서론
장기 기억 정보 저장소를 위한 세가지 필수 요구 사항은 다음과 같다.
- 많은 양의 데이터를 저장해야 한다.
- 저장된 정보는 이를 사용하는 프로세스가 종료된 후에도 유지되어야 한다.
- 여러 프로세스가 동시에 정보에 액세스할 수 있어야 한다.
우리는 파일 이라는 새로운 추상화를 통해 위의 요구사항들을 해결할 수 있다.
파일과 파일 시스템에 대해
파일이란?
프로세스에 의해 생성된 정보의 논리적인 단위이다.
디스크는 일반적으로 수백만개의 파일을 가지고 있으며 각각의 파일은 서로 독립적이다.
프로세스는 기존의 파일을 읽을 수 있을 뿐만 아니라 필요시 새로운 파일을 생성할 수도 있다.
- 파일에 저장된 정보는
영속적이어야 하며 다른 프로세스의 생성 혹은 종료에 영향을 받지 않는다. - 파일은 오직
소유자가 명시적으로 삭제할 때만 사라진다.
파일은 OS 에 의해 관리되며 OS 에서 파일을 다루는 부분을 파일 시스템 이라고 한다.
파일
사용자의 관점에서 파일에 대해 알아보겠다.
파일 명칭 부여
파일은 추상화된 매커니즘이다.
'파일은 정보를디스크에 저장하고 다시 읽을 수 있는 길을 제공한다.'
UNIX 시스템 은 대소문자를 구분하지만 MS-DOS 는 대소문자를 구분하지 않는다.
많은 OS들은 파일 이름을 <파일 이름>.<파일 확장자> 의 두 부분으로 구분한다.
마침표 다음에 나오는 부분은 파일 확장자 로 보통 파일의 종류를 가리킨다.
파일 확장자들
다음은 일반적인 파일 확장자들 이다.

UNIX 같은 시스템에서는 파일 확장자의 사용은 전통이며 OS는 이를 강제하지 않는다.
파일 확장자는 단지 소유자에게 종류를 상기시킬 뿐이며 컴퓨터에게 어떤 실질적인 정보를 제공하지는 않는다.- 이 경우
파일 확장자의 사용은컴파일러에게 필수적이며파일 확장자를 통하여 파일들을 구분할 수 있다.
Windows는 파일 확장자를 인식하며 확장자에게 의미를 부여한다.
사용자(프로세스)는 OS 에게 확장자를 등록하고 있는 어느 프로그램이 해당 확장자를소유하고 있는지를 지정할 수 있다.사용자가 어떤 파일 이름에 대해 더블클릭하면 특정 확장자와연결된 프로그램이 해당 파일을 인자로 받아 실행된다.
파일 구조
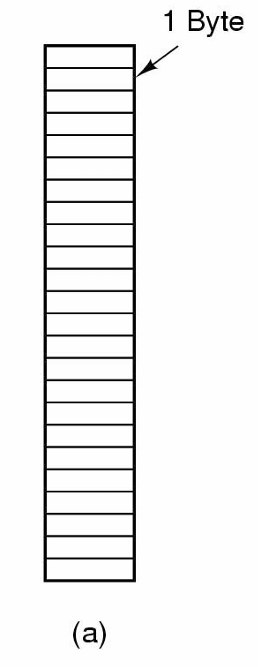
바이트 시퀀스
파일은 특별한 구조를 가지지 않는 바이트들의 연속이다.
UNIX 및 Windows가 이런 기법을 채택한다.
레코드 시퀀스
파일은 고정된 크기의 레코드들의 연속이다.
각 레코드들은 특별한 형태의 내부 구조를 가진다.
-
읽기 연산은 하나의 레코드를 읽는다.
-
쓰기 연산은 하나의 레코드를 변경하거나 추가한다.

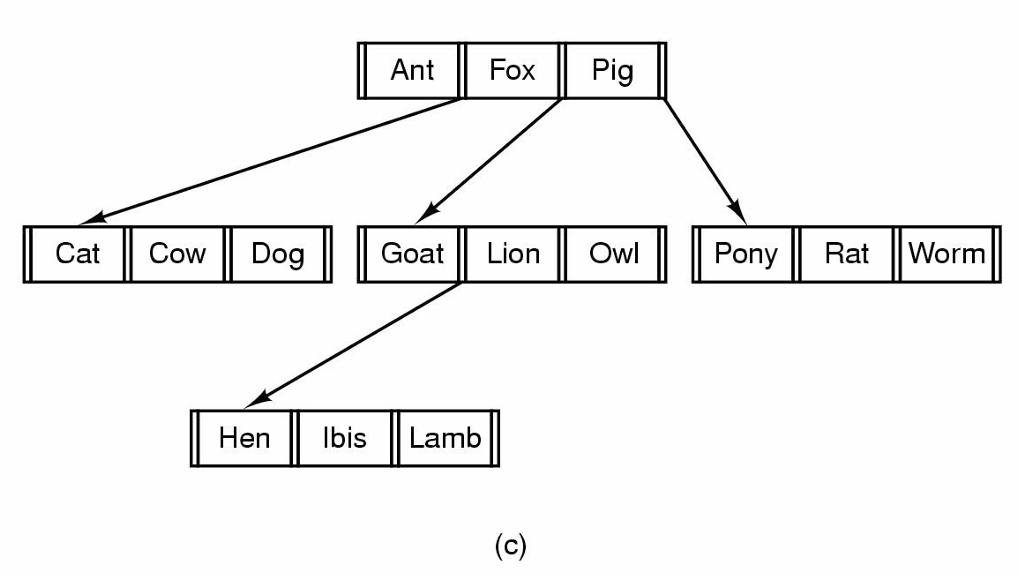
트리 구조
파일은 트리구조로 구성된 레코드들을 가지며 레코드 내부의 고정된 위치에 키 필드를 가진다.
트리는 키 필드를 기준으로 정렬되어 특정 키에 대한 빠른 검색을 가능하게 한다.
파일 유형
많은 OS 는 여러 유형의 파일을 제공한다.
다음과 같은 파일 유형들이 있다.
-
정규 파일 (Regular File)
-
사용자 정보를 가지고 있는 파일이다.
-
일반적으로 ASCII 파일 또는 바이너리 파일이다.
-
-
디렉터리 (폴더)
- 파일 시스템의 구조를 유지하기 위해 사용되는 시스템 파일이다.
-
문자 특수 파일
I/O 장치와 연관되어 있으며 터미널, 프린터, 또는 네트워크와 같은 문자I/O 장치를 모델링하기 위해 사용된다.
-
블록 특수 파일
- 디스크를 모델링하기 위해 사용된다.
정규 파일 자세히
일반적으로 ASCII 파일 또는 바이너리 파일이다.
ASCII 파일
텍스트 행으로 구성된다.
가장 큰 장점은 별다른 처리 없이 표시되거나 프린트 될 수 있으며, 텍스트 편집기로 편집될수도 있다.
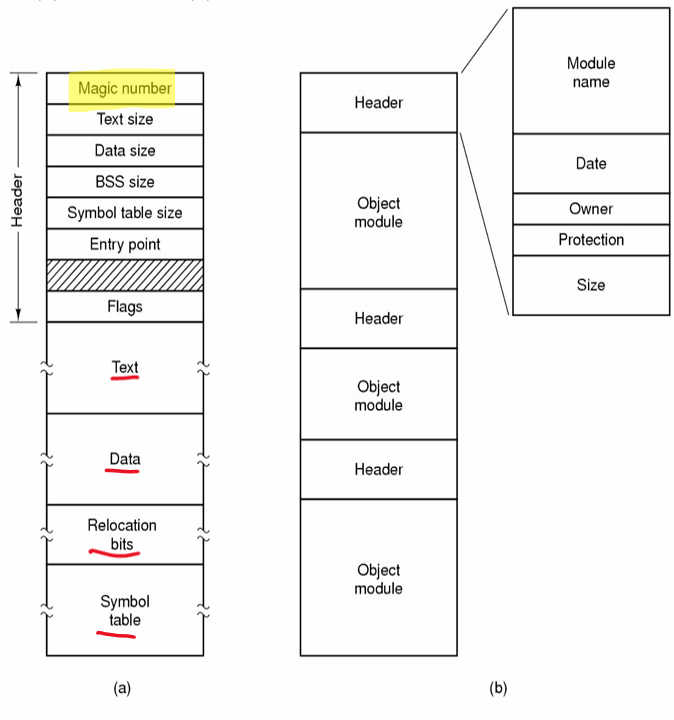
바이너리 파일
ASCII 파일이 아니다.
헤더, 텍스트, 데이터, 재배치 비트, 심볼 테이블과 같은 5개의 조각으로 구성된다.
-
헤더는
매직 넘버로 시작하며 이는 파일이실행 파일임을 표시하기 위해 사용된다. -
헤더 다음에 프로그램의 텍스트와 데이터가 존재한다. 이들은 메모리로 적재되며 재배치 비트에 따라 재배치된다.
-
심볼 테이블을 디버깅용도로 사용된다.
파일 접근
순차 접근
- 프로세스는 파일의 모든 바이트 or 레코드를 앞부분부터 순차적으로 읽을 수 있음
- 일부분을 건너 뛰거나 순서 바꿔서 읽지는 못함
- 대신에 왼전히 되감아서 파일을 다시 원하는 만큼 순차적으로 읽을 수는 있음
임의 접근 (Random Access)
- 디스크의 등장으로 파일의 바이트 or 레코드를 순서를 바꿔 읽거나 인덱스가 아니라 키 값에 따라 레코드에 접근하는 것이 가능해짐
(임의 순서로 읽는 것이 가능)
- 어디서부터 읽을 지를 지정하기 위해 두가지 기법 사용 가능
- 모든
read 연산마다 파일 내에서 읽을 위치를 지시 seek라는 특별한 연산이 현지 위치를 지정seek실행 후에 이러한 현재 위치부터 파일을 순차적으로 read함- UNIX, WINDOW 에서 사용되는 방법임
파일 속성

파일 연산들

파일시스템 호출을 사용하는 프로그램 예시

디렉토리
파일을 관리하고 추적하기 위해 많은 파일 시스템 들은 디렉토리 (폴더) 들을 가지고 있다.
디렉토리 도 파일 의 일종이다.
단일 레벨 디렉토리 시스템
가장 단순한 디렉토리 시스템으로서 하나의 디렉토리에 모든 파일을 담는 것이다.
이러한 디렉토리를 루트 디렉토리 라고 부른다.
초기 개인용 컴퓨터의 경우 하나의 사용자만 존재했기 때문에 이러한 시스템이 일반적이었다.

계층적 디렉토리 시스템
위의 단일 레벨을 보면 파일의 개수가 많아질수록 하나의 디렉토리에 그 많은 파일들이 모두 들어간다
이렇게 되면 나중에 디렉토리에서 원하는 파일을 찾기 어려울 것이다.
