CPU를 해제할 때까지 실행하도록 허용한다.
이 프로세스가 긴 시간동안 계속 수행중이어도 강제로 중단시킬 수 없다.
클록 인터럽트 에서 스케줄링 결정이 이루어지질 않는다.
선점형(preemptive) 알고리즘
프로세스를 선택하고 최대 값으로 정해진 시간을 넘지 않는 범위에서 실행되도록 한다.
만약 정해진 시간 간격의 끝에 도달하면 이 프로세스는 중단되고 스케줄러는 다음에 실행할 다음 프로세스를 선정한다.
선점형 스케줄링을 하기 위해서는 주기의 마지막에 클록 인터럽트 가 발생하여 스케줄러가 다시 CPU의 제어를 회복할 수 있어야 한다.
즉, 클록 인터럽트를 사용할 수 없다면 비 선점형 스케줄링만 사용할 수 있다.
시스템에 따른 스케줄링 알고리즘
모든 시스템
목표 :
- 공평함 : 각 프로세스에게 공평한 몫의 CPU 할당
- 정책 집행 : 정해둔 정책(규칙)이 집행되는지 관찰
- 균형 : 시스템의 모든 부분이 활동하도록 함 (놀고있는 부분 없도록)
batch 시스템
배치 시스템은 대량의 데이터를 특정 시간에 일괄처리하는 시스템이다.
배치 시스템은 세가지 성능 측정 기준을 사용한다.
-
처리율(Throughput): 시간 당 처리된 작업의 개수. 높을수록 좋다
-
반환 시간(Turn-around Time): 배치 작업이 제출된 순간부터 끝날 때 까지 걸린 통계적인 평균 시간.(평균적으로 사용자가 얼마나 오래 출력을 기다려야 하는지)
짧을수록 좋다! -
CPU 이용률: 시간 당 CPU가 얼마나 사용되는지
목표:
- 성능(처리율: 시간당 처리된 작업의 개수) : 시간 당 처리되는 작업 수 최대화
- 반환 시간(배치 작업이 제출된 순간부터 끝날 때 까지 걸린 통계적인 평균 시간) : 작업의 제출로부터 종료까지 걸리는 시간을 최소화
- CPU 이용률 : CPU가 항상 활용되도록 함
따라서 간단하고 빠른 응답을 요청하는게 아니므로 비 선점형 알고리즘 이나, 각 프로세스에게 긴 주기를 제공하는 선점형 알고리즘 이 적합하다.
이러한 알고리즘들은 프로세스 의 전환을 줄이고 성능을 향상시킨다.
대화식(interactive) 시스템
목표 :
- 응답 시간 : 요청에 빠르게 응답하도록 함
- 비례(Proportionality: 사용자의 선입견) : 사용자의 기대를 만족시킴
한 프로세스가 CPU를 독점하여 다른 사용자의 서비스를 방해하는 것을 막기 위해서 선점형 알고리즘 이 필수이다.
실시간 제약 시스템
목표:
- 마감시간 지키기: 데이터 손실을 방지
- 예측 가능 : 멀티미디어 시스템에서 품질 저하를 방지
프로세스가 장기간 실행되지 않을 수 있다는 것을 알고 있고 일반적으로 작업을 수행하고 빠르게 차단하기 때문에 선점이 필요하지 않은 경우도 있다.
• 배치시스템에서의 스케줄링
1. First-come first-served (FCFS) or FIFO
작업은 도착하는 순서대로 스케줄링 함(줄서기 생각)
일반적으로 비 선점적(nonpreemtive)임.
프로세스가 중간에 블록되고 교체되는 일이 없으므로 context switch가 발생하지 않기 때문
각각의 job들은 공평하게 처리되고 starvation 이 없다.
문제점

처리 시간이 오래 걸리는 job이 먼저 처리되면 일찍 끝나는 job들이 처리가 끝날 때 까지 기다려야 함
처리 순서에 따라 반환 시간이 크게 달라질 수 있다.
2. Shortest job first (SJF) 최단 작업 우선
아까 FIFO 에서 처리 순서에 따라 반환 시간이 크게 달라진다고 했는데
여기 최단 작업 우선 알고리즘에서 그 아이디어를 그대로 반영해서 처리 순서가 제일 짧은 job을 먼저 실행하도록 했다.