따라서 서로 연관된 파일들을 하나로 묶을 수 있는 계층적 시스템이 필요하다.
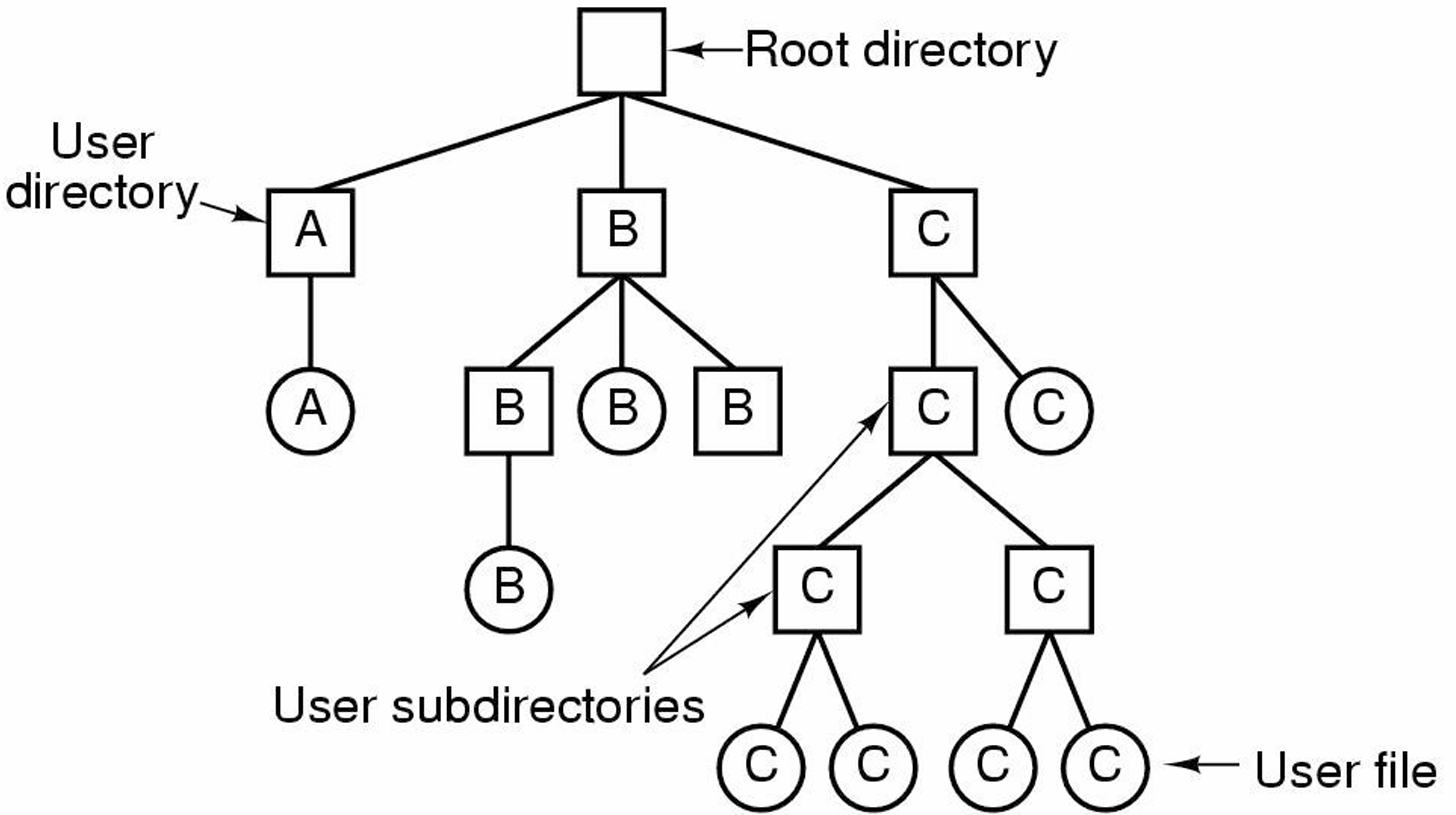
현대의 대부분의 파일 시스템들은 이러한 방식으로 조직화 되어 있다.
파일 경로 이름
두가지 방법이 있다
절대 경로 이름
\users\username\desktop\myfile
이렇게 각 파일마다 루트 디렉토리부터 파일까지의 경로들로 구성된 이름을 절대 경로 이름 이라 한다.
경로 이름의 첫번째 글자가 분리 기호 (예를들어 \) 로 시작하면 그 경로는 절대 경로이다.
상대 경로 이름
작업 디렉토리 (현재 디렉토리) 개념과 함께 사용된다.
작업 디렉토리는 말 그대로 내가 지금 작업을 하고 있는 공간이다.
다음과 같은 특별한 엔트리를 가지고 있다.
.
- 현재 디렉토리를 가리킨다.
..
- 부모 디렉토리를 가리킨다.
예시
다음과 같은 폴더 구조가 있다고 해보자
my_project/
├── documents/
│ ├── reports/
│ │ └── annual_report.txt
│ └── notes.txt
└── images/
├── logo.png
└── background.jpg만약 현재 작업 디렉토리가 my_project 라고 하면, notes.txt 파일에 접근하기 위해 다음과 같은 경로를 사용할 수 있다.
./documents/notes.txt
documents 가 현재 디렉토리의 하위 디렉토리 이므로 현재 디렉토리 . 에서 차례대로 절대 경로로 따라가면 된다.
만약 현재 작업 디렉토리가 my_project/documents/reports 라고 가정하면, notes.txt 파일에 접근하기 위해 다음과 같이 사용할 수 있다
../notes.txt
notes.txt 가 documents 의 하위에 있으므로 일단 현재 report 에서 .. 으로 상위 레벨 디렉토리인 documents 로 이동해야 한다.
이후 절대 경로로 따라가면 된다.
파일 시스템 구현
구현의 입장에서 파일 시스템을 살펴보겠다.
-
파일과 디렉토리를 어떻게 저장할 것인가?
-
디스크 공간을 어떻게 관리할 것인가?
-
모든 작업이 효율적이고 신뢰성 있게 실행되도록 어떻게 할 것인가?
파일 시스템 개요
디스크는 하나 이상의 파티션으로 구성될 수 있으며 각 파티션마다 독립적인 파일 시스템이 존재한다.
디스크의 섹터 0번은 MBR(Master Boot Record) 라 불리며 컴퓨터를 부팅하는 용도로 쓰인다.
부팅 순서
-
BIOS 가 MBR 을 읽어 이를 실행한다.
-
MBR 프로그램은 활성 파티션의 위치를 파악하고
부트 블록(활성 파티션의 첫 번째 블록)을 실행한다. -
부트 블록에 있는 프로그램은 해당 파티션에 존재하는
OS 의 부트 프로그램을 메모리에 적재한다.

파일의 구현
파일 저장 공간을 구현할 때 가장 중요한 문제는 '어느 블록이 어느 파일에 속하는지를 추적하고 관리하는 것' 이다.
몇가지 기법들을 알아보겠다.
연속 할당
가장 간단한 기법으로 각 파일을 연속된 디스크 블록에 할당하는 것이다.
각 파일은 새로운 블록으로부터 저장되기 때문에 마지막 블록의 뒷부분은 낭비된다.
즉, 단편화 (Fragmentation) 이 있다.
장점
-
구현하기 매우 쉽다. 파일의 시작 블록과 블록의 개수만 기억하면 된다.
-
읽기 성능이 매우 뛰어나다.
시작 블록만 알면 나머지들은 줄줄이 딸려오기 때문에 단 한번의 디스크 탐색 동작으로 전체 파일을 디스크에서 읽을 수 있다.
단점
- 디스크 단편화 (Disk Fragmentation)
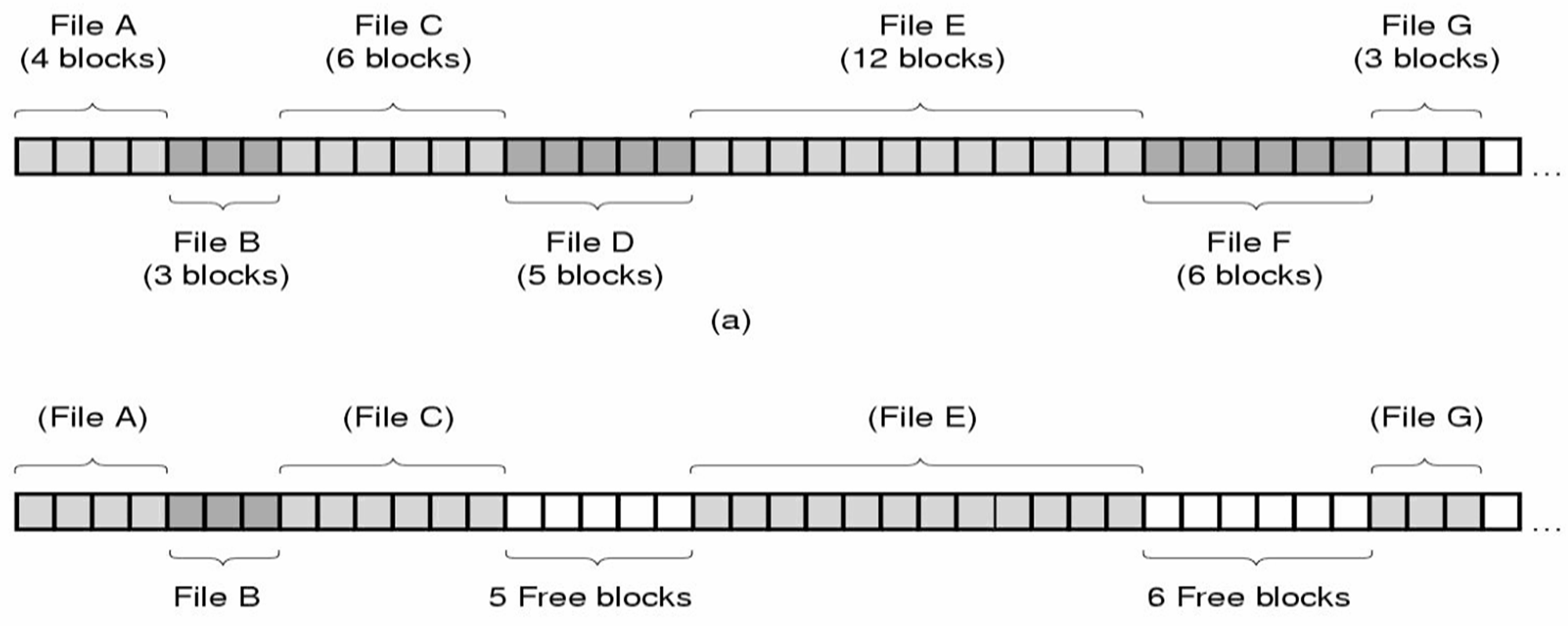
이렇게 중간중간 파일이 삭제되면 디스크에 구멍이 생긴다.
근데 이걸 합치는데는 어마어마한 비용이 들어서 이걸 방치할 수 밖에 없다...
이러한 단점 때문에 연속 할당은 주로 CD-ROM 에서 많이 쓰인다.
(읽기는 빠르고 삭제할 필요가 없으므로)
연결 리스트 할당
디스크 블록들을 연결 리스트 형태로 관리한다.
각 블록의 첫번째 워드 는 다음 블록을 가리키는 포인터로 사용되고 블록의 나머지 공간에 데이터를 저장한다.
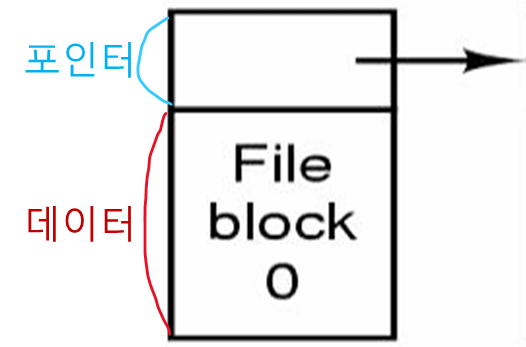
장점
- 연속 할당과 다르게
단편화가 없어서 남아있는 모든 디스크 블록의 사용이 가능하다.
단점
-
파일 임의 접근이 매우 느리다.
- N번 블록을 읽으려면 OS 는 첫 블록부터 N-1번 블록까지 하나씩 읽어야 한다.
-
수 바이트가 포인터를 저장하기 위해 사용되므로 하나의 블록에 저장되는 데이터 양은 더이상 2의 지수배가 아닐 수 있다.
FAT(File Allocation Table) 을 이용한 연결리스트 할당
위의 연결리스트 할당의 두가지 단점은 각 블록에 존재하는 포인터 를 메모리 내의 테이블에 저장함으로써 제거될 수 있다.
이러한 테이블을 FAT(File Allocation Table) 이라고 한다.
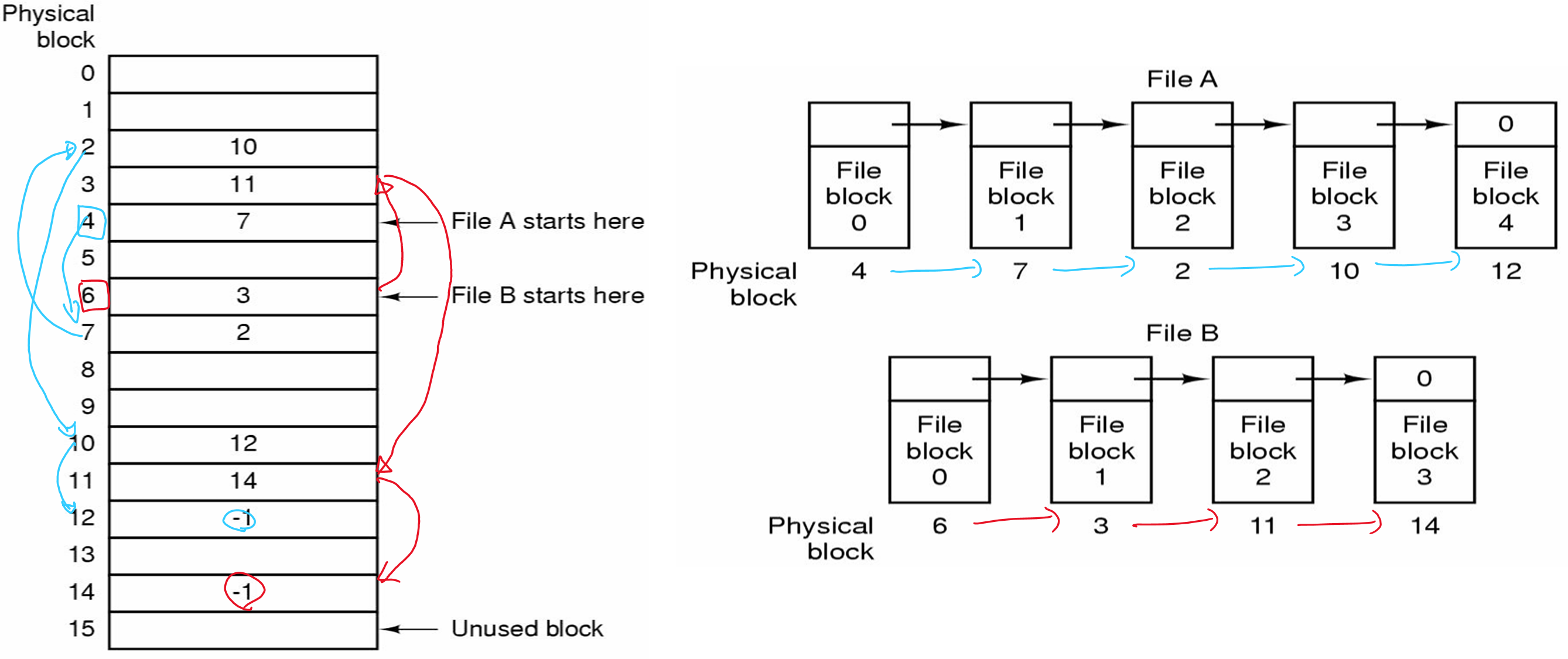
장점
-
한 블록 전체를 테이블에 저장할 수 있다.
-
임의 접근이 쉽다.
- 체인을 따라가야 하지만 체인이 메모리에 존재해서 디스크를 참조하지 않아도 됨
단점
-
전체 테이블이 메모리에 존재해야만 함
-
디스크가 200GB (대략 2^38) 이고
블록 크기가 1KB (2^10) 일 때, 2억개 (2^28) 디스크 블록 당 하나의 엔트리가 대응되어 테이블에는2억개의 엔트리가 존재한다. -
각 엔트리는 최소 3바이트를 필요로 하며 디스크 용량이 커지면 테이블의 크기도 커질 것이다...
-
I-Node
각 파일마다 i-node 라고 불리는 자료구조 를 가진다.