역시 이 알고리즘도 비 선점적 이다.
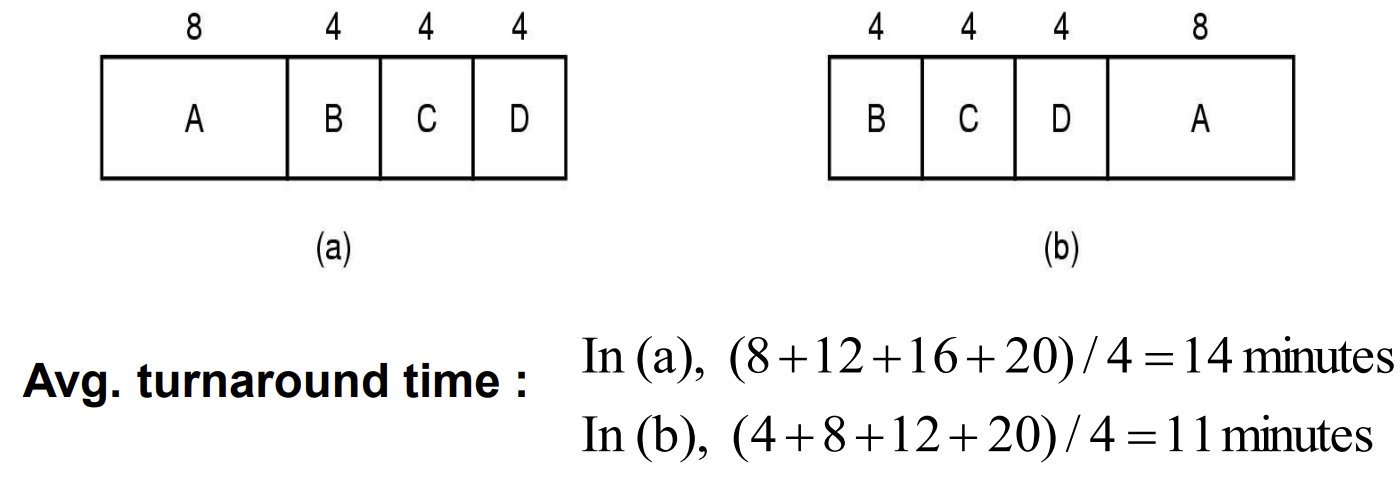
문제점
-
해당 프로세스가 CPU를 얼마나 사용할지 알 수 없다.
-
모든 job들이 동시에 도착(존재) 할 때만 알고리즘이 의미가 있다.
A,B,C,D,E 실행 시간이 2, 4, 1, 1, 1 이라고 알고 있을 때