i-node 는 파일의 속성 들과 파일의 디스크 블록 주소 를 가진다.
- 즉 i-node 가 이러한
파일의 위치 정보를 가지고 있어서 OS가 실제 데이터에 접근할 수 있게 한다.



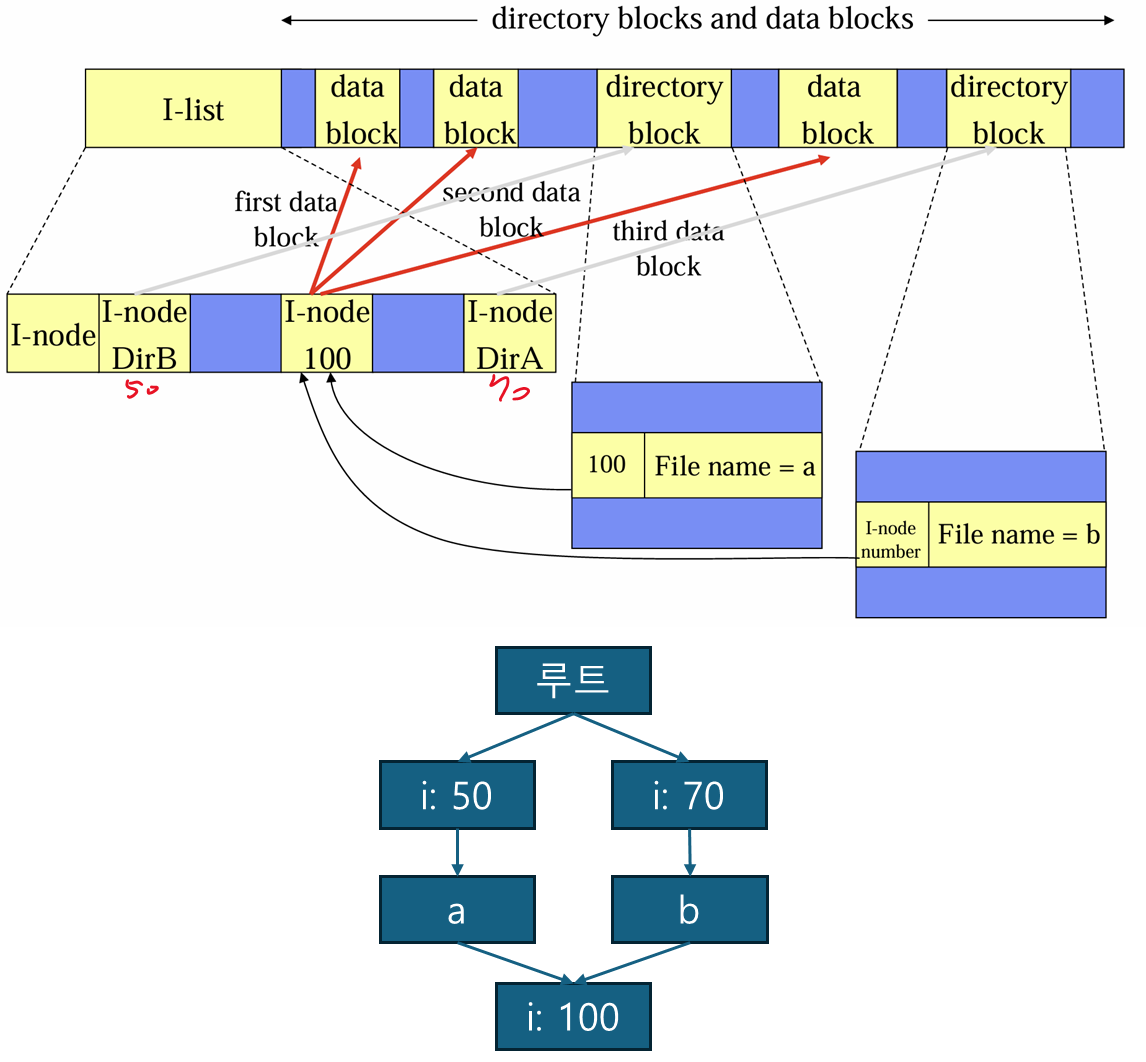
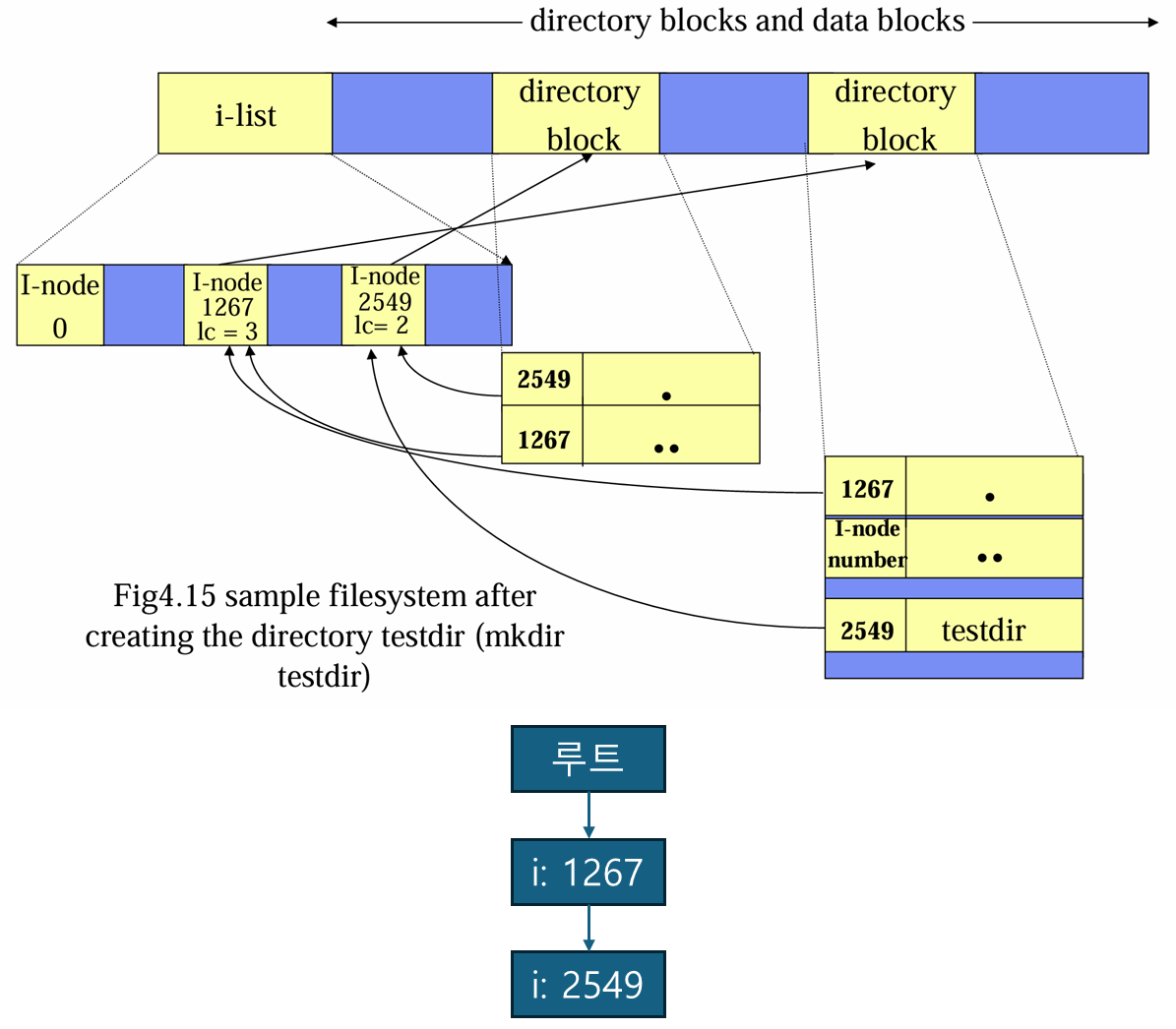
핵심
어떤 파일을 open 하면 해당 파일의 i-node만 메모리에 가지고 있으면 된다.
하나의 i-node 가 n 바이트 이고 최대 k개의 파일 을 동시에 열 수 있다면, 파일시스템이 준비할 i-node 배열의 저장 공간은 kn바이트 이다.
이는 앞에서 설명한 파일 할당 테이블이 차지하고 있는 공간보다 매우 적다
왜냐하면 i-node 기법은 동시에 열 수 있는 최대 파일의 개수만큼의 배열을 필요로 하기 때문이다.
예시
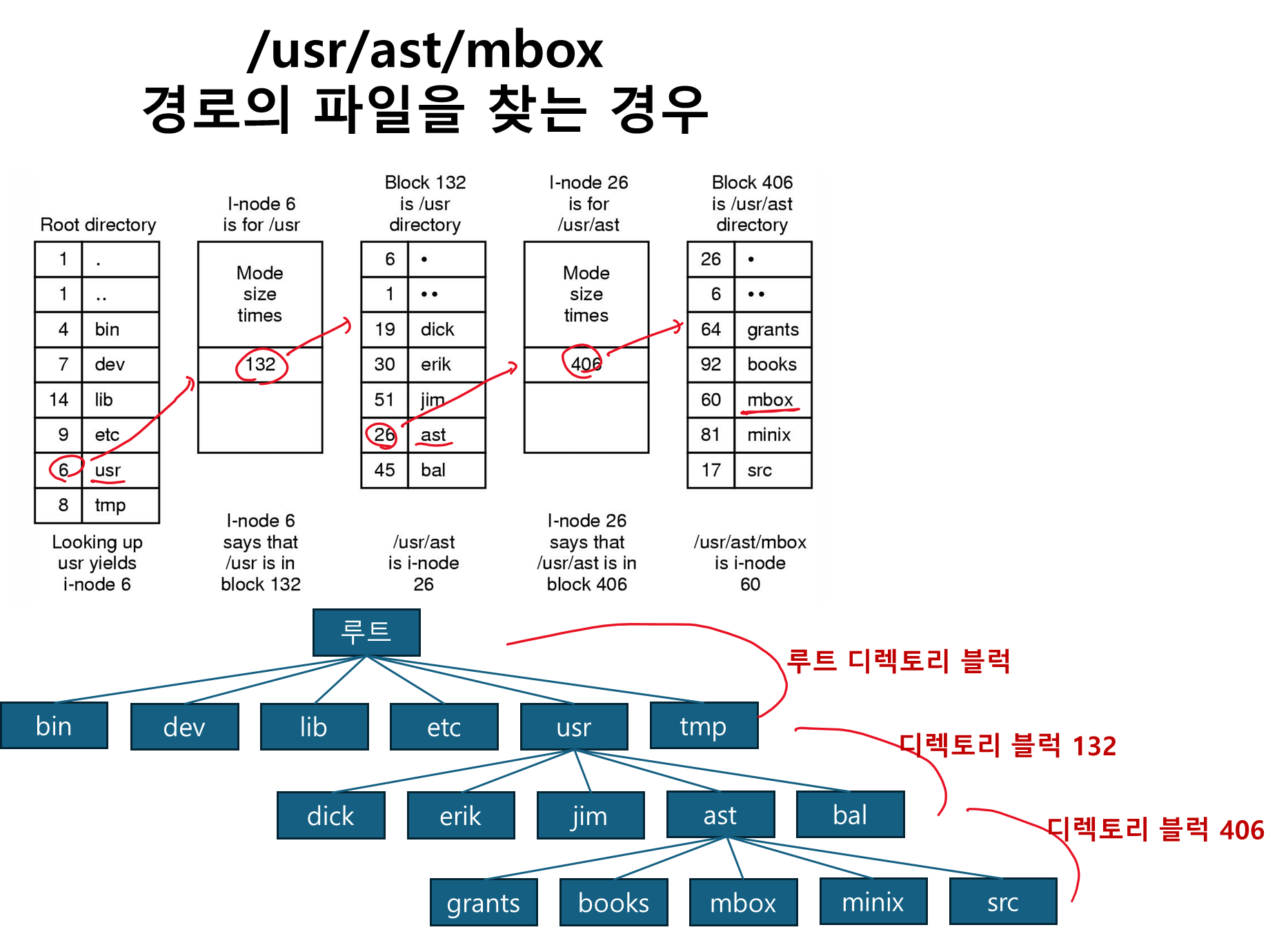
디렉토리 구현
파일을 일기 전에 파일을 먼저 open 해야 한다.
OS 는 파일을 open 할 때 유저가 제공한 파일 경로 이름 을 이용하여 디렉토리 엔트리 를 찾는다.
디렉토리 엔트리 는 디스크 블록을 접근하는 데 필요한 정보 (파일 블록의 주소, 첫번째 디스크 블록의 주소, i-node 번호)를 가지고 있다.
그럼 파일의 속성 을 어디에 저장하는가?
디렉토리 엔트리에 파일 속성을 직접 저장

디렉토리는 고정된 크기의 엔트리들의 리스트로 구성된다
각 엔트리는 다음을 가진다.
- 고정 길이의 파일이름
- 파일 속성 구조체
- 하나 이상의 디스크 블록의 주소
I-node 에 파일 속성을 저장
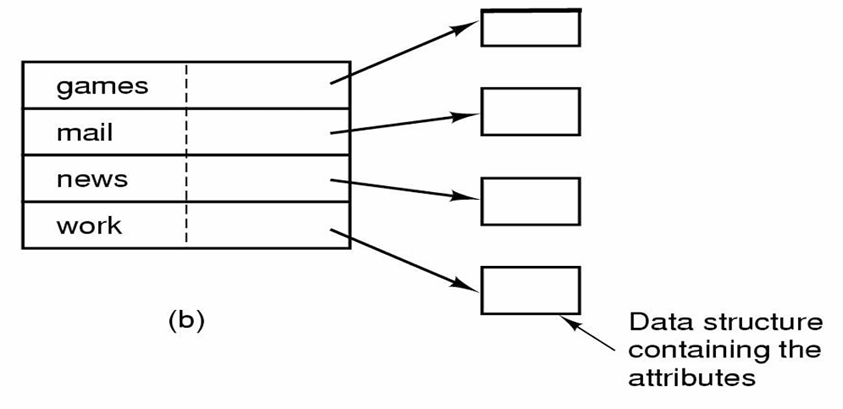
파일 속성이 디렉토리 엔트리가 아닌 i-node 에 저장된다.
이 경우 디렉토리 엔트리는 파일 이름과 i-node 번호만을 저장하므로 더 짧다.
가변적인 파일 이름의 구현
정렬 이름 기법
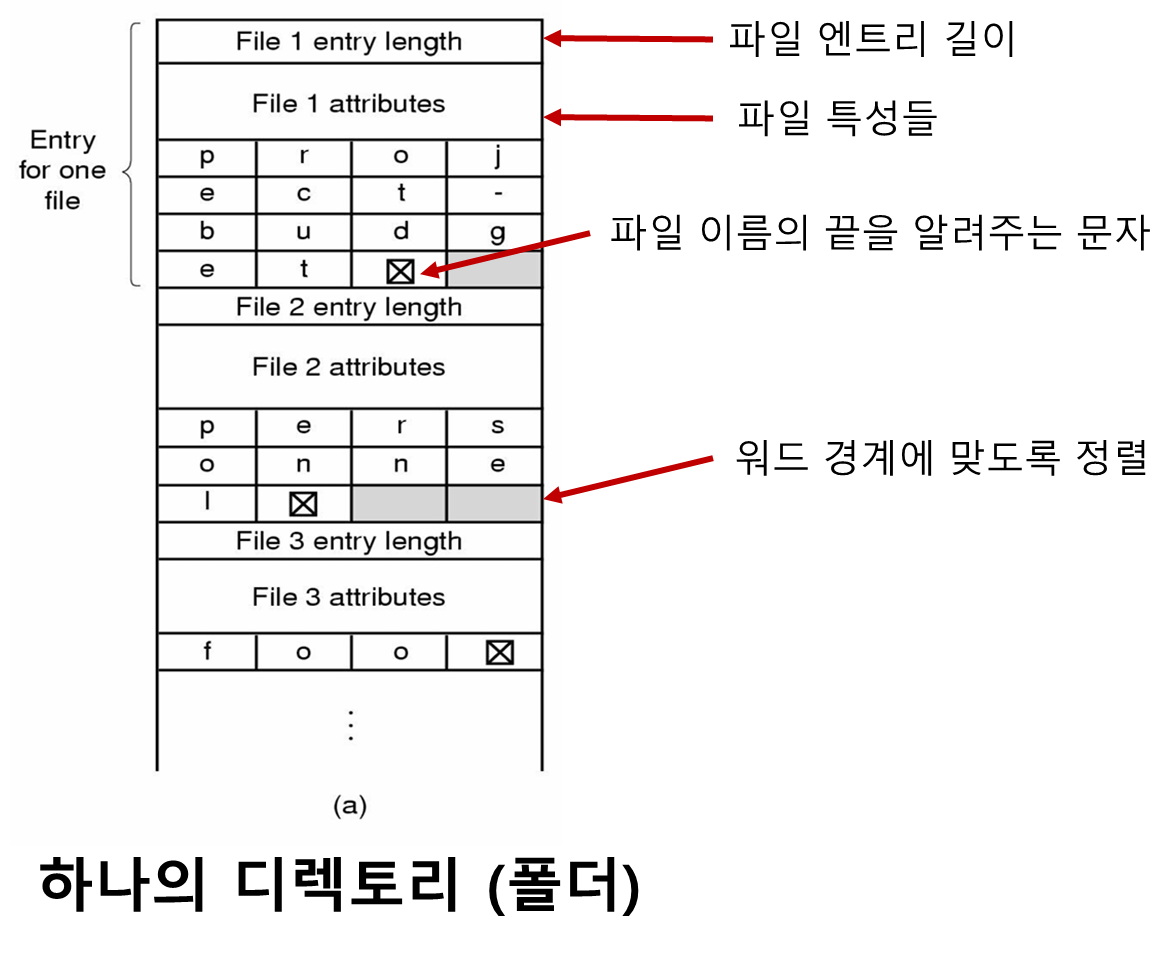
단점
-
파일이 제거될 때 단편화가 생길 수 있다. (앞에 디스크 파일 연속 할당 기법에서 발생하는 문제와 동일)
- 근데 디렉토리 전체가 메모리에 존재하기 때문에 입출력이 빠르니까
조각 모음이 가능하긴 함
- 근데 디렉토리 전체가 메모리에 존재하기 때문에 입출력이 빠르니까
-
하나의 디렉토리 엔트리가 다수의 페이지에 걸쳐 있을 수 있어서 파일 이름을 읽는 동안
페이지 폴트가 발생할 수도 있음
힙 기법
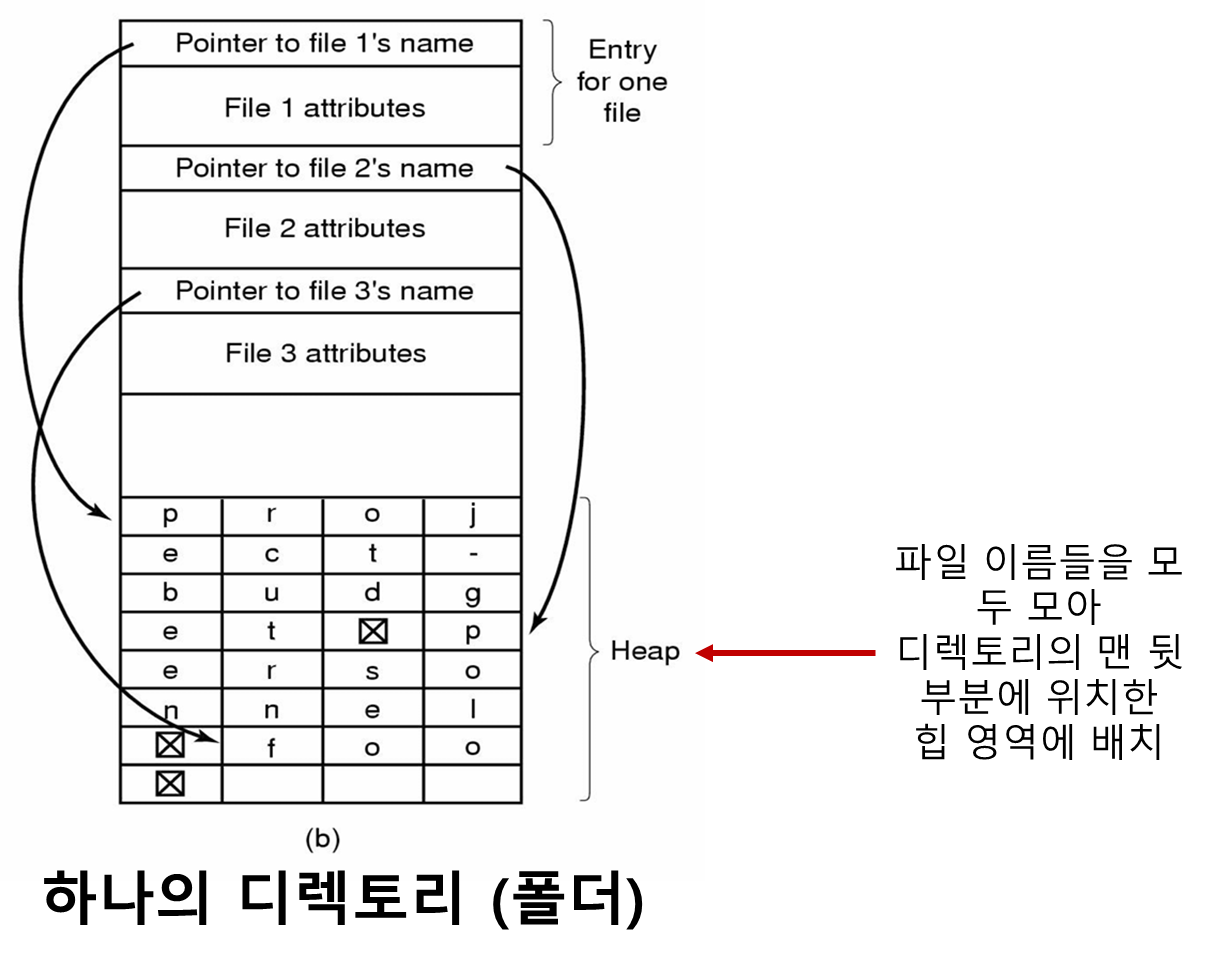
장점
-
한 엔트리가 제거된 후 다른 파일이 크기를 걱정하지 않고 이 엔트리를 사용할 수 있다.
- 힙에다 이름을 저장했기 때문에 가변성이 좋음, 아까처럼 단편화 걱정 안해도 됨
-
파일 이름이 반드시 워드 경계에서 시작할 필요가 없어 더미문자로 정렬 안해도 된다.
단점
- 파일 이름을 처리하는 동안 페이지 폴트 발생가능
공유 파일
여러 유저가 하나의 프로젝트를 수행중일 때 파일을 공유할 필요가 있다.
아래 그림을 보면 C의 파일 중 하나가 B의 디렉토리에도 존재하는 것을 표시되는데 링크 라는 작업을 통해 B의 디렉토리와 공유되는 파일이 연결된다.
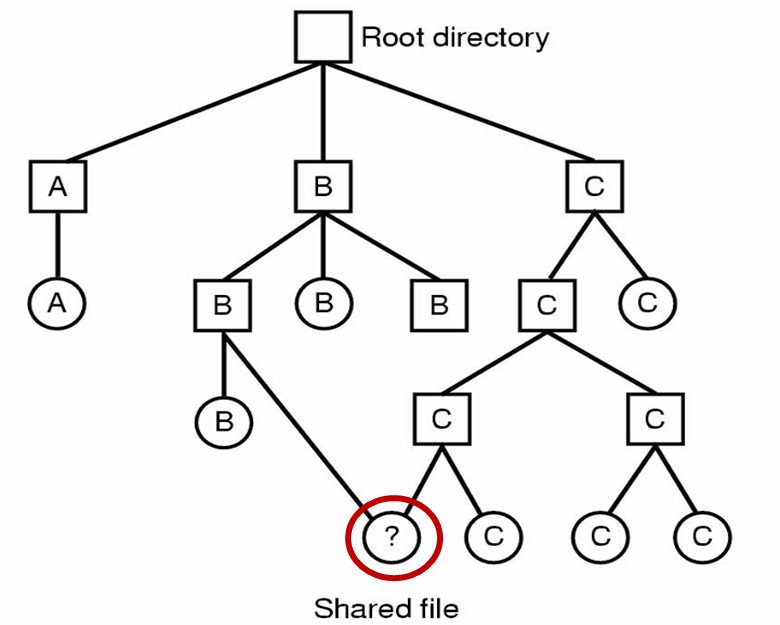
공유 파일에는 다음과 같은 문제점이 있다.
-
디스크 블록 주소를 디렉토리에 기록하는 구조라면 파일이 링크 될 때 그 주소가 복사되어 B의 디렉토리도 디스크 블록 주소를 가진다.
-
B 또는 C 중 하나가 파일의 뒷부분에 데이터를 추가한다면 해당 사용자의 디렉토리에만 새로운 블록 주소가 추가될 것이다.
-
다른 사용자에게는 이런 변화가 보이지 않아 공유의 목적에 위배된다.
하드 링크 : i-node 사용
디스크 블록 주소를 디렉토리에 기록하는 것이 아니라 i-node(파일과 관련된 자료구조) 에 기록하는 것이다.
UNIX 에서 사용되는 기법이다.