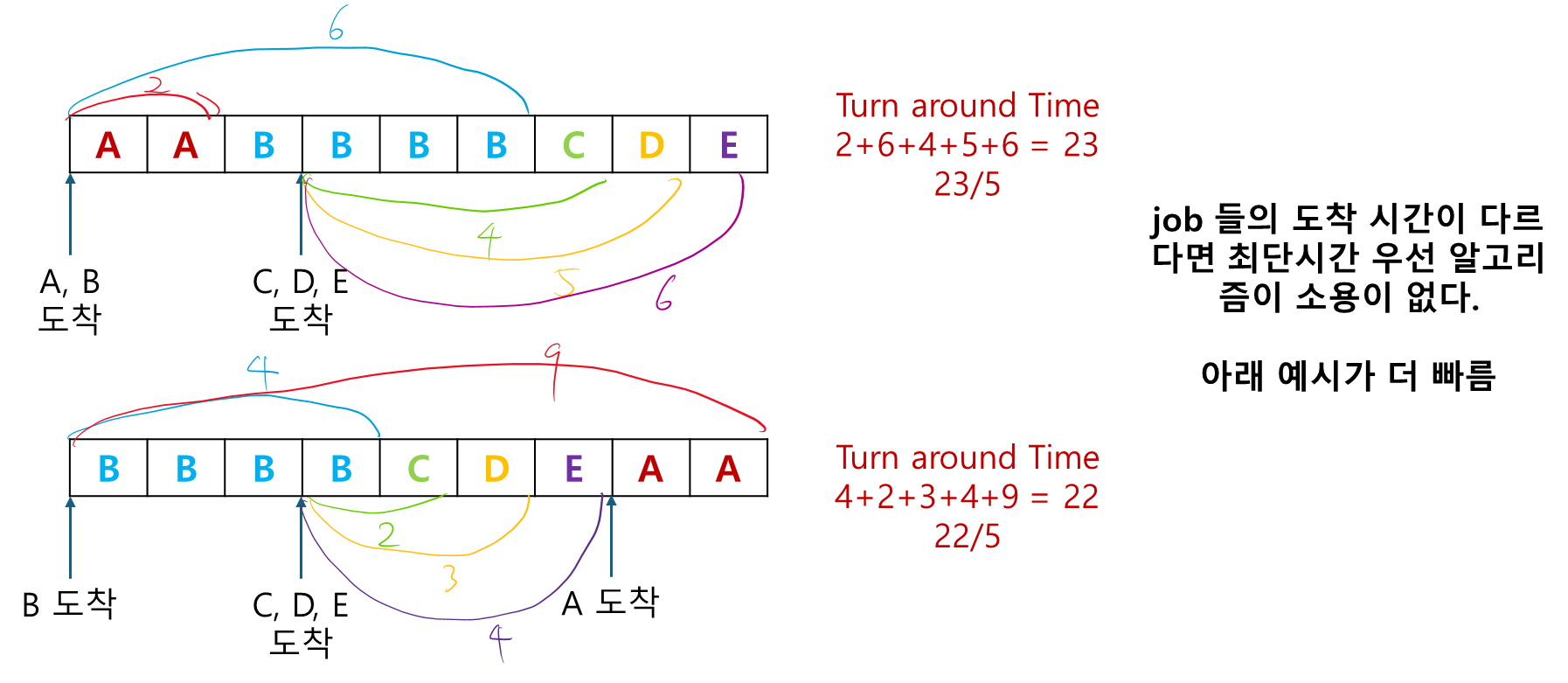
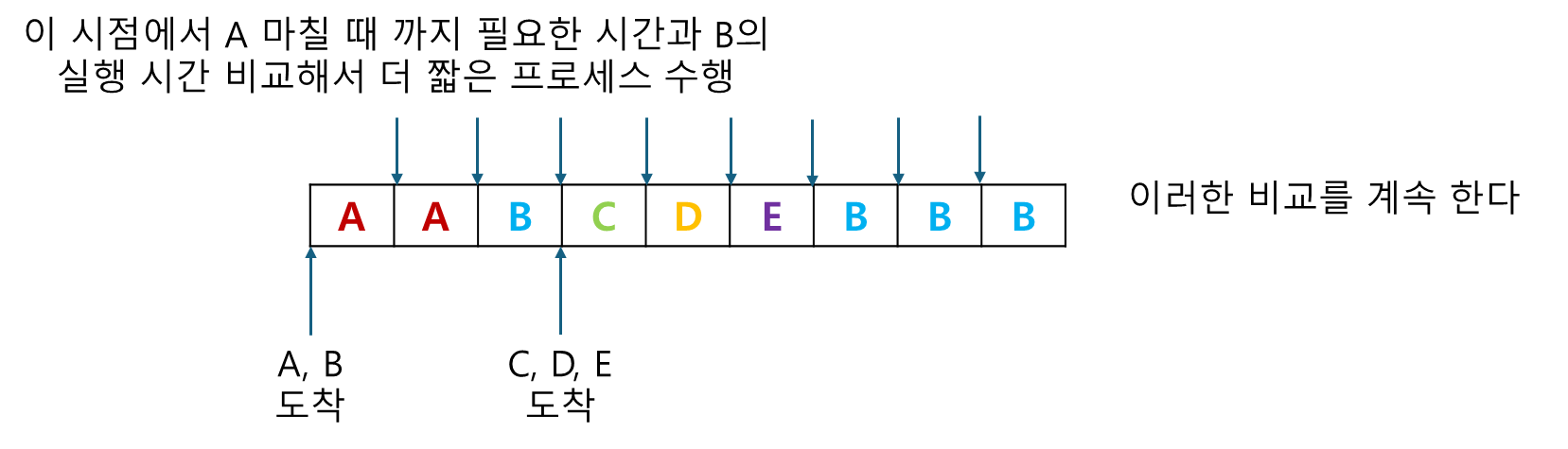
3. Shortest Remaining Time Next(SRTN)
2번의 SJF(최단작업우선) 의 선점적 인 방식이다. (즉, CPU 사용 시간 제한있음)
SJF 처럼 작업의 실행 시간을 미리 알고 있어야 한다.