하드 링크 문제점
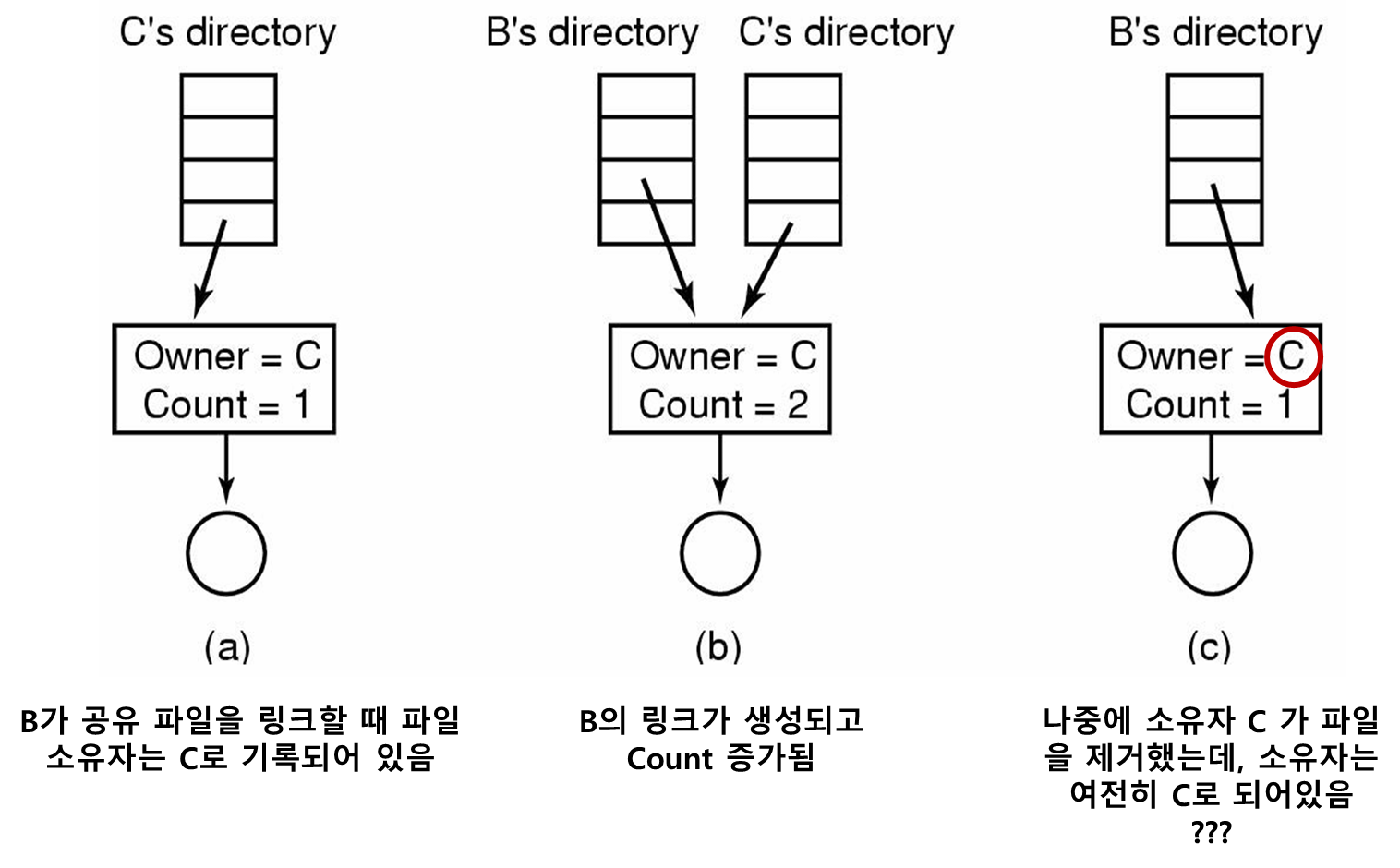
또한 디렉토리에서는 하드 링크를 쓰기가 쉽지 않다. (루프가 발생할 수 있음)
게다가 다른 파일시스템에서는 사용할 수가 없다.
심볼릭 링크
위의 하드 링크의 문제점을 해결하기 위해 등장함
윈도우의 바로가기 를 생각하면 된다.
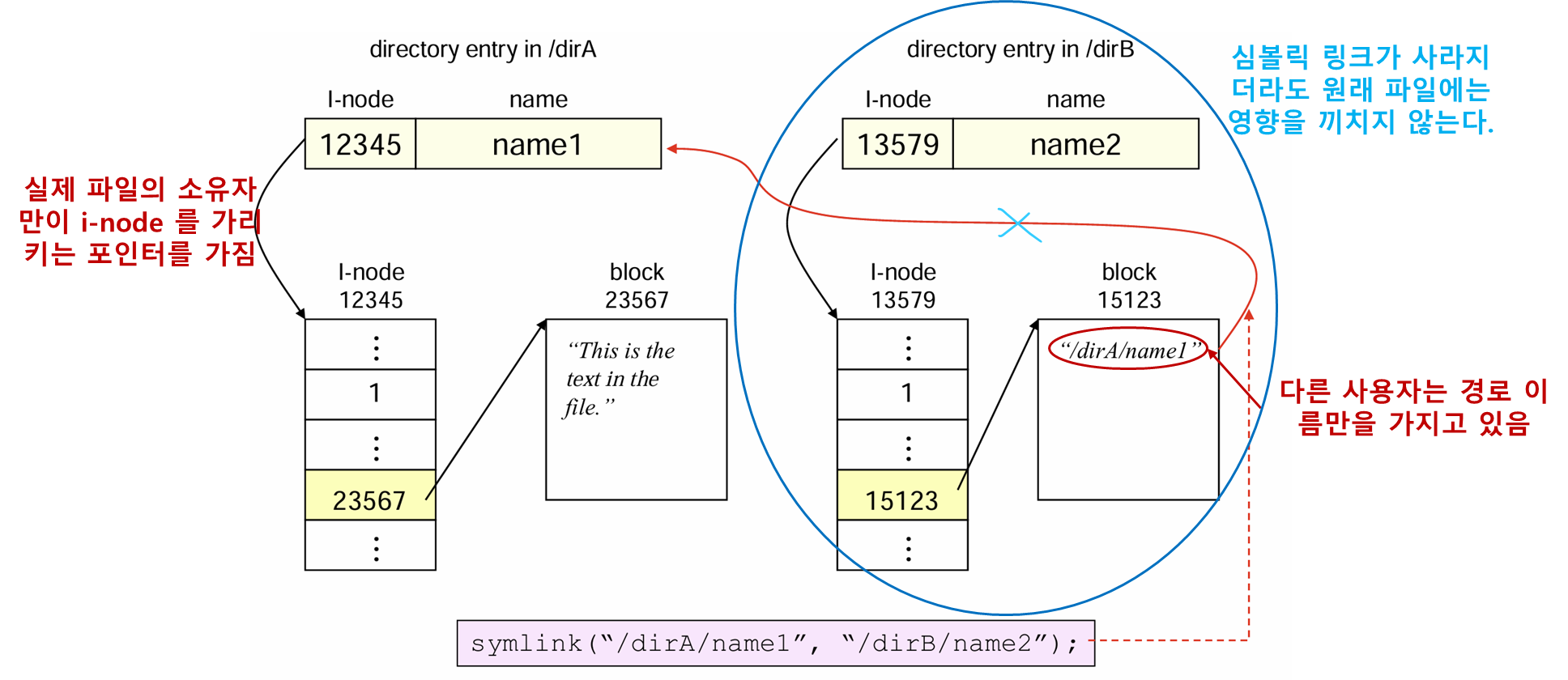
하드링크와 달리 심볼릭 링크는 디렉토리, 다른 파일시스템에서도 사용할 수 있다.
심볼릭 링크 문제점
추가적인 오버헤드가 발생한다.
-
심볼릭 링크를 위해 추가적인 i-node 가 사용되며 경로를 저장하기 위해
별도의 디스크 블록이 필요하다. -
파일에 포함된 경로를 다시 읽어야 해서 별도의
디스크 접근이 필요하다.
로그 구조 파일시스템
여기선 Long-structured File System: LFS 에 대해 설명하겠다.
현재 컴퓨터 하드웨어에서 유일하게 발전하지 못하고 있는 부분이 디스크의 탐색 시간이다.
LFS 는 앞으로 CPU는 더 빨라지고 RAM 은 더 커지며 디스크의 캐시 또한 매우 커질거라 예측을 한다.
따라서 read 요청의 상당수는 디스크 접근 없이 파일 시스템의 캐시에서 바로 처리가 가능할 것이며
대부분의 디스크 접근을 쓰기가 될 것이다. (말 그대로 디스크에는 주로 저장만 할 것)
LFS 요약
-
전체 파일 시스템 구조는
로그이다.- 주기적으로 메모리에 버퍼링된 wirte 요청을 모아 하나의 세그먼트로 구성한 후, 하나의 연속적인 세그먼트를 디스크의
로그의 끝에 기록한다. 로그에는i-node,디렉토리 블록,데이터 블록,세그먼트 요약이 포함될 수 있다.
- 주기적으로 메모리에 버퍼링된 wirte 요청을 모아 하나의 세그먼트로 구성한 후, 하나의 연속적인 세그먼트를 디스크의
-
파일 오픈은 이제 파일의 i-node 위치를 찾기 위해 i-node 맵을 사용해야 한다.
- i-node 맵은 디스크에 보관되고 일반적으로 메모리에 캐시 된다.
-
클리너는 다음 로그를 위해 사용되지 않는 세그먼트를 해제한다.
- 세그먼트의 활성 데이터는 새 데이터로 수집된다.
-
파일 블록이 새로운 세그먼트에 기록될 때, 파일의 i-node를 로그의 어딘가에서 찾아 변경하고 메모리에 가지고 있다 다음 세그먼트에 기록해야 한다.
- 근데 쉽지 않다.
저널링 파일 시스템
로그 구조 파일 시스템은 널리 사용되지 않는데 그 이유는 기존 파일 시스템과 거의 호환이 되지 않기 때문이다.
하지만 시스템 크래쉬로부터의 robustness 는 쉽게 기존 파일시스템에 적용될 수 있다.
저널링 파일 시스템 의 기본 아이디어는 파일 시스템이 어떤 작업을 실행하기 전에 이에 대한 로그를 기록하는 것이다.
나중에 부팅을 할 때 이러한 로그를 보고 미완성된 작업을 완료할 수도 있다.
파일 삭제를 예로 이해해보자, 다음은 파일 삭제의 3가지 단계이다.
-
파일을 디렉토리에서 삭제
-
i-node를 사용가능한 i-node 풀로 반환
-
파일이 차지하던 디스크 블록도 가용 풀로 반환
저널링 파일 시스템 동작
-
세가지 단계를 나열한 로그 엔트리 기록
- 로그 엔트리는
디스크에 기록됨
- 로그 엔트리는
-
로그 엔트리가 기록된 후에야 연산이 실행
-
연산이 성공적으로 실행되면 로그 엔트리는 지워짐
-
시스템 크래쉬 발생 시
- 파일 시스템은 먼저 로그를 참조, 어떤 연산이 실행 중 이었는지 검사함
- 실행중인 연산이 있다면 해당 파일이 정확하게 삭제될 때 까지 검사 반복실행
저널링이 제대로 작동되기 위해서는 로그에 기록된 연산들은 <멱등적(idempotent): 어떤 작업이 문제를 일으키지 않고 여러 번 실행 될 수 있음> 이어야 함
단, i-node K 로부터 새로 반환된 블록들을 가용 리스트의 끝에 추가하는 것은 멱등적이 아님
파일 시스템 관리와 최적화
블록 크기
블록의 크기를 크게 하면 Internal Fragmentation 으로 인해 디스크 공간이 낭비된다.
블록의 크기를 작게 하면 디스크 접근 을 자주 해야 되서 시간이 낭비 된다.

가용 블록들의 관리
링크드 리스트 기법
가용 디스크 블록들을 연결 리스트로 구성한다.
-
각 디스크 블록은 용량이 가득 찰 때 까지 가용 디스크 블록의 번호들을 가지고 있다.
-
맨 마지막 엔트리는 다음 가용 블록을 가리키는 포인터로 사용된다
-
일반적으로 사용되지 않는 가용 블록들로 리스트를 구성하기 때문에 이러한 가용 블록들의 주소를 저장하기 위해서 별도의 공간이 필요하지 않다.
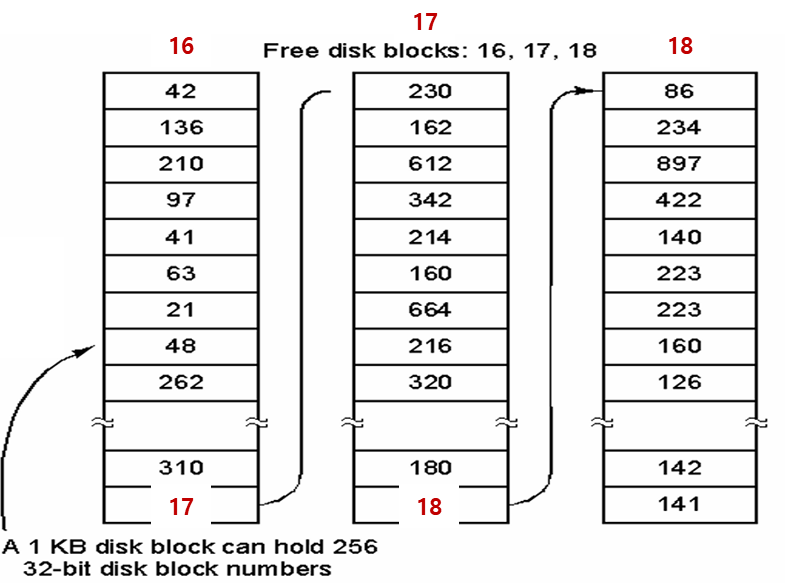
전체가 메모리에 올라올 필요 없이 맨처음 리스트만 올라오고 필요할 때마다 추가적으로 메모리에 올리면 된다.
비트맵 기법
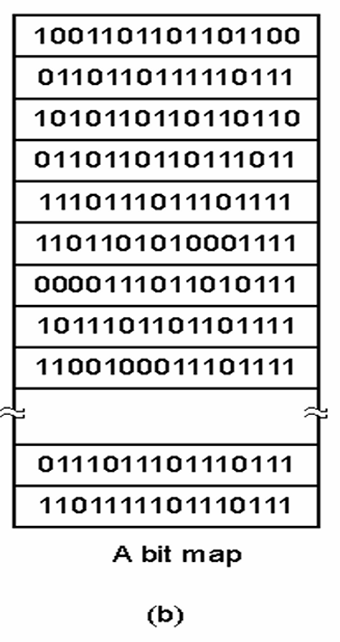
전체 비트맵을 메모리에 유지해야 한다.
관리하기가 쉽다.
파일 시스템 백업
재난과 실수로부터 대비하기 위해 백업이 필요하다.
물리적 덤프(백업)
디스크 0번 블록부터 마지막 블록까지 순서대로 테이프에 기록하는 것
가장 간단한 방법이고 가장 빠르다
단점
-
사용되지 않는 블록까지 백업함 (시간낭비)
-
배드 블록까지 백업함
- 배드 블록이 OS에 표시되면 끝없는 디스크 읽기 오류가 발생할 수 있다.
- 물리적 덤프 프로그램은 반드시 배드 블록 정보에 접근해서 백업되는걸 피해야 한다.
논리적 덤프
지정된 디렉토리부터 시작하여 디렉토리들을 순환적으로 방문하면서, 지정된 기준 날짜 이후에 변경된 모든 파일과 디렉토리들을 백업함
물리적 덤프와 달리 사용되지 않는 블록을 백업하지 않음
쉽게 특정 파일이나 디렉토리만 선택적으로 복원할 수 있다.
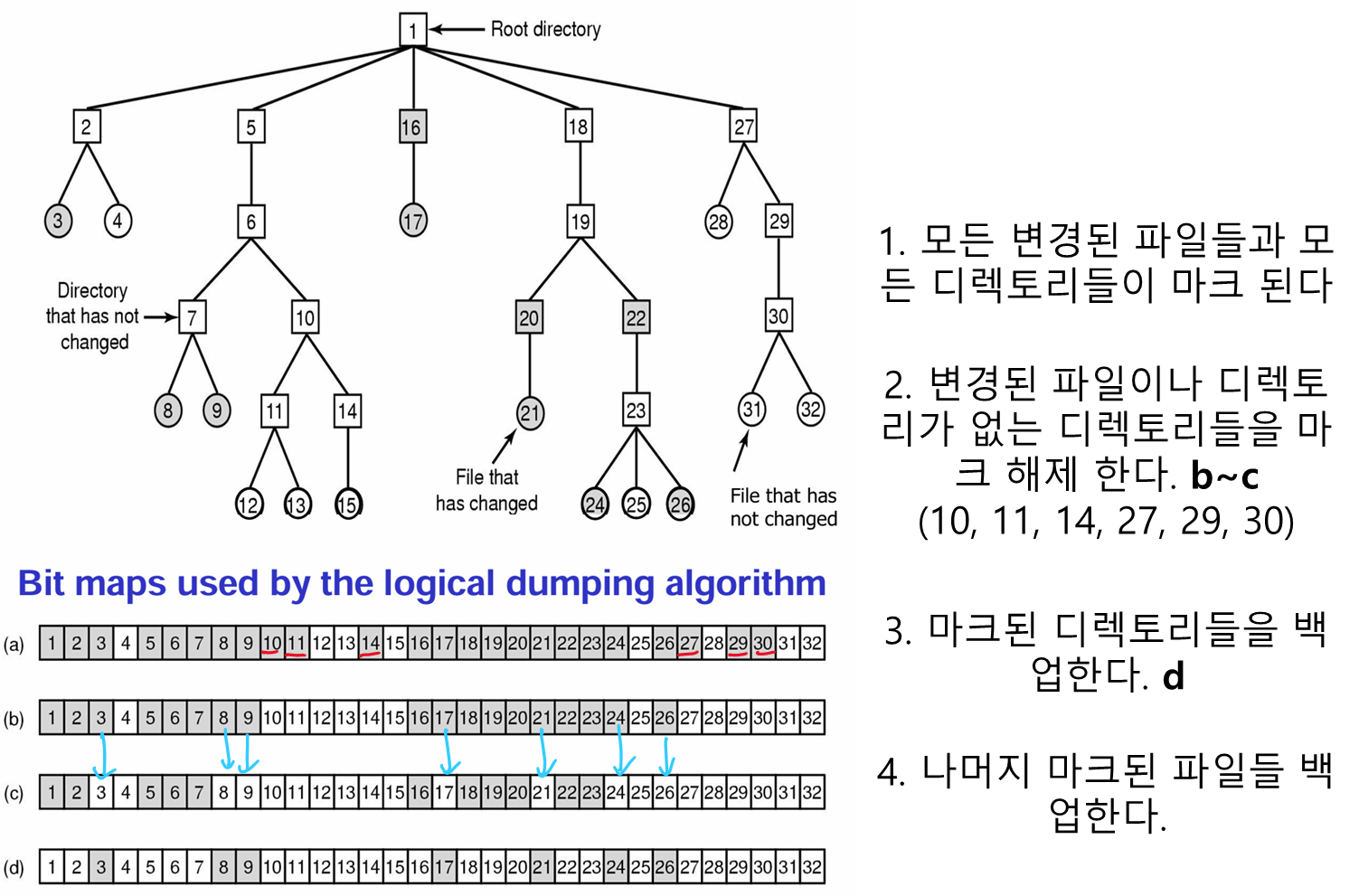
파일 시스템 일관성
변경된 모든 블록이 기록되기 전에 시스템 크래쉬가 발생하면 파일 시스템은 일관성을 상실한 모순된 상태가 된다.
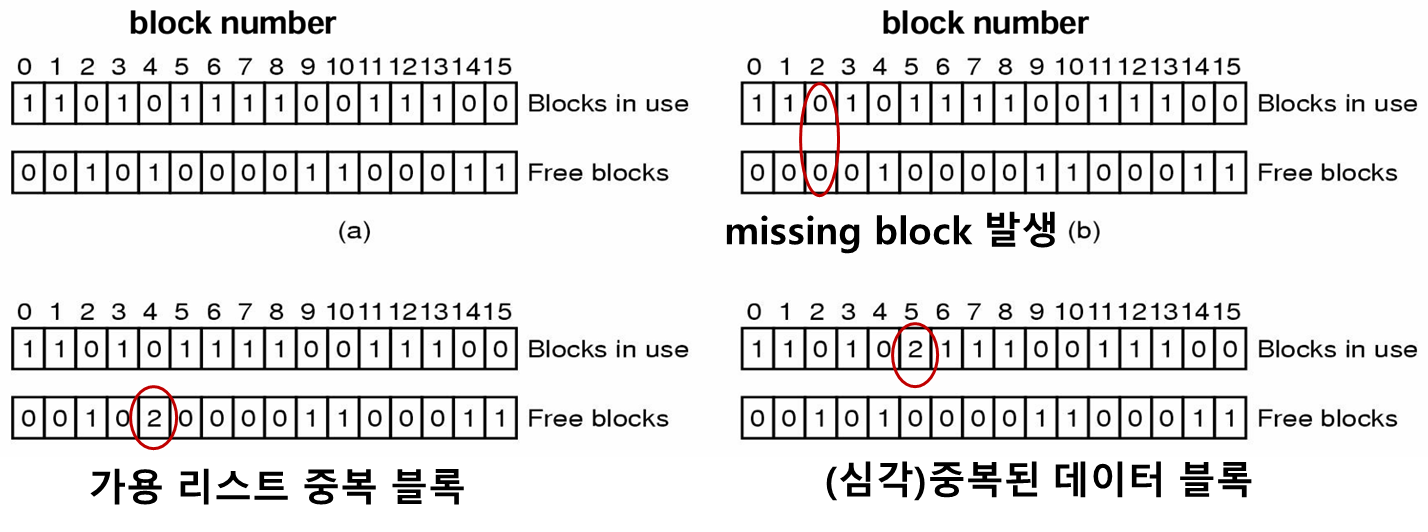
b,c의 경우 가용 리스트를 단지 변경하기만 하면 된다.
missing block 은 다음과 같이 디렉토리나 i-node 의 포인터가 크래시로 끊어졌지만 데이터 블록은 아직 free 되지 않았을 때 발생한다.