(A, B, C, D, E 각각 2, 4, 1, 1, 1 의 실행시간을 가진다)
이 알고리즘에서 스케줄러는 항상 프로세스의 남은 실행 시간이 가장 짧은 작업을 선택한다
동작:
-
새로운 작업이 도착하면 이것의 실행 시간을현재 수행중인 프로세스의 '잔여 시간'과 비교한다. -
도착한 프로세스의 '실행 시간'<현재 실행중인 프로세스가 '작업을 마칠 때 까지 필요한 시간'이면
현재 프로세스는 중단되고 새로운 작업이 실행된다.
(빠른거 부터 처리하겠다)
• 대화식(interactive) 시스템의 스케줄링
1. Round Robin scheduling (RR)
각 프로세스는 시간 할당량(Time Quantum) 이라 불리는 시간 주기 가 할당되며 한 번에 이 quantum 만큼 만 실행 된다.
프로세스가 quantum이 끝나기 전에 대기하거나 종료하면 CPU는 다른 프로세스로 할당된다
이렇게 quantum 에 따라 CPU를 할당해 주므로 starvation 이 없다.

문제점
quantum 의 길이에 따라 문제가 발생한다
-
만약 quantum이 너무 길면?
프로세스의 처리 순환이 늦어질 것이고 사용자는 응답을 오래 기다려야 한다. -
만약 quantum이 너무 짧으면?
너무 많은context switch가 발생해서 CPU의 효율이 감소한다.
일반적으로 quantum은 20 ~ 50 ms 가 적당하다고 한다.
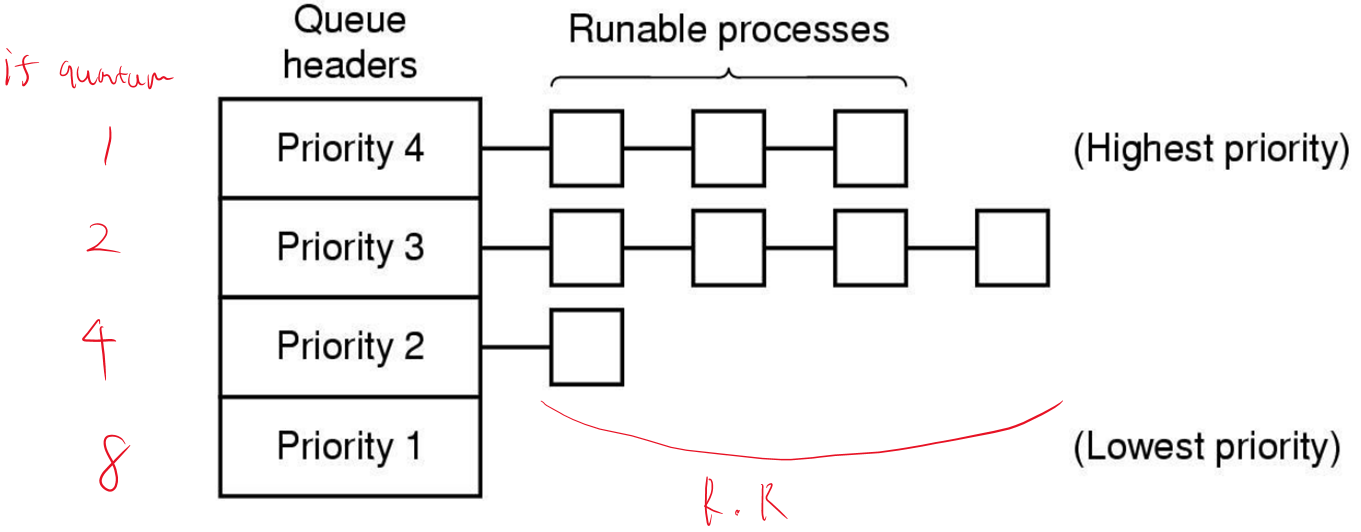
2. Priority Scheduling
라운드 로빈 스케줄링은 암묵적으로 모든 프로세스가 똑같이 중요하다는 가정을 하고 있다.