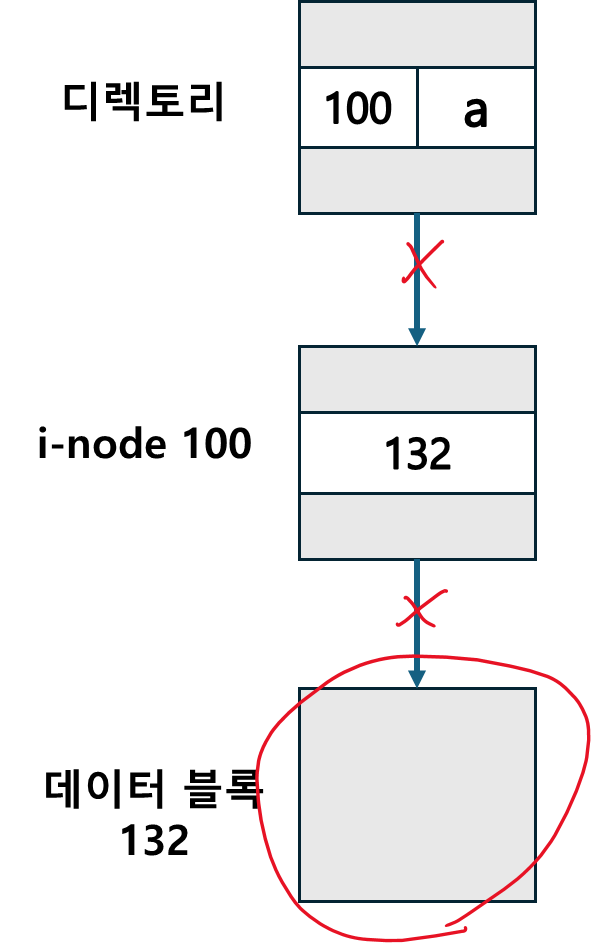
문제는 d 처럼 하나의 데이터 블록이 두개 이상의 파일에서 사용되는 경우인데
파일 시스템 검사기는 다음의 행동을 한다.
- 가용 블록 하나를 할당하여 블록 5번의 내용을 그 곳으로 복사
- 이 블록을 두 파일 중 하나에게 제공
File Consistency Check
-
File Consistency Check란?
파일 시스템의 일관성을 검사하는 과정이다. 파일 시스템에 오류가 발생했을 때, 이를 감지하고 수정하기 위해 사용한다. -
Usage Counter (블록 사용 카운터):
파일이 참조하고 있는데이터 블록의 수를 나타낸다. -
Link Counter (링크 카운터):
파일을 참조하는디렉토리 엔트리의 수 (파일 경로)를 나타낸다.
파일당 카운터(usage counter) 를 사용한다.
파일 트리를 재귀적으로 검사하는 동안 파일이 디렉터리에서 발견되는 경우 파일에 대한 카운터를 증가시킨다.
usage 카운터 를 파일의 링크 카운터 (i-node 자체에 저장 된) 와 비교한다
일관성 있는 파일 시스템의 경우 usage 카운터 == 링크 카운터 이다.
-
link 카운터 > usage 카운터 = 링크 카운터 수정
- 파일 삭제 중
크래시가 나서 파일 링크 카운터가 감소하지 않은 경우이다. - 그냥
link 카운터 = usage 카운터로 수정하면 된다. - 위의 저널링 파일 시스템에 삭제 예시에서 1-2-3 순서로 가면 발생 가능
- 파일 삭제 중
-
link 카운터 < usage 카운터 = 링크 카운터를 usage 카운터 값으로 설정. (안좋은 경우)
- 삭제 중 크래시 나서
i-node랑데이터 블록은 지워졌는데디렉토리 경로만 남아있는 경우이다. - 이것 역시
link 카운터 = usage 카운터로 수정하면 된다. - 3-2-1 순서로 가면 발생 가능
- 삭제 중 크래시 나서
버퍼 캐시
디스크 접근은 메모리 접근보다 read 시간 이 오래 걸린다
이를 개선 하기 위해 캐시를 사용할 수 있다.
아이디어는 최근에 액세스한 데이터가 다시 필요할 가능성이 높다는 것이다.
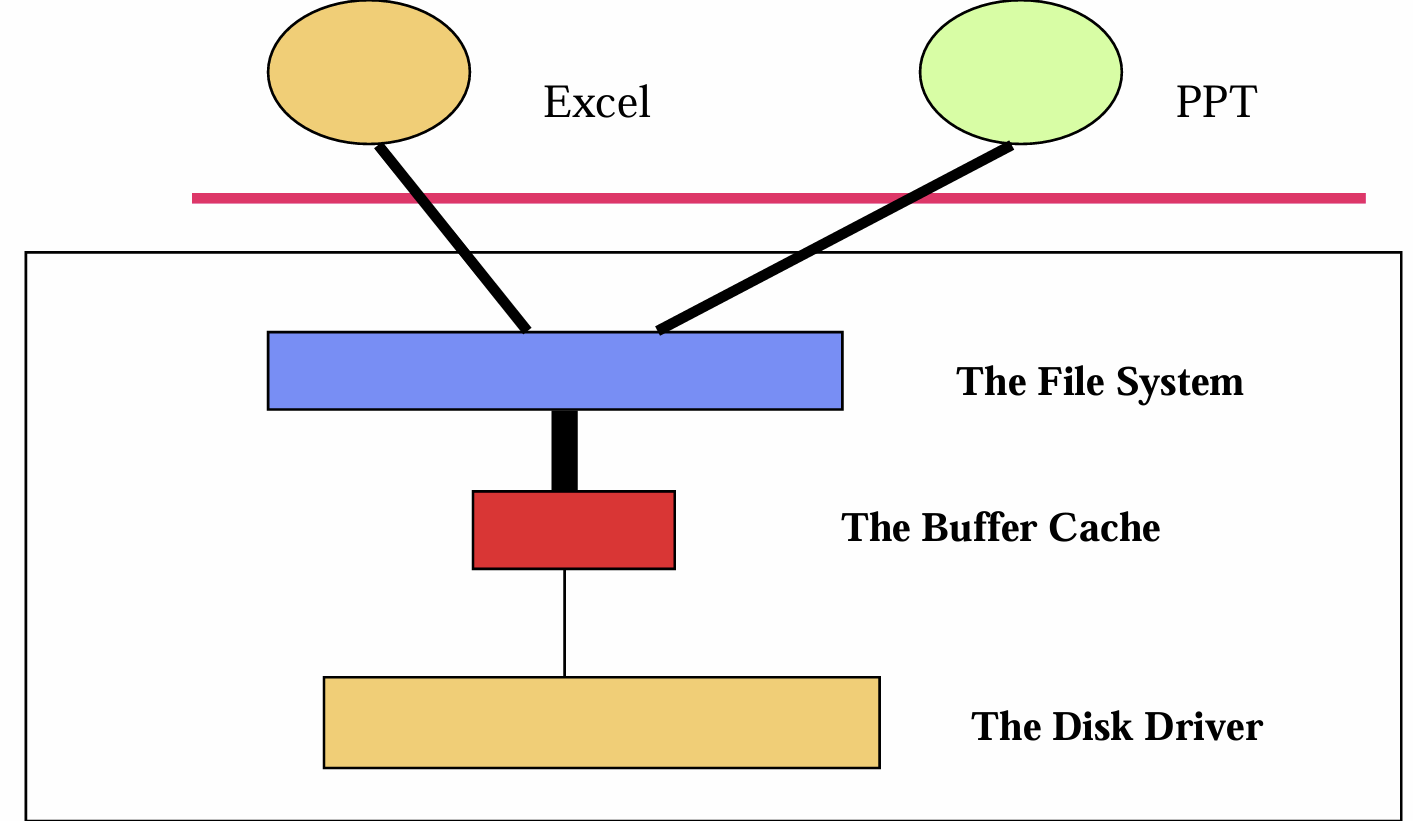
Buffer Cache
-
Buffer Cache란?
- 디스크 섹터를 메인 메모리에 복사한 버퍼.
- 최근에 접근한 데이터는 다시 필요할 확률이 높음 (지역성).
- 파일 시스템과 디스크 드라이버 사이에서 사용됨.
-
특징
- 유한한 블록 수를 가짐.
- 캐시 미스 시, 새로운 블록을 가져오기 위해 기존 블록 중 하나를 폐기해야 함.
- 일반적으로 LRU (Least Recently Used) 정책으로 블록 교체.
-
LRU 정책
- 가장 오랫동안 참조되지 않은 블록을 교체.
- 블록들은 실제 메모리에서 움직이지 않음.
- 블록 포인터를 스택 형태로 관리.
LRU의 문제점
-
작업 부하에 따라 비효율적일 수 있음:
- 순차적 스캔: 비디오, 오디오 파일
- 랜덤 접근: 대형 데이터베이스
-
특정 블록에 LRU가 적합하지 않음:
- I-node 블록: 짧은 간격 내에 두 번 참조되지 않음.
- 파일 시스템 메타데이터 블록: 일관성 유지가 중요하므로 디스크에 즉시 기록해야 함.
-
Unix와 MS-DOS의 차이:
- Unix:
sync또는update데몬 사용. - MS-DOS: write-through 캐시 사용.
- Unix:
쓰기 캐싱 정책
-
Write-through
- 데이터를 버퍼 캐시를 통해 디스크에 즉시 기록.
- 안전하지만 느림.
-
Write-behind (Write-back)
- 커밋되지 않은 블록을 큐에 유지하고, 주기적으로 디스크에 기록.
- 빠르지만 신뢰성 문제.
-
배터리 백업 RAM
- Write-behind 큐를 배터리 백업 메모리에 유지.
- 비싸지만 신뢰성 높음.
-
Log-Structured File System
- 항상 디스크에 새로운 블록을 순차적으로 기록.
- 디스크를 테이프처럼 취급.
디스크 암 모션 최소화
-
I-node 배치 최적화
- I-node를 디스크 시작 부분에 배치 (전통적 방식).
- FFS (Fast File System): 디스크를 실린더 그룹으로 나눔. 각 그룹에 자체 블록과 I-node를 가짐.
-
연속 블록 할당
- 블록을 연속된 그룹으로 할당 (예: 4블록 단위).