이번엔 프로세스에 우선순위를 부여해서 스케줄링 하는 알고리즘을 알아보자
우선순위는 프로세스에게 정적 또는 동적으로 할당될 수 있다.
정적:
사용하는 사람에 따라(지위), 가격을 더 지불했는가?
동적:
일부 프로세스가 심한 I/O bound 형태로 수행될 때, CPU가 이런 프로세스에 즉시 할당되어서 다음 I/O 요청을 빠르게 발생시키도록 해야 한다.
이때, 1/f 우선순위 (f : 프로세스가 사용하고 남은 quantum) 를 설정해서 I/O bound 프로세스에게 좋은 서비스를 제공할 수 있다.
문제점
가끔 우선순위가 잘 조정되지 않으면 높은 우선순위를 가진 프로세스만 실행되어 낮은 우선순위를 가진 프로세스에게 starvation 이 발생할 수 있다.
'age' 를 도입해서 starvation 을 방지할 수 있다.
age 란 ready queue 에서 오래 기다린 시간을 의미한다.
- ready queue 에서 오래 기다릴수록 우선순위 증가(오래 기다렸지? CPU 쓰게 해줄게)
- CPU 오래 사용할수록 우선순위 감소(너 CPU 독점 금지)
3. 다단계 큐
앞에 우선순위 스케줄링에서 큐에도 우선순위를 정했다.
가장 높은 우선순위 클래스는 1 quantum을 할당받고 내려갈수록 2, 4, 8... 이렇게 quantum을 할당받는다. (우선순위가 낮을 수록 퀀텀을 더 준다)
프로세스가 할당된 시간(퀀텀)을 모두 소비하면 한 단계 낮은 우선순위로 이동한다.
- 퀀텀을 다 썼네? CPU-bound(CPU 많이 쓰는) 프로세스군 : 우선순위 아래로
- 퀀텀을 다 못썼네? I/O-bound(CPU 많이 안쓰는) 프로세스군 : 우선순위 위로
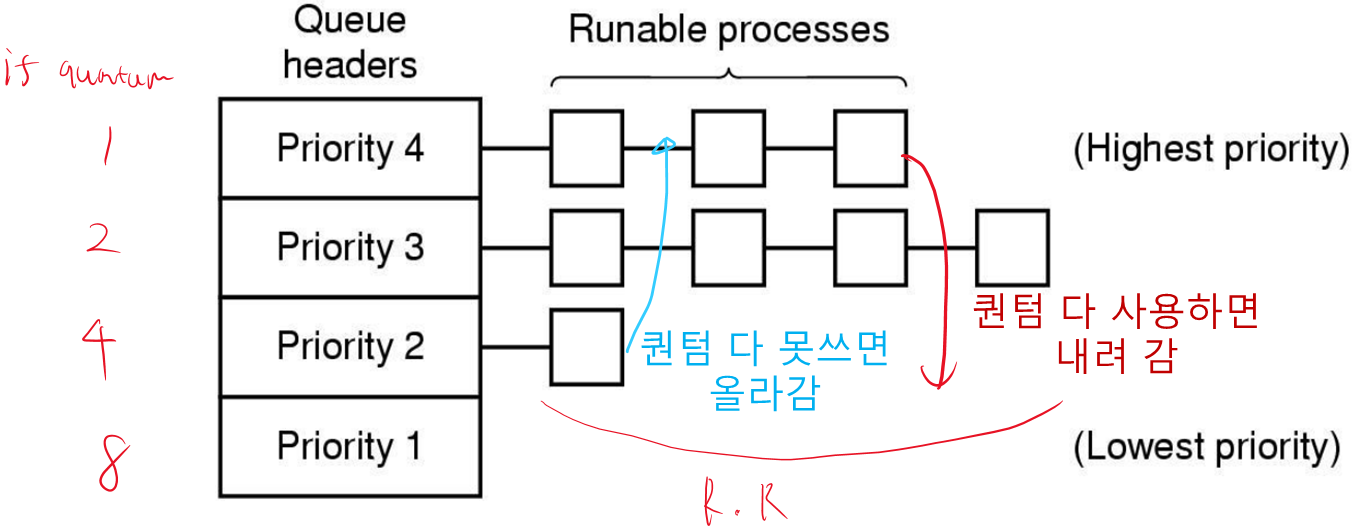
프로세스를 우선순위 클래스로 그룹화
클래스 간 우선순위 스케줄링
각 클래스 내 라운드 로빈 스케줄링
문제점
다단계 큐도 우선순위 문제로 starvation 이 발생할 수 있다.
4. 보장 스케줄링
'n 명의 사용자들에게 1/n 만큼의 CPU 성능을 제공한다.'
시스템은 각 프로세스가 생성된 이후 얼마나 많은 CPU 시간을 받았는지 추적할 필요가 있다.
이후 CPU가 실제 사용한 시간을 n으로 나눔으로써 각 프로세스에게 부여되었어야 할 CPU 시간을 계산한다.
비율 = 실제 CPU 사용 시간 / 주어진 CPU 사용 시간
알고리즘은 이 비율이 가장 적은 프로세스를 가장 가까운 경쟁 프로세스의 비율을 초과할 때 까지 수행시킨다. (1/n 만큼의 CPU 성능 보장)
5. 복권 스케줄링
보장 스케줄링 처럼 성능을 보장하는 또다른 알고리즘이다.
스케줄러는 프로세스들에게 CPU 시간과 같은 시스템 자원들을 위한 티켓 을 주는 것이다.
스케줄링 결정을 내릴 때 마다 무작위로 티켓을 선택하고 이 티켓을 가진 프로세스가 자원을 할당 받는다.
특징 :
-
티켓이 뽑히면 바로 CPU 사용 가능하다 (즉각적인 반응도)
-
더 중요한 프로세스는 티켓을 더 많이 받아 당첨 확률을 높일 수 있다.
-
협동하는 프로세스들은 티켓을 교환할 수 있다.
-
비례(사용자가 기대하는) 스케줄링 가능
- 다수의 프로세스들이 각각 10, 20, 25 프레임을 초당 제공할 때, 이 프로세스들에게 10, 20, 25개의 티켓을 제공하면 이들은 자동으로 이 비율로 CPU를 나눠가질 것이다.
• Real-Time 시스템 스케줄링
스케줄링에 있어서 시간을 지키는 것이 제일 중요하다.
따라서 스케줄링이 가능한가? 를 판단하는 것이 중요하다.
m개의 이벤트(job)이 존재할 때
각 이벤트 i 는 Pi 의 주기로 발생하고 이벤트 처리에 Ci초의 CPU 시간이 필요하면 다음과 같을 때 스케줄링이 가능하다.
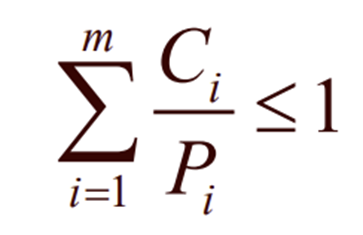
예를 들어
100, 200, 500 msec 의 Period 를 갖는 3개의 주기적인 이벤트를 가진 Real-Time 실시간 시스템이 있을 때
각각의 이벤트들이 50, 30 100ms 의 CPU 시간을 필요로 한다면
50/100 + 30/200 + 100/500 < 1 이므로 이 시스템은 '스케줄링이 가능' 하다
실시간 시스템은 정적일수도 동적일수도 있는데
정적인경우 시스템이 동작하기 전에 미리 스케줄링 결정을 다 짜놓아야 한다. 즉, 중간에 스케줄링 변경을 할 수 없다.
동적인 경우 중간에 스케줄링 변경이 가능하다.
